
指名検索が多いと得票数も多い説

(注)本noteは一切の政治的な主張を目的としておりません。マーケターまたはビジネスマンに「効果検証のデザイン」及び分析法を紹介するものです。
※タイトル画像については私も大好きな超人気番組、水曜日のダウンダウンのタイトルコールを加工した方の動画素材を使用させて頂きました。https://www.youtube.com/watch?v=NlFjgVgI9O4
【更新情報2024年5月26日】
「その決定に根拠はありますか?」
確率思考でビジネスの成果を確実化するエビデンス・ベースド・マーケティング
戦略を導く為の「エビデンスの作り方」をテーマに、これまで体系化してきたノウハウを紹介したマーケティング・インテリジェンスの書籍を出版致しました。5問の調査でTVCM(施策)→コンビニで商品を見た(要因)→売上がいくら増えたか?→年間16.67億円(効果)の様に経路ごとに構造的に効果を把握する国際特許(PCT)を出願した分析法など、確率モデルや因果推論をプロジェクトで実際に活用している方法を特典の動画講義も活用して実装レベルの知識まで提供しています。
自己紹介と本note執筆目的
「効果検証デザイナー」の小川貴史と申します。電通グループなどの広告会社やデジタルマーケティングコンサルのネットイヤーグループでインターネット広告、マス広告、UXデザイン、PR、データ分析など幅広く経験してきた知見を活かして、今はPR会社カーツメディアワークスでマーケティングコミュニケーション領域のコンサルティングを行っています。(効果検証デザイナーは個人作家活動の際の肩書きです)
日本のマーケティングの現場では、因果関係の把握など、効果検証については全然データドリブンじゃないと思っており、そこに課題を感じています。その状況を変えていくための活動として、昨年11月末に「Excelでできるデータドリブン・マーケティング」という書籍を出しました。時系列データ解析によって、TVCMやネット広告などによる効果を定量化(例えば、2億円のTVCMによって売上5億円が増えたなどの介入効果を推定)するマーケティング・ミックス・モデリングという分析法を紹介しました。拙書では時系列データ解析による(残存効果などを加味した変則的な)回帰分析によってそれを行い、演習で読者が分析を再現できる様にしました。
※時系列データの回帰分析=マーケティング・ミックス・モデリングではありません。後者は数理モデルによって効果を導き、予算配分試算まで行う手法のことを示します。前者はそのための手法のひとつです。私が採用したのは回帰分析ですが、他にも状態空間モデルやVARモデルなど様々な分析アルゴリズムの採用が模索されています。
※2020年(4月17日更新追記情報)その分析をZoomで学ぶことができる講義も行っています。
本note執筆の動機を紹介します。私は世田谷在住なのですが、2019年4月21日投票の区議会選挙に伴って、最寄り駅での各候補者での街頭での活動などを見てきました。それを見て、ふと、思いました。「選挙活動」の効果検証をする場合、自分ならばどうするかと。その際、「指名検索」をKPIとするのが良いと思い、本noteで紹介する分析を行ってみようと考えました。各議員名称の指名検索数が得票数に対してどれくらい影響を持つか?定量化するための(重)回帰分析を行うことにしました。
