
メタプラットフォームズ:Q1決算直前 - 生成AI研究の成果が問われるのはまだ先のこと

2024年4月24日(火)の米国株式市場のクローズ後に、メタ・プラットフォームズ(Meta Platforms, Inc.)の2024年Q1(2024年1~3月)の決算発表が予定されています。
前回の2023年Q4決算では、売上高が前年同期比25%増の400億ドルを記録し、純利益は140億ドルに達しました。希薄化後のEPSは前年同期比で3倍以上の5.33ドルと極めて好調な業績を示して、決算発表後は大きく窓を開けて株価が大きく上昇しました。
この4月に入ってからは、米国株式市場はやや軟調に推移し、直近では幾つかの主要銘柄の決算が嫌気されたり、地政学リスクの不透明さから、テクノロジー銘柄を中心に多くの銘柄が売り込まれています。 そんな状況下で4月24日に迎えるメタ社の決算ですが、同社からはAIおよび生成AI関連のプレスリリースが相次いで発表されています。 自社開発のAIアクセラレータ「MTIA」のバージョン2の発表、そして最新の大規模言語モデル「Llama 3」、また更にはAIアシスタントの「Meta AI」の一般公開など、決算前にして矢継ぎ早にAIテクノロジーのエコシステムを世の中に向けて発表しています。これらは2023年Q4決算時でも言及されていたプロジェクトですが、これまで不透明であった同社のAIおよび生成AI関連技術のビジネスでの活用シーンが明らかになるなど、同社の目指すメタバースの実現にはまだまだ道半ばながらも、しっかりと将来を見据えた事業投資としての研究開発であることが示されたことは、投資家とのコミュニケーションが改善しつつあるものとして好感すべきものと考えています。
この投稿では、前回の決算を振り返りつつ、最近発表されたAIアクセラレータ「MTIA v2」と大規模言語モデル「Llama 3」の概要をまとめていますので、ご参考になれば幸いです。
1. メタ・プラットフォームズについて
(1)企業概要
説明不要かと思いますが直近の企業概要です。

(2)業績推移
売上と利益について、過去からの業績推移を以下に示します。


(3)事業セグメントについて
メタ・プラットフォームズの事業は、以下の3つのセグメントに分かれています。
(a)Family of Apps
Facebook、Instagram、Messenger、WhatsApp、Threadsなどのアプリケーションを通じて、ユーザーにコミュニケーションやコンテンツの共有、コミュニティ形成の機会を提供しています。また、広告主に対する広告販売を通じて収益を生み出しており、2023年度の売上実績は、売上全体の約98%を占める1,319億ドルとなります。
(b)Reality Labs
メタ社の長期ビジョンである「メタバース」の構築に向けて、仮想現実(VR)や拡張現実(AR)に関連する新たなプロダクトやサービスの市場投入を担うビジネスセグメントです。このセグメントにはMeta Questファミリー、Ray-Ban Metaスマートグラス、Meta Horizon Worlds、Meta Spark、Meta Quest Storeなどが含まれます。2023年度の売上実績は19億ドルと、全体の1.4%を占めるに過ぎないビジネスですが、同社の目指すビジョン達成のためには極めて重要な役割を担っているセグメントです。
(c)その他の売上
WhatsApp Paymentsのインフラ利用料やその他の収入を含み、2023年度の売上実績は11億ドルです。

2. 前期決算の振り返り
(1)2023年Q4決算ヘッドライン
(a)業績概観(四半期)
前回の2023年Q4の決算では、好調な業績を発表しています。四半期売上高は400億ドルで、前年同期比25%の増加を達成しました。純利益は140億ドルで、希薄化後の1株当たり利益は5.33ドルとなり、前年同期の3倍以上の成長を記録しました。同社の主力ビジネスであるFamily of Appsの売上は390億ドルで、前年同期比24%増。そして、広告売上も387億ドルで、前年同期比24%増と、すべての指標で強い成長を示しました。また、7兆円の追加自社株買い計画と同社初の四半期ごとの50セント配当を含む将来の株主還元計画を発表しました。
(b)アナリスト予想と実績
① EPS: アナリスト予想 4.97 対 実績 5.33

