
「Pythonではじめる異常検知入門」を寄り道写経 ~ 第7章「異常検知の実践例」①ホテリングのT²法

第7章「異常検知の実践例」
書籍の著者 笛田薫 先生、江崎剛史 先生、李鍾賛 先生
この記事は、テキスト「Pythonではじめる異常検知入門」の第7章「異常検知の実践例」の 7-1-1 項および 7-1-3 項の「データが正規分布に従うことを仮定した異常検知」について、通称「寄り道写経」を取り扱います。
テキストの自動車データをお借りしてホテリングの$${\boldsymbol{T^2}}$$法を実践します!
ではテキストを開いて異常検知の旅に出発です🚀

このシリーズは書籍「Pythonではじめる異常検知入門」(科学情報出版、「テキスト」と呼びます)の異常検知の理論・数式とPythonプログラムを参考にしながら、テキストにはプログラムの紹介が無いけれども気になったテーマ、または、テキストのプログラム以外の方法を試したいテーマを「実験的」にPythonコード化する寄り道写経ドキュメンタリーです。
はじめに
テキスト「Pythonではじめる異常検知入門」のご紹介
テキストは、2023年4月に発売された異常検知の入門書です。
数式展開あり、Python実装ありのテキストなのです。
Jupyter Notebook 形式のソースコードと csv 形式のデータは、書籍購入者限定特典として書籍掲載のURLからダウンロードできます。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「Pythonではじめる異常検知入門-基礎から実践まで-」初版、著者 笛田薫/江崎剛史/李鍾賛、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
第7章 異常検知の実践例
Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
テキストのこの章では、次の3種類の異常検知をPythonで実践します。
① ホテリングの$${\boldsymbol{T^2}}$$法
・非時系列データが正規分布に従うと仮定する場合の異常検知
② One-Class SVM
・非時系列データが正規分布を従うと仮定しない場合の異常検知
③ 時系列データの異常検知
・残差が正規分布に従うと仮定する場合の異常検知
この記事は ① の非時系列データが正規分布に従うと仮定する場合の異常検知の寄り道写経を行います
テキストが利用するデータを引用させていただき、実装方法やパラメータを変えて、ホテリングの$${\boldsymbol{T^2}}$$法に近づきたいと考えています。

インポート
### インポート
# 数値・確率計算
import pandas as pd
import numpy as np
import scipy.stats as stats
# 距離計算
from scipy.spatial import distance
# 機械学習
from sklearn.svm import OneClassSVM
# 描画
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import seaborn as sns
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')Google Colab をご利用の場合は「描画」箇所を以下のように差し替えてください。
!pip install japanize_matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import japanize_matplotlib
import seaborn as sns
データの読み込み
R 言語の標準データセットに含まれる「Speed and Stopping Distances of Cars」を利用します。
次の R データセットサイトの No. 462 です。
【引用元サイト】
Webサイトから直接pandasのデータフレームへ読み込みします。
### データの読み込み
# URLの設定
URL = r'https://vincentarelbundock.github.io/Rdatasets/csv/datasets/cars.csv'
# ファイルをpandasのデータフレームに読み込み
df = pd.read_csv(URL, usecols=[1, 2])
# データフレームの表示
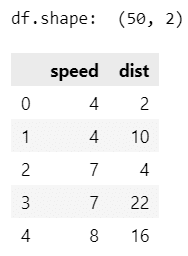
print('df.shape: ', df.shape)
display(df.head())【実行結果】
1920 年代に記録された車の速度「speed」と停止までにかかった距離「dist」のデータです。

