
NVIDIAが切り開いたAI半導体市場: 裾野拡がる市場の細分化(4)ユニコーン編(その1)

今回は、AIアクセラレーターを開発・販売するユニコーン企業として、米国カリフォルニア州シリコンバレーに拠点を置くCerebras Systems社とGroq社の2社を紹介します。ユニコーン企業とは、設立から10年以内で未上場の企業であり、企業評価額が10億ドル以上のベンチャー企業を指します。
これらの企業は、AIや機械学習のタスクを高速化するために設計された専用のAIハードウェアとコンピューティングプラットフォームの開発に、独自のアプローチで取り組んでいます。生成AIの社会実装が徐々に拡がる中、新たに顕在化する課題に対して、イノベーティブなテクノロジーを駆使して積極的に取り組んでいる企業です。

1. Cerebras Systems

(1)企業概要
Cerebras Systems社は、AI・機械学習を加速させる新しいコンピュータシステムをゼロから設計する目的で、コンピュータアーキテクト、機械学習研究者、システムエンジニア、ソフトウェアエンジニアが集まり、2015年に米国カリフォルニア州サニーベールで設立された企業です。
同社が開発・販売しているWafer Scale Engine(以下、WSE)は、AI分野の計算処理能力を飛躍的に向上させる製品として、市場から高い関心が寄せられており、すでに多数の企業や研究機関で採用されています。
WSEの技術の中心は、AIワークロードを加速するための革新的なアプローチ方法にあり、数百億のトランジスタと数千のコアを独自のアーキテクチャで単一の巨大チップ上に配置することにより、特に深層学習の計算能力で類を見ない性能を実現しています。
WSEは既に商用販売されており、クラウドやデータセンターでのコンピューティングリソースとして、また医療・製薬、金融サービス、エネルギー、科学計算など、様々な産業アプリケーションでの利用が進んでいます。
(2)プロダクト
トランスフォーマーなどの深層学習をベースとした生成AIの計算処理においては、多数のGPUを並列化して処理の高速化を図っています。しかし、GPUそのものは深層学習専用に開発されたわけではなく、また更に、処理規模が大きくなるにつれてクラスタのオーバーヘッドが増大するため、性能の向上に課題が出てきます
Cerebras社が開発した深層学習専用の巨大な半導体チップであるWSEは、従来のGPUクラスタの複雑さやプログラミングの難しさを解消し、深層学習の処理を単一デバイスで高速に実行することができます。

NVIDIA A100(右)とのサイズ比較(出典:Cerebras社 クリックして拡大)
Cerebras社の製品ラインナップは、WSEを搭載したコンピューティングシステムのハードウェアとソフトウェアで構成されています。ハードウェアには、データセンターに設置される「CS-2」、さらには「CS-2」を用いて巨大クラスタ化したAIスーパーコンピュータの「Condor Galaxy 1」や「Andromeda」があります。また、これらのハードウェアの性能を最大限に引き出すためのソフトウェア群として、「Cerebras AI Model Studio」や「CSoft」、「Cerebras ML Software」や「ソフトウェア開発キット(SDK)」が提供されています。加えて、CerebrasのシステムをPaaSとして利用できるクラウドサービスも用意されています。
(a)AI半導体チップ (WSE-2:Wafer Scale Engine-2)
Cerebrasがウェハースケールエンジンと呼ぶWSE-2(Wafer Scale Engine-2)は、世界最大かつ最速のAIプロセッサです。この単一のウェハの上に850,000のコアと40GBのオンチップSRAMを搭載し、各々が20PB/秒のメモリバンド幅と220PB/秒のプロセッサ間インターコネクトバンド幅でつながっています。このWSE-2の特徴と、AIの開発者や利用者にとってのメリットは以下の通りです。
このWSE-2の特徴とAIの開発者や利用者のメリットを以下に紹介します。
WSE-2は、AIと機械学習ワークロードのために専用設計されている。
850,000を超えるコア、2.6兆のトランジスタを1つのチップ上に統合配置した世界最大のプロセッサ
40GB SRAMをオンチップで搭載
従来のCPUやGPUでは不可能な計算リソースを単一チップ上に集約し、極めて高い計算能力を発揮
コア間接続は220PB/秒。複数コア間のデータ通信の遅延を大幅に削減し、システムパフォーマンスを向上
幅広いメモリ帯域幅により、チップ内での大量データの高速転送が可能
高い計算密度とエネルギー効率を両立し、モデルの学習と推論に必要な電力消費を削減
WSE-2を複数接続し、更に巨大クラスタを形成することで必要に応じたスケーラビリティを実現