(クリックで拡大)
② 売上: アナリスト予想 392億ドル 対 実績 401億ドル

(クリックで拡大)
(2)2023年度通期決算ヘッドライン
(a)業績概観(通期)
2023年度の通期売上は1,349億ドルで、営業利益は467億ドルでした。2022年11月に発表された約11,000人の人員削減計画やオフィス施設の縮小計画とともに、組織のスリム化が進み、前掲の売上と利益のグラフで明らかなとおり、収益性が大きく向上しています。
主力の広告ビジネスでは、配信広告数の増加により前年度比で183億ドル(16%)の増加がありましたが、広告単価の低下によってその一部が相殺されました。2023年の広告配信数は前年度比で28%増加。製品全体の広告表示頻度の増加とユーザー数の増加が要因となって、全地域で広告インプレッションが増加し、その中でも特にAPACとその他地域での顕著に増加しました。広告単価は前年度比で9%低下し、特定地域やリールなどの収益率の低い製品の配信広告数の増加が主な理由となっています。
また全体として、2023年度の広告収入の伸びの背景には、特に中国市場や消費財、エンターテイメントやメディアの電子商取引を行うマーケターからの支出増が寄与しています。 尚、Family of Appsセグメントにおけるユーザーエンゲージメント及び広告収益に関する各種指標は以下の通りです。

(b)アナリスト予想と実績(通期)
① EPS: アナリスト予想 14.39 対 実績 14.87

(クリックで拡大)
② 売上: アナリスト予想 1,337億ドル 対 実績 1,349億ドル

(クリックで拡大)
3. 2024年Q1のガイダンスと予想
メタ社は、2023年度Q4の決算発表時に、2024年度Q1の売上ガイダンスとして、アナリスト予想の339億ドルを上回るレンジとなる345億ドルから370億ドルのガイダンスを発表しています。そして、今回2024年Q1決算を直後に控えた現在タイミングでのアナリスト予測については、以下の通りです。
(1)アナリスト予想とレーティング
(a)予想EPSと予想売上

(b)ウォールストリートのアナリストのレイティングス

(2)主な株価指標

※NTM … Next Twelve Month
尚、前述したFamily of Appsの各種指標については、これまで発表されてきたDAU、MAU、ARPU、MAPについては、2024年度以降、Form 10-Qでは報告されなくなる予定です。代わりに、DAPとARPPのみによって、ユーザーとのエンゲージメント状況や広告収益の遷移報告が行われることが、2023年度のForm 10-Kに記載されています。
4. 先端技術研究部門(FAIR)
今回紹介するメタ社のAIアクセラレータや大規模自然言語モデル、AIチャットボットについては、FAIR(The Fundamental AI Research)というチームが開発を担当しています。メタ社におけるAIの先端技術研究は、かつてヨシュア・ベンジオ氏、ジェフリー・ヒントン氏と共に2018年のチューリング賞を受賞し、ディープラーニングのゴッドファーザーの1人として著名なヤン・ルクン氏をヘッドとして迎えたFacebook AI Research(FAIR)という非営利組織が行ってきました。しかしながらその後の変遷を経て、2023年には現在のReality Labsという組織の下部組織となって活動を続けています。
Reality Labsは主に仮想現実(VR)、拡張現実(AR)、ミクストリアリティ(MR)の製品開発に焦点を当てており、新たな技術開発と市場導入を目指しています。かつては非営利の研究組織として、研究成果のオープンソース化を自社の営利目的より優先していた経緯がありますが、2023年に行われた組織更改により、研究成果の自社の営利プロダクトへの利活用が進められており、今回、あらためてFamily of AppsやMeta AIがLlama3を活用していることの公の発表がなされていました。
尚、メタ社が2023年度に支出した研究開発費は、前年比で3.15億ドル増の384.8億ドルに達しています。これらの研究対象には、メタバースの構築を含むAR、VR、MRデバイス、ソーシャルプラットフォーム用ソフトウェア、ニューラルインターフェースなどの基礎技術開発が含まれています。さらには、広告ツールの強化や広告配信、ターゲティング精度の向上、コンテンツ推奨のためにも投資が行われており、加えて、新製品の開発や既存製品の新機能開発のため、生成AIを含むAI、そして汎用人工知能(AGI)に向けた開発取り組みにも多額の投資を行っています。
蛇足ですが、その他のビッグテックの研究開発予算と並べてみると、メタ社の研究開発予算は3番目に多く、このように莫大かつ積極的に投資を行っていることがわかります。
アマゾン 約856億ドル
アルファベット 約437億ドル
メタ 約364億ドル、
アップル 約299億ドル
マイクロソフト 約275億ドル
エヌビディア 約87億ドル
テスラ 約40ドル
5. AIアクセラレータ「MTIA v2」
(1)MTIA v2の概要
メタ社は、AI推論の性能向上とコスト効率の改善を目指して、独自のカスタムシリコン「MTIA(Meta Training and Inference Accelerator)」の開発を進めています。初代MTIAチップはAIタスクの推論用に設計され、特にソーシャルメディアプラットフォーム内でのレコメンデーション・アルゴリズムや広告配信の最適化に利用され、一定の成果を出してきました。この成功を受けて、メタ社はさらなる性能向上を目指し、第2世代となる「MTIA v2」を開発しました。このMTIA v2は、初代モデルに比べて計算能力、メモリ容量、メモリ帯域幅が大幅に強化されており、より複雑な推論タスクを効率的に実現することが可能です。
この新たな「MTIA v2」の開発は、メタ社がNVIDIAのH100やB200/GB200といった高価で市場供給が限定的なGPUに依存せず、自社内のシステムに最適化されたハードウェアソリューションを組み込むための戦略的試みの一つとなっています。