※説明変数を複数用いる回帰分析のことを「重回帰分析」説明変数が一つの場合は「単回帰分析」と言います。
映画の宣伝を例にします。映画の宣伝は公開前数か月、大作になると数年前から宣伝をします。だんだん「チラ見せ」していき、作品への期待感を醸成していく広告手法で、そうした手法のことをティザー広告と言います。公開前のティザー広告に、我々(消費者)が接触して「見たい!」と思っても、予約開始前に映画のチケットは購入できません。そんな時、(予約数の)代替変数として使えることが多い重要指標が「指名検索」です。時系列データ解析によるマーケティング・ミックス・モデリングを行う時も、日常的に購入する食品など低単価なものは、TVCMやネット広告などの施策を説明変数として、それぞれが「売上」(数や金額等)にどれだけ影響するか?を目的変数としてモデル式を作りますが、購買検討期間の長い商材では「指名検索」を使うことを推奨しています。購買への影響期間が長く、施策の接触から購買を行うまでの期間のバラつきが多いと、売上を目的とした予測モデルの精度などが担保できない場合が多いためです。
※「指名検索」は他にも、一般的に「ネットで調べて購入する様な商材」比較的高額で検討に1か月以上を有する様な商材のKPIとして重要なものとなります(例えば、不動産、自動車などの耐久消費財や高価格のサービス)反面、日常的に購入する低単価商材のKPIとしてはさほど重要ではありません(食品や日用品など低価格の商品やサービス)
候補者の目線になって考えてみました。私が仮に候補者だった場合、毎日、街頭で街頭に出て500人と握手したとします。ただ、握手しても、握手していただいた方が実際に「投票する気があるか」は分かりません。ただ、「(候補者である私の名前で)指名検索」をしてくれる数が増えたら、それは得票数に大きな影響を及ぼすのではないか?すなわち、日々の活動の効果を定量的に捉える指標とできるのでは?と考えられないかと思いました。
そこで、本noteでは、各候補ごとの指名検索数などを調べて、指名検索数がどれだけ得票数に影響するかを分析によって導きます。今回は(重)回帰分析を用いて、指名検索1回あたり、どれ位の検索数と関係がありそうか?を検証していきます。
※本当に知りたいのは指名検索1回増えると、得票数がどれだけ増えるか?という介入効果(指名検索(原因)→得票数(結果))の推定、すなわち因果効果です。ただ、この介入効果、因果関係をしっかりと突き詰めて検証するのは交絡など、考慮をしなくてはならないことが増えます。いったん本noteではそこまでの検証はせず、相関があるか?といった視点で見ていきます。本noteのタイトルも「因果」を示唆するものではなく、「相関」を示唆する説としています。因果推論についての知識を知りたい方は過去の私のnote「マーケターの施策効果把握、ほとんど間違えてるんじゃないか説」(下記)を参照ください。
なお、先に結論を申し上げると、「説」はおおむね立証できそうでした!
データテーブルを作る