大きさのイメージ
(出典:Cerebras社)
これらの特徴から、深層学習のモデルの学習と推論では、従来の汎用GPUと比較して顕著な性能向上を実現し、モデルの学習時間を大幅に短縮することができます。さらに大規模なモデルや複雑なデータセットを扱うことが可能となっており、研究やAIアプリケーションの開発のペースを大幅に加速させることができるとしています。

(b)WSEに搭載されるAI専用コア
WSEには、プログラマブルなAIタスク専用のコアが大量に搭載されています。データフローアーキテクチャに基づく設計により、データが流れることで処理が行われ、密行列から疎行列への計算の移行を容易にしています。疎行列計算では、約50%以上のデータがゼロとなる場合がありますが、データフロースケジューリングを細かく行い、不要なデータ演算をスキップすることで計算資源の無駄を削減し、非常に高い演算効率を実現しています。加えて、オンチップに搭載された8TBのSRAMを活用することにより、データアクセス速度を飛躍的に高めて、高速な処理を可能にしています。なお、プログラマビリティに関しては、TensorFlowの標準フレームワークを利用する限り、何ら変更なくそのままで利用可能ですが、特定のフレームワークや独自の環境を利用する場合は、SDKを利用してロジックを変更できるようになっています。

(出典:Cerebras社)
(c)CS-2システム
CS-2システムは、WSE-2を搭載した15インチラックの3分の1のサイズに収まるコンピューティングノードです。WSE-2を搭載するサーバーは、電力供給と冷却に高度な技術を要しますが、CS-2では内蔵されるカスタム電力供給と冷却技術により、従来のプロセッサよりも大幅に下回る動作温度で安定してチップの性能を最大限に引き出すことが可能です。
CS-2は、100ギガビット・イーサネットを12レーン搭載し、40ギガバイトの高速オンチップメモリと組み合わせることで、単位時間当たりの計算量において、これまでのいかなるマシンよりも優れた性能を発揮します。設定も簡単で、100ギガビット・イーサネットリンクを接続するだけで、数分でモデル学習を始められるとのことです。
またAI処理能力をスケールアウトするためには、複数ノードのクラスタリングが一般的ですが、数百、数千ノードのGPUクラスタを構築するには、エンジニアリングリソースへの大規模な投資が必要となるのが一般的です。このようなプロジェクトには、ノード間通信と同期のオーバーヘッド、利用率向上のためのバッチ設計、ハイパーパラメータの広範囲な調整と最適化、プロジェクトの長期化など、様々なハードルが存在しています。
しかしながら、1台で数百枚のGPUに匹敵する性能を持つCS-2のクラスタリングは、クラスタリングに必要なマシンの数を減らすことができ、また設定も非常にシンプルで、通信と同期、電力消費のオーバーヘッドを抑えながら、より効率的にスケーリングすることができます。


(d)ソフトウェアプラットフォーム
「CSoft」は、ワークフローとシームレスに統合するソフトウェアで、Cerebras MLソフトウェアとソフトウェア開発キット(SDK)の2つで構成されています。Cerebras MLソフトウェアは、機械学習のフレームワークであるTensorFlowやPyTorchと統合されており、モデルをCS-2システムに容易に取り込むことができます。また、ソフトウェア開発キットには、深層学習に関連する広範なライブラリとデバッグやプロファイリングツールが含まれており、C言語ライクなCerebrasソフトウェア言語(CSL)を使用して、カスタムカーネルなどを開発し、プラットフォームを独自に拡張することが可能です。
(e)ウェハースケールクラスタ(CG-1)
Cerebrasは、「ウェハースケールクラスタ」と称する、複数のCS-2システムで構成されたAIスーパーコンピュータの一台としてCG-1を提供しています。このCG-1は、192台のCS-2ノードをクラスタリングしたシステムで、最大6,000億のパラメータをサポートし、4エクサFLOPSのFP16演算を実現しています。これにより、従来のGPUクラスタでは困難であった大規模言語モデルの学習をほぼ完璧にリニアスケーリングさせることが可能になります。現在、CG-1は米国内で稼働しており、同社のクラウドサービスを通じて利用することができます。
[主なシステムスペック]
FP16で4エクサFLOPS以上のAI演算処理
AIに最適化された5,400万個のコアを搭載
64ノードのCerebras CS-2システムをクラスタリング
82テラバイトのメモリを搭載
6,000億のパラメータ・モデルをサポート(100兆まで拡張可能)
388テラビット/秒のノード間ファブリック帯域幅
AMD Epyc Gen 3コアを72,704基搭載

