(医療)ビッグデータビジネスという幻想

はじめに
刺激的なタイトルで始まりましたが、とても重要なテーマです。
この仕事をしていて、本テーマの本質的な問題点を理解している人は極めて少ないのではないか?と思い
前回のヘルステックベンチャーの目利きnoteが、キャピタルメディカベンチャーズ代表の青木さんのお眼鏡にかなったようで(とても嬉しい)。
その青木さんの(暗黙の)ご提案を反映し、このトピックを選ばさせていただきました。このnoteで何回も登場しているスライドですが、位置付けを確認しましょう。今回のテーマは、これらの項目のうち、強調させていただいた、②を重点的に記述していきます。
(① については、以前に投稿したこちらをご参照ください)

「あれ、赤信号になっているけど。。。日本には個人情報保護法や医療基盤法があるじゃないか?何故に??」
と思われた方もいらっしゃると思います。一方で、このスライドの赤信号評価を見て、「そうだよね。。。」と納得されている方もいらっしゃるはず(後者の方は、よく理解されていると思います)。
大企業、コンサル、そしてVCという様々な立場からこのテーマを眺めてきたこともあり、その詳細について記載していきたいと思います。それでは、
はじまり、はじまり。
大事なのは量ではなく、質(クオリティーデータの壁)
まず、用語確認です。皆様、ビッグデータアプローチとクオリティーデータアプローチという用語をご存知でしょうか?
そうなんです。データビジネスを検討する際には、ざっくりとこの2つのアプローチ方法があるのです。経済産業省が公開している討議用資料をカスタマイズして説明しますと、例えば次のようになります。
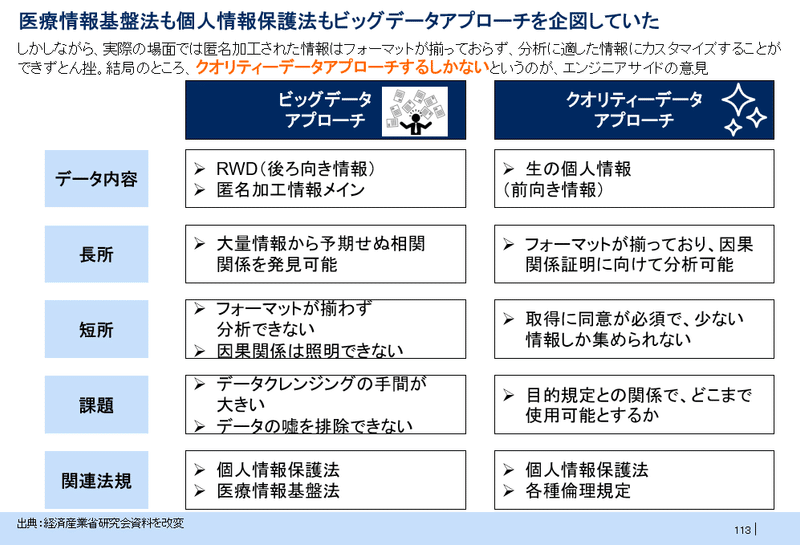
この2つのアプローチのうち、通常の場合、ビッグデータアプローチを企図されていると思いますが。。。
結論を書いてしまいますと、
「日本においてビッグデータアプローチの実現は、現状ほぼ不可能で、トライするならクオリティーデータアプローチするしか手段がないですよー」
これが結論です。多くの組織体は、この事実に気付かず(もしくは気付いても気付かぬフリをしつつ)、ビッグデータアプローチをしてしまっておりますので。そりゃあ、うまくいかないよねということになります。
多くの方にとりまして、データ分析技術というと、
「エクセルやアクセスに代表されるような大量のデータ(本当は、エクセルなんかでは扱えないくらいの大量のデータ)を、とにかくAIに分析させればいいんじゃないの?」
とイメージされていると思います。しかしながら、この読み込ませるデータには、極めて厳格な均一性と申しますか、標準化が求められるのです。それこそ、コンマの位置が1つズレるだけでもダメですし、全角と半角の違いも許されない。これくらいの粒度でのフォーマット統一性が求まられるとされます。
