
python初心者がチャットボットを作ってみた。

1.はじめに
はじめまして。まずは簡単な自己紹介をします。
私はこれまで心理カウンセラー(臨床心理士・公認心理師)として精神科病院で働いていました。また大学院でカウンセラーと利用者との治療関係をテーマにした研究を行っていました。コロナ渦で対人交流の機会が減り、悩みを相談できず一人で抱える方が増えている現在、AIが役立つのではないかと考えました。
そもそもAIとは?チャットボットとは?と、何も知らない状態でしたので、論文、書籍、youtubeを見て勉強しました。独学の限界を感じ色々調べた結果、AIプログラミングに特化したAidemyの Aidemy Premium 自然言語処理講座(3か月)を受講しました。3か月間でプログラミングスキルが無い私が、Aidemyのサポートをもらいながらチャットボットを作ったプロセスをお伝えします!
2.実行環境
windows 11
Python 3.7.13
Google Colaboratory
Microsoft Visual Studio 2022
LINE Massaging API
Heroku
git CMD
3.データ
まず、今回想定したモデルですが、「調子を尋ねるチャットボット」と定めました。現時点のスキルやリソースではカウンセリングするチャットボットは困難だと考え、話し手の体調や状況について具体的に聞き、それに対する気分や感情について質問します。雑談はどちらも話し手にもなり聴き手にもなるものですが、今回は話し手と聴き手の立場を明確に分け、聴き手がチャットボットになるようにしました。

また、雑談のように幅広い会話にならないよう、全ての会話は聴き手の「こんにちは。調子はどうですか?」から始まるように設定しました。話し手の調子について具体的に聴いたり発話を促すようにしたいため、あえて発話のバリエーションを少なくしました。的外れな会話になることを防ぐために、あたりさわりのない発話を設定しました。

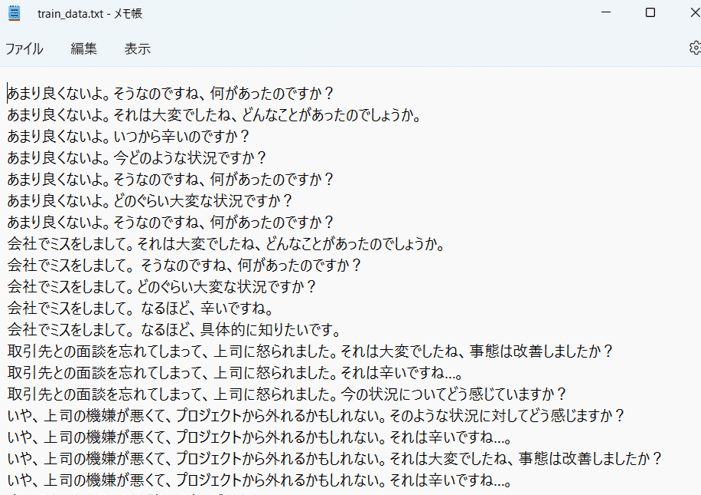
上記の理由から既存の雑談コーパスは使えないので自作しました。これが1番しんどい作業でした…!以下がおおまかなコーパス作成の流れです。なお、下記の作業は主にエクセルとテキストを用いています。
(1) 聴き手の発話リストをある程度設定する。
(2) 架空で様々な会話を考える。話し手と聴き手の会話はそれぞれ7,8ターンとしてそれを1例とする。聴き手は発話リストの中から選び、選べない場合は新たな発話としてにリストに追加する。
(3) 100例まで自作する。家族や大学教員の友人の学生の方数名に協力を依頼し、例をもとに作成してもらう。その間自分も引き続きデータを追加する。※協力してくださった方、本当にありがとうございました!