データの可視化
読み込みしたデータを異常検知の学習データに用いたいと思います。
そこで、データを可視化して分布等を確認します。
最初に散布図を描画します。
seaborn の regplot で作画した回帰直線付きの散布図です。
### 散布図の表示
# 描画領域の指定
fig, ax = plt.subplots(figsize=(5, 4))
# 散布図の描画 回帰直線付き
sns.regplot(data=df, x='speed', y='dist', line_kws={'color': 'tomato'},
scatter_kws={'ec': 'white', 's': 80})
# 修飾
ax.set(xlabel='スピード[mph]', ylabel='停止距離[feet]',
title='自動車の走行スピードと停止距離の関係\n'
f'相関係数:{df.corr().iloc[0, 1]:.3f}')
plt.grid(lw=0.5);【実行結果】
スピードと停止距離の間には強い正の相関があります。
いくつかのデータ点は回帰直線から離れている感じもします。

seaborn の regplot は単回帰直線のほかに、lowess平滑化曲線も描画可能です。
見てみましょう。
### 散布図の表示
# 描画領域の指定
fig, ax = plt.subplots(figsize=(5, 4))
# 散布図の描画 Lowess回帰曲線付き
sns.regplot(data=df, x='speed', y='dist', lowess=True, # ★lowess
line_kws={'color': 'tomato'},
scatter_kws={'ec': 'white', 's': 80})
# 修飾
ax.set(xlabel='スピード[mph]', ylabel='停止距離[feet]',
title='自動車の走行スピードと停止距離の関係\n'
f'相関係数:{df.corr().iloc[0, 1]:.3f}')
plt.grid(lw=0.5);【実行結果】
スピード 20 mph あたりで直線の傾きがやや大きくなっています。
停止距離 120 feet の外れ値的なデータ点の影響を受けたのでしょうか?

データの規格化
データをMin-Max法で規格化(正規化)します。
各変数の最小値・最大値は異常検知時に用いるパラメータになります。
未知データの規格化に利用します。
### データの規格化
# データの最小値・最大値の算出:異常検知のパラメータ
x_min = df['speed'].min()
x_max = df['speed'].max()
y_min = df['dist'].min()
y_max = df['dist'].max()
# Min-Max法でデータを規格化(正規化)
x = (df["speed"] - x_min)/(x_max - x_min)
y = (df["dist"] - y_min)/(y_max - y_min)規格化後のデータの散布図を seaborn で描画します。
### 散布図の表示
# 描画領域の指定
fig, ax = plt.subplots(figsize=(5, 4))
# 散布図の描画 回帰直線付き
sns.regplot(x=x, y=y, line_kws={'color': 'tomato'},
scatter_kws={'ec': 'white', 's': 80})
# 修飾
ax.set(xlabel='スピード', ylabel='停止距離',
title='自動車の走行スピードと停止距離の関係(規格化)\n'
f'相関係数: {np.corrcoef(x, y)[0, 1]:.3f}')
plt.grid(lw=0.5);【実行結果】


マハラノビス距離算出のパラメータの学習
規格化後のデータを学習データにして、マハラノビス距離算出のパラメータとなる「説明変数ごとの平均値」と「説明変数間の分散共分散行列の逆行列」を算出します。
### パラメータの学習
# 平均の算出
mean_x = np.mean(x)
mean_y = np.mean(y)
# 分散共分散行列の逆行列の算出
cov_i = np.linalg.pinv(np.cov([x, y]))
# 算出結果の表示
print(f'x:sppedの平均 {mean_x}')
print(f'y:dist の平均 {mean_y}')
print('\n分散共分散行列の逆行列cov_i')
print(cov_i)【実行結果】

ちなみにマハラノビス距離を求める公式は以下になります。
$$
d(\boldsymbol{x}) = \sqrt{(\boldsymbol{x}-\boldsymbol{\mu})^{\top} \boldsymbol{S}^{-1} (\boldsymbol{x}-\boldsymbol{\mu})}
$$
以降の作業は「異常度の閾値を定めるための確認作業」の位置づけになると思われます。

