
NVIDIAが切り開いたAI半導体市場: 裾野拡がる市場の細分化(4)ユニコーン編(その2)

今回は、Part1に続き、AIアクセラレーターを開発・販売するユニコーン企業として2社、米国カリフォルニア州シリコンバレーに拠点を置くSambaNova Systems社と英国のGraphcore社を紹介します。
これらの企業は、AIや機械学習のタスクを高速化するために設計された専用のAIハードウェアとコンピューティングプラットフォームの開発に、独自のアプローチで取り組んでいます。生成AIの社会実装が徐々に拡がる中、新たに顕在化する課題に対して、イノベーティブなテクノロジーを駆使して積極的に取り組んでいる企業です。

尚、今週は NVIDIAがGTCで、最新のGPUベースのアクセラレータシステム「Blackwell GB200」と同製品の出荷を2024年後半に開始する旨の発表を行いました。推論性能は最大30倍、エネルギー効率は最大25倍と、新たなハイエンドGPUとそのエコシステムで他社を引き離すには十分なスペックと価格のようにも思えたりもします。
前回や今回紹介するスタートアップ企業も、ユニコーン企業とはいえ、マーケットで存在感を増すには、まだまだ時間がかかりそうですが、スタートアップ企業には、別のイグジット(EXIT)の道もありますので、このテクノロジー領域の連ドラは、まだまだ長く続いていくように思います。
※ ユニコーン企業とは、設立から10年以内で未上場の企業であり、企業評価額が10億ドル以上のベンチャー企業を指します。
1. SambaNova Systems

