
ControlNet初心者教本 改訂版

0:ControlNetとは
ControlNet(コントロールネット)とは画像などを下地にしてポーズや構図、画像の雰囲気を抽出し、画像の生成時に参照する仕組みです。この時利用する仕組みのことをプリプロセッサ(preprocessor)といいます。
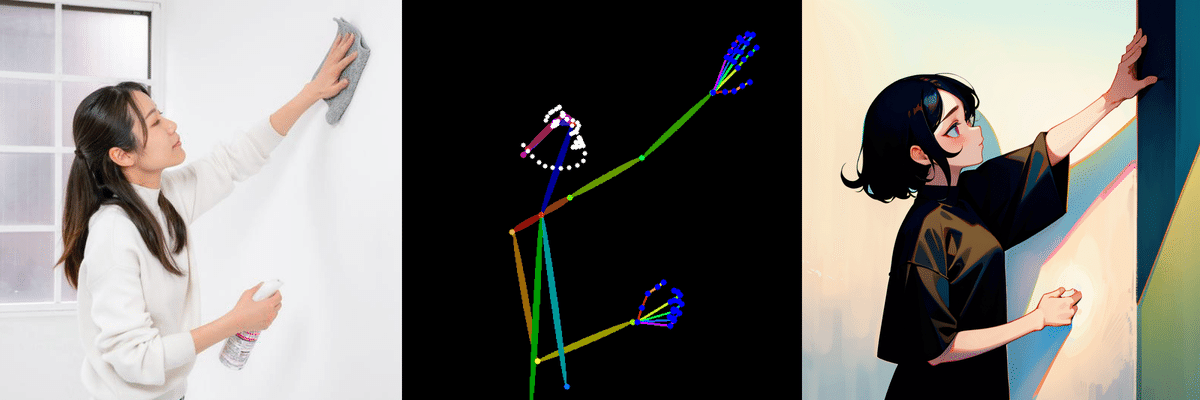
下の画像は人間を棒人間のような線で抽出するopenposeの例です。このようにポーズをまねたりすることができます。
1:コントロールネットの導入
まずは、SDWebUIから「拡張機能」を選択して「URLからインストール」を選択してください。「拡張機能のリポジトリのURL」に以下のURLをコピー&ペーストしてください。あとはインストールを押すだけです。
https://github.com/Mikubill/sd-webui-controlnet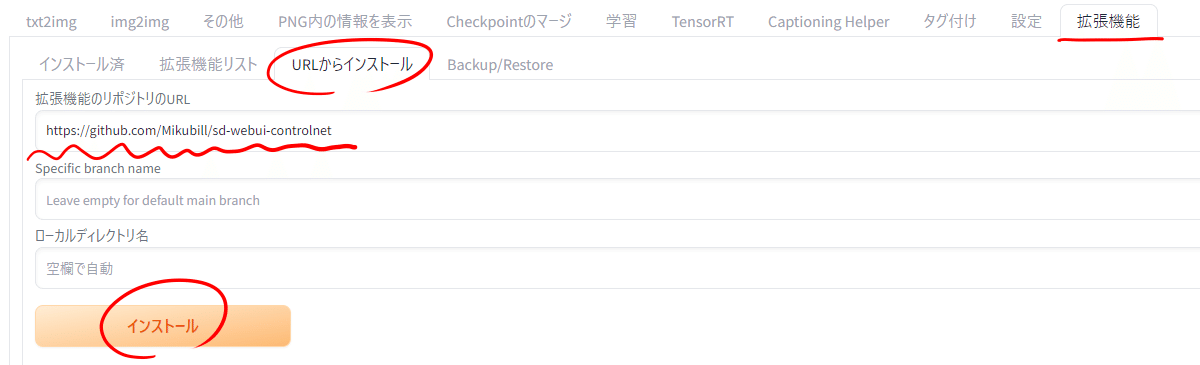
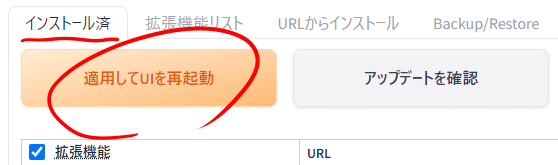
インストールが完了したら「インストール済み」タブに戻って「適用してUIを再起動」を押してください。
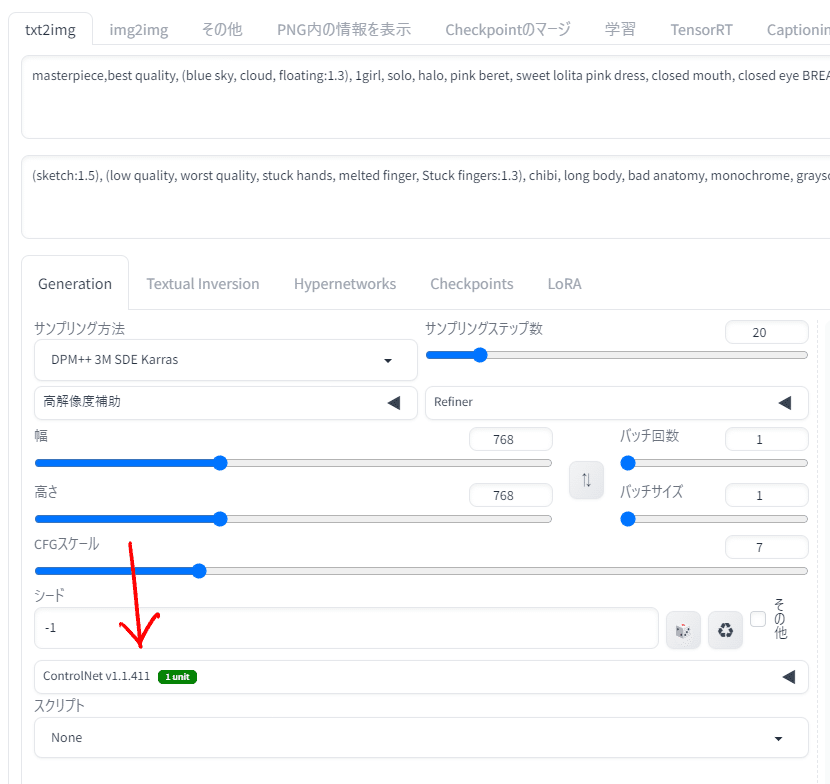
「txt2img」タブに戻るとシード値の下にコントロールネットのタブができています。クリックすると展開するので見てみましょう。
2:ControlNet拡張
コントロールネットには便利な拡張機能があります。(コントロールネットの拡張機能の解説はまだありません)
深度マップで使える手の修正用ライブラリー
https://github.com/wywywywy/sd-webui-depth-lib
open-pose editorの3D版
https://github.com/nonnonstop/sd-webui-3d-open-pose-editor
3:各バージョンのcontrolnetモデルと配置方法
コントロールネットのモデルは各SDバージョンに互換性がなく専用のものを使う必要があります。多くの人はSD1系モデルで大丈夫ですが、2系、SDXLを使っている人は注意が必要です。
URLを開くといろいろなモデルがあるのでどれをダウンロードすればいいかわからない人でストレージに余裕のある人はとりあえず全部ダウンロードしてもかまいません。余裕がない人はいったん飛ばしてcontrolnetの解説を見ながら自分に使えそうなものを選んでダウンロードしましょう。
ControlNet SD1系モデル
ControlNet SD2系モデル
ControlNet SDXL系モデル
モデルをダウンロードしたらコントロールネットの拡張機能フォルダーにモデルを配置する必要があります。
まずはWebUIをいつも起動している「webui-user.bat」があるフォルダーの「extenions」フォルダーを開きます。

