
AzureVMをオートスケーリングさせてみますかな、意図的に

はい、今回は Azure仮想マシン(の数)を意図的に増やしたり(スケールアウト)、減らしたり(スケールイン)してみようと思います。
Azure Virtual Machine Scale Sets では、負荷分散が行われる VM のグループを作成して管理することができます。 需要または定義されたスケジュールに応じて、VM インスタンスの数を自動的に増減させることができます
公式ドキュメント:仮想マシン スケール セットとは
AWS の場合では、こちらの記事で近しいことを紹介しました。
今回はこれとは若干異なりローリングアップデートではありません。
ちなみに、これらの記事のテンプレートでは実はムダに『スケール セット(VMSS)』を記述していたんですね。
なので、これらのテンプレートからデプロイされた VMSS のリソースでは、手動でスケールアウト/スケールインは可能なのですね。

この画像(Azure portal )の『 インスタンス数 』を変更すると、その数に従って増減します。
ただ、それだと面白くないので、増減の条件をあらかじめ指定して、その条件の状態を作り出し(この意味では手動ではありますが😅)、状態の変化を見たいと思います。
もちろん、今回もリソースは ARM テンプレートで作成します。
🔵前提
こちらの記事のテンプレートに追記します。
もしくは、仮想マシンインスタンスをWebサーバー化させた記事のテンプレートに追記します。
後者の方が、デプロイした後少し面白味がありますね。
追記するリソースは、『 Microsoft.Insights/autoscaleSettings 』です。
![]()
公式ドキュメント:
microsoft.insights autoscalesettings
ARM テンプレートを使用して Linux 仮想マシン スケール セットを作成する
このリソースに、設定を記述することで

このような、VM ( Ubuntu ) の CPU 使用率が上昇して「処理が厳しくなったよ~」をトリガーにスケールアウト、「落ち着いてきたから大丈夫だよ~」をトリガーにスケールインさせることにします。
🔵リソースの記述
以下の記述をテンプレートに追記しました。
{
"type": "Microsoft.Insights/autoscaleSettings",
"apiVersion": "[variables('AutoscalesettingsApiVersion')]",
"name": "[variables('autoscaleSettingsName')]",
"location": "[variables('location')]",
"dependsOn": [
"[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('vmssName'))]"
],
"properties": {
"name": "[variables('autoscaleSettingsName')]",
"targetResourceUri": "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('vmssName'))]",
"enabled": true,
"profiles": [
{
"name": "Profile1",
"capacity": {
"minimum": "2",
"maximum": "10",
"default": "3"
},
"rules": [
{
"metricTrigger": {
"metricName": "Percentage CPU",
"metricResourceUri": "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('vmssName'))]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "PT5M",
"timeAggregation": "Average",
"operator": "GreaterThan",
"threshold": 60
},
"scaleAction": {
"direction": "Increase",
"type": "ChangeCount",
"value": "1",
"cooldown": "PT1M"
}
},
{
"metricTrigger": {
"metricName": "Percentage CPU",
"metricResourceUri": "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('vmssName'))]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "PT5M",
"timeAggregation": "Average",
"operator": "LessThan",
"threshold": 30
},
"scaleAction": {
"direction": "Decrease",
"type": "ChangeCount",
"value": "1",
"cooldown": "PT1M"
}
}
]
}
]
}
}◻全体像
まず、一番粗い粒度で全体を見てみます。
"properties" が記述の肝です。

◻"properties" の全体像
"properties" を深堀すると、"profiles" が記述の肝であることがわかります。

◻"properties" > "profiles" の全体像
"profiles" を深堀すると、「 Profile1 」というものだけが見えてきました。
これは私が "name" で指定した任意の記述(値)ですので、汎用的なものではありません。

◻"properties" > "profiles" > "Profile1" の全体像
ようやく重要な(核となる)部分が見えてきました。
"capacity" と"rules" が今回追記する中核的な存在の記述の部分です。
◻"properties" > "profiles" > "Profile1" > "capacity"