この時点で合計200例、7ターン、計1400ターンを作成しました。データ数を増やすために話し手の発話に対して5~7個聴き手の発話を水増ししました。その結果2万弱のターンに増えました。これらの作業に約3週間かかりました。
4. 制作プロセス
モデルを作成するにあたり、巨大言語モデルとTransformerを使いたいと考えました。理由は単純に、現在のチャットボットのモデルの主流なのでそれを学びたいと思ったからです。
まず興味を持ったのがBERTです。BERTはBidirectional Encoder Representations from Transformersの略でGoogle社が2018年に発表した自然言語処理モデルです。WikipediaやBooksCorpusなどの膨大な言語を「Masked Language Model」や「Next Sentence Prediction」という手法で学習します。その学習済モデルを使って、少ないデータを用いて感情分析やニュースのカテゴリー分類など特定のタスクを行う(ファインチューニング)ことが出来ます。学習済モデルとして東北大BERTがあります。
BERTを用いたチャットボットのモデルとして、reppy4620さんの「BERTをEncoderとするChatbotの作成」のブログおよびブログで紹介しているGithubを参考にしてみました。
(補足)上記のコードを使用するために、コーパステキストファイルは話し手の発話・聴き手の発話・空白の3行で構成する必要があります。今回作成過程の詳細は割愛します。

結果はこちら…

あらら…同じことしか言いません(泣) 私のデータ数が少ないことが理由だと思われます。
何度か試しましたが、同じことしか言わない結果は揺ぎなかったので別のモデルを探りました。
次に、GPTで試しました。GPTはOpenAI社が開発した言語モデルです。GPT-2は2019年に発表されました。最新(2022年6月現在)は2020年に 発表されたGPT-3です。GPTはとにかく膨大な言語を学習しています。GPT-2では15億パラメータ、GPT-3では1,750億パラメータ数を使用しているそうです。すごいですね…!
女子高生チャットボット「りんな」でお馴染みのrinna社が、日本語に特化したGPT-2の大規模言語モデルを開発しオープンソース化しています(参考記事はこちら)。自然言語処理研究の発展のために、開発した言語モデルやトレーニングコードをGitHub、HuggingFaceで、オープンソースとして公開しています。これもすごいことですね…!
今回この学習済モデルを用いてチャットボットを作ってみました。つまり、学習済モデルではある文章に対してその後のテキストを自動生成しますが、それを発話に置換え、(話し手の)発話後の(聴き手の)発話を自動生成するように学習させました。

5.完成コード
モデル作成において非常に役立ったのが、Vtuberあざいるうかさんの「りんな GPT-2 の fine tuningをGoogle Colabの無料枠で試す方法」です。知識が乏しい私でも理解できる程、簡潔でわかりやすく紹介してくださっています。これを見ながら作成しました(一部異なる部分があります)。
準備としてGoogle Drive→My Drive内にフォルダを作成し、そこにテキストファイルのコーパスデータを入れておきます。
またGoogle Colabの「ノートブックの設定」で「ハードウェアアクセラレータ」を「GPU」に選択します。
まず、以下のコードでGoogle Colabを使うためのライブラリをインポートします。
from google.colab import drivedrive 配下のディレクトリをマウントします。
!mkdir -pで作成したフォルダのディレクトリ名を作成します。ちなみに私のフォルダは「ChatBot_gpt2」です。
%cdで作成したディレクトリに移動します。
drive.mount('/content/drive')
!mkdir -p '/content/drive/MyDrive/ChatBot_gpt2/'
%cd '/content/drive/MyDrive/ChatBot_gpt2/'!git cloneでhuggingface社がGithubで公開しているtransformersをクローンします。
その後クローンしたtransformersをインストールします。
ファインチューニングの進捗状況を可視化するために必要なtqdmをインストールします。
!git clone https://github.com/huggingface/transformers -b v4.4.2
!pip install transformers==4.4.2
!pip install tqdm==4.62.3datasets、sentencepieceをインストールします。
!pip install datasets==1.2.1
!pip install sentencepiece==0.1.91ここでGoogle Driveを開き、作成したフォルダ(私の場合「ChatBot_gpt2」)内の「transformers」を開きます。

「transformers」→「examples」→「language-modeling」フォルダに移動します。
そのフォルダ内にあるrun_clm.pyを開きます(私の場合、ダウンロードしてVisual Studioで開きました)。
ライブラリ宣言部分にfrom transformers import T5Tokenizerを追加します。

AutoTokenizerをT5Tokenizerに置換します。

(デクストップなどお好きなところに)ファイルを保存し、Google Drive内のrun_clm.pyのファイルを上書きします。
Google Colabに戻ります。
結果の処理を保存できるライブラリdillをインストール・インポートします。
!pip install dill==0.3.3
import dill以下のコードでrinna/japanese-gpt2-medium、すなわちrinnaの学習済GPT-2モデル(ここではmedium)を読み込みます。tain_fileとvalidation_fileはコーパステキストファイル名を指定します(私の場合は「train_data.txt」)。
その他のパラメータはあざいるぅかさんが設定した通りにしました。
!python ./transformers/examples/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-medium \
--train_file=train_data.txt \
--validation_file=train_data.txt \
--do_train \
--do_eval \
--num_train_epochs=3 \
--save_steps=5000 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--output_dir=output/ \
--use_fast_tokenizer=Falseログ履歴の表示をオフにするためのコードを記述します。これを記述していないと会話の度にログの履歴が表示されます。
import logging
logging.disable(logging.FATAL)以下のコードでrinnaのjapanese-gpt2-mediumを読み込みます。
from transformers import T5Tokenizer, AutoModelForCausalLM
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")以下のコードで作成したファインチューニングしたモデルを読み込みます。
model = AutoModelForCausalLM.from_pretrained("output/")
出力を設定します。
まず、当初の設定通り、最初にボット(聴き手)による「"アイ:こんにちは。調子はどうですか?」から会話を始めたいのでprintで設定します(人間味を持たせたかったので「アイ」さんにしてみました)。
while, if構文を用いてあなた(話し手)がqを入力すると会話が終わり(「あなたと話ができてよかったです。また話をしましょう」)、それ以外は発話の入力が表示されるようにします。
print("アイ:こんにちは。調子はどうですか?")