(2)広告とSNSでの応用事例
MTIA v1は、フェイスブックやインスタグラム、その他Metaスタックのアプリケーションで広告やソーシャルネットワーキングの機能要素に利用される深層学習によるレコメンデーションモデル(Deep Learning Recommendation Model)に特化して実用化されていました。これに対し、パワフルになった新たなMTIA v2は、どのようなシーンで利用されるのでしょうか。
メタ社によると、MTIA v2はランキングモデルやレコメンデーションモデルに最適なコンピュート、メモリ帯域幅とメモリ容量のバランスに焦点を当てて設計されています。推論タスクでは、バッチサイズが比較的小さい場合でも高い利用効率を達成することが求められます。このため、一般的なGPUと比べて大容量のSRAMを搭載し、バッチサイズが制限されている場合でも高い利用率を提供することができます。また、同時作業量が多い場合には十分な計算量を提供することが可能です。
① ランキングモデルへの活用について
ランキングモデルは、検索結果、ニュースフィード、製品のリストなどでユーザーにとって最も関連性の高いアイテムを選定して順序付けるために使用されます。MTIA v2の特徴がこのランキングモデルの最適処理を支援しています。
高速処理能力: 大量のユーザーデータとアイテム属性をリアルタイム処理し、ユーザーの嗜好や行動に基づく最も適切なアイテムをランキングします。
深層学習の最適化: 深層学習に依存するランキングアルゴリズムの複雑な推論を高速に実行します。
スケーラビリティ: システム規模の増大に伴うランキング処理の負荷増加に適切に対応します。
② レコメンデーションモデルへの活用
レコメンデーションモデルは、ユーザーの過去の行動や嗜好、その他のコンテキスト情報を分析し、ユーザーが興味を持ちそうなコンテンツや製品を提案します。MTIA v2の特徴がこのレコメンデーションモデルの最適処理を支援しています。
パーソナライゼーション: 高度な計算によりユーザーごとにパーソナライズされたレコメンデーションを生成します。
リアルタイムデータの活用: ユーザー行動をリアルタイムに捉えて、即時にレコメンデーションのためのロジック処理を行います。
高いエネルギー効率: レコメンデーションで発生する膨大なクエリ処理において、消費電力効率の良いMTIA v2を使用することで運用コストを削減します。
(3)MTIA v2の技術的背景
(a)MTIA v1との比較
MTIA v2は、初代のMTIA v1と比較して多くの重要な改善が施されています。以下に主な技術的な改善内容を紹介いたします。
① コンピューティング能力
MTIA v1に比べて、MTIA v2では性能が強化された多くのプロセッシングエレメント(PE)を搭載しています。また、スパース性へのサポート機能を追加したことにより、MTIA v1の演算能力102.4 TFLOPSからMTIA v2では708 TFLOPSへと性能が向上しています。これによって複雑な計算のパフォーマンスが向上し、深層学習の推論タスクのレスポンス時間を短縮できるようになりました。
② メモリ容量とメモリ帯域幅の増加
MTIA v1では、各PEに128 KBのローカルメモリが実装され、オンチップに合計で128 MBのメモリが搭載されていました。一方、MTIA v2では、各PEのローカルメモリである高速SRAMが384 KBに増加されており、オンチップの共有メモリであるSRAMも256 MBに増強されています。これにより、各PEが独立してアクセスする際の競合を最小化するように管理されています。さらに、オフチップメモリには、最大204.8GB/sの帯域幅を持つLPDDR5メモリを128 GB搭載しており、大きなデータセットや長期依存性を必要とするアプリケーションにおけるメモリ帯域幅のパフォーマンスボトルネックへの対策が施されています。
③ 製造プロセスの進化
MTIA v1はTSMCの7nmプロセスで製造されていましたが、MTIA v2は5nmプロセスで製造されており、チップのサイズが421 mm²に拡大されています。これにより、より多くのトランジスタを搭載できるようになり、総ゲート数とFLOPSの増強が図られ、エネルギー効率の向上が期待されています。
④ エネルギー効率の向上
MTIA v2は、高い処理性能と省電力性能を両立できるように設計されています。MTIA v1は25WのTDP(熱設計電力)で動作していましたが、MTIA v2では90WのTDPでより高い性能を提供し、データセンターでの電力消費に関わる運用コストの削減と環境負荷の軽減が見込まれます。
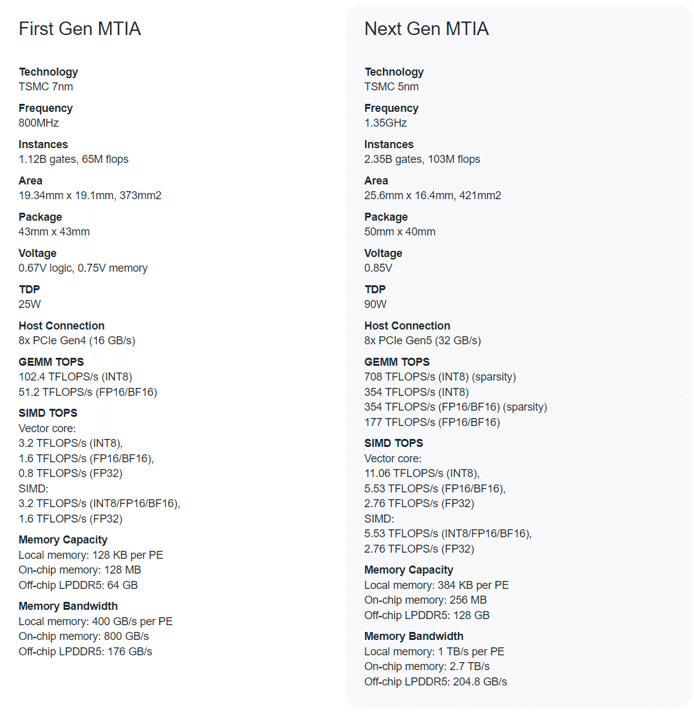
(b)チップのアーキテクチャと仕様の進化
MTIA v2では、MTIA v1からのアーキテクチャに大幅な変更が加えられており、これにより、より高度なAIモデルの処理に対応すると同時に、推論速度を大幅に向上させることができるようになっています。以下に、MTIA v2のアーキテクチャの概要を紹介いたします。
① プロセッシングエレメント(PE)の進化
MTIA v2は、64個のPEを搭載し、これらは8x8グリッドのレイアウトに配置されています。各PEは独自のRISC-Vベースのマイクロアーキテクチャに基づき、スカラーおよびベクトル計算を行うために最適設計されています。これにより、高度な数学的演算を効率的に行うことが可能であり、特に深層学習モデルで一般的なマトリックス乗算や畳み込み演算を高速に処理できます。また、PEは個別のメモリアクセスと計算タスクをより効率的に処理でき、AI推論のレイテンシを大幅に削減します。さらに、各PEはプログラマブルであり、異なるタイプのAIアルゴリズムに適応することができるため、多様なAIアプリケーションに対応する柔軟性を持っています。

