
機械学習モデルの実装:変分オートエンコーダー(VAE)

1.概要
本記事では変分オートエンコーダー(Variable AutoEncoder):VAEをPytorchで実装します。ライブラリ紹介ではなく実装がメインのため学習シリーズに近い内容となります。
2.VAEの概念理解
VAEはAutoEncoderの拡張版みたいなもののため事前に理解が必要です。
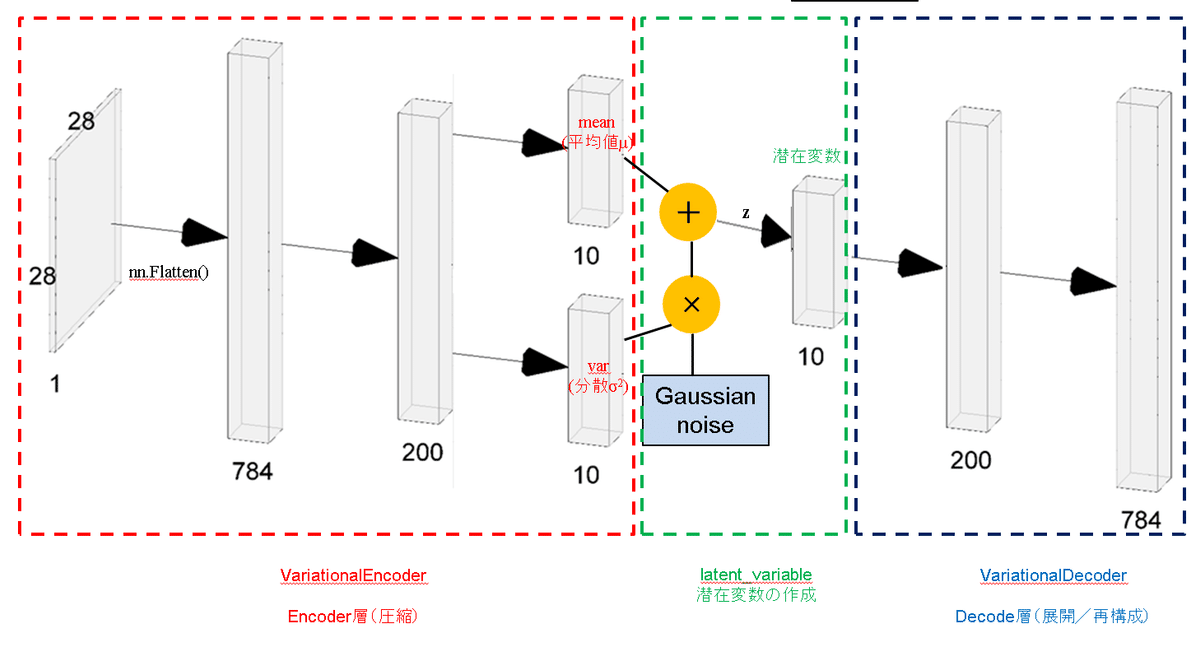
2-1.VAEのモデル概要
VAEの基礎構造は下図の通りです。特徴として下記があります。
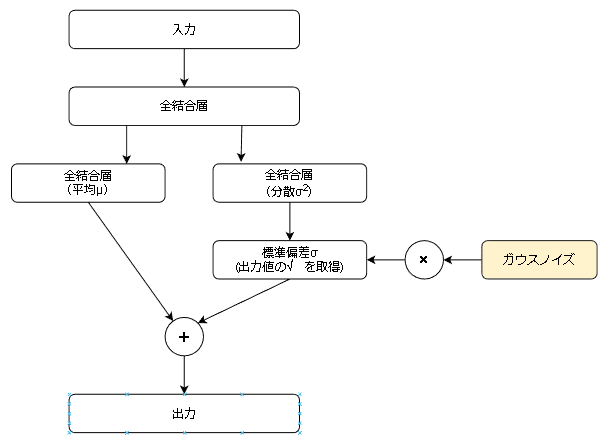

【VAEの特徴】
●Encoderの出力を標準正規分布に従って標準化することでDecoder単独で画像の生成が可能である。(AutoEncoderは入力データがないと無理)
●VAEでは学習時に2つの損失関数(BCE誤差と潜在ロス)が必要である。
ー>BCE誤差:入力画像と出力画像の誤差(AutoEncoderと同じ)であり再構築ロスとも呼ばれる
ー>潜在ロス:Encoderの出力とガウス分布が一致すると0になる損失関数
●ガウスノイズを加える部分を「Reparametrization trick」といい、この操作により誤差逆伝搬を可能にしている(出典)。
$$
BCE誤差:E(w) = -\sum_{i=1}^n[t_{i}\log f_{w}(x_{i}) + (1 - t_{i})\log (1 - f_{w}(x_{i}))]
$$
$$
潜在ロス: L = -\frac{1}{2}\sum_{j=1}^k(1+\log \sigma^2_{j}-\mu^2_{j}-\sigma^2_{j})
$$
なお上記の潜在ロスはエンコーダーが$${\sigma^2}$$(分散)を出力しておりますが、別パターンとして$${\gamma_{j}=log(\sigma^2)}$$を出力するように書き換えたものがあります。この方法の方が計算が安定して学習速度が向上するとされております。
$$
潜在ロス: L = -\frac{1}{2}\sum_{j=1}^k(1+\gamma_{j}-\exp(\gamma_{j})-\mu^2_{j})
$$
3.MNISTによる画像データの生成
MNISTを使用して下記を実行してみます。
入力画像から同じ画像を生成
標準正規分布(平均0, 分散1)から画像を生成(元データは不使用)
3-1.MNISTデータ取得および理解
MNIST(Mixed National Institute of Standards and Technology database)とは手書きの数値であり下記特徴があります。
学習用データ数:60,000枚、テスト用データ数:10,000枚
画像サイズは(1, 28, 28)の白黒データ
データサイズは8bitグレースケールであり0~255(int)である
MNISTデータは”torchvision.datasets”でラベルと合わせて取得可能です。
[IN]
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# トランスフォームオブジェクトを生成
transform = transforms.Compose(
