
NVIDIAが切り開いたAI半導体市場: 裾野拡がる市場の細分化(3)アーキテクチャ編(第2版)

3Dグラフィックスの処理に特化したGPUは、深層学習の行列演算を大量かつ高速に処理する能力を持っており、そのため、CPU(汎用プロセッサ)に代わってAIタスクを処理する主流の半導体となっています。しかし、元々グラフィック処理用に設計されたGPUは、AIアクセラレーターとしての処理効率とエネルギー効率の限界が指摘されています。そして、AIモデルの大規模化やAIタスクが複雑になるにつれて、これらの課題がより顕著になると予想されています。
これらの課題に対応するための取り組みとして、AIタスクに特化したドメインスペシフィックアクセラレーター(以下、DSA)という技術革新領域があります。DSAは、自然言語処理など特定のAIタスクに特化したハードウェアで、汎用チップと比較して高い性能やエネルギー効率を実現しています。以前、「ハイパースケーラー編」で紹介したハイパースケーラーが開発するASICなども、DSAに含むことができます。
今回は、このDSAに焦点を当て、従来のコンピューティングアーキテクチャに起因する課題の解決を目指している、ユニコーン企業を含む新興企業のAIアクセラレーターやそのシステムについて紹介してみたいと思います。
尚、本投稿の記載の通り、前置きだけでかなり冗長な内容になってしまったため、各社の紹介記事については別投稿させて頂きます。(工事中含む)
※ 2024/3/21(木)第2版修正
(2)ユニコーン企業編 Part 2 を追加しました。
1. 汎用アクセラレーターの課題とDSA
(1)GPUの課題について
まず、AIタスクを処理する際にGPUを用いることの課題について説明します。GPUの主な課題は、元々グラフィック処理に特化した設計であるため、AIタスクに最適化されていない点にあります。
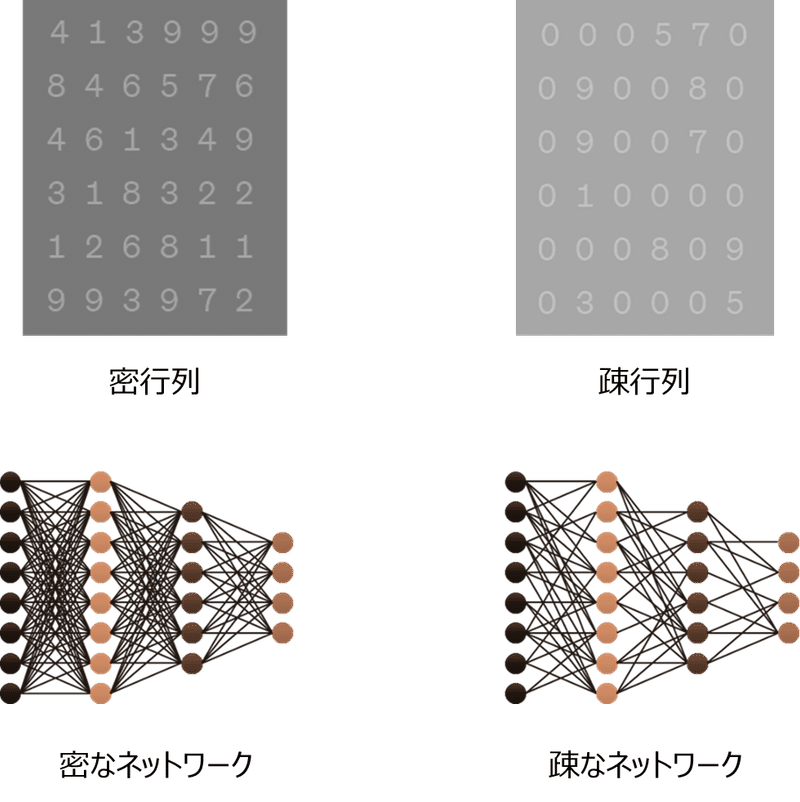
GPUはシングルインストラクション・マルチプルデータ(SIMD)アーキテクチャを採用しており、1つの命令を複数のデータに対して同時に並列処理する能力に長けています。この特性は、AIタスクが3Dグラフィックス処理のような密集した行列の並列計算を要する場合には、非常に効果的で、汎用CPUを大きく上回る性能を発揮します。しかし、自然言語処理やグラフニューラルネットワーク(GNN)などのAIアプリケーションにおいて頻繁に発生する疎の状態にある行列の計算との相性は良くないことが分かっています。疎な行列とは、要素の多くがゼロである行列のことを指しますが、GPUでこれらの行列を効率的に扱うことが難しいことから、計算性能に制限が生じてしまいます。つまり、疎の状態にある行列では、ゼロ値が多いことから、演算の必要な割合が減少するにもかかわらず、SIMDアーキテクチャのGPUでは、計算不要なゼロ値のデータに対しても演算してしまい、計算資源の無駄遣い、計算時間の増加、エネルギー消費の増大といった非効率性をもたらしてしまいます。
そして現在、GPTのような自然言語処理をベースとする大規模言語モデルのモデルサイズが拡大していることから、これらGPUの課題に関心が寄せられている状況にあります。
(2)処理効率とエネルギー効率
2024年2月に発表されたSambaNova社のSamba-1や米国アルゴンヌ国立研究所のAuroraGPTによって、1兆パラメータを超えるモデルが登場しました。これらは、モデルのパラメータサイズを大きくすることで精度や性能を向上させるスケーリング法則が現在も有効であることを示しています。しかし、これらの大規模モデルの開発と運用には、膨大な計算資源やエネルギーが必要となります。そのため、処理効率やエネルギー効率の改善に今以上に向き合うことが求められることになります。
これまで、ムーアの法則に基づいて演算回路の計算性能は著しく向上してきましたが、昨今は、メモリの性能が今後のコンピューティング性能の大きなボトルネックになると見られています。具体的には、メモリからデータを取り出す速度が演算回路の計算性能に追いつかず、これがボトルネックとなってシステム全体のパフォーマンスを低下させる原因となってしまうということです。