まず、Googleキーワードプランナーを用いて、世田谷区の区議会議員候補を標本としてデータテーブルを作成し、分析しようとしましたが、指名検索数が得られない人が多かった為、23区の「区長候補」を用いてデータテーブルを作成していくことにしました。
※キーワードプランナーで調べられるのは、完全一致と言い、前述の候補一覧にあった氏名の検索ワード(これを検索クエリと言います)と完全合致する検索数(Google)のみです。その他、キーワードプランナーで得られる情報はどの様なものか?リスティング広告の運用の際に使ったことがない方、検索クエリ、完全一致といったリスティング広告付帯知識のない方は以下の参考文献をご覧ください。
(参考文献)
次に以下の記事を参照し、23区の区長選の候補者の年齢や、過去何回当選したか?それぞれの区の候補書が何人いるか?を調べました。
次に、それぞれの候補の得票数を下記記事から抽出しました。
また、おそらく各候補の得票数を左右する要因として、区ごとの人口もまとめました。以下の記事に2018年1月1日の住民基本台帳を元にした値がまとめられており、参照させて頂きました。
成型したデータテーブルを確認する
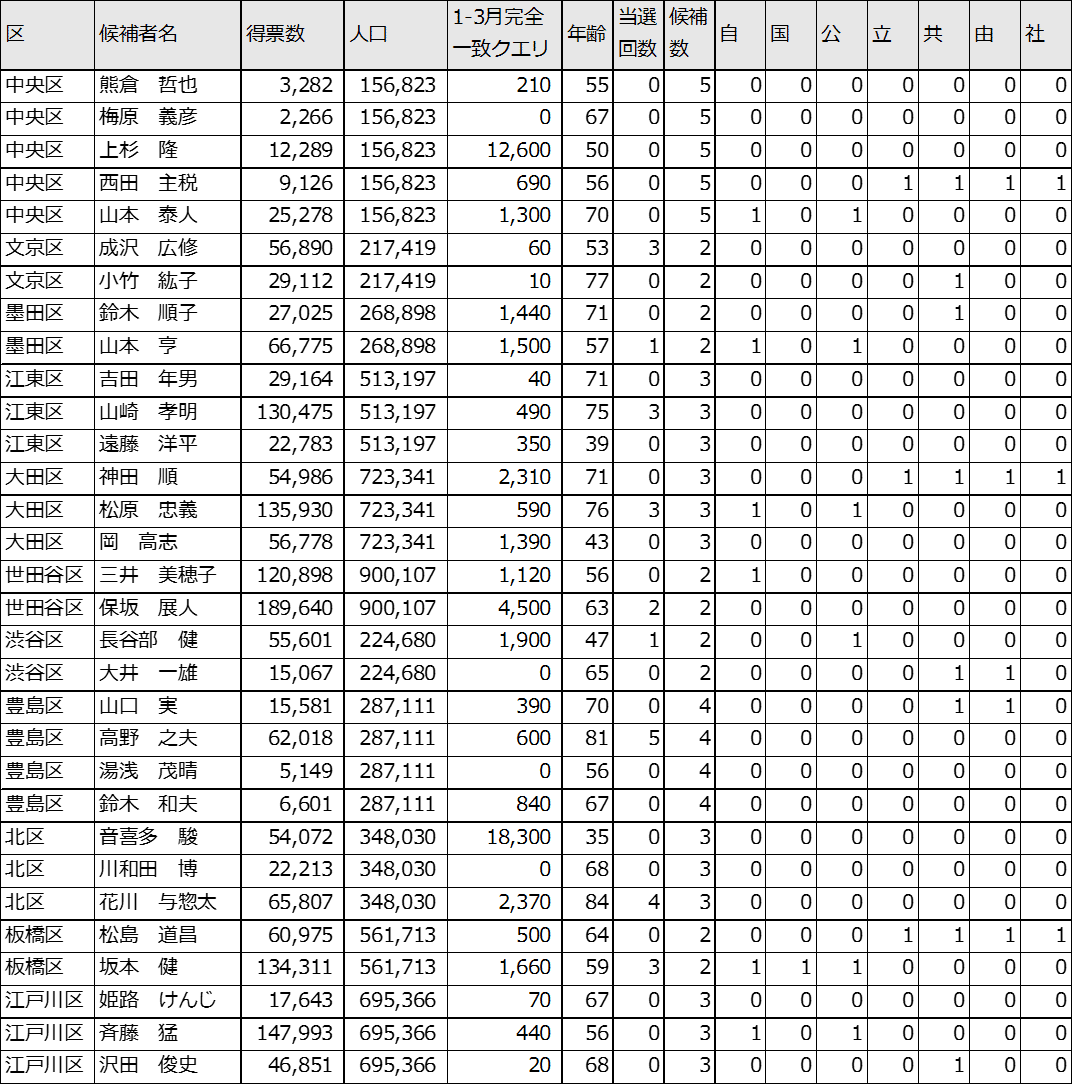
今回は、重回帰分析の目的変数として得票数を用いて、説明変数として、区ごとの人口、1-3月完全一致クエリ(グーグルキーワードプランナーより)候補者の年齢、過去の当選回数、区ごとの候補者数、どの党から推薦されているか?という候補変数を作ってみました。
Excel標準の「データ分析」アドインの機能を用いて、相関行列を作成します。
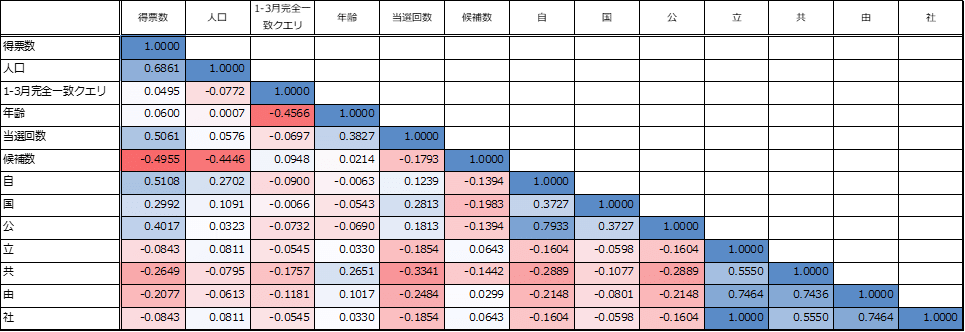
得票数に対しては、区の人口や(候補者の)当選回数が影響が強そうです。また、「立」と「社」の相関係数が1となっていて、「立」と「社」の値が全く同じ値だと考えられます。こうした2つの変数を同時に分析で説明変数として使用すると、「線形結合(完全なる多重共線性)」というエラーが発生します。分析時にいずれかを外す必要があります。(線形結合でなくても、相関の強い変数を同時に説明変数として採用すると「多重共線性」というエラーが発生するリスクが高まります)
※相関係数は、1対1の関係が強いかを象徴する指標なのですが、1対多の変数との関係によって、関係の強さが大きく変わることがあります。その指標となる偏回帰係数といった指標も見ることが必要です。
今回は「Excelでできるデータドリブン・マーケティング」の演習でも使用させて頂いている「エクセル統計」というExcelアドイン型の分析ソフトを使用して回帰分析を行いました。
※エクセル統計では線形結合している変数がある場合、いずれかを外す処理をしてくれます。本来は各変数の基本統計量やヒストグラムを描画しての分布の確認などを行うことが推奨されますが、本noteでは詳しい統計知識を共有する目的として行うと膨大な文章量となるため、紹介は割愛させて頂きます。「Excelでできるデータドリブン・マーケティング」では、Excelの標準アドイン機能となる「分析ツール」及び「エクセル統計」を用いた回帰分析を行う演習の中で、本来確認すべき前処理工程や、分析時に出力される様々な指標についてしっかりと解説していますので、そちらをぜひご覧ください。