フォルダーの中にインストールしている拡張機能のフォルダーがあるのでその中からコントロールネットを選びます。
その中に「models」フォルダーがあるのでそれを開いてダウンロードしたモデルを配置してください。
3:基本解説
コントロールネットのタブには様々な機能があり始めてみると戸惑いやすいです。
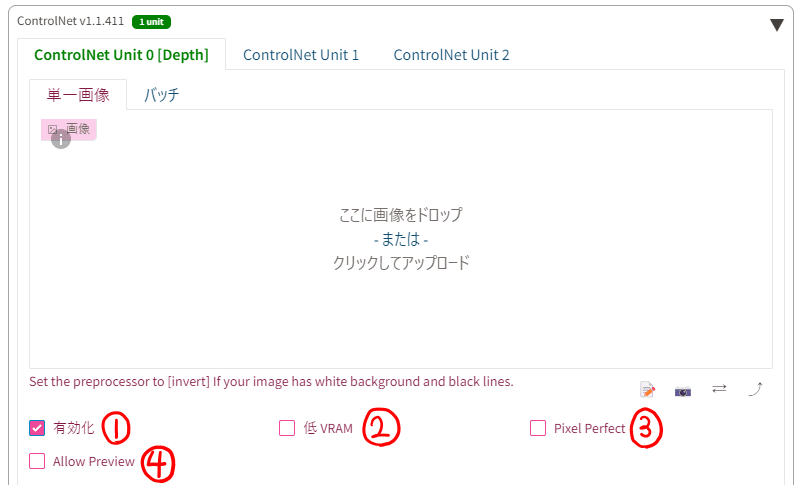
「ここに画像をドロップ」のところに参照する画像を指定します。ドロップでもフォルダーから指定のどちらでもできます。
①有効化(Enable)
ここからコントロールネットを使うかを決められます。
②低VRAM(Low VRAM)
VRAM不足で動作しない場合に使用します。生成速度は低下するようです。
③Pixel Perfect
「Pixel Perfect」をオンにするとプリプロセッサの解像度を画像に合わせて自動で合わせてくれるため⑪の「Preprocessor Resolution」が消えます。便利なのでONにすることをお勧めします。
④Allow Preview
この項目をONにすると処理された参照する画像を、「Generate」ボタンを押さずに見ることができます。使うプリプロセッサを指定し、プリプロセッサとモデルの間にある爆発マークを押すと「preprocessor preview」の欄に処理された画像が出力されます。
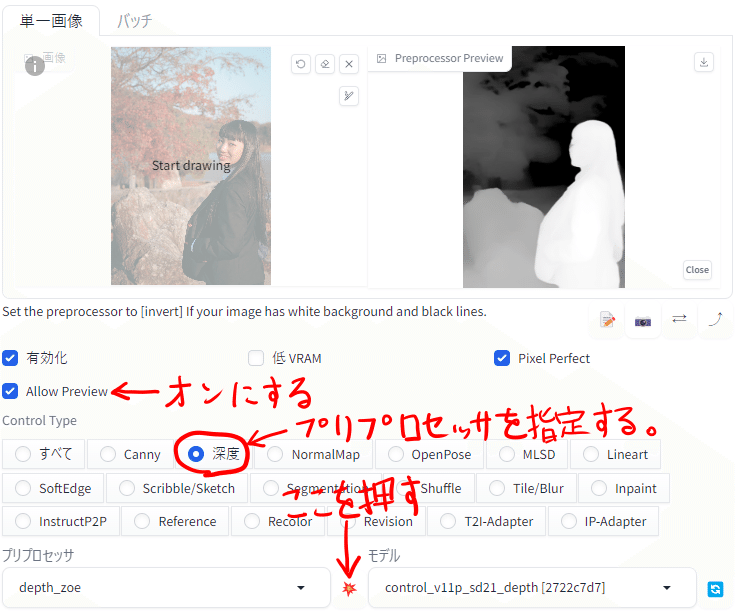
⑤Control Type
ここで使用するプリプロセッサを指定します。この時対応するモデルがあれば自動で指定されますが、使用しているモデルのSD1/2/XLの種類を見分けてくれるわけではないので、複数モデルを入れている方は注意してください。
⑥プリプロセッサ(Preprocessor)
プリプロセッサには精度の違いなど種類がある場合があります。複数の処理の仕組みがある場合ここから指定できます。
⑦モデル(Model)
多くのプリプロセッサではモデルが必要になることがあります。「Control Type」指定時に自動的にこちらも指定されますが、先ほども書いたように使用しているモデルのSD1/2/XLの種類を見分けてくれるわけではないので注意してください。
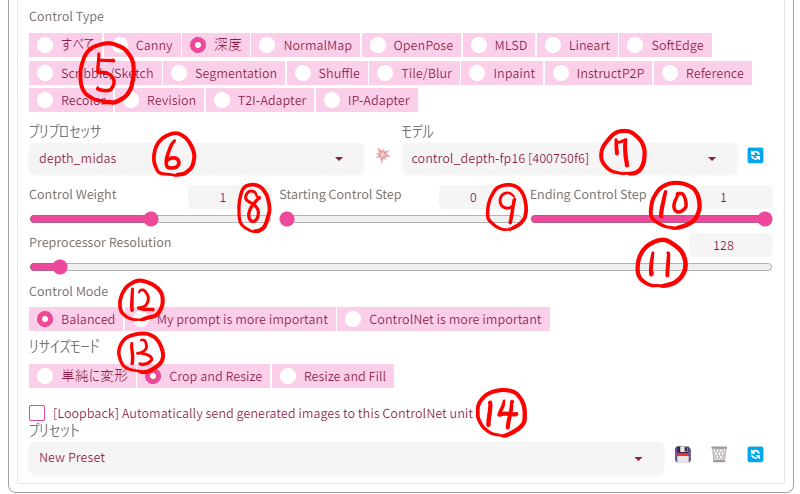
⑧Control Weight
コントロールウェイトではコントロールネットが与える影響力を調整できます。
⑨Starting Control Step
この項目ではコントロールネットが影響を与え始めるステップ(%)を指定できます。この項目は0(最初から)で構いません。
⑩Ending Control Step
この項目ではコントロールネットが影響を与え終わるステップを(%)を指定します。目的によって変更することをお勧めします。
⑪Preprocessor Resolution
ここでは処理された画像の解像度を変更できます。小さい値にするとコントロールネットの精度が低下するので、初期値(512)以上か③Pixel PerfectをONにしましょう。Pixel PerfectがONになっているとこの表示は消えます。
⑫Control Mode
ここではプロンプトを優先するか、コントロールネットの処理を優先するか決めます。
Balanced:初期のモードです。両方をバランスよく採用します。
My prompt is more important:プロンプトを重視したモードです。
ControlNet is more important:コントロールネットの処理を重視したモードです。
⑬リサイズモード(Resize Mode)
これは生成画像のサイズと参照画像のサイズが違う場合、自動的にサイズを変更してくれる機能です。ただし、基本的に生成画像と参照画像の縦横比はは合わせた方が良いです。
単純に変形(Just Resize):生成画像の大きさに合わせて処理された参照画像を変形させます。縦長画像を正方形で生成すると画像はつぶれてしまいます。

縦が圧縮されつぶれてしまっている
Crop and Resize:処理された参照画像を短辺に合わせてトリミング(切り取り)します。余った部分は削除され反映されません。切り取っても問題ない部分が残るときはこれを使います。

縦長なので上下が見切れている
Resize and Fill:処理された画像の縦横比のままに足りない部分を追加します。横長の画像を全て収めながら縦長にしたいときに使えます。多くの場合空白を追加するので問題ありませんが深度マップ(depth)の場合灰色の部分が追加されて生成に影響を与えるためお勧めしません。