等高線図用データの作成
ユークリッド距離およびマハラノビス距離の等高線に用いる値 z1、z2 の計算は、テキスト138ページのコードどおりに実行します。
(この記事ではコード表示を省略いたします)
データ点と平均値間の距離の計算
scipy の distance を用いて、学習データの各データ点と平均値間のユークリッド距離およびマハラノビス距離を計算します。
等高線図の中心からの乖離が数値で分かります。
### 2変数の各データ点と平均値の距離の算出
## ユークリッド距離
# 2変数の各データ点と平均値の距離の算出
dist_e = np.array([[i, j, distance.euclidean([i, j], [mean_x, mean_y])]
for (i, j) in zip(x, y)])
# 距離の大きい順にindexを取得(argsortでindexを昇順で取得, [::-1]で降順)
dist_e_top_idx = dist_e[:, 2].argsort()[::-1]
# 距離の大きいデータ点と距離を表示
print('ユークリッド距離:平均値からの乖離TOP5: ')
display(pd.DataFrame(dist_e[dist_e_top_idx[:5]],
columns=['speed', 'dist', 'euclidean']))
## マハラノビス距離
# 2変数の各データ点と平均値の距離の算出
dist_m = np.array([[i, j, distance.mahalanobis([i, j], [mean_x, mean_y], cov_i)]
for (i, j) in zip(x, y)])
# 距離の大きい順にindexを取得(argsortでindexを昇順で取得, [::-1]で降順)
dist_m_top_idx = dist_m[:, 2].argsort()[::-1]
# 距離の大きいデータ点と距離を表示
print('\nマハラノビス距離:平均値からの乖離TOP5: ')
display(pd.DataFrame(dist_m[dist_m_top_idx[:5]],
columns=['speed', 'dist', 'mahalanobis']))【実行結果】
中心から遠いトップ5のデータ点の位置を表示してみました。
距離の算出方法によって、中心からの距離が変わっているようです。


等高線図の描画
テキスト図7-3「中心からの距離の違い」を描画します。
等高線図にグラデーションで色を付けてみました。
線を付与する「contour」はテキストのコードを引用させていただきました。
色を付与する「contourf」を追加しました。
### 2変数のユークリッド距離(円)、マハラノビス距離(楕円)の可視化
## 描画領域の指定
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
## 左のユークリッド距離の描画
# ユークリッド距離の等高線・等高面の描画 ★グリーンの色を付けた
ax1.contour(z1.T[0], z1.T[1], z1.T[2], levels=10, colors=['black'],
linestyles='--', linewidths=0.5)
ax1.contourf(z1.T[0], z1.T[1], z1.T[2], levels=10, vmin=-0.4, vmax=1,
cmap='Greens_r')
# 散布図の描画
sns.scatterplot(x=x, y=y, color='white', ec='black', s=80, ax=ax1)
# 平均から2番目に遠いデータをオレンジで描画 ★色を付けた
sns.scatterplot(x=[dist_e[dist_e_top_idx[1]][0]],
y=[dist_e[dist_e_top_idx[1]][1]],
color='tab:orange', ec='black', s=80, ax=ax1)
# 平均から2番目に遠いデータに円を描画
c_r = patches.Ellipse(xy=(0, 0), width=0.1, height=0.1, fill=False,
ec='tab:red', linewidth=2)
ax1.add_patch(c_r)
# 修飾
ax1.set(xlabel='スピード', ylabel='停止距離',
title='自動車の走行スピードと停止距離の関係(規格化)\nユークリッド距離')
ax1.grid(lw=0.5)
## 右のマハラノビス距離の描画
# マハラノビス距離の等高線・等高面の描画 ★ブルーの色を付けた
ax2.contour(z2.T[0], z2.T[1], z2.T[2], levels=10, colors=['black'],
linestyles='--', linewidths=0.5)
ax2.contourf(z2.T[0], z2.T[1], z2.T[2], levels=10, vmin=-5, vmax=5,
cmap='Blues_r')
# 散布図の描画
sns.scatterplot(x=x, y=y, color='white', ec='black', s=80, ax=ax2)
# 平均から2番目に遠いデータをオレンジで描画 ★色を付けた
sns.scatterplot(x=[dist_e[dist_m_top_idx[1]][0]],
y=[dist_e[dist_m_top_idx[1]][1]],
color='tab:orange', ec='black', s=80, ax=ax2)
# 平均から2番目に遠いデータに円を描画
c_r = patches.Ellipse(xy=(0.48, 0.66), width=0.1, height=0.1, fill=False,
ec='tab:red', linewidth=2)
ax2.add_patch(c_r)
# 修飾
ax2.set(xlabel='スピード', ylabel='停止距離',
title='自動車の走行スピードと停止距離の関係(規格化)\nマハラノビス距離')
ax2.grid(lw=0.5);【実行結果】
マハラノビス距離のほうがデータの分布に寄り添っている感じがします。
色付きのデータ点は中心から2番目に遠いデータです。