ですから、笑えない笑い話として、ある日系企業の方が、
「うちには、大量のビッグデータがあります。これを是非解析していただきたい!!」
として持ってきたのが、紙データだったとか。。。
(もちろん将来的には、紙データもすぐに分析可能な方式へ変換できるのかもですが。。。)
アメリカは、15年間&10兆円の年月と予算をかけてデータフォーマットを整備
皆様の中には、アメリカではデータビジネスが進んでいるイメージがある人もいらっしゃると思います。その認識は正しく、アメリカでは、電子カルテも含め、多くのデータクオリティーが高く、日本には存在しないようなデータ分析ビジネスを行う会社が出てきております(ex、薬剤フォーミュラリ―解析、在庫管理ビジネス)
しかしながら、このデータビジネスの素地は一朝一夕で実現できたわけではありません。その背景には、ブッシュ政権時代からトランプ政権に至るまで、約15年以上の年月、さらには、10兆円以上の予算をかけてひたすらにデータ標準化を実施したという、強いリーダーシップと実行力があります。
そのポイントは、次に示す、HITECH法とMACRA法です。簡単に説明しますれば、飴と鞭の法律をうまく駆使して、ひたすらに各種医療機関にフォーマットの揃ったデータ収集を義務付けました(例えば、このフォーマット導入したら、「●●●万円あげますよー」とした上で、その数年後に、「導入していないなら罰金●●●万円払わせますよー」とした)。

これが実現できた背景には、もちろんアメリカ自身が持つ政策推進力の強さもあると思いますが。医療保険制度の違い、すなわち、民間の保険会社が強い力を持っていたという背景もあります。
ここは中々日本にいてはイメージしにくいところだと思いますが、分かりやすく、強い営利目的を有する医療民間保険会社を想像してみてください。当該営利医療民間保険会社は、極力、(ケチって)保険費用を払いたくないと考えるはずです。それが故、「どの潜在患者が病気になりやすいか」「どの病気であればあまり保険費用支払いが少なくて済むか」を知りたくて知りたくて仕方がないはずです。
そこで、国民1人1人の健康状況を総合的かつ即時的に分析・把握できる医療ビッグデータ解析へのニーズが極めて強かった。民間保険会社による圧力の強さも、このフォーマットが揃った背景の1つにはあると考えて良いでしょう。これにより、電子カルテのみならず、薬局も含めたデータ連結が可能になっていると聞いております。
では、ここまで読んでいただいた読者の方に質問いたします。
「アメリカで、これだけの年月(15年)と予算(10兆円)がかかりました。国民皆保険制度の下、民間保険会社のプレッシャーが弱い環境下、わずか数年で日本で実現できると思いますか?」