[transforms.ToTensor(), # Tensorオブジェクトに変換
lambda x: x.view(-1)]) # データの形状を(28, 28)から784,)に変換:nn.Flatten()と同じ
# MNISTの訓練用データ
mnist_train = torchvision.datasets.MNIST(
root='MNIST', #MNISTフォルダがある場合はそこを参照
download=True, # ダウンロードを許可
train=True, # 訓練データを指定
transform=transform) # トランスフォームオブジェクト
# MNISTのテスト用データ
mnist_test = torchvision.datasets.MNIST(
root='MNIST', #MNISTフォルダがある場合はそこを参照
download=True, # ダウンロードを許可
train=False, # テストデータを指定
transform=transform) # トランスフォームオブジェクト
# データローダーを生成
train_dataloader = DataLoader(mnist_train, # 訓練データ
batch_size=64, # ミニバッチのサイズ
shuffle=True) # 抽出時にシャッフル
test_dataloader = DataLoader(mnist_test, # テストデータ
batch_size=64, # テストなので1
shuffle=False) # 抽出時にシャッフルしない
[OUT]
MNISTフォルダが作成され、その中にデータが格納される
(※データそのものはtorchvision.datasets.MNISTのインスタンス化時に自動で取得)なおサンプルを1つ取り出して中身を見ると、下記が確認できます。
”torchvision.datasets”で取得したデータは(data, label)のTuple型
データセット取得時に"transform"で前処理しているため、画像データは1次元配列であり正規化(min:0, max:1)されている。
[IN]
import matplotlib.pyplot as plt
_ = mnist_train[0]
print(f'type:{type(_)}, data:{_[0].shape}, label:{_[1]}')
print(f'最大値:{_[0].max()}, 最小値:{_[0].min()}')
plt.imshow(_[0].reshape(28, 28), cmap='gray')
[OUT]
type:<class 'tuple'>, data:torch.Size([1, 784]), label:5
最大値:1.0, 最小値:0.0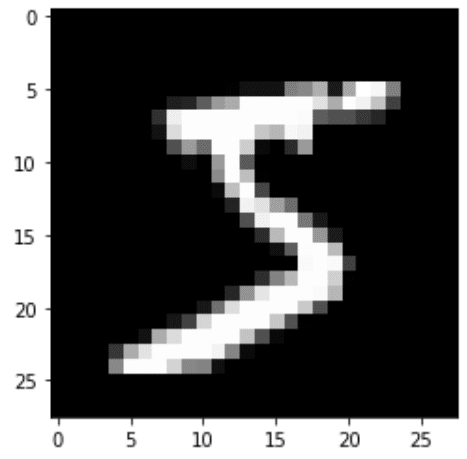
なお次節以降でデバイス割り当てができるように指定しておきます。
[IN]
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
[OUT]
cuda3-2.VAEモデル作成/パラメータ設定
VAEを作成します。構成は大きく分けて4つです。