今回は、
"minimum": "2",
"maximum": "10",
"default": "3"と設定しました。
ざっくり言うと、『 最低 2台(インスタンス)でスケールセットを構成し、最大 10台(インスタンス)まで増加することができる 』といった感じです。
参考:ScaleCapacity object
Azure portal から確認すると、『 インスタンスの制限 』の部分です。
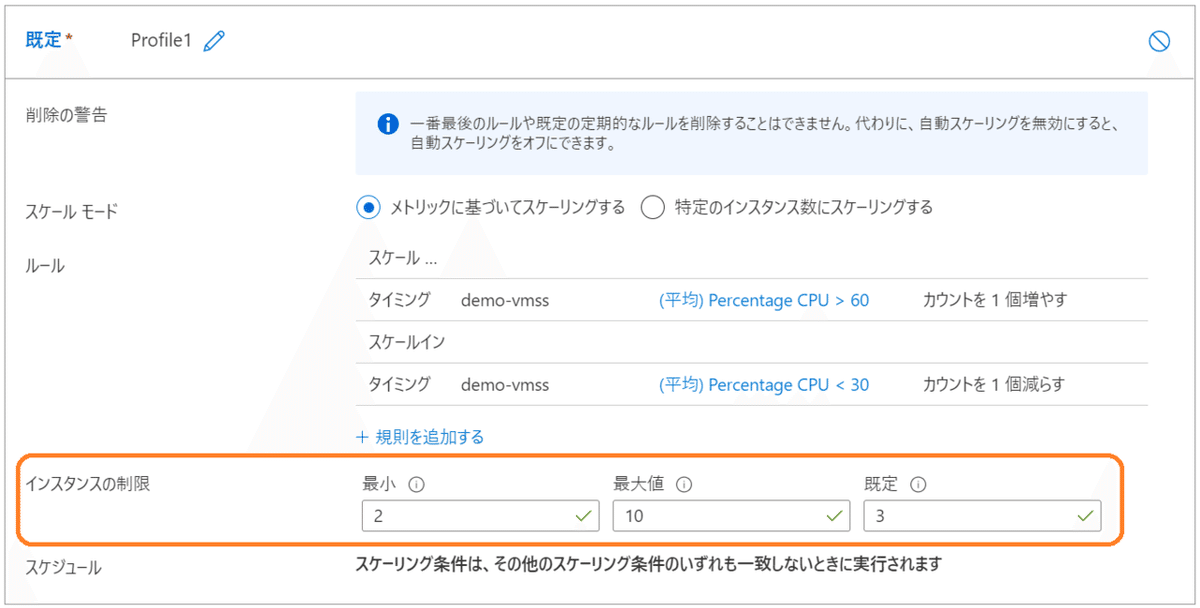
◻"properties" > "profiles" > "Profile1" > "rules"
Azure portal から確認すると、『 ルール 』の部分です。
今回は、2つルールを指定しています。
スケールアウトとスケールインをそれぞれ 1つずつです。

それぞれのルールに
"metricTrigger":
"scaleAction": を記述するのですが、
スケールアウトの場合、"scaleAction": > "direction" の値を『 Increase 』に
"scaleAction": {
"direction": "Increase", 👈
"type": "ChangeCount",
"value": "1",
"cooldown": "PT1M"
}スケールインの場合、『 Decrease 』と記述します。
"scaleAction": {
"direction": "Decrease", 👈
"type": "ChangeCount",
"value": "1",
"cooldown": "PT1M"
}それぞれ条件を満たした場合に、インスタンスを1つ増やす/減らすという指定になっています。
この条件の部分が『 "metricTrigger" 』にあたり、CPU 使用率が 60%を超えたらスケールアウト、30%を下回ったらスケールインという感じになっています。
なお、今回は CPU 使用率をトリガー(条件)にするので、"metricName": "Percentage CPU" としています。
◆スケールアウト
"metricTrigger": {
"metricName": "Percentage CPU", 👈メトリックを指定
"metricResourceUri": "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('vmssName'))]",
"timeGrain": "PT1M",👈メトリックの単位収集期間、今回は1分
"statistic": "Average", 👈メトリックの単位収集期間での集約方法、今回は平均
"timeWindow": "PT5M",
"timeAggregation": "Average", 👈収集されたメトリックを平均で集計
"operator": "GreaterThan",
"threshold": 60 👈
}
◇スケールイン
"metricTrigger": {
"metricName": "Percentage CPU",
"metricResourceUri": "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('vmssName'))]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "PT5M",
"timeAggregation": "Average",
"operator": "LessThan",
"threshold": 30
}参考:
MetricTrigger object
ScaleAction object
自動スケール ルールの条件
Azure Monitor のサポートされるメトリック > Microsoft.Compute/virtualMachineScaleSets
◻関連する追記した "variables"
"AutoscalesettingsApiVersion": "2015-04-01"
"autoscaleSettingsName": "[concat(parameters('EnvironmentName'),'-ASS')]"の二つを追記してリソースから参照させています。
なお、この二つはベタ書きしてしまっても問題ないですし、値もこれでなく任意のもので全然問題ありません。
🔵スケーリング実行
リソースをデプロイし、想定する動きをするか確認します。
負荷をかける
片方の VM(インスタンス)の CPU 使用率を意図的に100% 程度に上昇させます。

デプロイされた時には、2 台のインスタンスだけが存在しますので、今回は、インスタンス ID が『 2 』の VM にログインし、以下のコマンドを実行しました。
azureuser@demo-vmss000002:~$ yes > /dev/null少し待つと、

うわ~、一気に CPU 使用率が上がってほぼ 100% 貼り付き状態になりました。
そして、

1台インスタンスが増えました。
平均 CPU使用率60%を超えた状態が続いたので、スケールアウト発動です。
負荷を戻す
再度インスタンス ID が『 2 』の VM にログインし、Ctrl + C で先ほどのコマンドを停止させました。
少し待つと、

ふぅ~良かった、CPU 使用率が一気にほとんど使われていない状態に戻っていきました。
そして、

先ほど増えたインスタンス ID が『 4 』の VM が、平均 CPU使用率30%を下回る状態が続いたので、スケールイン発動で消滅しました。
ということで、想定通りの動きが確認できました。
🟠今回はここまで 🔚
いかがだったでしょうか?
実際に運用で使う場合、特殊なケースを除き手動でスケーリングを行うことは基本的になく、この記事のように何かしらの事前定義したトリガーに従って行うことになると思います。
システム運用においても自動化は当然大事ですね。
最後までお読みいただきありがとうございました 😊
▶ 続けて読むのにおススメな記事
この記事が参加している募集
もしこの記事が何かの参考になったもしくは面白かったという方は、応援していただけると大変嬉しいです😊 これからもよろしくお願いします。