⑭loopback:不明機能。公式でこの機能の説明はなくバッチ生成の時に使用するといわれていますがこれがなくてもバッチ生成は機能します。
その他の便利機能
参照画像の下にボタンがいろいろ並んでいますが、一部はウェブカメラ用の機能のようです。(持っていないので使えませんでした)
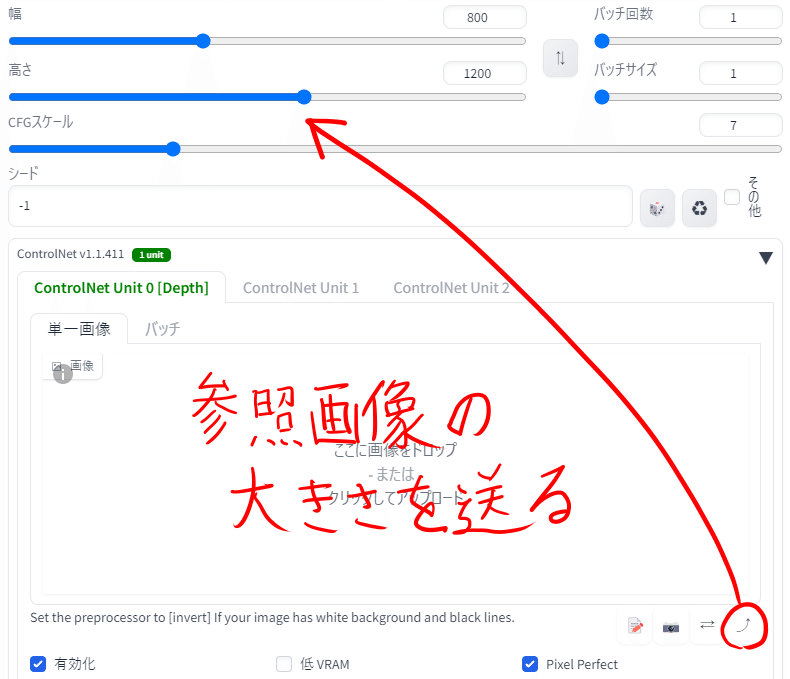
一番右の右上矢印は参照画像の大きさをそのまま生成サイズに送るボタンのようです。あまりサイズが大きくない画像の場合は便利です。

また、コントロールネットの一番下はコントロールネット用の設定を保存するプリセット機能があります。アイコンは左から現在の設定を記録する保存mark、現在指定されているプリセットを削除するごみ箱ボタン(プリセットがない場合は表示されません)、更新ボタンとなっています。
マルチコントロールネット
controlnetは複数同時に使うこともできます。WebUIの「設定」から「controlnet」を選択します。
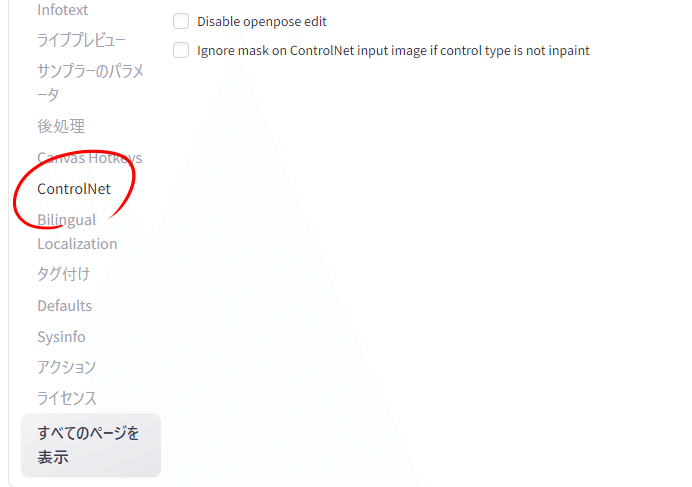
コントロールネットの設定の中に「Multi-ControlNet」「モデルのキャッシュサイズ」というものがあります。「Multi-ControlNet」では同時に使うcontrolnetの数、「モデルのキャッシュサイズ」では同時にVRAMに保持しておくcontrolnetモデルの数をしてします。モデルをキャッシュしておくとVRAMを消費しますが、fp16モデルは1つ700MB程度ですのでさほど増えませんし、キャッシュしていても生成が早くなるのは数%くらいですのでこちらはどちらでも大丈夫です。
変更したら「設定を適用」「UIの再読み込み」を押します。マルチコントロールネットが適用されると次のような表示になります。
4:各プリプロセッサの解説
Canny
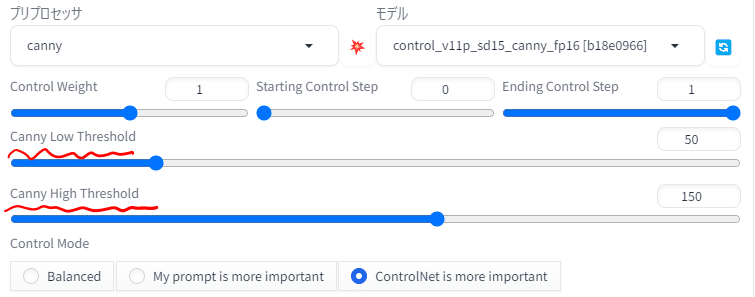
Cannyは画像の輪郭線を抽出して方法です。ほかのコントロールネットと違う点は一本の線を二本の線で挟んで認識することがあるということです。それによって処理された画像を手書きで修正するのが難しくなることがあります。

cannyにはしきい値を設定することができます。「Canny Low Threshold」では低い方のしきい値、「Canny High Threshold」では高い方のしきい値を設定できます。この値の大小を逆にして生成することはできません。しきい値の最大値は255ですがこの値を操作することで検出する線の量を制御できます。
例えばLowの値が低く、かつhighの値も低いと多くの線を検出します。線の検出量はhighの値を大きくしていくことで減少します。
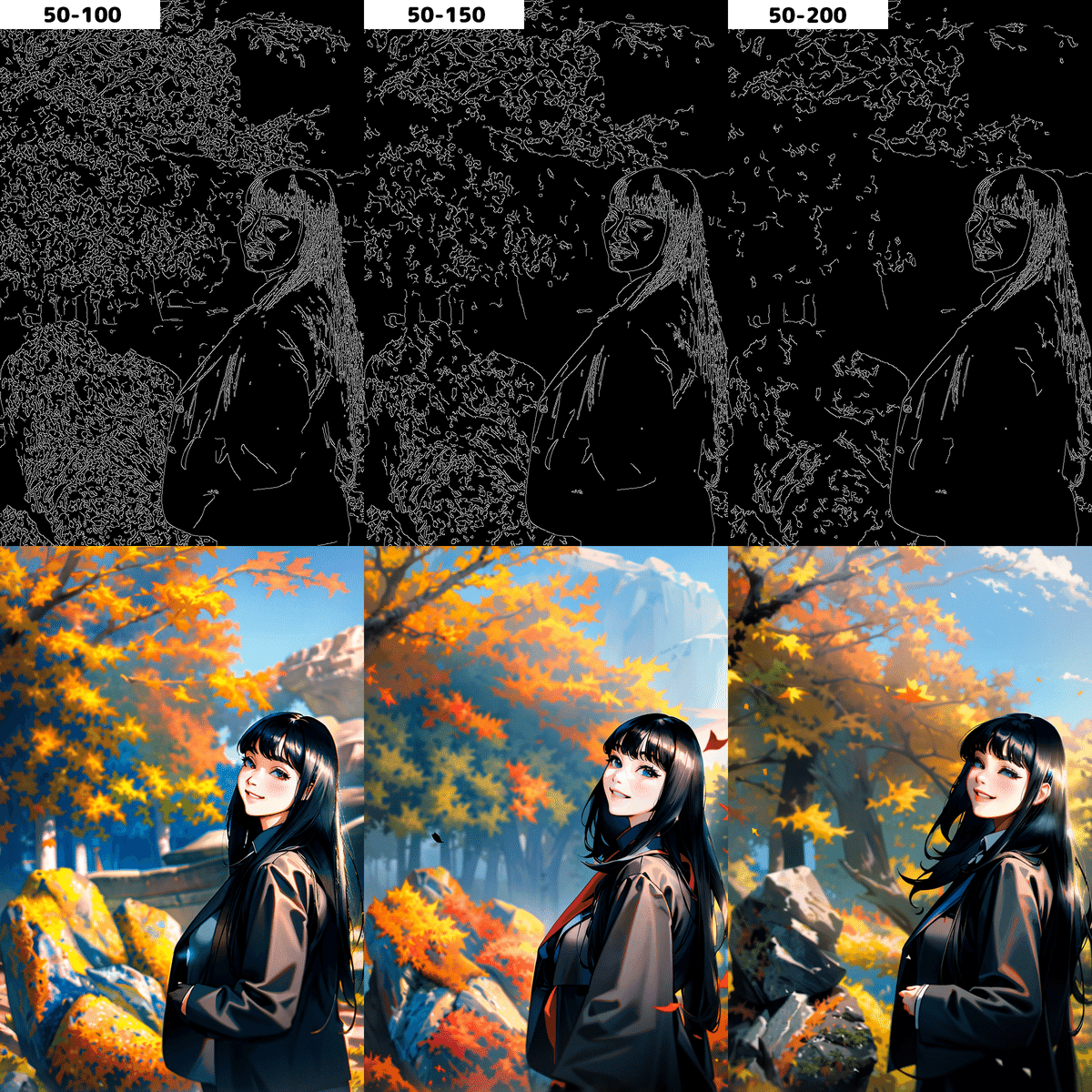
Lowの値を上げていくことでも検出する線の量は減少していきます。検出する線の減少は少なく見えますが生成する画像によっては割と変わっていることが分かります。