(出典:Cerebras社)
(f)クラウドソリューション
大規模言語モデルのトレーニングやファインチューニングに最適化された、数百万コアを擁する専用クラスタで構成されたクラウドプラットフォームは、Cirrascale Cloud Services社によってサービス提供されています。このクラウドサービスでは、定額料金によるモデルトレーニングやトークンごとに計算される従量課金制のサービスが提供されています。
「Cerebras AI Model Studio」というソフトウェアを用いることで、数百万コアの専用クラスタを活用し、大規模な言語モデルの学習とファインチューニングを、高速かつ容易に行うことができます。
(3)ユースケースと既存顧客
Cerebrasのプロダクトが利用されるのは、特に計算要求の高いAIアプリケーションです。
(a)大規模な言語モデルの学習と推論
大規模言語モデルの学習や推論をより高速かつより効率的に実行
- 多言語チャットボット
- 高度テキスト分析ツール等
(b)コンピュータビジョン
画像認識やオブジェクト検出などのコンピュータビジョン処理
- 自動運転車
- 監視システム
- 医療画像分析など
(c)HPC(高性能計算:High Performance Computing)
膨大なデータセットの処理や複雑な数値シミュレーションのために高度計算の必要な分野
- 科学研究
- 気象予測
- 量子物理学のシミュレーションなど
(d)ヘルスケア
精密かつ高速な計算の必要なヘルスケア分野
- 医療データ分析
- 創薬
- 遺伝子配列解析
- 高度診断支援など
尚、Cerebras社の既存顧客として企業名を確認できた企業や研究所、団体を以下に紹介します。
[グラクソ・スミスクライン]
医薬品開発とバイオテクノロジーでの利用
[アストラゼネカ]
創薬
[エジンバラ大学パラレルコンピューティングセンター]
大規模言語モデル開発、COVID-19治療研究、ゲノミクスと公衆衛生研究
[アルゴンヌ国立研究所]
癌治療法開発のためのシミュレーション
[ピッツバーグ・スーパーコンピューティング・センター]
医用画像処理、気象・気候データ、ゲノム解析、物理学
[ローレンス・リバモア国立研究所]
COVID-19および癌処方薬開発、認知シミュレーションシステム開発
[米国国防高等研究計画局(DARPA)]
デジタルRF戦闘機エミュレータ、リアルタイムRFシナリオエミュレーション
[米国国防総省]
リアルタイムシミュレーション
[国立エネルギー技術研究所(DOE)]
火力発電所の燃焼モデル解析
2. Groq

(1)企業概要
Groqは、2016年に米国カリフォルニア州マウンテンビューで創立された、AIと機械学習の分野に特化した技術企業です。この企業は、GoogleのTPU(Tensor Processing Unit)の開発に貢献した創業者(現CEO)によって立ち上げられ、独自のハードウェアとソフトウェアソリューションを開発し提供しています。
同社のプロダクトラインナップには、GroqChipプロセッサ、GroqCardアクセラレーター、GroqNodeサーバ、GroqRackコンピュートクラスタ、GroqWareスイートなどがあり、AIタスクを高速かつ効率的に処理し、高い推論スピード、高いエネルギー効率を実現しています。特に、同社が開発したGroqChipは、シンプルなハードウェアアーキテクチャを持ち、エネルギー効率が高く、特に大規模言語モデルを対象とする自然言語アプリケーションで、計算密度とメモリ帯域幅の優位性を生かして、従来のGPUの処理速度を大幅に上回る性能を実現しています。
(2)プロダクト
① Groq LPU推論エンジン
Groqは、AIに最適化されたソフトウェアとハードウェアのエコシステムを提供しており、その中核をなすのがGroq LPU推論エンジンです。Groq LPU推論エンジンは、大規模言語モデル向けに設計された言語処理ユニット(Language Processing Unit)の推論エンジンで、シンプルな構造を活かして計算とメモリ帯域幅のボトルネックを解消し、従来のGPUよりも遥かに高速なテキストシーケンスの生成を可能にしています。
このエンジンは、シングルコアアーキテクチャを採用しており、500億以上のパラメータを持つ大規模言語モデルを自動でコンパイルする能力に加え、リアルタイムメモリアクセスと同期ネットワークを通じて、低コストかつ低消費電力で、従来の10倍以上のパフォーマンスを実現しています。例えば、Llama-2 70Bを使用した場合でも、1ユーザーあたり毎秒300トークン以上を処理することが可能で、業界最速の推論パフォーマンスを実現しています。さらに、Groq LPU推論エンジンは小型で消費電力も低く、エッジデバイスへの導入が容易であり、エッジデバイス上で、大規模言語モデルを用いたAIアプリケーションを数日で稼働させることができます。
② GroqChip
GroqChipは、高速なテンソル計算やその他の機械学習に適した演算を得意とするAIアクセラレーターチップで、LPU推論エンジンにおいてAIタスクを実行するためのコアテクノロジーです。AI、機械学習、HPCの分野での高速演算を実現するため、ゼロから設計されたこの革新的なプロセッサは、「決定論的な振る舞い」という考えに基づき設計されており、どのような状況でも同じ結果を出せる予測可能性が重視されて開発されました。
GroqChipは、80TB/秒のメモリ帯域幅を持ち、230MBのSRAMメモリをオンチップで備えているため、大量のデータへの高速アクセスが可能で、最大750TOPsのテラ演算能力と188TFLOPsの浮動小数点数演算能力を有しています。また、最大16個のGroqChipをRealScaleチップ間インターコネクトを通じて直接接続することで、遅延を最小限に抑えつつシステムのスケールアップすることができます。