ホテリングのT²法による異常検知
ホテリングの$${T^2}$$法の異常度と閾値を考えてみます。
■ 異常度
ホテリングの$${T^2}$$法の異常度は「マハラノビス距離の二乗」ですので、データ点$${\boldsymbol{x}^{\prime}}$$の異常度$${a(\boldsymbol{x}^{\prime})}$$は次のようになります。
$$
a(\boldsymbol{x}^{\prime}) = (\boldsymbol{x}-\boldsymbol{\mu})^{\top} \boldsymbol{S}^{-1} (\boldsymbol{x}-\boldsymbol{\mu})
$$
テキストでは異常度を次のように示しています。
式中の$${N}$$の意味を理解できていないので、深堀りはやめます。
$$
a(x^{\prime}) = \displaystyle \sum_{i=1}^N \left( \cfrac{x_i-\mu_i^*}{\sigma_i}\right)^2
$$
ここまでの仮まとめです。
マハラノビス距離の二乗がホテリングの$${T^2}$$法の異常度です。
「データ点と平均値間の距離の計算」で求めたマハラノビス距離「dist_m」を二乗するとホテリングの$${T^2}$$法の異常度になるのです!

■ 閾値
異常判別の閾値の鍵を握るのはカイ二乗分布です!
データ点の数(行の数)$${N}$$がデータの説明変数の数(列の数)$${M}$$よりも十分に大きいとき、ホテリングの$${T^2}$$法の異常度$${a(\boldsymbol{x}^{\prime}) }$$は自由度$${M}$$のカイ二乗分布に近似的に従います。
この記事で用いたデータは2次元(列数)なので、ホテリングの$${T^2}$$法の異常度は自由度2のカイ二乗分布に近似的に従います。
5%を異常にする「95%点」を閾値にする場合には、自由度2のカイ二乗分布の95%点を閾値にします。
1%を異常にする「99%点」を閾値にする場合には、自由度2のカイ二乗分布の99%点を閾値にします。
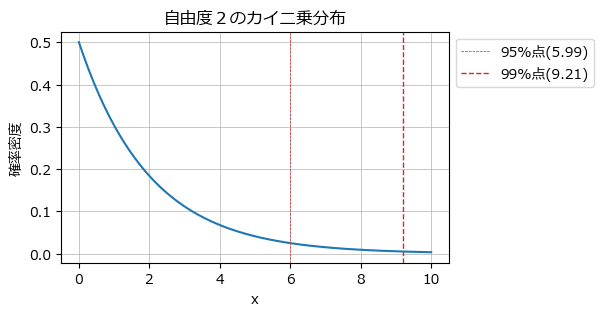
自由度2のカイ二乗分布の確率密度関数と95%点・99%を可視化しましょう。
### 自由度2のカイ二乗分布の描画
## 設定
# 自由度
df = 2
## 描画用データの作成
# x軸の値の作成
xval = np.linspace(0, 10, 1001)
# 自由度2のカイ二乗分布の確率密度関数の算出
yval = stats.chi2.pdf(xval, df=df)
# 閾値:自由度2のカイ二乗分布の95%点・99%点の算出
thres95 = stats.chi2.ppf(q=0.95, df=df)
thres99 = stats.chi2.ppf(q=0.99, df=df)
## 描画
# 描画領域の設定
fig, ax = plt.subplots(figsize=(5, 3))
# 自由度2のカイ二乗分布の確率密度関数の描画
sns.lineplot(x=xval, y=yval, ax=ax)
# 閾値95%点の垂直線の描画
ax.axvline(thres95, color='tab:red', lw=0.5, ls='--',
label=f'95%点({thres95:.2f})')
# 閾値99%点の垂直線の描画
ax.axvline(thres99, color='tab:red', lw=1, ls='--',
label=f'99%点({thres99:.2f})')
# 修飾
ax.set(xlabel='x', ylabel='確率密度', title='自由度2のカイ二乗分布')
plt.legend(bbox_to_anchor=(1, 1))
plt.grid(lw=0.5);【実行結果】
凡例に付記した数値がホテリング$${T^2}$$法の異常度の閾値です。