while True:
you = input("You : ")
if you =="q":
print(f"アイ : あなたと話ができてよかったです。また話をしましょう")
breakインデックス化した発話をinput_に代入します。それをoutput_で文章化します(デコードします)。
top_pで発話の後に生成するテキストを確率として当てはまり具合が高いものを設定します。
top_kで言葉の候補をサンプリングした際、確率の上位候補を絞ります。 bad_words_idsで、<MASK>などを生成しないように設定します。no_repeat_ngram_sizeで繰り返しの文言が続く回数を設定します。デフォルトは1です。
length = len(you) + 4は先頭から不要な文字列を削除するために設定します。
input_ = tokenizer.encode(you, return_tensors="pt")
output_0 = model.generate(input_, do_sample=True, max_length=40, num_return_sequences=1,
top_p=0.95, top_k=20, bad_words_ids=[[1],[2],[5]], no_repeat_ngram_size=1)
output_1 = tokenizer.batch_decode(output_0)
length = len(you) + 4
output = output_1[0][length:50]
print(f"アイ : {output}")ただし、下記のコードだけではいくつか不具合が出てきます。
まず、元々のモデルが発話後のテキストを自動生成するものです。
ですので例えばoutput_1[0][length:50]で設定すると文字列50の長さまで延々と自動生成してしまいます。

かといって、短い設定にすると途中で文章が切れてしまいます。
そこで考えたのがスライスです。「。/!/?」といった文末表記以前の文章を取得すればちょうど良い文章で終わってくれると考えました。

ただし、このままだと「。/!/?」は削除されてしまうので、スライス後「。/!/?」を追加するようにしました。
さらに、元々の学習済の言語の性質上、顔文字や(笑)といった表記が混ざることがありました。「それは辛いですね(笑)」という発話が生成されることがあったので、replaceで記号は空白に置換するようにしました。
以下がmodel = AutoModelForCausalLM.from_pretrained("output/")以降修正したコードです。
なお、一般的な文字列の操作のためにstringをインポートします。発話が途中で切れないように output_1[0][length:60]と、長めに設定しています。
model = AutoModelForCausalLM.from_pretrained("output/")
import string
tex = ["。", "?", "?" , "!", "!", "." ]
print("アイ:こんにちは。調子はどうですか?")