(1)企業概要
SambaNova Systems社は、2017年に設立されたカリフォルニア州パロアルトに本社を置く企業であり、自社開発のAI半導体を含むハードウェアとソフトウェアによる統合AI支援プラットフォームを開発・提供しています。
このSambaNova Systems社の特徴は、データそのものがハードウェアロジックを構成するというコンセプトを持つ独自のデータフローアーキテクチャを採用した「DataScale」という統合システムにあり、この従来システムのパフォーマンスを大幅に上回るDataScaleを中核に周辺のハードウェアとソフトウェアによって構成される統合システムを提供しています。以下、同社のプロダクトとなるシステムの概要や特徴について紹介して行きます。
(2)プロダクト
SambaNova社のプロダクトの中核を担うのが「DataScale」で、このDataScaleを中心に同社のプロダクトラインナップが構成されています。
このハードウェアとソフトウェアが統合されたDataScaleは、生成AIモデルや基礎モデルを含むAIモデルの開発とモデルの実稼働環境を提供するプラットフォームであり、自社開発した高性能なAI半導体「Cardinal SN30 Reconfigurable Dataflowユニット」を搭載しています。
このDataScaleの上には、モデルの学習やファインチューニング、インストラクションチューニングや推論のプロセスを実行・運用するためのMLOpsツールが提供され、さらにその上位に自然言語処理を行うGPT、自動音声認識ASR(Automatic Speech Recognition)、BloomなどのAIモデルを活用するAIアプリケーション開発を支援するための「SambaNova Suite」という開発フレームワークが提供されます。
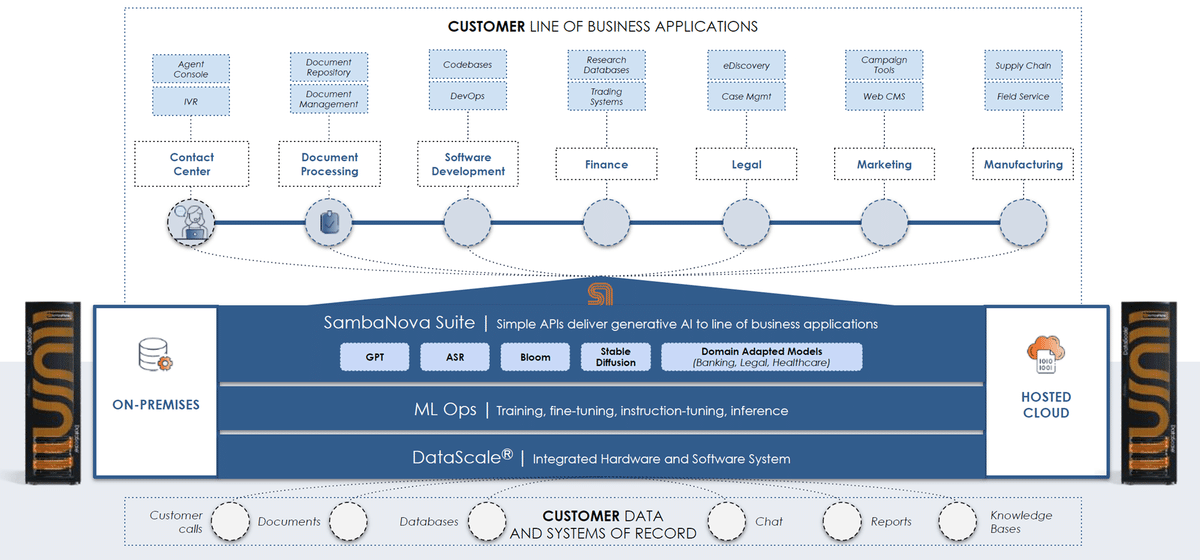
(出典:SambaNova社 クリックで拡大)
(a)DataScaleシステム
同社システムの中核をなすDataScaleは、AIモデルの学習や推論を高速に実現するハードウェアとソフトウェアの統合されたコンピューティングユニットです。このシステムの特長は、独自のデータフローアーキテクチャによって従来のGPUシステムを大幅に上回るパフォーマンスを実現し、単一ノードから数百ノードまでシームレスにスケールアップできる能力にあります。
DataScaleは、単一プラットフォーム上でモデルの学習と推論を実行することが可能で、エンドツーエンドの機械学習パイプラインを管理するためのフレームワークを提供しています。このDataScaleシステムをいくつかのモジュールに分解して紹介します。
① RDU 「SN40L」
Reconfigurable Dataflow Unit(RDU)は、データフロープロセッサとして設計・開発されたもので、データ処理をより効率的かつ柔軟に行うことができる革新的な技術を搭載しています。このハードウェアはリコンフィギュレーションが可能で、新しいニーズやアルゴリズムの変化に迅速に対応でき、同社の提供するSambaFlowソフトウェアスタックと組み合わせて使用することで、コンピューティング、メモリ、通信ネットワークを再構成して統合し、大規模なAIモデルのワークロードを高性能に処理することができます。
このRDUは、2020年に発表されたSN10を皮切りに、SN20(2021年)、SN30(2022年)、そして最新の2023年に発表されたSN40とSN40Lと各々に性能を向上させています。最新バージョンであるSN40Lは、特に生成AIモデルの学習と推論に特化して開発されており、1,040個のRDUと64GBのHBM3高帯域幅メモリを搭載しており、8つのSN40Lをクラスタ化することで、5兆のパラメータ(5テラ)を処理することができます。

② SambaFlow
SambaFlowは、PyTorchやTensorFlowなどの標準フレームワークと完全に統合されており、モデルの最適なデータフローグラフを自動的に抽出、最適化、実行することで、学習と推論のパフォーマンスを迅速に最適化するソフトウェアスタックです。このソフトウェアは、ローコード/ノーコードAPIを提供し、AIモデルの開発と展開を大幅に簡素化できるだけでなく、ハードウェア環境とも密接に連携し、任意の数のデバイスや構成間でのスケーリング管理を可能とし、大規模なモデルと膨大なデータの取り扱いを容易にします。また、SambaFlowは、AIモデルの最適なデータフローグラフを自動的に最適化するため、開発者は低レイヤーのチューニングに注意を払うことなく、高いパフォーマンスの実現が可能となります。