■ 学習データによる異常判別の確認
異常検知の実装を進めていきましょう!
既に計算済みの「学習データの各データ点のマハラノビス距離」を二乗して、学習データの異常度「anomaly_score」にします。
異常度の閾値の基準は 5% にしましょう。
自由度2のカイ二乗分布の 95% 点(つまり異常は5%)を閾値「thres」とします。
これらをまとめて「異常検知」を可視化します。
### ホテリングのT²法によるの異常判別の描画
## 異常値T²の算出:T²はマハラノビス距離の二乗
anomaly_score = dist_m[:, 2]**2
## 異常値の閾値:自由度dfのカイ二乗分布の上側alpha%点
df = 2
alpha = 0.05
thres = stats.chi2.isf(q=alpha, df=df)
## 描画処理
# 描画領域の指定
fig, ax = plt.subplots(figsize=(6, 4))
# 正常値の散布図の描画
query1 = anomaly_score <= thres
sns.scatterplot(x=np.where(query1)[0] + 1, y=anomaly_score[query1], s=80,
color='lightblue', ec='tab:blue', ax=ax, label='正常値')
# 異常値の散布図の描画
query2 = anomaly_score > thres
sns.scatterplot(x=np.where(query2)[0] + 1, y=anomaly_score[query2], s=80,
color='lightpink', ec='tab:red', ax=ax, label='異常値')
# 閾値の水平線の描画
ax.axhline(thres, color='tomato', ls='--')
# 修飾
ax.set_title(f'ホテリングの$T^2$法による異常判別\n異常度の閾値 {thres:.2f} '
f'(自由度{df}の$\chi^2$分布の上側{alpha:.0%}点)')
ax.set(xlabel='データ番号', ylabel='異常度', ylim=(-1.9, 13.9))
ax.grid(lw=0.5)
ax.legend(loc='upper left');【実行結果】
学習データのうち、2つのデータを異常判別するモデルになりました。