while True:
you = input("あなた : ")
if you =="q":
print(f"アイ : あなたと話ができてよかったです。また話をしましょう")
break
input_ = tokenizer.encode(you, return_tensors="pt")
output_0 = model.generate(input_, do_sample=True, max_length=40, num_return_sequences=1,
top_p=0.95, top_k=20, bad_words_ids=[[1],[2],[5]], no_repeat_ngram_size=1)
output_1 = tokenizer.batch_decode(output_0)
length = len(you) + 4
output = output = output_1[0][length:60].replace("/","").replace("</","").replace("(","").replace(")","").replace("^","").replace(">","").replace("<","").replace("「","").replace("」","")
for t in tex:
if t in output:
output = output.split(t)[0] + t
else:
output
print(f"アイ: {output}")結果は以下となります。時々ちぐはぐなことを言う・同じことを繰り返しますが、明らかにおかしいことは言わない印象です。


6.LINE Bot化の流れ
欲が出てきまして、LINEでチャットしたくなりました。そこで、LINEBotに関するブログ「【初心者向け】PythonによるHeroku環境で簡単LINEBot開発」や「Pythonで作る竈門炭治郎のLINE BOT」を参考にしました。
上記のブログで詳細に記載されていますので、ここでは流れを簡潔にお伝えします。
6.1. 準備
-1-
完成コードをoutputし、main.pyとして保存します。
デスクトップにフォルダ(例:Line_Bot)を作成し、そこに
main.pyのデータを保存します。さらに、以下のデータを追加します。
procfile (形式は指定しない)
requirements.text
runtime.text
outputフォルダ
procfileにはweb: python main.pyと入力しておきます。main.pyというpythonファイルを動かすためです。
web: python main.py
requirements.textには必要なライブラリとそのバージョンについて入力しておきます。ちなみにpytorchは軽量化のためcpu版にします(参考:PyTorchを使ったアプリをHerokuにディプロイする際の注意点)。
flask==2.0.1
line-bot-sdk==1.16.0
transformers==4.4.2
sentencepiece==0.1.91
datasets==1.2.1
--find-links https://download.pytorch.org/whl/torch_stable.html
torch==1.7.1+cpu
runtime.textでは使用するpythonのバージョンを記載しておきます。
python-3.7.13
最後にoutputフォルダですが、こちらはGoogle Colabでファインチューニングを学習した結果のデータとなります。5.で作成したGoogle Colabのコードをもう一度表示します。
!python ./transformers/examples/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-medium \
--train_file=train_data.txt \
--validation_file=train_data.txt \
--do_train \
--do_eval \
--num_train_epochs=3 \
--save_steps=5000 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--output_dir=output/ \
--use_fast_tokenizer=False下から2番目のoutput_dir=output/、これでoutputディレクトリに学習結果が入っています。試しにMy Driveを見てみます。
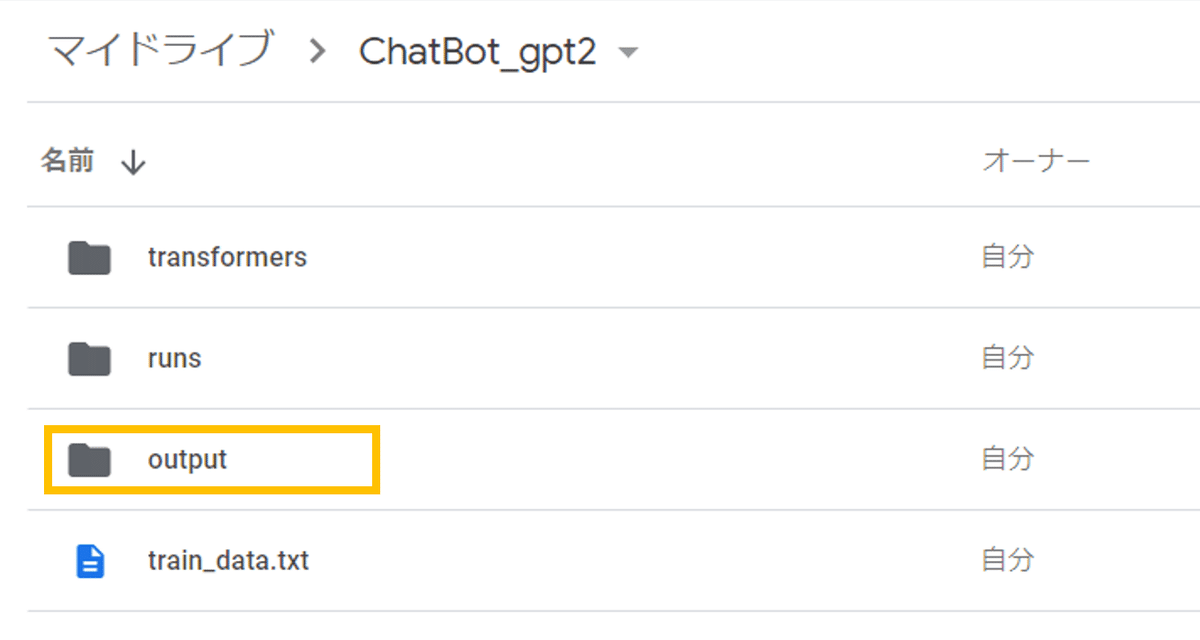