(出典:SambaNova社 クリックで拡大)
③ DataScaleハードウェア
これは、データセンターに対応するラックレベルの統合システムで、1台以上のDataScaleノードと統合されたネットワーク、および管理インフラで構成されています。いくつかのラインナップがあり、DataScale SN30システムは、42Uサイズのデータセンターラックに内蔵されて販売されています。

※イメージは、1世代前のSN30というモデル
(3)テクノロジー
SambaNova社のテクノロジーの中でも、同社を特徴付けるデータフローアーキテクチャの概要について、紹介します。
① データフローについて
従来のコアベースのコンピューティングアーキテクチャでは、演算処理と通信制御処理が分離されています。演算処理は必要に応じてプログラムされますが、データの移動を司る通信はハードウェアによって管理され、柔軟かつ緻密な制御が困難です。一方、SambaNovaの再設定可能なデータフローアーキテクチャは、演算処理の一連に対して、データがどのように通過すべきかを最適化し、通信処理のプログラミングを可能にします。
SambaNova社のテクノロジーコンセプトの根底にあるのは、データフローとニューラルネットワークの関係に基づくアプローチです。これは、データ自体を用いてロジックのプログラミングを行うもので、ソフトウェア2.0とも称される、プログラミングの新しいパラダイムによるソフトウェアとハードウェアの統合的なアプローチです。
従来のプログラミングモデルではアルゴリズムやロジックをコードに落とし込みますが、データフローではデータ自体がプログラムフローを定義します。機械学習モデルを大量のデータを用いて学習させるイメージにも似ています。ハードウェアとソフトウェアは、入力されるデータストリームからデータの畳み込みや重み付けなどの最適な計算パターンを自動で認識し、システムの処理ロジックを自ら構成します。この過程で、データストリーム自体が直接、演算処理を定義するため、そのロジック構成とプロセッサユニット間のデータ移動が最適化され、従来では困難だった高いレベルの並列処理と効率性を実現することができます。
そして、このデータフローを具現化しているのがRDUです。この特定タスクやアルゴリズムに応じてその構成を動的に変更できるRDUの中身には、640個のプログラマブルなPCU(パターンコンピュートユニット)と640個のPMU(パターンメモリーユニット)がハードウェアに実装されています。RDUは、これらのプログラマブルなハードウェアと大容量のオンチップメモリを大規模に実装によって、高い演算効率を実現し、従来のGPUでは難しかった大規模モデルや複雑なアルゴリズムの実行を可能にしています。
② データフローアーキテクチャについて
従来のコアベースのコンピューティングアーキテクチャでは、演算処理と通信制御の処理が分離されています。演算処理は必要に応じてプログラムされますが、データの移動を管理する通信はハードウェアによって制御され、その結果、柔軟で緻密な制御が困難とされています。
下図は、従来のコアベースアーキテクチャでの畳み込みグラフの実行シーケンスを示しています。この処理では、各カーネルがCPUやGPUにロードされた後、データと重みを読み出し、計算を実行し、そして結果をメモリに書き込むというステップが繰り返されています。つまり、データ移動量が増加し、大量のメモリ帯域幅を消費してしまうことになります。この場合、機械学習や高性能計算(HPC)では、データの移動を頻繁に引き起こし、結果としてプロセッサの利用率の低下や処理時間の増加につながってしまいます。

(出典:SambaNova社 クリックで拡大)
SambaNova社のデータフローにおけるRDUのプログラミングは、SambaFlowによって実現されます。RDU上での一連の演算処理やデータの取り込み方法について、RDUに配置された物理リソース(パターン演算ユニット(PCU)、パターンメモリユニット(PMU)、スイッチングファブリック)を活用し、SambaFlowが命令シーケンスを空間的にプログラムすることで、データフローグラフを最適化します。これにより、RDU全体でデータが効率的に並列処理され、高いハードウェアの利用率、高スループット、そして低遅延が実現されます。
このSambaFlowとRDUの最適化によって、機械学習や科学計算などのデータ集約型アプリケーションが最適に構成され、新たなニーズやアルゴリズムに迅速に適応し、再利用が可能になります。
RDUは、3次元に配置されたオンチップのスイッチングファブリックを介して、パターン演算ユニット(PCU)とパターンメモリユニット(PMU)がメッシュ接続されています。アプリケーションの起動時にSambaFlowがRDUを設定し、特定のアプリケーションに最適化されたデータフローグラフを実行できる環境を整えます。また、RDUはASICとは異なり、後からロジックを変更できる点や、複雑なプログラミングと長いコンパイル時間が必要なFPGAとは異なり、マイクロ秒単位で迅速に再構成が可能です。