この2点の異常データはどの位置にあるのでしょう?
マハラノビス距離の等高線図に異常判別の閾値を表示してみたくなりました。
寄り道します。
■ 異常度 on マハラノビス距離の等高線図
異常度はマハラノビス距離の二乗、ということは、異常度の平方根はマハラノビス距離であり、異常度の閾値の平方根はマハラノビス距離での閾値、ということになる気がします!(気がするだけ?)
この仮説に則って、異常度の閾値の平方根をマハラノビス距離の等高線図にプロットしてみましょう!
閾値の%は「異常度の%」と読み替えて、1%、5%、10%(それぞれ99%点、95%点、90%点)を閾値表示します。
### 異常度の閾値付き描画
# 3つの閾値:自由度2のカイ二乗分布の上側α%点の平方根
alphas = [0.10, 0.05, 0.01]
thres_levels = [np.sqrt(stats.chi2.isf(q=p, df=2)) for p in alphas]
## 描画処理
# 描画領域の指定
fig, ax = plt.subplots(figsize=(5, 5))
# マハラノビス距離の等高線・等高面の描画
ax.contour(z2.T[0], z2.T[1], z2.T[2], levels=10, colors=['black'],
linestyles='--', linewidths=0.5)
ax.contourf(z2.T[0], z2.T[1], z2.T[2], levels=10, vmin=-5, vmax=5,
cmap='Blues_r')
# 3つの閾値の描画
ax.contour(z2.T[0], z2.T[1], z2.T[2], levels=thres_levels, colors=['tab:red'],
linestyles=[':', '--', '-'], linewidths=[1, 1, 2])
# 散布図の描画
sns.scatterplot(x=x, y=y, color='white', ec='black', s=80, ax=ax)
# top2のデータ点をオレンジ色にする
sns.scatterplot(x=[dist_e[dist_m_top_idx[0]][0]],
y=[dist_e[dist_m_top_idx[0]][1]],
color='tab:orange', ec='black', s=80, ax=ax)
sns.scatterplot(x=[dist_e[dist_m_top_idx[1]][0]],
y=[dist_e[dist_m_top_idx[1]][1]],
color='tab:orange', ec='black', s=80, ax=ax)
# 修飾 凡例用のダミー描画(実際には描画されない)
ax.plot([], [], color='tab:red', ls=':', lw=1, label=f'{alphas[0]:4.0%}')
ax.plot([], [], color='tab:red', ls='--', lw=1, label=f'{alphas[1]:4.0%}')
ax.plot([], [], color='tab:red', ls='-', lw=2, label=f'{alphas[2]:4.0%}')
# 修飾 その他
ax.set(xlabel='スピード', ylabel='停止距離',
title='自動車の走行スピードと停止距離の関係(規格化)\nマハラノビス距離')
ax.legend(title='異常度の閾値');【実行結果】
可視化するとデータ点と閾値の関係・位置がよく分かります!
閾値 5% のときの異常データをオレンジで着色しました。

ちなみに閾値 5%の異常データを調べてみましょう。
### 閾値5%の場合の異常値の詳細
print(f'閾値(5%): {thres_levels[0]:.3f}')
over95_idx = np.where(dist_m[:, 2] >= thres_levels[1])[0]
pd.DataFrame(dist_m[over95_idx], index=over95_idx,
columns=['speed', 'dist', 'mahalanobis']).round(3)【実行結果】
2つのデータ点の位置とマハラノビス距離が分かりました。

未知データの異常検知
寄り道は続きます。
未知データを作成して、異常検知してみましょう!
最初に各種定義です。
データの規格化関数、学習データから得たパラメータ類(平均、最小値、最大値、分散共分散行列の逆行列、異常度の閾値)をひとまとめに定義・設定します。
## 事前定義
# Min-Max Scaler関数の定義
def min_max_scaler(X, min_value, max_value):
return (X - min_value) / (max_value - min_value)
# 学習データの平均値のnumpy配列化
means = np.mean([mean_x, mean_y])
# 学習データの最小値と最大値の設定
min_value = np.array([x_min, y_min])
max_value = np.array([x_max, y_max])
# 学習データの分散共分散行列の逆関数は既に計算済みの cov_i を使用
# 異常度の閾値 5%
threshold = stats.chi2.isf(q=0.05, df=2)
print('異常度の閾値: ', threshold)【実行結果】

未知データを作成します。
### 未知データの作成
data_new = np.array([[7, 30], [18, 20], [21, 100], [14, 5]])
print('未知データ:')
print(data_new)【実行結果】
4つのデータを作成しました。