重回帰分析を行う
まずは、目的変数を「得票数」として、それ以外の「全説明変数」を用いて分析してみます。これを「モデル1」とします。
モデル1結果

黄色く色を塗った偏回帰係数について説明します。人口は0.1195…となっています。区の人口の数×係数分、得票数に影響があると考えられます。
単回帰分析モデルの場合は単回帰係数と言いますが、 重回帰分析モデルの回帰係数を偏回帰係数と言います。「ある偏回帰係数は、それ以外の説明変数の値を固定した(変化させない)場合に、その説明変数が1増加するとyがどれだけ増加/減少するかを示しています。」(「」内の記載は以下統計WEB記事より引用)
※ただ、これらの回帰係数は例えば、「人口→得票数」因果の向きを保証してくれるわけではありません。
次に緑色に塗った標準偏回帰係数を説明します。これは、目的変数(得票数)への影響数が大きい変数はどれか?横並びで比較するものです。
もう少し詳しく説明します。「標準偏回帰係数は、説明変数および目的変数をそれぞれ標準化した値から算出される偏回帰係数のことです。標準偏回帰係数は重回帰式における各変数の重要性を表す指標であり、標準化偏回帰係数どうしの大小を比較できます。」(「」内の記載は上記の統計WEB記事より引用)
人口が0.5676…次いで(過去の)当選回数が0.4549…と大きな値となっており、これらの影響が大きそうであると言えます。
オレンジ色に塗ったP値は「偏回帰係数は 0 である(影響がない)」という帰無仮説を検定した値となっており、「P値が有意水準よりも小さい時は、帰無仮説を捨て対立仮説を採択します。すなわち、対立仮説が正しいと結論付けられます。」(「」内の記載は下記の統計WEB記事「検定で使う用語」より引用)
(参考文献)
有意水準は一般的に5%が用いられます。自然科学など理想的な実験に近い状況で行われる調査分析では厳しめの1%が採択されることも多く、社会科学など、実験的な調査分析が行えない状況では多少甘めの10%を採択することがある様です。拙書及び本noteでは10%水準として分析を行いました。マーケティングの分析は自然科学より社会科学に近く、実験の様な理想的な環境で得られないデータを分析することが多い為です。
※今回の目的変数とした「指名検索数」真に得たいのは候補者のことを興味を持って調べる検索数です。これが、実験の様な理想的な環境で得られるデータです。これに近い値を得るためには、完全一致の「候補者名(例 小川貴史」だけでなく、「小川貴史 評判」「小川貴史 経歴」など、想定される様々な掛け合わせキーワードを網羅し、徹底的に調べる必要があります。
10%を基準とした際に有意水準を下回るのは「人口」と「(過去の)当選回数」のみとなっています。それ以外の変数は有意水準をクリアできていません。
最後に、水色で塗った偏相関係数は他の説明変数の影響を考慮した当該変数と目的変数(得票数)の相関係数となっています。指名検索「1-3月完全一致クエリ」の単相関係数は0.0495…ですが、偏相関係数は0.3064…となっており、他の変数の影響を考慮することで、指名検索は得票数への影響がありそうだと分かります。