(出典:SambaNova社 クリックで拡大)
以下にRDU上に実装されているコンポーネントとその概要を紹介します。
[パターン演算ユニット(PCU)]
並列演算を実行するために設計され、再構成可能な多段のSIMDパイプラインにより、高い演算密度とレーン間、ステージ間の並列性を実現
[パターンメモリユニット(PMU)]
オンチップメモリであり、データ移動の最小化、レイテンシの低減、帯域幅の増加をもたらす
[スイッチングファブリック]
PCUとPMUを結ぶ高速スイッチで、スカラー、ベクトル、制御の3種のネットワークからなる3次元ネットワークを形成している
[合体ユニット(CU)とアドレス生成ユニット(AGU)]
AGUとCUは、RDUとオフチップDRAM、もしくは、他のRDUやホストプロセッサなどとの相互接続性を提供。また、RDU Connectは、複数のRDUによるクラスタを構成する際のRDU間の高速パスを提供
③ データフローアプローチの利点
以下は、データフローによる利点となります。
データとコードの移動が少ないため、必要なメモリ帯域幅が削減される
テラバイト級の大容量のオンチップメモリで大規模モデルをサポートすることが可能
パイプライン方式でグラフ全体を並列処理することで、幅広いバッチサイズに対して高い利用率を実現
高いオンチップメモリ容量、ローカライズ、および内部ファブリックの高帯域幅による高いパフォーマンスの実現
RDU上のパイプライン処理により、予測可能で低レイテンシのパフォーマンスを実現
階層アーキテクチャによって、コンパイラのマッピングが簡素化され、実行効率が大幅に向上
(4)ユースケースと既存顧客
以下に、Sambanova Suiteの具体的なユースケースをいくつかご紹介しますが、主に、計算要求の高いAIアプリケーションに向いています。
(a)データ分析と機械学習
大量のデータを効率的に処理し、機械学習モデルの学習や推論に利用
(ビジネスインサイトの抽出や意思決定プロセスの支援など)
(b)自然言語処理
チャットボット、翻訳システム、文書要約、感情分析などで利用
(顧客サービスの自動化やコンテンツの自動生成など)
(c)コンピュータビジョン
画像認識、ビデオ分析、顔認証システムなど、視覚データの解析に利用
(セキュリティ、監視、医療診断などでの応用)
(d)レコメンデーションシステム
ユーザー嗜好や行動を分析した商品やサービスのレコメンデーション
(オンラインショップやコンテンツ配信サービスでのUX向上)
(e)医療・ヘルスケア
医療分野でのデータドリブン型アプローチに利用
(医療画像の解析、遺伝子データの処理、疾病の早期発見等)
(f)金融分析
金融業界でのデータ分析と意思決定支援に利用
(市場トレンドの予測、リスク管理、不正検出など)
以下は、SambaNova社の既存顧客として企業名を確認できた企業や研究所、団体です。
アクセンチュア
OTP銀行(ハンガリー)
理化学研究所 計算科学研究センター
米ローレンス・リバモア国立研究所
米アルゴンヌ国立研究所
2. Graphcore