1.Encoder:入力データの次元を圧縮する層である。VAEのEncoderは出力層が2つあり片方が平均μ、もう片方が分散varに相当する。
※初期出力時はただの2個の全結合層であるが特殊な損失関数を用いて学習すると結果的にμとvarのに代わる層になる
2.潜在空間(Reparameterization trick):Encoderからの出力値μと$${\sigma^2}$$を使用してReparameterization trickより$${z = \mu + \epsilon \cdot \sigma}$$を計算して潜在変数を作成する
3.Decoder:潜在変数から次元を拡大して入力値と同じ次元に戻す。
4.損失関数:2つの損失関数(BCE誤差と潜在ロス)が必要であり、これらの合計が最小になるように学習させる。
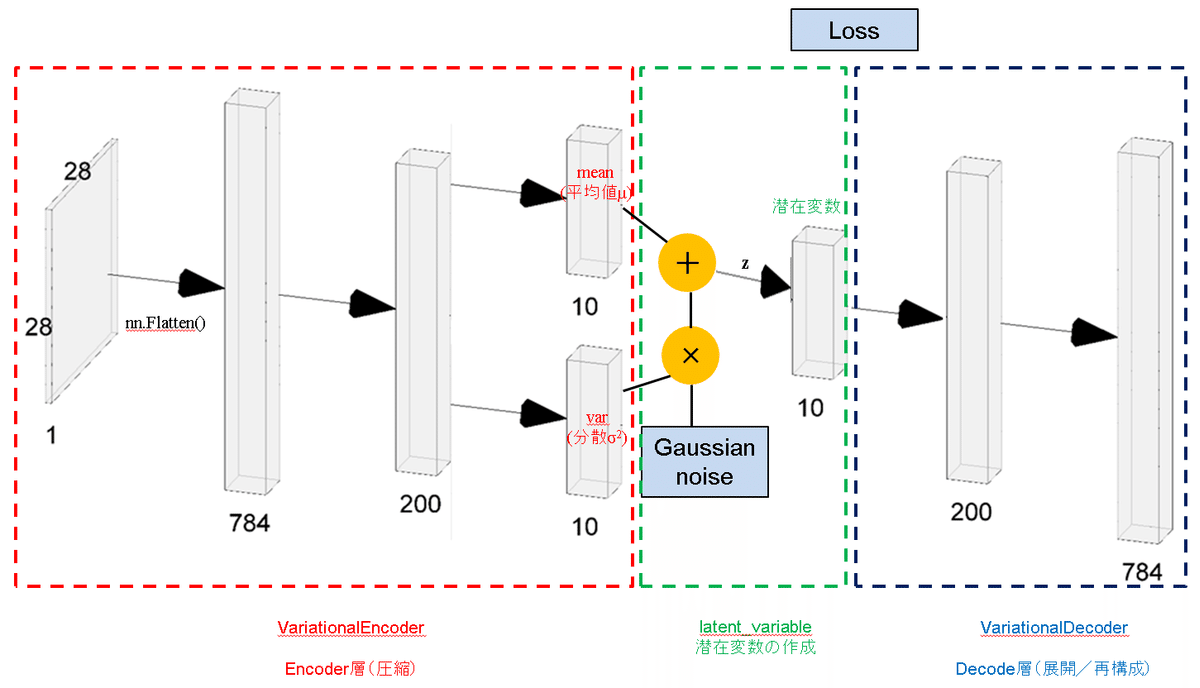
EncoderクラスとDecoderクラスをVAEクラスに組み込むため先にEncoderとDecoderクラスを作成します。その後VAEクラス内に潜在空間と損失関数を記載します。
3-2-1.Encoderクラス
Encoderクラスはただの全結合層であり、最終の出力レイヤが2層並列になっているだけです。その他の詳細は下記の通りです。
【Encoderクラスの詳細】
●入力画像(MNIST)より入力次元は784次元->200次元->10次元に圧縮
●活性化関数に関して、784->200次元ではReLUを使用。200->10次元において平均層(mean)では不使用、分散層(var)ではSoftplus関数を使用
[IN]
import torch.nn as nn
import torch.nn.functional as F
class VariationalEncoder(nn.Module):
'''エンコーダー
Attributes:
device: 使用するデバイス
l1: 全結合層
l_mean: 全結合層(平均値を出力する層)
l_var: 全結合層(分散を出力する層)
'''
def __init__(self, device='cpu'):
super().__init__()
self.device = device
self.l1 = nn.Linear(784, 200) # 全結合層: 入力784に対して200ユニットを配置
self.l_mean = nn.Linear(200, 10) # 全結合層: 入力200に対して10ユニットを配置
self.l_var = nn.Linear(200, 10) # 全結合層: 入力200に対して10ユニットを配置
def forward(self, x):
h = self.l1(x) # 784次元から200次元に減少させる
h = torch.relu(h) # l1の出力をReLU関数で活性化する
#平均(μ)出力
mean = self.l_mean(h) #200次元から10次元に減少させる
#分散(σ^2)出力
var = self.l_var(h) #200次元から10次元に減少させる
var = F.softplus(var) # l_varの出力をソフトプラス関数で活性化する
return mean, var # l_meanとl_vaeの出力を返す
[OUT]