多くの場合、しきい値は初期値のlow-100、high200で大丈夫ですが、書き込みを意図的に増やしたい場合はどちらの値も下げ、逆に減らしたい場合は上げた方が良いと思われます。
しきい値を初期値で重み(Weight)と終了のタイミング(Ending Control Step)を0.3以上から0.1刻みで総当たりした表が下の画像になります。

全体的な構図は真似できていますが左腕の位置などが最後まで正確に反映されませんでした。そこでもっと読み取る量の多いlow-50、high100で試してみます。

処理する画像の描き込みを上げると左腕の位置までちゃんと反映することができました。表を見ると重み(Weight)が0.7以上、終了のタイミング(Ending Control Step)を0.3以上であればほとんどの場合で背景、人物ともにほぼ正確に配置されていると確認できました。
では、容姿を変えたい場合はどうでしょうか?一番左の元画像をもとに似た構図と、容姿の違う構図を作ってみました。
真ん中の画像はしきい値をlow-50、high100に、重み(Weight)が1、終了のタイミング(Ending Control Step)を1に設定しました。容姿を真似て生成する場合にはそのままで大丈夫です。
次に髪型をツインテール、服を白いコート、ピンクのマフラーに変更してみる場合はどうでしょうか?
しきい値はlow-50、high100、重み(Weight)は1で同じですが、終了のタイミング(Ending Control Step)を0.4に設定しました。線を正確に指定するので難しいのではと思いましたが、同じような長袖の服であれば問題なく変えれるようです。

Depth
深度マップ(depth)編 Depthは写真やイラストから奥行きの情報を読み取り画像生成に活用する方法です。

Depthには「depth_leres」「depth_leres++」「depth_midas」「depth_zoe」の4種類のプリプロセッサがありますが、どれも人体を読み取る精度は高いです。

4つの中では「depth_zoe」の精度が最も高く、背景があっても他より高い精度で再現してくれます。 「depth_zoe」で重み(Weight)と終了のタイミング(Ending Control Step)を0.3以上から0.1刻みで総当たりした表が下の画像になります。

画像によりコントロールネットの重み(Weight)と終了のタイミング(Ending Control Step)を微妙に変化すると思いますが、おおむねどちらも0.5以上あれば大丈夫です。 例えば、参照画像に忠実にしたい場合はどちらも高めで構いませんが髪型や服装などを変更したいときもあるでしょう。 その時は重み(Weight)を高めに設定して、終了のタイミング(Ending Control Step)を0.5など低めにすることで、最初はコントロールネットの影響を受けて大体の造形が決まり、あとはモデルの出力に任せるといったことができます。 画像はプリプロセッサを「depth_zoe」、重み(Weight)を1、終了のタイミング(Ending Control Step)0.5に設定し、髪形を少し変更したものです。

季節を春に、服装を白いコートに加えたい場合「depth_zoe」のまま、重み(Weight)を0.5に下げ、終了のタイミング(Ending Control Step)0.5に設定することでコントロールネットの影響を下げつつ、参照画像の雰囲気を損なわないまま季節感を変更することができます。

openpose
openposeは人体を棒人間のように処理してそれをもとに生成する仕組みです。人体だけを検知するので背景や持ってるものは反映されません。人の姿勢だけを真似たいときに便利です。また髪形や服装を変えやすいのも特徴です。
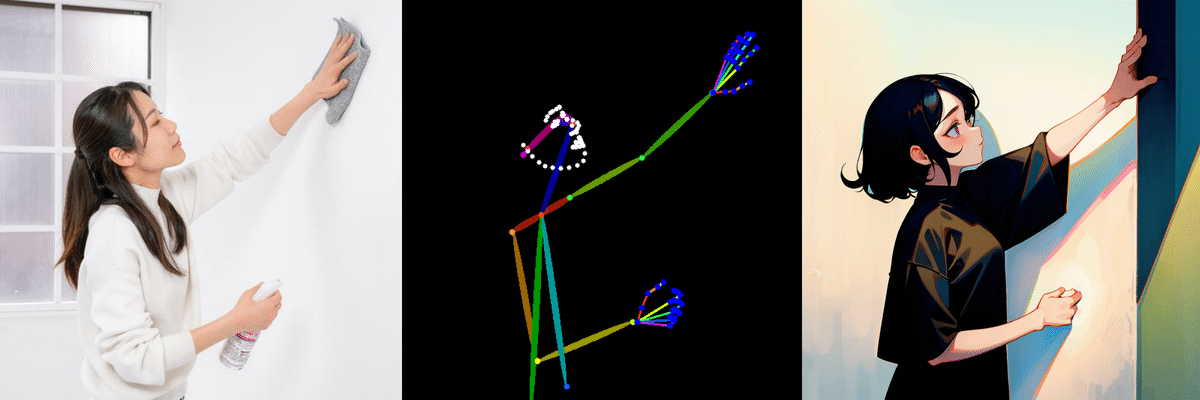
openposeにはプリプロセッサが「dw_openpose_full」「openpose」「openpose_face」「openpose_faceonly」「openpose_full」「openpose_hand」の6つあり、それぞれ影響範囲が違います。
「dw_openpose_full」と「openpose_full」は見た目がほぼ同じですがdwの方が後にできたので性能が上と評価されています。ポーズのみ参照したい場合は「openpose」、表情だけ参照したい場合は「openpose_faceonly」、ポーズと手を参照したいときは「openpose_hand」、ポーズと表情を参照したい場合は「openpose_face」を使います。
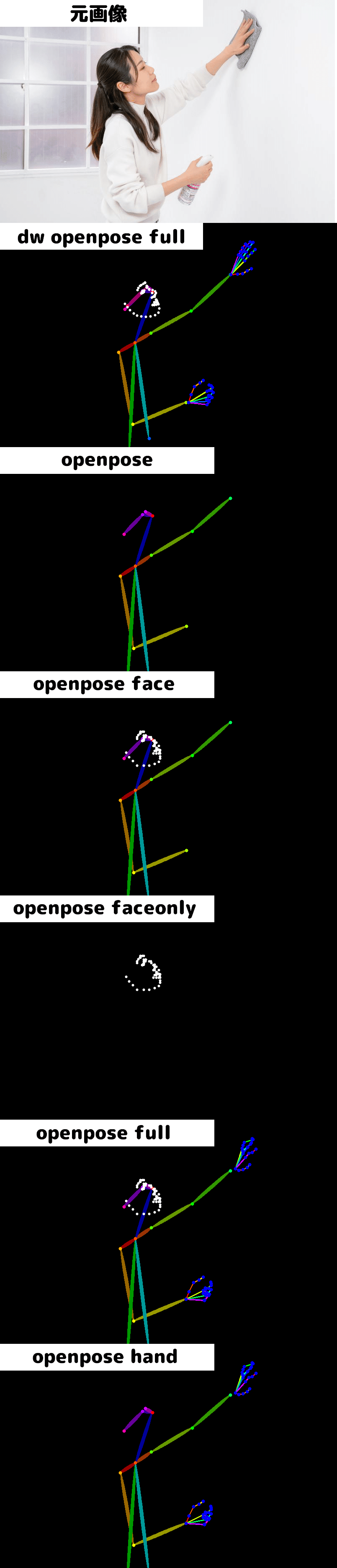
「dw_openpose_full」を例にモデルの重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。この表見てみるとポーズを参照し始めるのは重み(Control Weight)が0.5くらいからのようです。安定して生成するには0.8以上がおすすめです。制御終了ステップ(Ending Control Step)はあまり関係なく0.3からほぼそのまま出てくるようです。