② メモリアーキテクチャの強化
MTIA v2では、メモリアーキテクチャが大幅に強化され、PEごとのローカルメモリの拡張とともに、オンチップおよびオフチップのメモリリソースも増強されています。PE間で共有される256MBのオンチップメモリは、その帯域幅を最大限に活用してデータアクセス時間を短縮しています。さらに、オフチップには128GBの大容量LPDDR5メモリが搭載されており、より大きなデータセットを扱うことができます。
③ ネットワークオンチップ(NoC)の採用
MTIA v2は、チップ内部のデータ通信を管理するために高度なネットワークオンチップ(NoC)を採用しています。このNoCは、PE間のデータフローを最適化し、エンドツーエンドのデータ通信遅延を削減するための高帯域幅かつ低遅延の通信機能を提供します。また、PE間だけでなく、メモリブロックやI/Oインターフェースとの間でもデータを効率的にルーティングし、システム全体のバランスを最適化します。ネットワークはメッシュ、トーラス、ハイパーキューブなどの複数のトポロジー設計から成り立っており、これにより異なるワークロード特性に応じたデータのルーティング経路を最適化し、通信のオーバーヘッドを最小限に抑えることが可能です。NoCは動的なトラフィック管理とルーティング機能を備えており、ネットワークの輻輳をリアルタイムで検出し、回避することができます。この導入により、AIモデルの大規模な並列処理とデータ同期が可能となり、システムの全体的な性能向上に寄与しています。
④ エネルギー効率の向上
MTIA v2は、高性能ながらも低消費電力で運用が可能です。この高エネルギー効率は、改良された製造プロセスとアーキテクチャの最適化によって達成されています。5nmプロセスによる製造は、トランジスタ密度を高め、計算効率を向上させつつエネルギー消費を抑えることを可能にしています。
(c)インフラストラクチャへの統合
MTIA v2は、自社のAIインフラストラクチャへの実装を前提として開発されたものであり、企業全体のAI戦略に貢献する取り組みとなっています。MTIA v2は、メタ社のインフラやアプリケーションに高度に最適化されたハードウェアアクセラレータとして設計されています。このチップは、大規模なデータセンター環境でのエネルギー消費と物理的スペースの要求を削減しながら、処理能力を大幅に向上させることができます。データセンター内での効率的なスケーリングが可能となり、MTIA v2の導入により、そのコンピューティングプラットフォームの性能を最大化すると共に運用コストを含む電力消費を削減できます。また、MTIA v2は特に深層学習と自然言語処理に最適化されたハードウェアアクセラレータであり、メタ社で利用するAIモデルの展開と管理プロセスを改善することが可能です。この導入により、よりリアルタイムなデータ処理と高度な機械学習モデルをサポートすることが可能となります。
尚、メタ社は2023年に270億ドルの設備投資を行い、その大部分はデータセンターやサーバー、ネットワークインフラストラクチャへの投資でした。2024年には300億ドルから370億ドルの投資が予定されています。これらの膨大な設備投資に対して、MTIA v2導入によるコストダウン効果は、現状では限定的であるかもしれませんが、2024年1月に35万台のNVIDIA H100を発注したメタ社にとって、将来のコストダウンに向けた布石として進めていると思われます。
6. 大規模自然言語モデル 「Llama3」