このoutputフォルダをダウンロードし、デスクトップのフォルダに追加します。
ちなみに、データを追加するなどファインチューニングし直したい場合、同じディレクトリ名にすることが出来ないのでoutput_dir=output2/など別名にします。
-2-
作成したコードをWebアプリケーション化し、管理・運用してくれるサービスとして主にHerokuが用いられています。
Herokuのアカウントを作成しNew appを作成します。
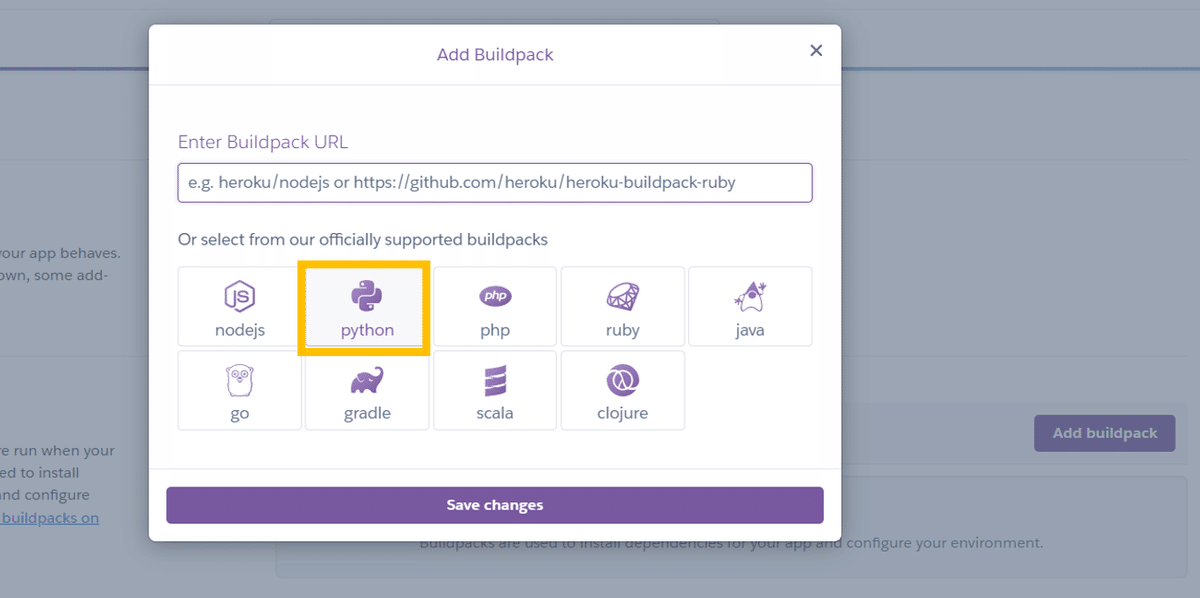
setting→Buildpacks→Add Buildpackでpythonを選択します。
Domeinsで表示されているURLは-3-で必要になります。

-3-
LINE Developersのアカウントを作成し、Massaging APIのチャネルを作成します。※詳細は様々なブログで紹介されていますので割愛します。
Massaging API設定→応答設定では応答モード=Bot、あいさつメッセージ=オン、応答メッセージ=オフ、webhook=オンに設定します。大体のチャットボットはあいさつメッセージをオフにしていますが、私の場合調子を尋ねるボットなので、図のようなあいさつにしました。

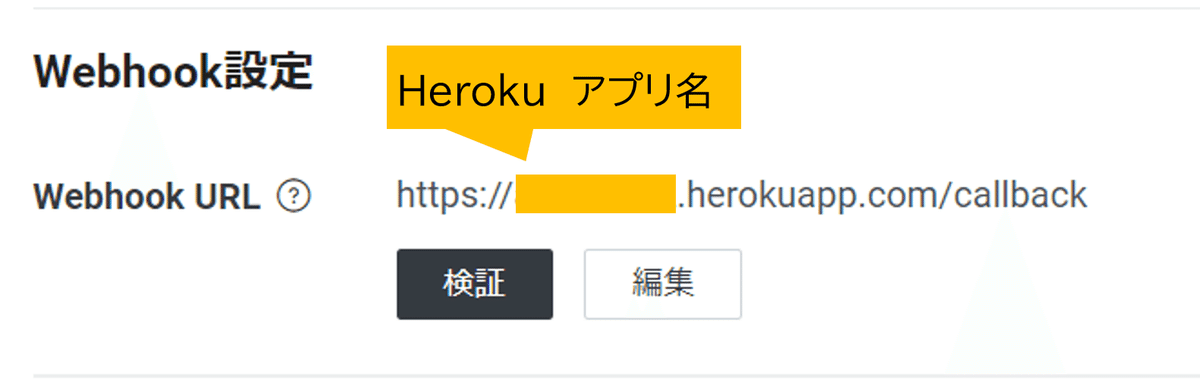
Webhook設定→Webhook URLで、さきほどherokuで作成したURLに/callbackを加えます。
また、Massaging API設定にある、チャネルアクセストークン、チャネル基本設定にあるチャネルシークレットを発行します。
-4-
git をインストールします。
6.2. main.pyのコード
Pythonのコード上でOS(オペレーティング・システム)に関する操作を実現するためにosをインポートします。
ウェブアプリケーション開発のためのpythonフレームワークであるflaskをインポートします。他は先ほどと同様です。
from flask import Flask, request, abort
import os
import logging
from transformers import T5Tokenizer, AutoModelForCausalLM
import string
logging.disable(logging.FATAL)
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage,
)変数appにFlaskを代入しインスタンス化します。
学習済GPT-2およびファインチューニングしたモデルをtokenizer、modelに代入します。
環境変数を設定し、LineBotAPIやHandlerを動かせるようにします。
YOUR_CHANNEL_ACCESS_TOKENにはLINE のチャネルで発行したチャネルアクセストークン、YOUR_CHANNEL_SECRETにはチャネルシークレットを入力します(いずれも二重引用符で囲みます)。
# 変数appにFlaskを代入。インスタンス化
app = Flask(__name__)
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
model = AutoModelForCausalLM.from_pretrained("output/")
YOUR_CHANNEL_ACCESS_TOKEN = "チャネルアクセストークン"
YOUR_CHANNEL_SECRET = "チャネルシークレット"
line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(YOUR_CHANNEL_SECRET)以下、line-bot-sdkをもとに作成しています。ブログ「Pyhon line-bot-sdkによるLINE Botの始め方」で詳細が記述されています。
LINEユーザーが公式Lineアカウントへメッセージを送り、Messaging APIがそれを受け取る。
Messaging APIに登録しているWebhook URL(Bot server)へHTTPS POSTリクエストを送る。
受け取ったリクエストの"Header"の著名と"Body"をサーバーに登録している秘密鍵によってエンコードされた著名が一致するかどうか検証する。
承認されればBotが応答し、その結果をMessaging APIへ返す。Messaging APIから公式LINEアカウントへ返す。
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'LINEでMessageEvent(普通のメッセージを送信された場合)が起こった場合に、 def以下の関数を実行します。