現在のコンピューティングシステムでは、データは使用頻度や速度要求に応じて階層化されたメモリに各々配置されます。頻繁に高速アクセスが必要なデータは高速なキャッシュメモリに保持され、繰り返しアクセスされることで、転送速度の低さを隠蔽しています。しかし、この方法は密なデータ構造を扱う場合には有効ですが、不規則なアクセスパターンを持つ疎なデータ構造を扱う場合、キャッシュのヒット率が低下してしまうため、上述のキャッシュシステムの効果が減少してしまいます。
加えて、エネルギー効率の問題も隣接する課題として存在します。プロセッサ間やプロセッサとメモリ間でデータを移動する際に発生するエネルギー消費は、計算処理時の消費エネルギーよりも大幅に高く、特にAIアプリケーションのように大量のデータを移動させる必要がある場合、電力消費は大きな問題となります。
以下に、エネルギー消費の具体的イメージを共有します。この例を通じて、データの移動がエネルギー消費に大きく影響を与えることを理解いただけると思います。尚、ピコジュールはエネルギーの単位です。
半導体内で64ビットの倍精度演算を1回行う際には、20ピコジュールのエネルギーが消費されます。
半導体内でデータが1ミリメートル移動する際、26ピコジュールのエネルギーが消費されます。
データが10ミリメートル移動すると、256ピコジュールのエネルギーが消費されます。
DRAMやHBMなどの外部メモリからデータを取得する際、16,000ピコジュールのエネルギーが消費されます。
(3)DSAのハードウェアフォーマット
特定のアプリケーションやタスクに特化して設計されるDSAに利用される代表的なハードウェアには、FPGA(Field Programmable Gate Array)とASIC(Application-Specific Integrated Circuit)があります。CPUやGPUは、汎用の演算回路であることからDSAには分類されません。
FPGAは、数千から数百万の論理セル(ゲートアレイ)が配置されたハードウェアチップで、VHDLなどのハードウェア記述言語を用いてロジックを開発し、ハードウェアにプログラムすることで独自の論理チップを作成することができます。また、完成後もプログラムによって回路構成を変更できる柔軟性も特長です。一方、ASICは特定のアプリケーション専用に設計されたロジックに基づき製造される半導体チップで、完成後の回路構成の変更はできませんが、特定のタスクに対して高いエネルギー効率と処理性能を提供します。FPGAとASICの使い分けは、プロトタイピングや少量生産では初期コストが低く、市場投入までの時間を短縮できるFPGAが適しています。一方、大量生産の場合、単位あたりのコストが低く、高度な演算回路を最適化できるASICが適しています。
さらに、特定のアプリケーションに最適化されつつも、変化する市場ニーズや技術要求に柔軟に対応できるプログラマブルASICやリコンフィギュラブルチップ(Reconfigurable Chip)のようなDSAも存在します。これらの技術は比較的新しい分野に属しており、性能やエネルギー効率を最適化する一方で、柔軟性とプログラム可能性を兼ね備えています。これにより、特定のアプリケーションやタスクに特化したアクセラレーターチップの開発で利用されています。
① プログラマブルASIC
プログラマブルASICは、従来のASICの性能と効率を維持しながら、プログラムによる柔軟性を追加した新しいタイプの集積回路です。ASICは一度製造されると、その機能を後から変更することはできませんが、プログラマブルASICは製造後もソフトウェアを通じて特定の機能やパラメータの調整が可能です。この特性により、開発者は柔軟に回路の動作を変更でき、変化する技術要求に効率的に対応することができます。プログラマブルASICには、eFPGAを搭載したASICや、ロジックブロックの接続方法を後からプログラム可能にするASICなどがあります。また、プログラマブルASICに分類されるかは定かではありませんが、Xilinx社やIntel社が提供するプログラム可能なロジックを搭載したSoC(System on Chip)、Infineon Technologies社のPSoC(Programmable System on Chip)なども存在しています。