(1)Llama3について
2024年4月18日に発表されたLlama 3は、2023年7月に公開された「Llama 2」の次のバージョンとして最新の大規模言語モデルです。無償で商用利用が可能であることから、Llama 2はプライベートなデータを学習させて独自の大規模言語モデルアプリケーションを開発する際の主たるターゲットとなっており、今回「Llama 3」としてアップデートされました。Llama 3は、Llama 2と同様にトランスフォーマーベースのアーキテクチャを採用していますが、より大規模で高品質なデータセットを使用して学習され、トークナイザーのサイズを128Kトークンに増加させ、より複雑な言語表現の理解を可能にしました。さらに、Grouped Query Attention(GQA)技術を導入することで計算効率と応答速度が向上しています。Llama 3のモデルは、8B(80億)と70B(70億)の異なるパラメータサイズが用意されており、教育、ビジネス、エンターテインメントなど幅広い分野での応用が期待されています。
(2)Llama 3のモデルバリエーション
Llama 3は、特定のタスクに特化して設計された各モデルを提供しており、それぞれ異なるパラメータ数を持っています。以下に、既にオープンソースとして公開されている主要な4つのモデルとその特徴を紹介します。これらのモデルは、小規模なプロジェクトから大規模なエンタープライズアプリケーションまで、目的とするタスクに応じて使い分けることができます。
(a)Meta-Llama-3-8B
約80億のパラメータを持つMeta-Llama-3-8Bは、Llama 3シリーズの基本モデルであり、広範囲の一般的な言語理解と生成タスクに適しています。このモデルは多様なNLPアプリケーションでの使用が想定されており、中規模のデータセットで効果的なパフォーマンスを目指しています。
(b)Meta-Llama-3-8B-Instruct
このバージョンも80億のパラメータを持ちますが、ベースとなる8Bモデルにインストラクション・チューニングが施されたモデルです。具体的な指示に従った応答生成を最適化することで、ユーザーの意図に沿ったアウトプットを提供することが可能です。例えば、ユーザーが明確な指示を与えた場合に最も適切な応答を生成することが期待されます。
(c)Meta-Llama-3-70B
700億のパラメータを持つ70Bモデルは、より深い言語理解と複雑な生成タスクに対応するために設計されています。この大規模なパラメータ設定により、高度な文脈の理解や細かいニュアンスの捉え方が向上し、特に大きなデータセットを用いた学習に最適です。ビジネスアプリケーションや対話システムなど、幅広い用途での使用が考慮されています。
(d)Meta-Llama-3-70B-Instruct
ベースとなる70Bのモデルのインストラクション・チューニング版で、さらに細かいユーザー指示に応じたタスク実行に特化してチューニングされています。これにより、非常に複雑な指示に対しても正確に応答する能力を持ち、高度なカスタマイズが求められるシナリオでの使用に適しています。