openposeは髪の色や服装などを変えやすいですがパースのきいた構図が苦手です。だいたい、顔と手の位置(奥行き)が同じくらいの画像だとうまくいきやすいです。 上の画像はモデルの重み(Control Weight)を0.8、制御終了ステップ(Ending Control Step)を0.35、下の画像はモデルの重み(Control Weight)を1、制御終了ステップ(Ending Control Step)を0.8にして生成しました。

Lineart
Lineartはその名の通り、参照する画像の輪郭線を一本の線で処理する手法です。コントロールネットの中では参照画像への忠実度が高く、イラスト向きなのも特徴です。

Lineartには主に「lineart_anime」「lineart_anime_denoise」「lineart_coarse」「lineart_realistic」の4つのプリプロセッサがあります。
まず実写の場合の比較表を見てみましょう。animeとついている方は実写に不向きなのか特に「lineart_anime_denoise」の方ではほとんど境界を認識できていません。基本的に実写の場合は「lineart_realistic」でよさそうです。

では、イラストの場合はどうでしょうか。実写では反応の良くなかった「lineart_anime」「lineart_anime_denoise」で境界の検出がうまくいっています。「lineart_anime_denoise」の方が少し太い線を出力しますが両者に大きな違いはありません。イラストの場合であれば基本的にどれでも使えそうです。

lineartにはもう二つ、「lineart_standard (from white bg & black line)」「invert (from white bg & black line)」という線画用のプリプロセッサが用意されています。白背景に黒い線が引いてある線画を参照するときに使用します。見た目はほぼ同じですが「lineart_standard」はlineartの画像処理の仕組みを使用していますが、「invert 」の方は画像処理の仕組みを使用せず色をただ反転させているだけです。

「lineart_anime」を例にモデルの重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。lineartは安定性が高く、重み(Control Weight)が0.7くらいあれば、制御終了ステップ(Ending Control Step)はあまり関係なく0.3からほぼそのまま出てくるようです。

lineartは正確な線を参照するので人物の服装や髪形、背景を変更するのはやや苦手です。その代わり見た目を大きく変えることなく、色合いや画風を変更することができます。
例えばControl Weightを0.7、Ending Control Step0.5で参照元の出力とモデルと髪と服の色を変更してみることができます。また、手や男性などが苦手なモデルやLoRAの画風を使うために、いったんそれらが得意なモデルで出力してからコントロールネットで線画を抽出し、画風を適用させることもできます。

softedge
ソフトエッジはLineartやcannyよりおおざっぱに、Scribble/Sketchよりは服のしわや等の細部を拾うプリプロセッサです。輪郭線を太く処理するのが特徴です。

softedgeには「softedge hed」「softedge hedsafe」「softedge pidinet」「softedge pidisafe」の4つのプリプロセッサがあります。大きく違いがないように見えますが、「softedge_pidinet」が最も精度が良いようです。
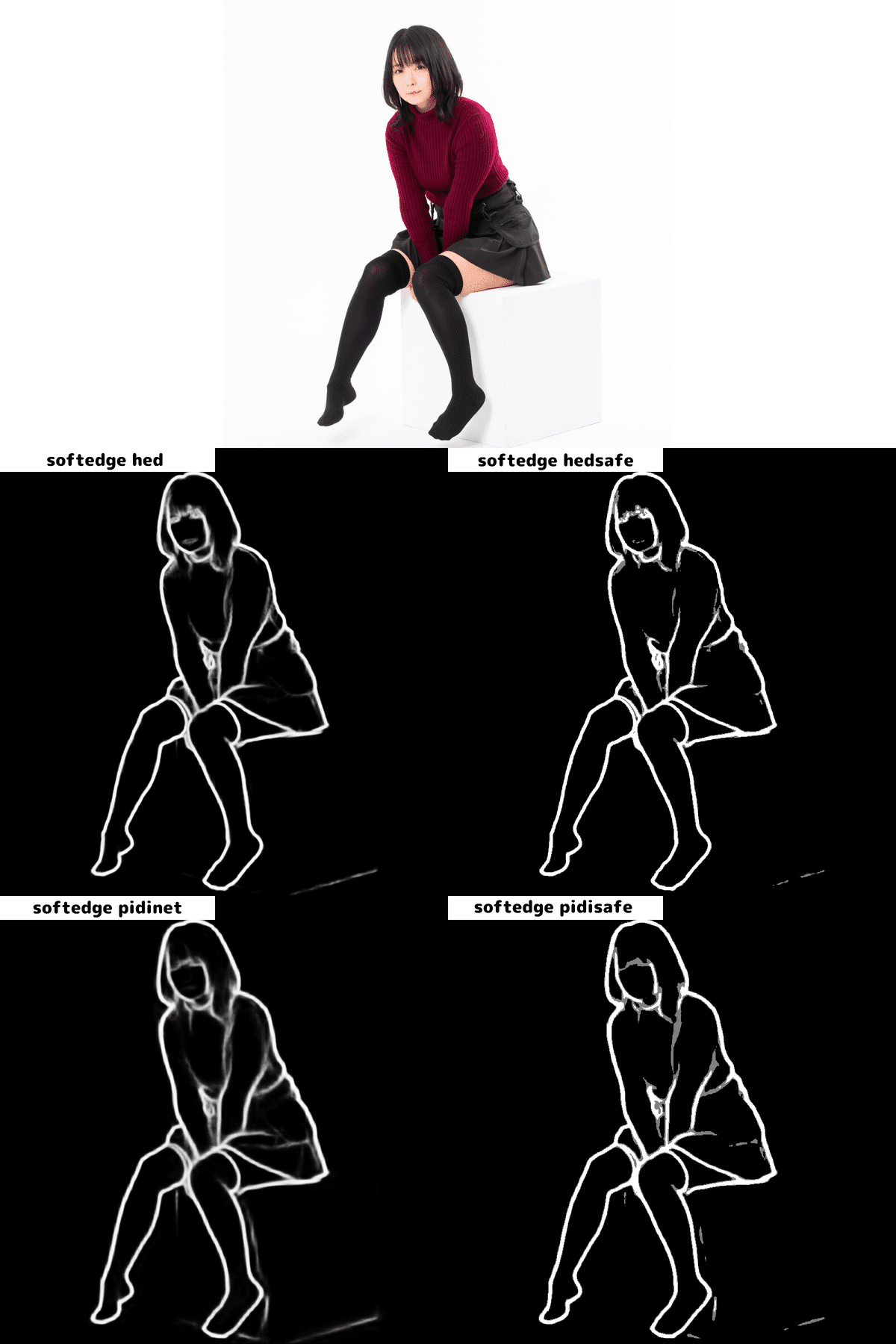
「softedge pidinet」でを例にモデルの重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。白背景も相まって非常に安定性が高いです。モデルの重み(Control Weight)が0.6以上あれば制御終了ステップ(Ending Control Step)はあまり関係ないようです。