reply_messageの第一引数のevent.reply_tokenは、イベントの応答に用いるトークンです。第二引数には、linebot.modelsに定義されている返信用のTextSendMessageオブジェクトを渡しています。なお、print("アイ:こんにちは。調子はどうですか?")のコードはLINEでは適していないので削除します。
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
tex = ["。", "?", "?" , "!", "!", "." ]
message = event.message.text
input_ = tokenizer.encode(message, return_tensors="pt")
output_0 = model.generate(input_, do_sample=True, max_length=40, num_return_sequences=1,
top_p=0.95, top_k=20, bad_words_ids=[[1],[2],[5]], no_repeat_ngram_size=1)
output_1 = tokenizer.batch_decode(output_0)
length = len(message) + 4
output = output_1[0][length:50].replace("</s>","").replace("</","").replace("(笑)","").replace("^","")
for t in tex:
if t in output:
output = output.split(t)[0] + t
else:
output
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=output))
if __name__ == "__main__":
port = int(os.getenv("PORT",5000))
app.run(host="0.0.0.0", port=port)6.3 Herokuへデプロイ
6.2.で作成したmain.py及び6.1.で準備したデータを格納したフォルダをデスクトップに保存します(ここではフォルダ名を「Line_Bot」としました)。
それらのデータをHerokuでデプロイ(サービス公開)するための手順をgit CMDで行います(ターミナルで行っているサイトがありましたが、私はなぜかうまくいかなかったのでこちらを使います)。
まず、git CMDを開きます。cd(change directory)で対象のフォルダ(ここでは「Line_Bot」)に移動します。
cd OneDrive
cd デスクトップ
cd Line_Bot以下のコードでherokuにログインします。heroku: Press any key to open up the browser to login or q to exit:と表示されますのでEnterキーなどをクリックします。そうするとブラウザでherokuのログイン画面が表示されますのでログインします。
heroku login以下のコードを入力します。アプリ名はherokuで作成したアプリ名です。私の場合はaibot2022としたので、heroku git:remote -a aibot2022と入力します。
git init
heroku git:remote -a アプリ名
git add .以下のコードを入力します。メッセージには"initial commit"や"first commit"などを入力します。git push heroku masterでHerokuをデプロイします。これはある程度時間がかかります。
git commit -m "メッセージ"
git push heroku masterするとpush出来ずエラーになりました…(泣)
理由はSize of checkout and restored submodules exceeds 1 GB.とのことです。
なお、サイズが500MBを超えるとCompiled slug size: ○○M is too large (max is 500M)となりpushしてくれません。
See: http://devcenter.heroku.com/articles/slug-sizeと記載していたので見てみます。
Here are some techniques for reducing slug size:
Move large assets like PDFs or audio files to asset storage.