(クリックで拡大)
(3)Llama 3の応用アプリケーション
Llama3は既に、Metaが提供する「Meta AI」というAIアシスタントに統合され、Instagram、Facebook、Messenger、WhatsAppなどの主要なアプリケーションで実用化されています。このAIアシスタントは、主に北米やシンガポールなどの英語圏の数十カ国で利用されており、例えばInstagramのダイレクトメッセージで今日のディナーのおすすめを提案するようなシーンで活用されています。Meta AIの主な特徴と機能は以下の通りです。
(a)リアルタイムコミュニケーション支援
ユーザーがメッセージングアプリで会話を行う際、文脈に基づく返答や情報を提供でき、これには天気予報、ニュース、イベント情報などが含まれます。
(b)画像生成機能
特にWhatsAppとMeta AIでは、「Imagine」というベータ版の画像生成機能が提供されており、入力されたテキスト内容に基づく画像生成がリアルタイムで行われます。
(c)マルチモーダルな対話能力
Meta AIは、テキストだけでなく、画像や音声データを組み合わせて理解し、応答することが可能です。これにより、よりリッチなユーザー体験を提供できます。
(d)教育的・情報提供的役割
ユーザーがテキスト入力で質問する際、関連情報を提供します。これは、Google検索やBingなどの知識ベースからリアルタイムで情報を取得して実現しています。
また、Meta AI(https://www.meta.ai/)というウェブサイトでチャット型の質問応答アプリケーションを公開しており、そのバックグラウンドで動作している自然言語モデルはLlama3です(このサイトは、日本国内からは利用できないようです)。さらに、MetaはLlama3を新たなマルチモーダルなMetaスマートグラスやMeta Questシリーズなどへの活用研究も進めており、Metaのアプリケーションやハードウェア製品などサービス全体にわたって利用を進める方針を表明しています。
以下はMeta AIで利用可能な幾つかの機能のサンプルです。

シームレスに自然言語検索が可能(出典:メタ社)