② リコンフィギュラブルチップ
リコンフィギュラブルチップは、ハードウェア構成を動的に変更できる先進的なチップです。この分野では既に活発な研究開発が進められており、特定の用途や性能要求に深く特化して設計されることで、効率的かつ高速な演算を実現し、より消費電力を抑えられるチップの完成が期待されています。尚、リコンフィギュラブルチップは、リコンフィギュラブル・コンピューティングやアダプティブ・コンピューティングといったより大きなコンセプトの文脈の中で、重要な要素技術の1つとして位置づけられています。
(4)非ノイマン型アーキテクチャ
ノイマン型アーキテクチャは、演算器を計算システムの中心に置き、記憶装置からデータと命令を取り出して処理する方式で、現代の多くのコンピュータシステムの基礎となるアーキテクチャです。しかし、このアーキテクチャは上述(2)で示した通り、演算回路とメモリの速度差が拡大するにつれ、特に大量のデータを扱うAIアプリケーションにおいて、システム全体の処理性能とエネルギー消費における課題が顕著となります。
この課題に対し、ノイマン型のボトルネックを解消する非ノイマン型のアーキテクチャによる提案が多く生まれています。これらの提案には、データや命令の処理方式が異なるものや、データの移動を少なくして効率的な計算を行うような提案などがあり、これらの提案によって演算処理速度やエネルギー消費の問題が解決されることが期待されています。
以下の①②③は、AIアクセラレーターの開発で採用されている非ノイマン型のテクノロジーですが、ユニコーン編として紹介する企業の多くは、これらテクノロジーのいずれかの要素を取り入れています。
① Compute in memory architecture
データの演算をメモリ内で直接行います。これにより、データ移動が原因で生じる遅延とエネルギー消費を削減し、演算性能を大幅に向上させることが可能です。特に、メモリアクセスが性能のボトルネック原因となっていた疎行列計算において、顕著な改善の期待されているアーキテクチャです。
② Dataflow Computing
従来のCPUやGPUなどの演算回路は、密な行列計算を得意としていますが、ゼロが多く含まれる疎行列の計算では、不要な計算や不要なメモリアクセスが増え、システムの性能を低下させるという課題があります。
Dataflow Computingは、データが準備されたら自動的に演算を開始する方式を採用しており、プログラムの実行がデータの流れに基づいて動的に制御されます。この手法では、各コアが独立して動作し、高度な並列処理が可能なため、疎行列の扱いに長けており、不要な計算を避け、必要な計算のみを処理することで、計算資源を最適利用し、性能低下とエネルギー消費を抑えることが期待されるテクノロジーです。
③ ニューロモルフィックコンピューティング
ニューロモルフィックコンピューティングは、人間の脳のように効率的で柔軟な計算を目指し、ニューロモルフィックチップを用いて従来とは異なる方法で情報処理を行う技術です。このコンピューティング手法では、エネルギー消費を大幅に削減しながら、複雑な認識、学習、推論タスクを効率的に処理する能力が期待されています。
尚、ニューロモルフィックチップは、ニューロモルフィックコンピューティングを実現するための構成要素となる半導体であり、人間の脳の構造や機能を模倣した特殊な演算回路を指し、技術傾向としては、アナログ半導体技術を活用し、脳に近い処理方法で情報を扱う試みが比較的良く見受けられます。
2. ユニコーン企業編
(1) ユニコーン企業編 Part 1
ピックアップ企業 : Cerebras Systems と Groq
(2)ユニコーン企業編 Part 2
ピックアップ企業 : SambaNova Systems と Graphcore
3. 過去の関連記事
(1) 主要半導体メーカー編
(2) ハイパースケーラー編
御礼
最後までお読み頂きまして誠に有難うございます。 今後ともどうぞよろしくお願いいたします。
だうじょん
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。
この記事が気に入ったらサポートをしてみませんか?