Remove unneeded dependencies and exclude unnecessary files via.slugignore.
Purge the build cache.
上記のサイトを参考にしてpushをしたものの、何度もはねのけられてしまいました。slugignoreファイルを作って不要なファイルを加えないようにしてみましたが大きさは微動だに変わりませんでした。
そもそもrinnaのGPT-2学習済モデルが大きすぎることに気づき、5.の作業をやり直し、rinna/japanese-gpt2-mediumの"medium"をxsmallに変更しました。
そしたら、ようやくデプロイできました…!この時の感動もひとしおです。
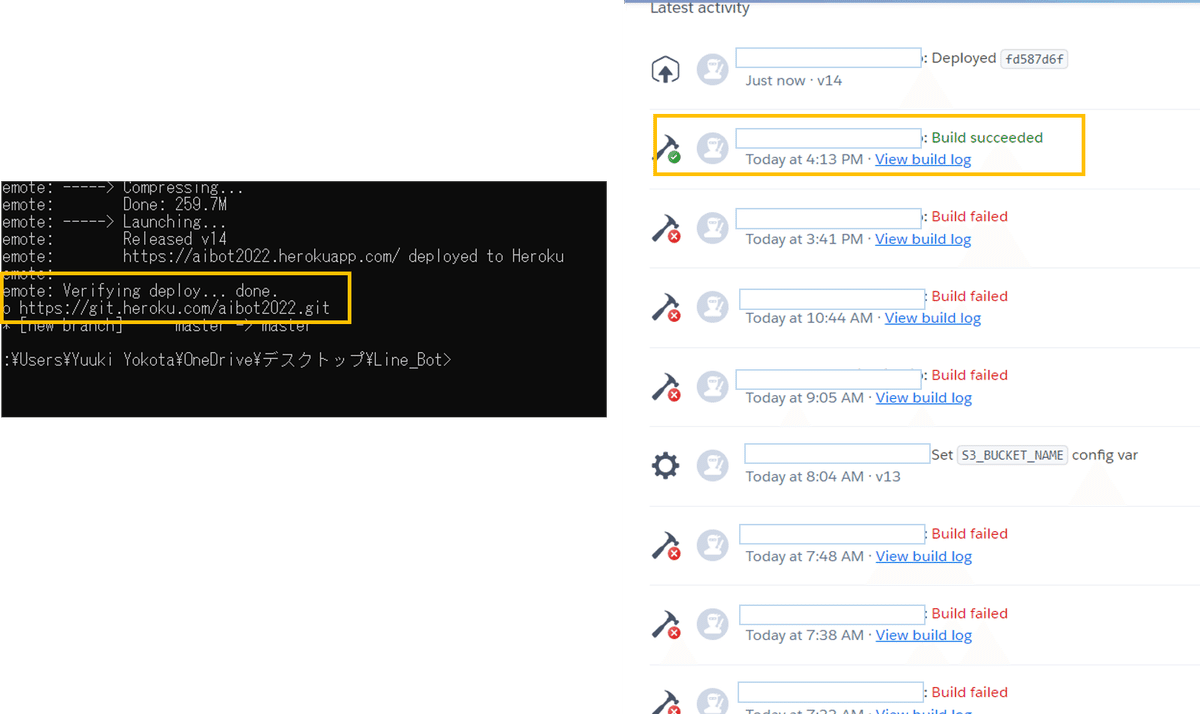
その後、以下を入力します。二重引用符の中はLINEのチャネルアクセストークン・チャネルシークレット、--appの後のアプリ名はHerokuで作ったアプリ名を入力します。
heroku config:set LINE_CHANNEL_ACCESS_TOKEN="チャネルアクセストークン" --app アプリ名
heroku config:set LINE_CHANNEL_SECRET="チャネルシークレット" --app アプリ名 7.LINE Bot完成
6.で失敗談は割愛しましたが、完成までかなり悪戦苦闘して、ずっと一方通行にLINEに話しかけていました。
「ようやくしゃべった…!」
ボットが私に応えてくれた…喜び再びです。
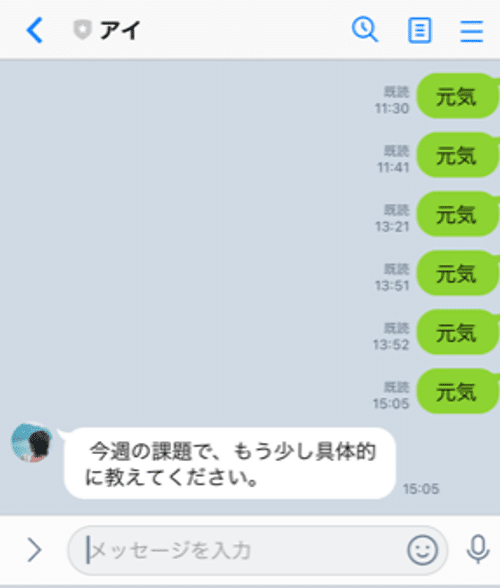
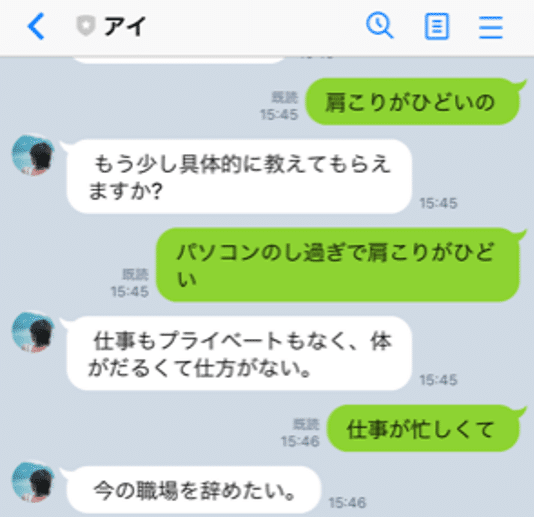