(参考文献)
次にエクセル統計の(重)回帰分析で行える機能として、P値を指定(有意水準)を下回る説明変数の組み合わせでモデルを探索する「説明変数選択機能」を使って分析を行います。今回は4種類ある選択法のうち「減少法」という方法を採択し、P値10%未満を条件に説明変数選択を行いました。この結果をモデル2とします。
モデル2結果

説明変数がだいぶ絞り込まれました。目的変数(得票数)への影響数が大きい変数はどれか?横並びで比較する標準偏回帰係数を見ると、「人口」、「当選回数」に次いで、「某政党のフラグ」、次いで「1-3月完全一致クエリ(指名検索)」となりました。
本noteについては政治的主張を目的としたものではない為、ひとつだけ採択されたある政党の推薦というフラグに関してはどの政党かをマスクさせて頂きました。
また、以下図にあるのはモデルの予測精度(の目安)となる指標を比較する為のものです。

( R2 乗)は「決定係数」といい、そのモデル(回帰式)が目的変数(得票数)の変動をどれくらい説明しているか?という目安です。ただし、重回帰分析で説明変数を増やしていくと、その変数が無意味(目的変数に対して影響を及ぼさない)ものであっても、決定係数は次第に 1に近づいていきます。決定係数が高くなったのが説明変数の数を増やしただけの効果によるものか、増やした以上の効果があったのかを見たいとき、「自由度調整済み決定係数」(修正R2乗)を比較します。(重)回帰分析の予測精度の比較として用います。モデル2の自由度調整済み決定係数が高くなっており、モデル1より有効なモデルだと考えられます。
※エクセルでは自由度調整済み決定係数を「補正R2」としております。これはソフトウェア固有の略称であり、統計学で用いられる正式な名称は「自由度調整済み決定係数」&「決定係数」です。
(参照文献)
※Excel(分析ツール)またはエクセル統計を用いて行った分析結果については罫線の設定やフォント変更、セルの着色は本note用に筆者が加工を行ったもので、それぞれデフォルトの分析結果で得られる書式とは異なっています。
最終結果(モデル2)から導く「指名検索が多いと得票数も多い説」に対しての示唆
「1-3月完全一致クエリ(指名検索)」の偏回帰係数は1.987…です。これは、「Googleの完全一致で氏名」を検索された回数1回あたり、1.987…回の得票を押し上げるという介入効果の目安となります。
例えば候補者名が「小川 貴史」だとした場合、Googleキーワードプランナーの完全一致で「小川 貴史」の検索クエリ数を推計している状態です。実際には「小川 貴史 評判」「小川 貴史 経歴」または「おがわたかし」など、幅広いワード(検索クエリ)が実行されています。また、Yahoo!など他の検索エンジンも考えられます。一概には言えませんが、キーワードプランナーで調べた候補者氏名の完全一致の2倍~10倍位は、小川 貴史関連の検索が発生していると思われます。
よって、仮にその倍数が4倍とした場合は、偏回帰係数は1/4の0.496…となります。指名検索が1回増えると、0.496…の得票が増える。これくらいだと、腹落ち感のある結果ではないでしょうか?
