

#AI画像生成


Negative Prompt を入れるタイミングについて
こんにちはこんばんは、teftef です。久しぶりに書きます。
今回は Negative Prompt が画像生成時に与える影響についてです。
簡単に内容だけネタバレすると、Diffuseion モデルの推論では Negative Prompt は 1 step 目からかけるより、 n >1 step 目からかけたほうがいいんでね。という趣旨です。
私もまだ初学者であり、説明が間違っていたり勘

Latent Surfing(第3回 AI なんでもLT 会の振り返り)
こんにちはこんばんは、teftef です。2024 年 3月 10 日に開催された LT 会で話したことについてのまとめと振り返りです。「Latent Surfing 」という題目で、 GAN や Diffusion Models を用いたモーフィングについて話しました。その内容についてまとめます。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了

セグメンテーションを用いた被写体切り抜きとパーツ分け
こんにちはこんばんは、teftef です。今回は,セマンティックセグメンテーションを使って画像内の被写体抽出をただ試すだけという記事です。いくつかの論文と手法をベースにしていますが、詳しいことは書かない予定です。Google Cloab も配布しているのでぜひ最後まで見ていただけると幸いです。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承くださ

Latent Consistency Models について
こんにちはこんばんは、teftef です。今回は爆速画像生成ができる Latent Consistency Models についてです。WebUI 拡張やお試しも載せておきます。
拡散モデルの拡散過程は確率常微分方程式 (Probability Flow ODE) を解いて得ることができ、少ないステップによってその解軌道に沿ったサンプリングができるように学習します。これによって、Consisi

超解像について (その2・SRGAN と ESRGAN)
こんにちはこんばんは、teftef です。超解像その1の続きです。前回は、画像を拡大するアルゴリズム手法から始まり、SRCNN といった機械学習手法を使って超解像をするところまで書きました。今回はさらに SRCNN を応用した SRGAN , ESRGAN , Real-ESRGAN について書いていきます。GAN の概要は飛ばすので、もし読みたい方がいればこちらをご覧ください。
私もまだ初学


『FABRIC』 : フィードバックベース画像Editor
こんにちはこんばんは、teftef です。今回はユーザーのお気に入り画像をフィードバックし、ファインチューン無しでその画像に寄った画像を生成してくれるツール「 FABRIC 」についてです。 FABRIC はユーザーのフィードバックを基に、LDMs にそのフィードバック情報を追加することでユーザーエクスペリエンスと出力品質を向上させています。
私もまだ初学者であり、説明が間違っていたり勘違い

ComfyUI で動かす Stable Diffsion XL
こんにちはこんばんは、teftef です。今回は話題の Stable Diffusion XL についてです。と、言っても使い方の記事は調べればいくらでも出てくると思うので、主は依然として論文解説をします。使い方を見に来たという方々にとってはその目的にに沿わないと思うので、主が特に分かりやすいと思った記事を下に張っておきます。今回は SDXL が条件付けとして画像のサイズを使用していることについ
もっとみる
AI の, AI による, AI のための Governance
こんにちはこんばんは、teftef です。ここ最近の AI (Artificial Inteligence) は様々な形で私たちの身の回りのタスクを補うようになっています。しかし AI を受け入れ、共存していくという選択肢とともに AI に支配(統治)されることを恐れる声もあります。現在の AI にはどのような能力があり、人間とどのような関係性を気づいているのか、また、これから先私たちは AI
もっとみる
DeepFloyd IF : 自然言語モデルの知識を利用した画像生成モデル (Imagen)
こんにちはこんばんは、teftef です。2023 年 4 月 29 日に Stability AI に所属する開発チーム : DeepFloyd から Stable Diffusion とは異なる手法を使用した DeepFloyd IF が公開されました。このモデルは文字を破綻せずに生成できたり、高品質な画像を生成できるモデルとして注目を集めています。今回はこの DeepFloyd IF のベ
もっとみる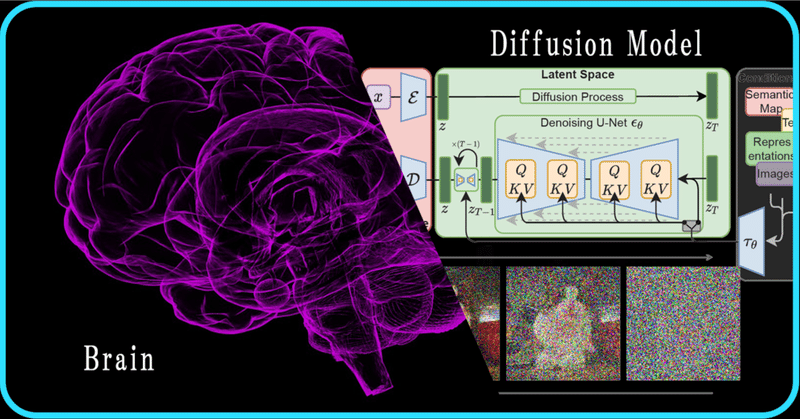
fMRI から画像を生成する話
こんにちはこんばんは、teftef です。今回は大阪大学から出た fMRI 画像から Stable Diffusion を用いて画像生成する論文をベースに Brain 2 Image について書いていこうと思います。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、

AI を自分好みに調整できる、追加学習まとめ ( その6: Instruct Pix2Pix )
こんにちはこんばんは、teftef です。今回は画像に対して text を用いて操作内容を指示し、元画像と大きく離れることなく指定した内容を編集する手法、Instruct Pix2Pix です。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。
使用した論文 今回、使用した論文

AI を自分好みに調整できる、追加学習まとめ ( その4: Imagic )
こんにちはこんばんは、teftef です。今回も追加学習手法についてです。今回はTextual Inversion , DreamBooth に引き続きファインチューニングの変わり種である Imagic についてです。Imagic はファインチューニングに用いる画像が入力画像の 1 枚の 1 shot の手法で、その入力画像の固有性を維持しながら、画像編集ができるという手法です。
私もまだ初学

AI を自分好みに調整できる、追加学習まとめ (その2 : Textual Inversion )
こんにちはこんばんは、teftef です。昨今のAI画像生成において、既存のモデル以外にも、独自の「絵柄」や「画風」を出力できるようにした『オリジナルモデル』を制作する方々が増えています。しかし個人が 0 からモデルを学習させるには膨大な時間と計算量を必要とするため、既存のモデルをベースに学習する「追加学習」と呼ばれる手法を使用することが一般的でしょう。追加学習の大雑把な解説は前回の記事をご覧く
もっとみる