(1)企業概要
Graphcore社は、2016年に英国ブリストルで設立された企業で、AIおよび機械学習向けに特化した高性能半導体プロセッサ「Bow IPUプロセッサ」をはじめ、関連するハードウェアとソフトウェアを組み合わせた、AIモデルに最適化されたプロダクトエコシステムを提供しています。このIPUプロセッサは、AI専用に設計されており、深層学習を含む複雑なモデルの学習と推論において、従来のCPUやGPUと比較して著しく高い演算速度と効率を実現します。以下、Graphcore社のプロダクトエコシステムの概要とその特徴を紹介していきます。
(2)プロダクト
① Bow IPUプロセッサ
Bow IPUプロセッサは、WoW(Wafer-on-Wafer)3D積層技術を採用した世界で初めてのプロセッサで、より高い周波数で動作が可能であり、最大350テラFLOPSのAI処理能力を実現し、電力効率にも優れています。
このプロセッサは、TSMCの7nm製造プロセスを採用しており、1472のIPUコアが配置され、8832個の独立したプログラムスレッドが並行して実行される設計になっています。各IPUコアは、900MBのプロセッサ内メモリを搭載し、64.5TB/秒のメモリバンド幅で稼働します。
全てのIPUコアは、11TB/秒のさまざまなコミュニケーションパターンをサポートするノンブロッキングスイッチで相互に接続されています。また、320GB/秒の通信帯域を持つIPU-LINKを使用し、複数のBow IPUプロセッサを最大で10個までクラスタリングすることが可能です。

このようにBow IPUプロセッサは、コンピュート・イン・メモリ(CIM)技術を採用し、各IPUコアにメモリを隣接配置し、これを密に統合することで、データ転送のオーバーヘッドを削減し、高速かつエネルギー効率の高い演算環境を実現しています。また、IPU上のメモリには、従来のDRAMに比べて約300倍、HBMに比べて約30倍の性能を持つeSRAMを使用しており、この高速なメモリアクセスによって、AIアプリケーションの処理性能を大幅に向上させています。
② Bow-2000
1Uサイズのラックユニットに4つのBow IPUプロセッサを搭載したBow-2000は、3.6GBのインプロセッサーメモリを備え、ストリーミングメモリを最大256GBまで拡張可能です。1.4ペタFLOPSのAI処理能力を有するこの製品は、複数のBow-2000を接続して構成されるBow Podシステムの中核をなすユニットです。

尚、複数のBow-2000を積み重ねることで、中規模から大規模のシステムを構成するBOW-PODは、理論上最大64,000のIPUを接続可能なシステムとなっています。BOW-POD 16は、16基のBow IPUプロセッサを搭載し、さらに大きなシステムとして、1024基のBow IPUプロセッサを搭載するBOW-POD 1024までのシステム構成が用意されています。

(出典:Graphcore社)

(出典:Graphcore社)
また、巨大な基礎モデルや大規模言語モデルをBow-Podで扱う際には、モデルのレプリカを複数のIPUに分散して配置し、並列処理を可能にするためのパイプラインモデルパラレリズム(縦の軸)、テンソルモデルパラレリズム(横の軸)、およびデータパラレリズム(奥行きの軸)を通じてスケールアウトできるよう設計されています(下図)。このアプローチにより、メモリアクセスの最適化や複数IPU間の効率的なデータ交換を通じて、スケーラビリティとパフォーマンスの向上を図り、非常に大きなサイズのモデルも効率的に処理することが可能となっているとしています。

③ Poplar グラフ フレームワーク ソフトウェア
Graphcore社は、AIと機械学習の開発を加速するための幅広いソフトウェア製品を提供しています。
(a) Poplar SDK
Poplar SDKは、Graphcore社の核心となるソフトウェアスタックであり、IPUハードウェアとソフトウェアを直接連携させるための開発キットです。この開発キットは、OpenCL、TensorFlow、PyTorchなどの標準的な機械学習フレームワークと統合され、グラフベースのツールチェーンを通じたソフトウェア開発環境を提供します。
既存のAIモデルをGraphcore社のプラットフォームに移植する場合、IPU専用のモデルクラスを使用してインスタンスを生成し、特定のコードを追加することで稼働させることが可能です。また、PythonやC++を用いたIPUプログラミングを直接行うこともできます。