③ GroqCard Accelerator
GroqCardアクセラレーターは、データセンターや計算集約的なタスクに最適な、高性能かつ効率的な計算リソースを提供するために開発されたデバイスです。このアクセラレーターは、標準的なPCIe Gen4 x16インターフェースを採用し、サーバーのスロットに容易に装着できます。GroqChipを1基搭載し、230MBの大容量SRAMおよび最大80TB/秒の帯域幅を誇るインチップメモリを用いることで、高速かつ低遅延な処理を実現します。また、消費電力は標準で240W、最大で375Wとなっており、高い計算性能を保ちながらも消費電力を抑えることが可能です。
GroqCardは、最大11個のRealScaleチップ間コネクタを備えており、外部スイッチなしで複数サーバーをつないでスケールアップができます。さらに、GC1-010B、GC1-0109、GC1-0100という異なるモデルが提供されており、RealScaleチップ間コネクタの数によって、それぞれのスケーラビリティを選択することができます。

④ GroqNode Server
GroqNodeサーバーは、データセンター用に開発されたサーバーシステムで、標準ラックに容易に組み込むことができる設計になっています。このサーバーは4Uサイズの筐体に2つの高性能CPUと1TBのDRAMメモリを搭載し、最大で8枚のGroqCardアクセラレーターを装着することが可能です。RealScaleテクノロジーを活用し、最大640TB/秒のメモリ帯域と最大1.76PBのオンチップメモリを用いて、高速な演算処理を実現します。

⑤ GroqRack Compute Cluster
GroqRackは、データセンター向けに特別に設計された、高度に拡張可能なコンピューターネットワークシステムです。このシステムは、8台のGroqNodeサーバーで構成されており、合計64個のGroqChipによって支えられています。さらに、704個のRealScaleチップ間コネクタを備えて、外部スイッチを使用せずに複数のサーバーをつないでのシステム設定が可能です。これらにより、GroqRackは、1ラックあたりわずか1.6マイクロ秒という非常に短いレイテンシでデータ処理を行うことができます。