Lineartやcannyよりおおざっぱとはいいますが輪郭線の太さがかなり太いので髪形や服装を大幅に変えることは難しいようです。その代わり、Lineartなどと同じように髪や服の色を変える、画風を変更することに使えそうです。モデルの重み(Control Weight)を0.6、制御終了ステップ(Ending Control Step)0.3に設定して髪の色と服の色を変えてみたものが下の画像です。

また、輪郭線を強調するのでLineartではつぶれてしまう、あるいは他のものと混ざりやすい指先などがしっかり識別できるので重みや制御終了ステップが早くても人体の細部まで再現が可能です。上の画像と同一設定で背景がある画像を参照してみました。同一設定のLineartでは指先などの細部が荒れますがsoftedgeではしっかり認識できているようです。

Scribble
輪郭線を抽出するプリプロセッサは参照画像に忠実なことが多いですが、要素を変更しにくいという欠点もあります。そこで役立つのが「Scribble」です。このプリプロセッサは輪郭線を非常に大まかに抽出するので姿勢などを変えることなく、細部を変更していくことが可能です。
SketchはT2I-Adapterに含まれるため別項で解説します。

Scribbleには「scribble_hed」「scribble_pidinet」「scribble_xdog」3つのプリプロセッサがあります。前者二つに大きな違いはありませんが、「scribble_xdog」はしき値を設定でき、線の検出量を制御することができます。下段はその数値を8,32,56と変化させたものになります。数値が少ないと線の量が多くなり、大きくしていくと線の量が少なくなるようです。制御したい要素の数や大きさなどに応じて変化させていくことができると思います。

「scribble_pidinet」を例にモデルの重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。scribbleは自由度が高い上に人物の輪郭の正確さもかなり最初から反映されているように感じます。例では白背景ですが背景のある写真などは苦手なようであり、Lineartと並んでこちらもイラスト向きといえるかもしれません。

Lineartとsoftedgeでは外見を大きく変更するのはやや難しめでしたが、scribbleでは比較的容易に可能です。今回はモデルの重みを0.6、制御終了ステップを0.3にして、髪型を金髪ツインテールに、服装を夏っぽくしてみました。Lineartやsoftedgeではショートパンツにならなかったり、そもそもツインテールにできなかったりしましたが、softedgeでは違和感なくできるようです。

Segmentation
Segmentationは人物や物体を決まった色に色分けするプリプロセッサです。物体の位置を正確に指定できるため構図などが決まっている場合は非常に強力です。その代わり顔や腕が体と同じ位置にある場合は、顔の向きや腕の位置が変わってしまうことがあります。

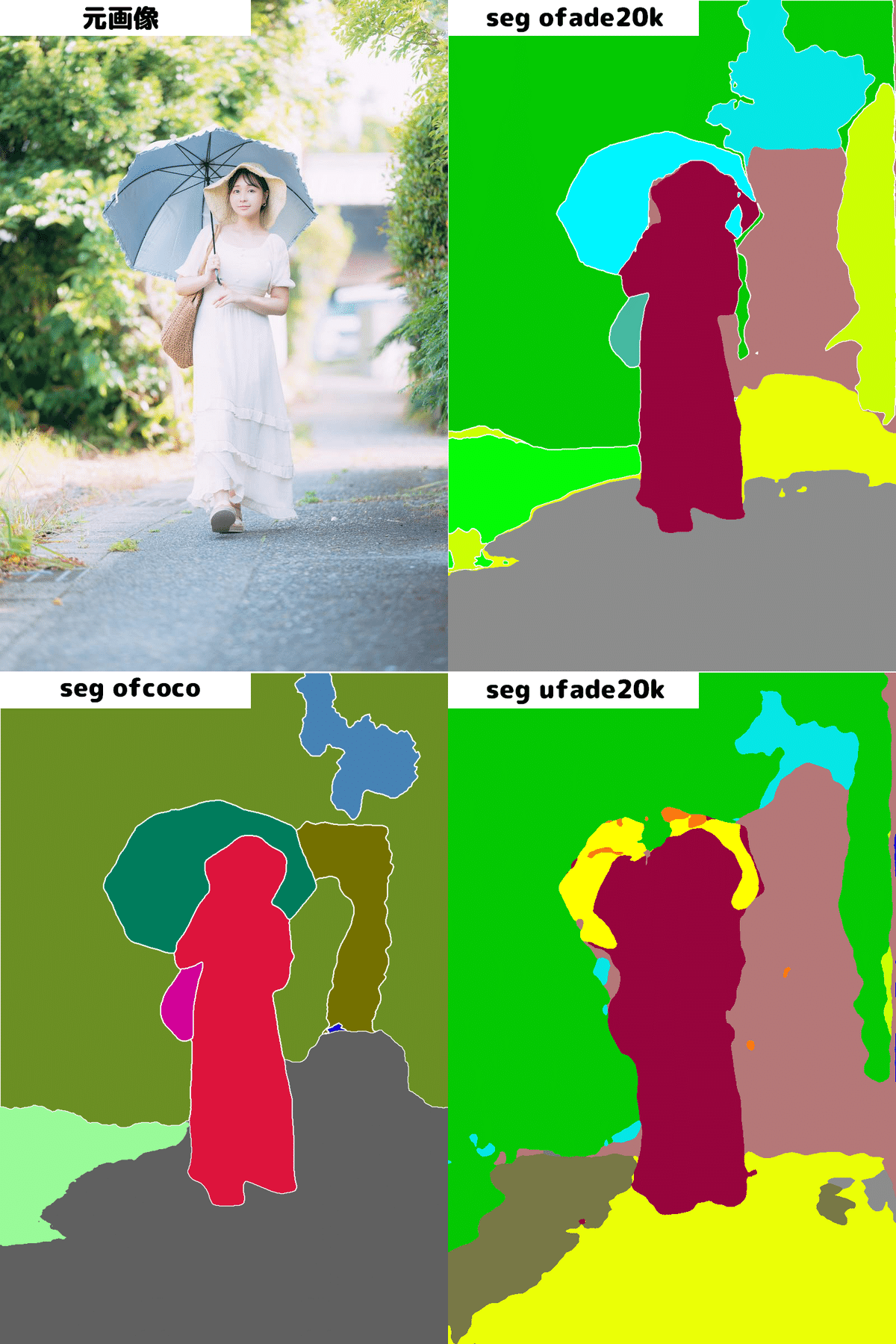
次にSegmentationのプリプロセッサを比較してみましょう。Segmentationには「seg_ofade20k」「seg_ofcoco」「seg_ufade20k」の3つがあります。
比較するとわかるのですが、岩の部分など検出の精度は「seg_ofcoco」が一番高いように感じます。
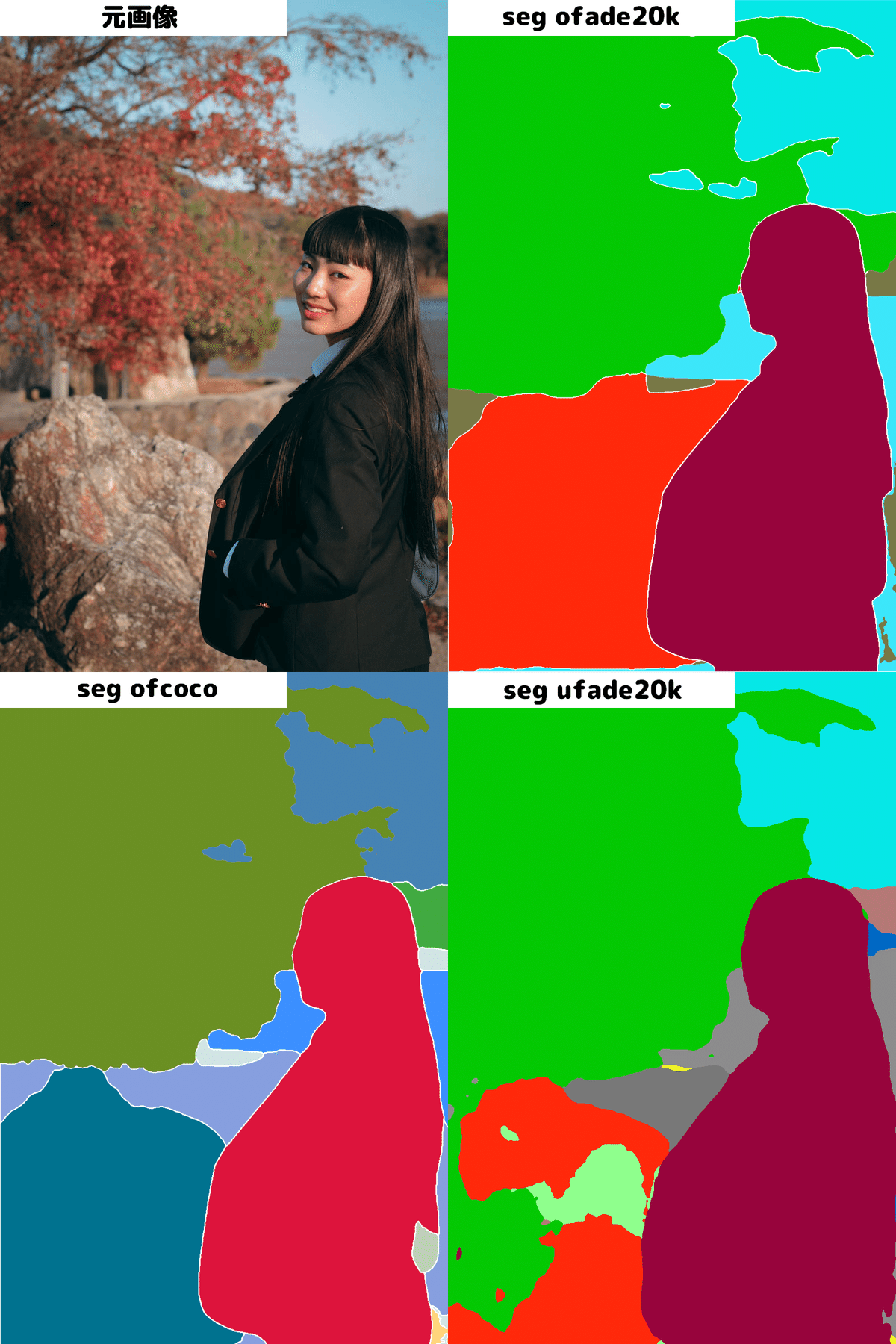
もう一枚比較があるのでこちらも見てみます。やはり「seg_ofcoco」は傘の全体的な検知がうまくいってます。背景がぼやけていても境界線に迷いがないのもわかります。
普通に画像を変換するだけならよいのですが画像に変更を加える場合、どの色がどの物体に対応しているか知らなければなりません。「seg_ofcoco」の色と物体に関する情報が見当たらなかったので、セグメンテーションを使って画像の構図を設定する際は「seg_ofade20k」を使うことをお勧めします。下の画像は「seg_ofade20k」の物体と色の対応表です。
「seg ofcoco」を例にモデルの重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。セグメンテーションは基本的に背景があっても問題なく人物と分離できるため、背景付きの画像でおすすめです。モデルの重み(Control Weight)が0.7以上あれば制御終了ステップ(Ending Control Step)はあまり関係がないと思います。