日本の電子カルテのシェア状況なども踏まえ、お考えください。
データサイエンティストの嘆き
ここまできて、さらに疑問を持たれる方もいらっしゃるのではないでしょうか。
「いや、日本にはデータサイエンティストがたくさんいるはずで。その人たちが何とかしてくれるはずでは?」
この疑問に対する答えとしては、一応YESになるでしょう。ただし、それは彼ら彼女らが活躍できる土壌があればという仮定の話になります。
悲しいことに、彼ら彼女らの仕事の半分以上は、何と、データクレンジングです。
すなわち、フォーマットが揃っていないデータを、ひたすらに揃え続ける仕事。そういう単純業務に追われているというのが現実のようです。
(「こんなの、自分たちの仕事じゃねー!!」と苛立つ人多いとか何とか)
数年前、ヒアリングした時には、これが現実なのか、、、、という衝撃の感想でした。
ちなみにですが、日本でいうデジタル庁にあたるアメリカの組織では、このフォーマットを揃えるためのエンジニアが大量に雇われていて、ひたすらにデータフォーマットを揃え続けているとかいないとか。
なので、ビッグデータ分析は、一朝一夕ではいかない、すさまじい手間暇がかかるビジネスなのだということを理解する必要があります。
このあたり、慶應SFCの安宅さんの講義がとても参考になります。データビジネスに関する一般論も含め、大変勉強になります。少しでもこの領域に関わる方は必聴だと思いますところ、是非(視聴者は、学生よりも社会人の方が多いとか)。僕は、昨年、コロナ下の在宅ワークの隙間時間に受講し続けました。
以下に引用しているのは基礎編ですが、応用編の方も視聴の価値があると思います。クオリティーデータの重要性については、応用編の方で特に説かれておりましたので(どなたか、アーカイブURLをご存じの方はご共有の程をよろしくお願い申し上げます。)
個人情報保護法というもう1つの壁
さて、ここまできて、ビッグデータアプローチの難易度が極めて高いということで絶望的なのに関わらず。もう1つの大きな壁があります。それは、個人情報保護法です。
やや小難しい話になってしまいますので、スライドを示しつつ、簡単な解説をするのみに留めますが。この法律を遵守すると、使いにくいデータしか集まりにくく、さらに用途も当初から限定されてしまうという制約があります。
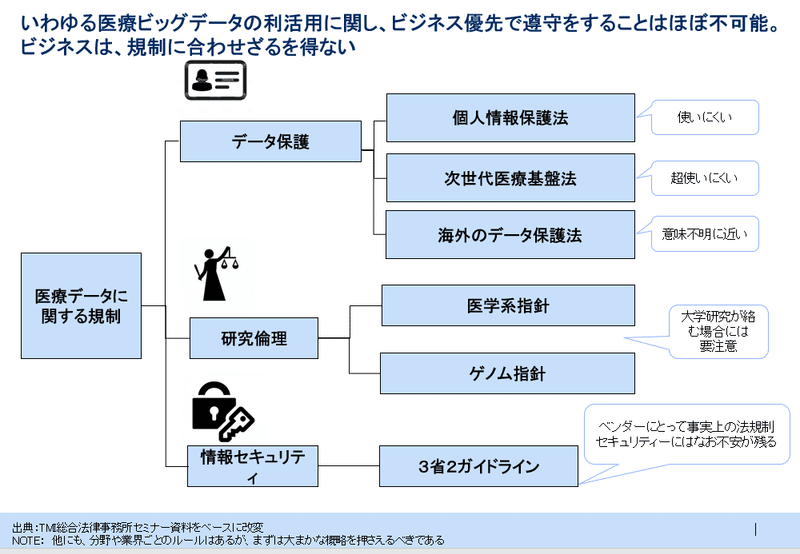
さらに、最先端の話をしてしまいますと。多くの人は、「同意さえすれば」「匿名加工情報化すれば」プライバシー上も実際上も何も問題ないと思われているでしょう。
ここでは、多くの弁護士や学者の方が議論している内容を紹介するに留めますが。実は、多くの問題がまだまだ残されているという雰囲気だけでも味わっていただけましたら。