⑥ GroqWareスイート
Groqware Suiteは、AI、機械学習、HPCに特化したソフトウェア群で構成され、効率的な演算処理を実現するための包括的なツールとライブラリを提供しています。このソフトウェア群は、「ソフトウェア定義ハードウェア」というGroqが提唱するコンセプトに基づき、ソフトウェアの柔軟性とハードウェアの高性能を組み合わせたアプローチで、様々な計算ニーズに対して最適化されたパフォーマンスを提供する環境を提供しています。
Groq Compilerは、PyTorch、TensorFlow、ONNXなどの機械学習フレームワークで開発されたAIモデルをGroqChip上で最適に動作させるためのコンパイラで、これにより、既存のAIモデルをGroqの環境に簡単に移行することができます。また、GroqFlowツールチェーンの自動処理機能により、PyTorchやTensorFlowで記述されたコードを、最小限の変更でGroqのハードウェア上で容易に実行できます。
Groq APIは、GroqChipを細かく制御するためのAPIであり、このAPIを利用してカスタム計算やカスタムタスクを定義し、GroqChipを制御することができます。
GroqViewプロファイラやVisualizerは、プログラムの性能やメモリ使用状況を可視化し、デバッグやパフォーマンスの最適化作業を支援するツールです。
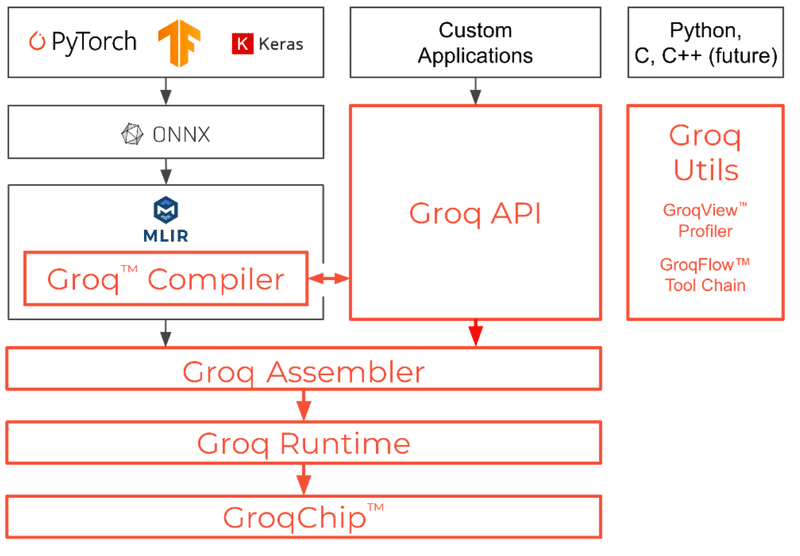
(出典:Groq社)
⑦ GroqCloud(https://console.groq.com/playground)
GroqCloudは、Groqが運営する大規模言語モデルをAPIを通じて、企業や開発者向けに提供するクラウドサービスです。イメージとしては、OpenAI社のPlaygroundに似たインターフェースとサービスを提供しています。
現在、Llama 2やGemma 7B、Mixtralのモデルがサービス対象になっており、「Groqのレスポンスがとにかく爆速」というソーシャルネットワーク上での高評価は、このGroqCloudの使用感に基づいたものです。

(3)テクノロジー
Groqのプロダクトを支えるテクノロジーの幾つかについて紹介します。LSTMなどの自然言語処理におけるデータストリーミング処理に際してのメモリマネジメントなど、以下に紹介する以外にもコアとなるテクノロジーを幾つも持っていると思われますが、Groqの強みを支えるテクノロジーの幾つかについて以下紹介したいと思います。
① Tensor Streaming Processor Architecture
GroqChipは、従来のCPU、GPU、FPGAとは異なるアプローチを採用しており、制御フローやハードウェア間の相互作用を管理するためのアービターやリプレイメカニズムなど、従来の演算回路でよくみられる反応的(リアクティブ)なコンポーネントを実装していません。尚、アービターは、複数のコンポーネントやプロセスが共有リソースへのアクセスを要求する際の衝突を防ぎ、効率的で公平な配分を保証するシステムで、リプレイメカニズムは、データの不整合やエラー発生時の処理を保証し、システムの正常な状態を回復させるために使用される機能です。GroqChipでは、これらアービターやリプレイメカニズムを持たない代わりに、「ソフトウェア定義されたハードウェア」というアプローチを取っています。この方式では、プログラムの処理制御をハードウェアの内部機構で行うのではなく、ソフトウェア(具体的には、コンパイラ)によって制御・管理する仕組みが採用されています。このコンパイラによって定義されたハードウェアでの処理では、データがメモリから読み出され、演算回路に送られるまでの時間を正確に把握することができるため、ハードウェアを効率的に動作させて、計算速度を向上させることが可能です。簡単に言えば、Groqは複雑なハードウェアの制御機構を排除し、ソフトウェア(コンパイラ)でハードウェアの全動作を定義・制御することにで、演算速度の向上とハードウェア設計の単純化を実現していると言えます。