(b)PopArt & PopLibs
PopArtとPopLibsは、カスタムモデルの開発を支援する独自のソフトウェアフレームワークです。PopArtは、C++やPythonを用いたカスタムモデルの開発をサポートしており、一方のPopLibsは、IPUに最適化された行列演算やニューラルネットワークの操作を実現するライブラリです。
(c)PopVision
PopVisionは、AIと機械学習の開発者が自ら記述したプログラムコードを詳細に分析し、パフォーマンスチューニングを行うためのソフトウェアツールです。このツールは、IPUのパフォーマンスを最大限に引き出し、開発プロセスを効率化することを目的としています。
具体的には、IPUのメモリ使用状況や処理プロセスがどのように実行されているかを詳しく確認でき、パフォーマンスのボトルネックを特定し、プログラムを最適化するのに役立ちます。
④ Cloud IPUs
Graphcore社のIPUを高性能な計算リソースとして利用することができるクラウドサービスは、オンプレミス環境を構築することなく、AI開発や研究を迅速に開始することを可能にします。このサービスでは、数分でIPUインスタンスを起動し、直ちにモデルの開発やAIアプリケーションの構築を始めることができます。また、必要に応じてIPUインスタンスの数を柔軟に増減できるスケーラブルなサービスを提供しており、使用した分だけの従量課金制を採用しています。

(3)テクノロジー
① 超並列MIMD(Multiple Instruction, Multiple Data)
Graphcore社のIPUは、高性能な計算リソースを提供するクラウドサービスを通じて利用できます。オンプレミス環境の構築なしに、AIの開発や研究を迅速に開始することが可能です。数分でIPUインスタンスを起動し、直ちにモデルの開発やAIアプリケーションの構築に取り掛かれます。このサービスはスケーラブルで、必要に応じてIPUインスタンスの数を増減することができます。また、従量課金制で、使用した分だけ支払うことになっています。(下図)