データをMin-Max法で規格化(正規化)します。
学習データの最小値・最大値を用います。
### 未知データの規格化(正規化)
data_new_mm = min_max_scaler(data_new, min_value, max_value)
print('規格化後の未知データ:')
print(data_new_mm)【実行結果】

それでは!📯
未知データの異常検知を実行します!
### 未知データの異常検知
# 異常度の算出
anomaly_score_new = np.array([distance.mahalanobis(
[i, j], [mean_x, mean_y], cov_i)**2
for i, j in data_new_mm])
print('異常度 : ', anomaly_score_new)
# 異常ラベルの算出 0: 正常、1:異常
anomaly_label = (anomaly_score_new > threshold) + 0
print('異常ラベル: ', anomaly_label)【実行結果】
4つのデータの異常度と異常ラベルです。
異常ラベル=1が異常ですので、3つ目のデータが異常です!


異常度の可視化をしましょう。
### 描画処理
# 描画領域の指定
fig, ax = plt.subplots(figsize=(6, 4))
# 正常値の散布図の描画
query1 = anomaly_label == 0
sns.scatterplot(x=np.where(query1)[0] + 1, y=anomaly_score_new[query1], s=80,
color='lightblue', ec='tab:blue', ax=ax, label='正常値')
# 異常値の散布図の描画
query2 = anomaly_label == 1
sns.scatterplot(x=np.where(query2)[0] + 1, y=anomaly_score_new[query2], s=80,
color='lightpink', ec='tab:red', ax=ax, label='異常値')
# 閾値の水平線の描画
ax.axhline(threshold, color='tomato', ls='--')
# 修飾
ax.set_title(f'ホテリングの$T^2$法による異常判別\n異常度の閾値 {threshold:.2f} '
f'(自由度2の$\chi^2$分布の上側5%点)')
ax.set(xlabel='データ番号', ylabel='異常度')
ax.grid(lw=0.5)
ax.legend(loc='upper left');【実行結果】
3つ目のデータが異常度の閾値を超えている様子が分かります。

未知データをマハラノビス距離の等高線図にマッピングしてみましょう。
### 異常度の閾値付き描画
# 閾値:自由度2のカイ二乗分布の上側5%点の平方根
thres_level = np.sqrt(stats.chi2.isf(q=0.05, df=2))
## 描画処理
# 描画領域の指定
fig, ax = plt.subplots(figsize=(5, 5))
# マハラノビス距離の等高線・等高面の描画
ax.contour(z2.T[0], z2.T[1], z2.T[2], levels=10, colors=['black'],
linestyles='--', linewidths=0.5)
ax.contourf(z2.T[0], z2.T[1], z2.T[2], levels=10, vmin=-5, vmax=5,
cmap='Blues_r')
# 閾値の描画
ax.contour(z2.T[0], z2.T[1], z2.T[2], levels=[thres_level], colors=['tab:red'],
linestyles=['--'], linewidths=[2])
# 散布図の描画
sns.scatterplot(x=data_new_mm[:, 0], y=data_new_mm[:, 1], color='white',
ec='black', s=80, ax=ax)
# 異常データをオレンジ色にする
sns.scatterplot(x=[data_new_mm[anomaly_label == 1][0][0]],
y=[data_new_mm[anomaly_label == 1][0][1]],
color='tab:orange', ec='black', s=80, ax=ax)
# 異常データに円を描画
c_r = patches.Ellipse(xy=data_new_mm[anomaly_label == 1][0],
width=0.1, height=0.1, fill=False,
ec='tab:red', linewidth=2)
ax.add_patch(c_r)
# 修飾 凡例用のダミー描画(実際には描画されない)
ax.plot([], [], color='tab:red', ls='--', lw=2, label='5%')
# 修飾 その他
ax.set(xlabel='スピード', ylabel='停止距離',
title='自動車の走行スピードと停止距離の関係(規格化)\nマハラノビス距離')
ax.legend(title='異常度の閾値');【実行結果】
「異常検知した感」を味わえますね!