(4)前バージョンのLlama 2との違い
Llama 3とその前身であるLlama 2を比較すると、いくつかの重要な改善点と新機能が確認できます。これらの新たな改善により、Llama 3はより複雑なタスクを効率的に処理し、用途への応用範囲を拡大することが可能となっています。主な違いを以下にまとめます。
(a)パラメータ数とモデルサイズ
Llama 3は最大で700億パラメータを持つモデルを提供し、さらに大きなモデル(400B)も開発中です。これにより、より複雑なデータセットを扱い、高度なタスクを効率的に処理できる能力が向上しています。
(b)トークナイザーの拡張
Llama 2のトークナイザーがサポートするトークン数は32Kトークンでしたが、Llama 3ではこれが128Kトークンに拡大されています。この変更により、扱える語彙が増加し、より多様な言語表現のエンベディングが可能になっています。
(c)Grouped Query Attention(GQA)の採用
Llama 3は、8Bおよび70Bの両方でGrouped Query Attention(GQA)を採用しています。GQAは、トークン間の相互作用を効率的に計算するための技術で、これによって大規模な入力データに対しても計算コストを抑えつつ高いパフォーマンスを維持することができ、推論効率の向上と、より長いシーケンスの処理能力の強化が期待できます。尚、Llama 2では70BモデルのみがGQAを採用していました。
(d)性能の最適化
Llama 3は、コンテキストの長さをLlama 2の2倍、8,192トークンに拡張しています。これにより、長い文脈のタスク処理能力が向上しています。
(e)トレーニングデータの量と質
Llama 3は、15兆以上のトークンで事前学習されており、容量はLlama 2の7倍、含まれるプログラムコードも4倍に増加しています。データセットは30言語以上をカバーする高品質の非英語データも5%以上含むことで、多言語性能の向上が図られています。
(f)データフィルタリングと品質管理
トレーニングデータの品質を確保するために、新たに開発されたヒューリスティック・フィルター、NSFWフィルター、セマンティック重複排除アプローチ、テキスト分類器を用いたデータフィルタリングパイプラインが導入されています。これらのフィルターによって、データの品質を予測し、高品質なデータのみをモデルトレーニングに利用するよう、トレーニング前のデータ処理設計がなされています。
(g)トレーニングの並列処理
モデルのトレーニングは、データ並列化、モデル並列化、パイプライン並列化を組み合わせたアプローチで最適化され、GPUクラスタ上での計算効率が大幅に向上しています。
(h)ファインチューニングの改善
Llama 3では、特定の用途やタスクに合わせたインストラクションファインチューニングが強化されています。教師ありファインチューニング(SFT)、拒絶サンプリング、近接ポリシーファインチューニング(PPO)、直接ポリシーファインチューニング(DPO)のテクニックが活用され、モデルの指示理解と適切な応答能力が向上しています。
(i)評価と改善
Llama 3は、実世界のシナリオに基づくパフォーマンスの最適化が行われています。そのため、高品質な人間による評価セットが開発されています。この高品質な人間評価セットとは、モデルやアルゴリズムのパフォーマンスをより正確に測定するために利用される実際の人間のアノテーターが提供する評価データセットです。高品質な人間評価セットは、多様なプロンプト、データ品質管理、詳細なアノテーション、専門知識を持つアノテーターによるパフォーマンス品質の管理、比較とベンチマーキング、改善と最適化といった特徴を持ち、これらの高品質な評価セットを用いることで、モデルの実用性、信頼性、および応用可能性のレベルをより把握し、改善につなげることができるようになります。
(5)Llama 3のプラットフォーム
Llama 3を利用するためのインフラとして、AWS、Microsoft Azure、Google Cloud、Hugging Face、Kaggle、NVIDIA NIM、Databricks、Snowflake、IBM WatsonXといった主要なクラウドプラットフォームとモデルAPIプロバイダーでの利用が予定されています。また、Llama 3ベースのモデル開発やアプリケーション開発をサポートする主要なフレームワークやツールとしては、Hugging Face Transformers、PyTorch、TensorFlow、Google Colab、LangChain、MLflowなどが挙げられています。
(6)今後の開発
Metaは、Llama 3のさらなる機能強化とパフォーマンス向上を目指したいくつかの開発プロジェクトを計画しています。これらのプロジェクトは、以下のような進化を予定しています。
(a)Llama 3の400Bモデルの開発
現在、Metaがトレーニングしている最大のモデルとなるのがLlama 3の400Bモデルです。この4000億以上のパラメータを持つモデルは、非常に高度な言語処理能力と複雑なタスクへの適応能力を備えており、医療、法律、科学研究など、専門的な分野での応用が期待されています。
(b)多言語・多モーダルのサポート
多言語対応及びマルチモーダル化への進化が計画されています。これにより、多様な言語やテキストだけでなく、画像や音声などのマルチモーダルなデータの理解と生成の能力が向上します。
(c)より長いコンテキストの扱い
より長いコンテキストを扱えるようになり、複雑な会話や文脈をより深く理解する能力を強化することが目標です。
(d)パフォーマンスの強化
推論効率と処理速度をさらに向上させ、リアルタイムアプリケーションでのパフォーマンスを実現すること。
(e)新機能の追加
コーディング能力の改善、詳細な推論タスクの能力強化、その他の新機能の追加が予定されています。
(f)アクセシビリティの向上
より多くの開発者や研究者がLlama 3を利用できるように、さまざまなプラットフォームでの利用を可能にすること。
(g)持続的なリリース
ユーザーや開発者からのフィードバックを逐次反映させ、定期的に新しいバージョンの「Llama 3」をリリースし、モデルを改善し続けること。

(クリックで拡大)
以上です。
御礼
最後までお読み頂きまして誠に有難うございます。 今後ともどうぞよろしくお願いいたします。
だうじょん
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?