(出典:Graphcore社の資料を二次加工。クリックして拡大)
Graphcore社のMIMDアーキテクチャは、SIMDアーキテクチャを採用しているGPUの処理能力の限界やデータ移動による処理遅延及び電力消費に関する課題に対する解決策として提案されており、このMIMDアーキテクチャによって、AIや機械学習のワークロードにおけるパフォーマンスの最適化とシステム全体の省電力性能を大幅に向上するとしています。このMIMDアーキテクチャの実現に貢献している技術には以下があります。
[超並列処理エレメント]
IPUには数千の演算処理エレメントが搭載され、膨大な数の異なる演算を並列処理することが可能
[インプロセッサ メモリシステム]
IPUには、データ処理を行うコアのすぐ隣にインプロセッサメモリシステムが配置されており、データの移動が最小限に抑えられ、処理遅延と電力消費を大幅に抑えることが可能
[強力なソフトウェアスタック]
並列処理タスクを効率的にプログラム可能なソフトウェアスタックを開発。標準的な機械学習フレームワークもサポートし、従来のAIモデルの移植も容易に可能
[スケーラブルなアーキテクチャ]
複数のIPUを接続し、より大規模なシステムを構築可能なスケーラブル設計となっており、膨大な演算処理を必要とするAIワークロードにも対応が可能
② アルゴリズム効率の向上
従来の技術では、アルゴリズムの改善に限界がある場面もありましたが、Graphcore社のアルゴリズム技術では、より少ない計算リソースを用いてもAIモデルの精度を向上させることが可能です。さらに、動的スパーシティを活用することで、学習中にモデルの接続性が進化し、計算コストを低く抑えつつ、モデルのパラメータ空間を効率良く探索することができます。この技術は、スパースニューラルネットワークの学習を加速する最適化技術により、アルゴリズムの効率をさらに向上させています。
通常、AIをより賢くするためには多くのデータや複雑な計算が必要とされますが、Graphcore社の技術を使用することで、これらの要素をより少なくしても、同じかそれ以上の成果を達成することが可能になります。この成果の背後には「動的スパーシティ」という技術があり、AIが学習する過程でどのデータのつながり(接続性)を重要視するかを自動で調整することによって、無駄な計算を減らしつつ、必要な情報だけを集中的に学習することが可能になります。
さらに、Graphcore社はスパースニューラルネットワークの学習、すなわちデータ間のつながりを少なくしてAIをより効率的に学習させる技術を改善しました。この進歩により、AIの学習速度を高め、計算コストの削減を実現しています。
③ 計算効率とエネルギー効率の劇的な向上
Graphcore社が採用している計算効率とエネルギー効率を向上させる手法には、いくつかの鍵となる技術があります。まず、Graphcore社の専用ハードウェアであるIPUは、スパース計算に特化して設計されています。この設計により、AIモデルの演算で不要なパラメータを削除し、計算量を大幅に減らすことが可能です。この結果、従来のCPUやGPUに比べて、より高速かつ効率的な処理が実現されます。加えて、Poplarソフトウェアスタックと動的スパーシティ技術の最適化により、スパースニューラルネットワークの性能を最大限に引き出し、AIモデルの演算に必要なエネルギーを削減します。
さらにIPUは、コンピュート・イン・メモリ技術により、演算、メモリアクセス、データ操作を同一シリコンチップ上で行うことができ、データ転送時のエネルギー消費を大幅に削減することが可能になります。
下図は、GPUとIPUのメモリマネジメントの違いを示しています。左側にGPU、右側にIPUが配置され、それぞれのコア利用率と電力消費の割合が図解されています。GPUの場合、コアの10%がRAMとして使用され、55%が利用されていないか他の用途に使用される「dark silicon」となっており、機械学習の演算に利用されるのは僅か35%となっています。これに対しIPUでは、コアの75%がRAMとして活用され、この領域を利用して高速なデータアクセスが可能となり、機械学習の演算には残りの25%が使用されることを示しています。
この図から読み取れるのは、汎用的に設計されたGPUでは、「dark silicon」の部分がグラフィックス処理やHPC(高性能計算)などの際には利用されるが、AIモデルの演算時には利用されず、またAIモデルの演算のための35%のシリコンを稼動させるのに大量の電力が必要になることです。一方、AIモデルに特化して設計されたIPUプロセッサは、コアの近くに高速なメモリを配置し、省電力で効率的なAIアプリケーションの処理を実現できることを示しています。

(出典:Graphcore Japan社)
④ モデルのスケーラビリティと柔軟性の向上
Poplarソフトウェアスタックは、静的スパーシティおよび動的スパーシティに対応し、さまざまなワークロードに最適化された実行を可能にします。開発者は、従来の密なモデルよりもはるかに複雑で精緻なモデルを、より少ないリソースで設計できるようになり、将来の更にサイズの大きい大規模言語モデルや複雑なAIタスクにも対応できるスケーラビリティを備えています。
このアプローチは、使用するデータの中から重要な部分だけを選択し、それを利用することで、複雑なAIモデルを少ない計算リソースで実現するというもので、の重要なデータの選び方を、あらかじめ決める静的スパーシティと、モデルが学習する過程で決める動的スパーシティの両方に対応しています。これにより、開発者はより少ない計算リソースを用いて、より複雑かつ詳細なAIモデルを構築することが可能になります。
(4)ユースケース
独特な設計思想に基づき、高速でエネルギー効率の高いGraphcore社のプロダクトエコシステムは、多様な産業での応用が期待されています。コンピュータビジョンや自然言語処理など、広く知られているAIタスク以外にもGNN(グラフニューラルネットワーク)の様々なユースケースについても提案しています。

(出典:Graphcore社の資料を二次加工。クリックして拡大)
以上
御礼
最後までお読み頂きまして誠に有難うございます。 今後ともどうぞよろしくお願いいたします。
だうじょん
関連記事
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?