ホテリングの$${T^2}$$法による異常検知は以上です。

One-Class SVM
テキスト7-1-3節「補足」の「One-Class SVM」による異常検知を行います。
学習データを用いてOne-Class SVMの学習を行い、学習データで異常点を見つけます。
学習データに用いるpandasのデータフレーム「data」はテキストの配布コードを用いて作成してください。
では異常検知と異常検知結果の可視化を行います。
OneClassSVMのパラメータ nu と gamma の数値を変えると、さまざまな異常検知の閾値を堪能できると思います!
### One-Class SVMの決定境界の描画
## One-Class SVMの実行
# One-Class SVM分類器の設定
clf = OneClassSVM(nu=0.01, kernel='rbf', gamma=3)
# One-Class SVMの学習
clf.fit(data)
# 学習データによるクラス予測 1:正常値、-1:外れ値
pred = clf.predict(data)
# 決定境界からの距離の算出 負は外れ値
score = clf.decision_function(data)
## 等高線用のx,y,zの値を設定
xx, yy = np.meshgrid(np.linspace(-0.1, 1.1, 1000), np.linspace(-0.1, 1.1, 1000))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
## 描画処理
# 描画領域の指定
fig, ax = plt.subplots(figsize=(5, 5))
# 決定境界(異常値の閾値)の描画
ax.contour(xx, yy, Z, levels=[0], colors='tomato', linwidths=1, linestyles='--')
# 散布図の描画
sns.scatterplot(x=data['x'], y=data['y'], hue=pred*-1, s=80, alpha=0.5,
palette=['tab:blue', 'tab:red'], ec='lavender', ax=ax)
# 凡例
ax.plot([], [], color='tomato', lw=1, ls='--', label='決定境界')
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles=handles, labels=['正常', '異常', '閾値'], title='異常検知',
loc='upper left')
# 修飾
ax.set(xlabel='スピード', ylabel='停止距離',
title='One-Class SVMによる異常検知')
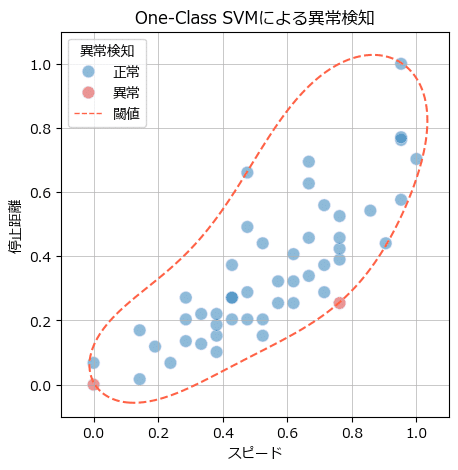
ax.grid(lw=0.5);【実行結果】
パラメータ nu、gamma にはテキストと異なる値を設定しています。
データにぴったりと寄り添うように、ぐにゃりと曲がった閾値が生成されています。
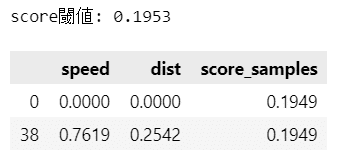
One-Class SVM で算出できる Score を異常度と見立てて、異常度の閾値 offset_ 、異常データとみなした2点の Score を確認しましょう。
### 異常値(スコア)の詳細
print(f'score閾値: {clf.offset_[0]:.4f}')
scores = np.concatenate([dist_m[:, :2], clf.score_samples(data).reshape(-1, 1)],
axis=1)
anomaly_idx = np.where(pred < 0)[0]
pd.DataFrame(scores[anomaly_idx], index=anomaly_idx,
columns=['speed', 'dist', 'score_samples']).round(4)【実行結果】
距離とは異なる指標ですので、直感的に理解しにくい感じがいたします。
第7章①の寄り道写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?