概念を説明する図(出典:Groq社)
上図は、Groqがいかに効率的なハードウェアを実現しているかを示している図です。左側の図は、論理演算やレジスタなどの基本的な計算要素を含む、世間に一般的なチップの設計を示しています。中央の図は、Groqが排除したコンポーネントを赤い×印で示しており、これには、キャッシュメモリや制御ロジック、複雑な命令を実行するためのプランニングシステムなどが含まれます。これらは一般のチップで必須とされますが、Groqは物理部品を排除し、これらをすべてソフトウェアで処理しています。右の図は、不要な要素を取り除いた結果ですが、各演算ユニット(緑色の部分)がより大きく、リソースが効率よく利用されることを示しています。結果、同じチップ面積でより多くの演算能力を実現することができます。
このように、ハードウェアデザインを簡略化することで、チップが不要な計算や予測を行う必要がなくなり、予測できない遅延(テールレイテンシ)の発生を抑制できます。さらに、チップ上のすべての動作を厳格にスケジュールすることで、消費電力を正確に予測し、制御することが可能となり、エネルギー効率を大幅に向上させることができます。つまり、Groqは物理的なハードウェアの複雑さを減少させることによって、ソフトウェアによる処理制御と効率的な電力消費を実現し、結果として、システム全体の性能とコスト効率の向上を実現していると言えます。
② ソフトウェア定義されたハードウェアがもたらすメリット
ソフトウェア定義されたハードウェアがもたらす利点を簡潔に紹介します。
(a)予測可能性
ソフトウェアが全ての制御を行うため、どのようにプログラムが動作するかを事前に把握でき、その結果、プログラム処理にかかる時間を正確に知ることができます。
(b)QoS(サービス品質)
「決定論的」なGroqChipは、毎回同じ動作をします。これにより、プログラムの処理速度や結果を正確に予測することができ、複数のモデルや複雑なタスクにおいても、結果の一貫性を保つことができ、常に一定の品質を維持することができます。
(c)設計とデバッグの容易さ
GroqChipでは、プログラムが一度動作し始めると、毎回同じ方法で動作し、他のプログラムが同時に動作していても影響を受けず、チップ性能の詳細情報をあらかじめ把握できること、また、プログラムを一度確認して問題がなければ、再びチェックする必要がないため、デバッグをシンプルに行うことができます。
(d)TCO(総所有コスト)
「決定論的」であることから、予測されるチップのエネルギー消費を制御することで、エネルギー消費の最適化やプログラム実行速度の調整が可能で、TCOの改善に大きく寄与します。
③ RealScaleチップ間インターコネクト
RealScaleは、Groqのシステムをスケールアウトする際の核となる技術です。この技術により、GroqChipや各種コンポーネントが連携して、デバイス間で直接高速通信を行い、1つの大きなコンピュータシステムのように機能させることができます。また、デバイス間の通信はソフトウェアによって定義・管理されており、トラフィックの輻輳やデータ送信の遅延を抑制し、システム全体のパフォーマンスを向上させることができます。

(出典:Groq社)
上図は、従来のネットワーク(左図)とソフトウェア定義ネットワーク(右図)を比較しています。従来のネットワークでは、システムがデータのやり取りを予測できないため、ノードAからノードBへのデータ転送が多すぎることで、ノードBが処理しきれない状況が発生しています。この状況は、「バックプレッシャー」と呼ばれる問題を生み、ノードCやノードDの通信パフォーマンスに影響を及ぼし、データの再ルーティング(再送)が発生してネットワークの遅延を増加させて、システム全体のパフォーマンス劣化を引き起こします。
一方、ソフトウェア定義ネットワークでは、データの送信があらかじめソフトウェアによってスケジュールされているため、ノードが処理しきれないという状況が生まれにくく、安定したネットワーク通信を実現できます。
尚、RealScaleは、階層的にGroqChipのレイヤー、GroqNodeのレイヤー、そしてGroqRackのレイヤーで相互接続し、より大きな単位にスケールアップしても、効率的な通信と高い計算性能を維持できるとしています。
(4)事例やユースケース
Groq自身、大規模言語モデルを活用した自然言語処理系で強みを持つことから、原則、文書生成や翻訳などの直接的な自然言語処理系AIタスク、プログラムコーディング、会話・音声・画像・動画など、モーダル変換を伴う自然言語処理系AIタスクで、Groqのプロダクトやサービスが利用されていると考えられます。
以上
御礼
最後までお読み頂きまして誠に有難うございます。 今後ともどうぞよろしくお願いいたします。
だうじょん
関連記事
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。
この記事が気に入ったらサポートをしてみませんか?