参照画像をもとに季節を春に、服装を着物に変えてみました。右の画像の画像は重みを0.7、制御終了ステップを0.6に設定したものです。腕の位置や顔の向きなどは参照されませんでしたが、画像の構図はしっかり受け継げています。枝や顔の向き、腕の位置が固定されないので他のプリプロセッサより自由度が高いことが分かります。

Reference
Reference(参考)という言葉の通り、画像の雰囲気を抽出するプリプロセッサです。画像の輪郭や配置などを参照するのではなく雰囲気といった概念的なものを画像に反映することができます。モデルを必要とせず、比較的2系やSDXLでも使いやすいです。
例では左の画像を参照し、プロンプトに「fire background」などを加えて右の画像を作ってみました。

Referenceには「reference adain」「reference adain+attn」「reference only」の三つのプリプロセッサがあります。また、Style Fidelity(スタイルの忠実度)という項目もあり、それぞれ違いがありますが、重み(Control Weight)が0.7以上から大きく変化するようです。使い勝手や構図が大きく変わらない「reference only」が一番おすすめです。

次にStyle Fidelity(スタイルの忠実度)の変化を見ていきます。プロンプトには「fruit background」を入れて元画像を参照画像に入れてみました。スタイルの忠実度を上げていくほど背景のフルーツの量は増えていきます。
ただ、忠実度が高すぎると元画像が背景としてそのまま出てくることがあります。雰囲気を参照したい場合と、元画像のまま画風を変更したい場合で忠実度を変えるとよいでしょう。

「reference only」を例に重み(Control Weight)を0.7、制御終了ステップ(Ending Control Step)を1.0、スタイルの忠実度(Style Fidelity)を0.75に設定しました。モデルの出力は同シード値でcontrolnetがオフの場合です。水の表現が大きく参照画像側に寄っていることが分かります。これによりモデルの素の出力では出ない表現をすることができます。

Tile/Blur
tileは一度画像をぼかした後、再度描きこみを増やすプリプロセッサです。通常のhiresよりも描きこみを増やせるためイマイチな画像のリメイクに使うことができます。
また、Blurは画像の背景等を主にぼかしてポートレート写真のような雰囲気を作り出します。
まずはBlurについてみていきましょう。使用するプリプロセッサは「blur gaussian」です。元画像をコントロールネットの参照画像に入れて「sigma」という項目でブラーの強さを調節します。下の画像がその比較表になっています。4ではほぼかかりませんが、12だと少しかかりすぎてしまいます。個人的には8~10程度の数字がおすすめです。

次に重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。重みはあまり関係なく、制御終了時のタイミングで微調整すると良いようです。

「tile colorfix」「tile colorfix+sharp」は描きこみ自体は増えますがあまり変化をかじられなかったので省略します。
次に「tile resample」と通常のhiresアップスケールの違いを見ていきます。一般的に描きこみを多くするのは「Latent」ですが、それよりもtileの方が詳細に描かれているのが分かります。

次に重み(Control Weight)と制御終了ステップ(Ending Control Step)を一覧表で出しました。Down Sampling Rateは4です。重みはあまり関係ないようですが、制御終了ステップが0.4くらい早いとモデルの絵柄の雰囲気が多く残るようです。逆に制御終了ステップが遅いと色味がよりシャープになっているように感じます。お好みで使い分けてください。

inpaint
inpaintとは生成した画像の一部にマスク(画像真ん中の半透明の白い部分)をして変更したいプロンプトを打つと変更してくれたり不要なものを消してくれたりする機能です。これにより一部が微妙だと思った画像を簡単に手直しできます。