皆さんは、昨日見た広告全てのうち何種類を覚えているか思い出すことができますか?また広告に限らず、昨日TV番組やインターネットサイトなどのメディアでキャッチした情報をきっかけとして「検索」を行った回数は何回ありますか?考えてみてください。おそらくは、数回あるかないか?もしくは人や日によっては0回という日もあるかもしれません。また、「認知」はしているが、「指名検索」したことがないブランドは圧倒的に多いのではないでしょうか?
よって、企業やブランドが働きかけるコミュニケーションで、当該ブランドを(検索して)調べる、こうしたアクションの誘発は、購買への中間指標として非常に重要なものです。(低単価の日用品以外は特に)数理モデルを用いたアプローチによって広告効果を定量化する際に、「指名検索数」は非常に重要な指標となる場合が多いのです。
分析に興味を持っていただいたマーケターの方へ
拙書、「Excelでできるデータドリブン・マーケティング」では、アルコール飲料の事例、通販商材の事例を用いて、アルコール飲料は目的変数を売上本数として、通販商材はコールセンターとインターネット、双方の申込数を目的変数として、それをTVCMやインターネット広告、OOH、紙媒体がそれぞれいくつを押し上げるか?残存効果なども加味しながらモデル化していく様をこってりと演習します。今回紹介したエクセル統計の無料版でも分析を体験することができます。そんな演習をこってりと行った後の最終章(8章)では、本noteで重要なKPIとした指名検索などを用いる例を紹介しています。マーケティング分析をいくつかの業界でセグメントして、自動車業界など、高額な耐久消費財は、「指名検索」が重要といった内容や、因果推論について、こってりと解説します。こってりを3回も使ったのは意味があります。データサイエンティストの大先輩から、拙書、「Excelでできるデータドリブン・マーケティング」は、「データサイエンス書籍のラーメン二郎」と評価頂いたからです。
Amazonで購入して届くと、百科事典のような大きさに皆さん驚かれるとか笑
また、同書の監修を頂いたのはエクセル統計の開発会社の社会情報サービス社の方です。エクセル統計はマーケターにさほど知られていない印象があります。マーケターの皆様に強くオススメしたいソフトです!(なお、本noteで何度か参照した統計WEBも同社が運営するサイトです)
【更新情報2024年5月26日】
「その決定に根拠はありますか?」
確率思考でビジネスの成果を確実化するエビデンス・ベースド・マーケティング
戦略を導く為の「エビデンスの作り方」をテーマに、これまで体系化してきたノウハウを紹介したマーケティング・インテリジェンスの書籍を出版致しました。5問の調査でTVCM(施策)→コンビニで商品を見た(要因)→売上がいくら増えたか?→年間16.67億円(効果)の様に経路ごとに構造的に効果を把握する国際特許(PCT)を出願した分析法など、確率モデルや因果推論をプロジェクトで実際に活用している方法を特典の動画講義も活用して実装レベルの知識まで提供しています。