ただし残念なことがありまして、会話の質が劣化したんですよね。なぜなら学習済データをxsmallに変えたからです。mediumですと約1.2GBでしたがxsmallですと約152KB、つまり約10倍まで軽量化出来ました。その分学習が出来ていないということですね。Herokuの制限がありますので、こればかりは仕方ないです。別の方法で運用する必要があります(またお金がかかりそうです)。
ちなみにクレジットカードを登録すれば月1000時間まで利用できるみたいです(参考「Heroku DynoのFreeプラン(無料プラン)はどこまで使えるか?」)。また、ブログ「無料枠サーバーを24時間スリープさせない方法」を参考に、定期的にアクセスしスリーブ状態にしないようにしました。
こうして初心者が目標のLINEBot化まで到達しました。
8.終わりに
今回のチャットボットは、話し手の発話に対して予測される聴き手の発話を自動生成するものでした。巨大言語モデルを使用することで多少ちぐはぐさがあるものの、自然な応答を生成することが出来ました。ただし、話し手の発話の入力の度にそれに続く文を生成するので、その前の会話の文脈を把握していないといことが課題です。後は単純に学習データが少ないため、地道にデータを追加したいと思います。
初心者が今回のタスクを実現するには限界がありました。Aidemyのサポート無くしては実現できませんでした、感謝申し上げます。
今回得た知識と体験をもとに、さらなるスキルアップのために継続して勉強します。
追記:続編もご覧ください!
心理カウンセラーがチャットボットを作ってみた。その2|Lani-Kai|note
この記事が気に入ったらサポートをしてみませんか?