inpaintには「inpaint global harmonious」「inpaint only+lama」「inpaint only」の三つがありますが、「inpaint global harmonious」は全体の色味が変わってしまうことが多々あるため使いづらいです。ですので後者2つについて解説していきます。
基本操作
inpaintを使うためにはマスクというものを使って参照する画像の帰る部分を指定しなければなりません。これはマウスやペンタブなどで塗ることによって使用できます。下の画像は空と雲の部分にマスクがかかった状態です。
①は戻るボタンです。直前に書いたマスクを取り消します。②は全部消すボタンです。画面上のマスクをすべて消去します。③はマスクを描くときのブラシサイズを指定します。塗る面積に合わせて調節してください。
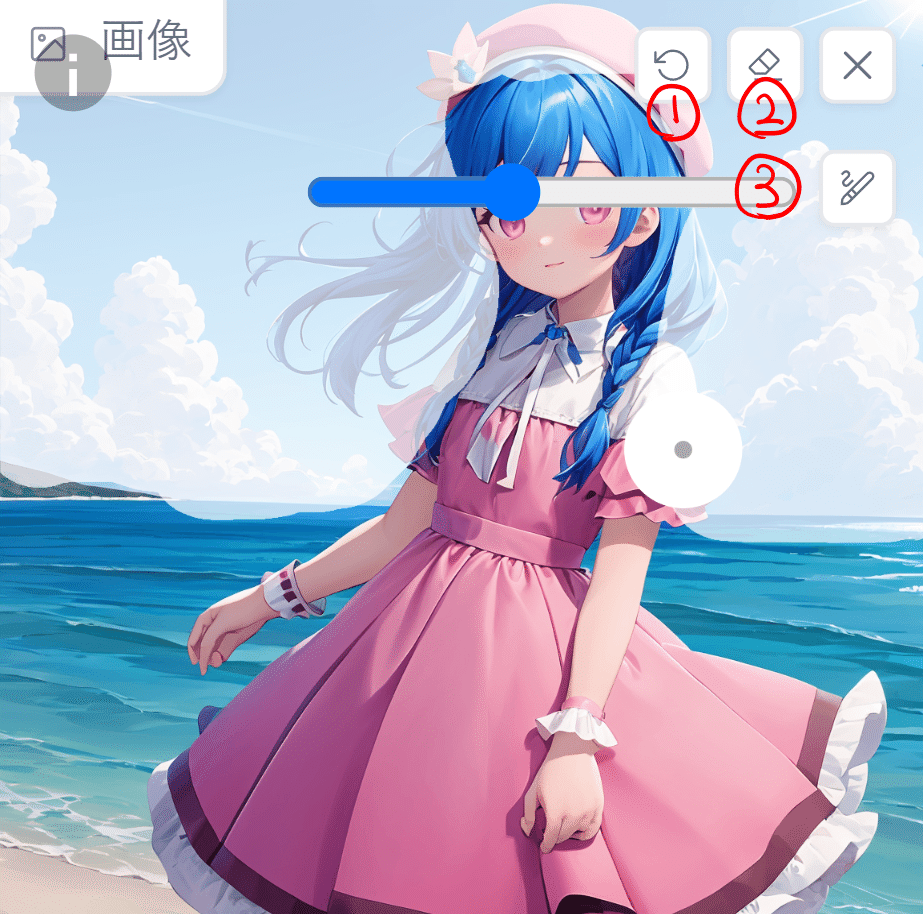
また左斜め上の「i」のマークを押すとショートカットを表示できます。
「Alt+マウスホイール」でキャンバスを大きくできます。
「Ctrl+マウスホイール」でブラシサイズを変更できます。
「R」で大きくしたキャンバスを元に戻せます。
「S」で全画面モードにします。
「F」キャンバスを移動させます。

実践編
・指の本数と長さを調節する
これが一番使えるかなと思います。プリプロセッサは「inpaint only+lama」を使います。使い方は消したい指と長さを調節したい指にマスクして生成するだけです。主に指の本数が多い場合に使いやすいです。

・不要なヘアリボンを消す
プリプロセッサは「inpaint only+lama」を使います。厳密にでもなくていいですができるだけリボンのある場所を狙ってマスクすると髪型が崩れにくいです。ネガティブプロンプトに「hair ribbon」を追加して生成するとリボンなしのポニーテールが出来上がります。

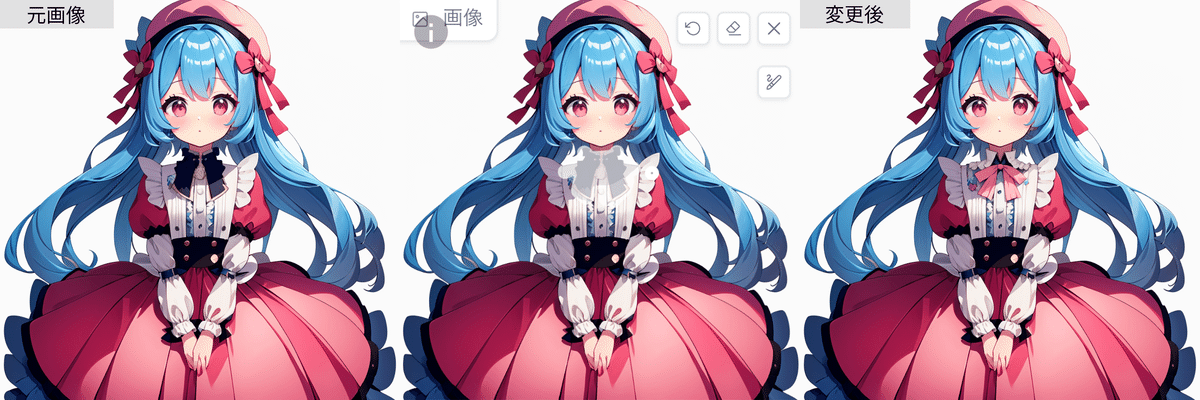
・胸元にリボンをつける
逆にリボンをつけ足したい場合はプリプロセッサは「inpaint only」を使います。胸元に指定するのでマスクを襟まで含めてあげると成功率が上がります。プロンプトに「pink ribbon」を追加して生成すると胸元にリボンをつけ足すことができました。
・背景を夕暮れに変更する
プリプロセッサは「inpaint only」を使います。背景を変えるときは髪などを巻き込んでしまうことが多いのでより元画像に忠実にしたい場合は髪を残すように慎重にマスクしましょう。マスクをしたらプロンプトに「sunset」などを入れて生成すると背景を変更できます。ただ「sunset」をプロンプトに入れて生成しましたがモデルによっては効かないこともありました。うまくいかない場合は別のモデルで試してみることも必要です。
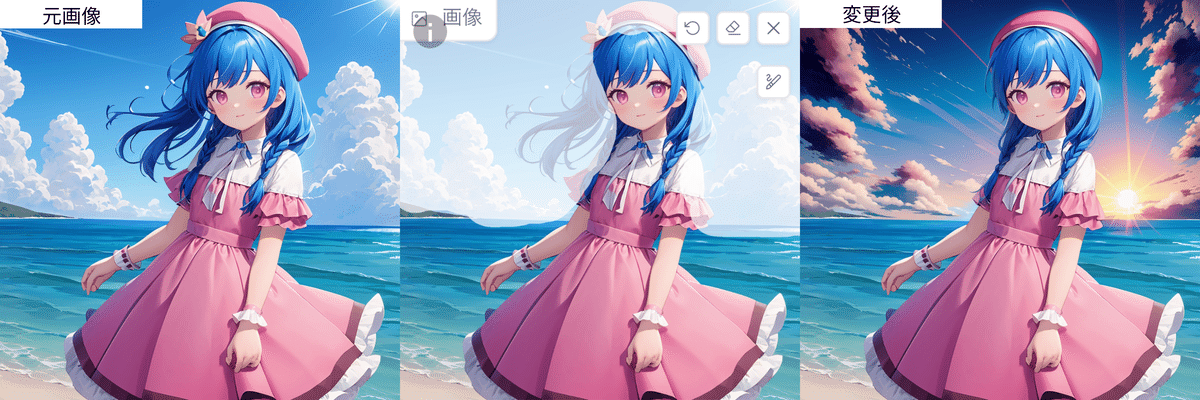
実践編
・segmentation + Dw openpose + inpaint
各種コントロールネットを活用した画像の修正ワークフローを紹介します。まずは元となる大まかな構図を出力します。

最初にごちゃごちゃした背景をsegmentationで窓と窓枠の形を整えます。色はsegmentationの項にあるカラーリストから「Windowpane(窓ガラス)」を選択しました。コーヒーカップも正しく認識できていなかったのでコップの形に塗りなおしました。

セグメンテーションで生成していると腕と手の位置が良いものがあったのでマルチコントロールネットの二番目にdw_openposeを指定し、人物の腕の配置と手を整えます。

最後にinpaintで赤丸の部分の違和感がある部分を消しました。窓枠にも違和感がありますがinpaintで直すには範囲が広いのでトリミングします。

完成した画像がこちらになります。

11月10日 更新
この記事が気に入ったらサポートをしてみませんか?