このスライドは、匿名加工化しても結局は、あまり意味ないのでは?ということも示唆しているものです。実は、匿名加工しても、結局は情報の突合せで特定できてしまうということです(一方で、匿名化し過ぎた情報は使い勝手が悪い)。
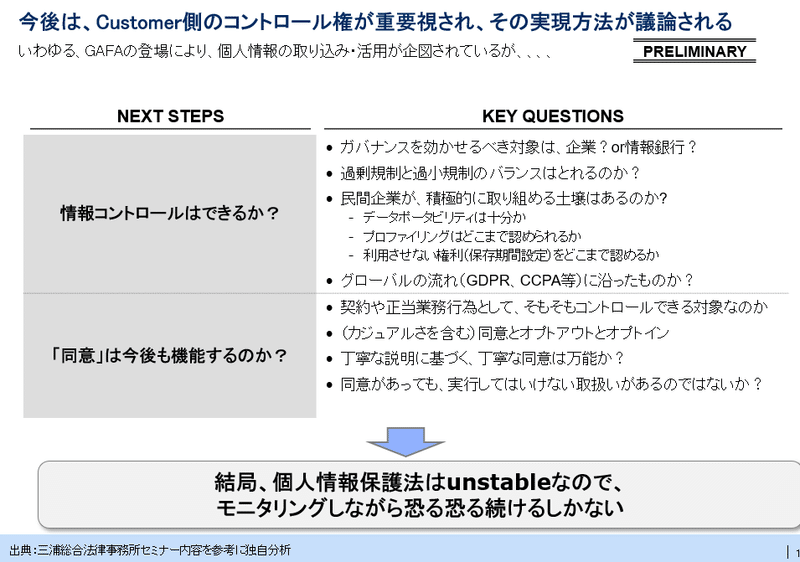
こちらは、もっと最先端の議論で。結局、同意したところで後で事情変更はいくらでも想定されるのだから。情報コントロールができるようにならないとプライバシーの保護なんてできないよねという話。ここには記載してませんが、「医療に代表される公共のためならば、同意なしで使えるルールがないともはや活用は不可能」なんていう議論もあります。
プライバシーの扱いについては、先進国であることの証左と宿命であるとは思いますが。それでイノベーションを止めて良いのかどうかは、検討の余地がありそうです。
わずかに見える勝ち筋
ここまで来て、多くの場合、(医療)ビッグデータビジネスはやめておいた方がいいという認識を持たれるのが通常だと思います。
ポンチ絵風にまとめると次のような2つの壁の認識を持たれると良いでしょう。
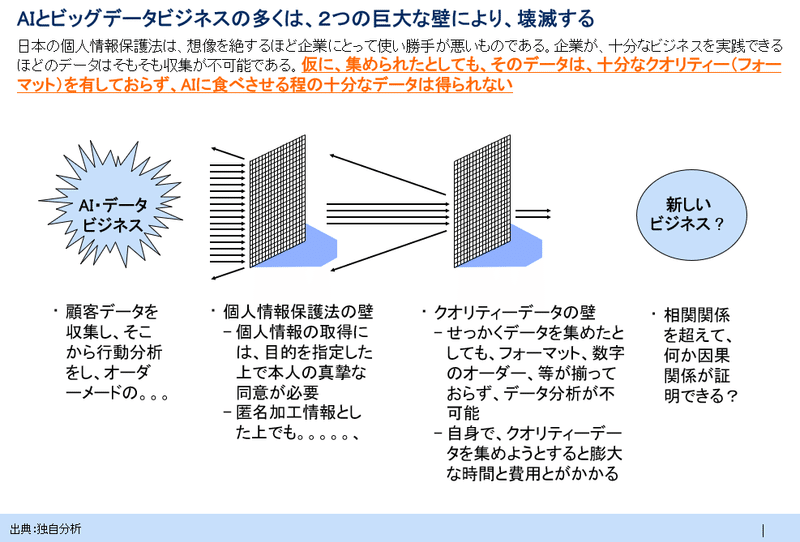
しかしながら、リスクを取るのが当然のキャピタリストは、それでもベンチャーとしての勝ち筋を探します。というか、
・少ないデータで確実に結果を出しに行く
・日なたビジネスではなく、日陰ビジネスで結果を出しに行く(つまり、本流ではうまくいかないとしても亜流でうまくいくところを探す)
などが挙げられますし、(理論上は)他にも複数考えられるところでしょう。実際、いくつかの勝ち筋はあります(それが、本質的な問題解決につながっているかどうかは置いておいて)
終わりに
先日もこの領域に詳しい弁護士の友人たちや、業界の人と話をしていたのですが。やるべきことが分かっているのに実行できないことは本当にもどかしく思っておりますし、問題の根深さは深刻です(しかも、有識者とされる人に限ってこの問題点を見て見ぬフリをしている印象があります)。
このあたりの問題点について、「深っちゃん、ビジネスと法律の領域展開うまそうだから書いてよ」と頼まれ、発刊予定の書籍にすでに原稿を提出済みですので(もう1年前に脱稿済)。もう少し詳細な問題点や解決策については、そちらで発表できましたら。薬剤師や薬学に関するリサーチペーパーも、近いうちに届けられるかもしれません。
やや暗い内容になっているかもしれませんが、冷静に思考・分析をした上で、粛々とやれることに情熱を注ぎこむのが性分ですので。この想いに共感してくださる方、是非、一緒に頑張りましょう!! 少なくとも僕は、いつでも領域展開する準備はしております。
この記事が気に入ったらサポートをしてみませんか?