-3-2-2.Decoderクラス
Decoderクラスもただの全結合層です。詳細は下記の通りです。
【Decoderクラスの詳細】
●活性化関数:中間層はReLUを使用するが最終層は「正規化されたデータに合わせる+BCEを使用(0~1の確率値)」のためsigmoid関数を使用
●入力値と同様に出力値の形状は"[batch, 1, 784]"となる。
●VAEクラスのインスタンス化の時にデバイス選択が簡単にできるようにクラス内にdevice設定をいれておく。
[IN]
class VariationalDecoder(nn.Module):
'''デコーダー
Attributes:
device: 使用するデバイス
l1: 全結合層(200ユニット)
l2: 全結合層(784ユニット)
'''
def __init__(self, device='cpu'):
super().__init__()
self.device = device # 全結合層1: 入力10に対して200ユニットを配置
self.l1 = nn.Linear(10, 200) # 全結合層1: 入力200に対して784ユニットを配置
self.l2 = nn.Linear(200, 784)
def forward(self, x):
h = self.l1(x) # l1に入力して10次元から200次元に拡大
h = torch.relu(h) # ReLU関数で活性化
h = self.l2(h) # l2に入力して200次元から784次元に拡大
y = torch.sigmoid(h) # シグモイド関数で活性化
return y
[OUT]
-3-2-3.潜在空間(Reparameterization trick)
まずEncoderクラスとDecoderクラスを包括したVAEクラスを作成します。
[IN]
class VAE(nn.Module):
'''変分オートエンコーダーのクラス
Attributes:
device: 使用するデバイス
encoder: エンコーダーのモデル
decoder: デコーダーのモデル
'''
def __init__(self, device='cpu'):
super().__init__()
self.device = device
self.encoder = VariationalEncoder(device=device)
self.decoder = VariationalDecoder(device=device)
def forward(self, x):
mean, var = self.encoder(x) # エンコーダーに入力し、l_meanとl_vaeの出力を得る
z = self.latent_variable(mean, var) # l_meanとl_vaeの出力から潜在変数を作成
y = self.decoder(z) # デコーダーに潜在変数を入力して画像を生成
return y, z
def latent_variable(self, mean, var):
'''潜在変数を作成する
'''
eps = torch.randn(mean.size()).to(self.device) # 平均0、分散1の標準正規分布からl_meanの出力値の数だけサンプリング
# (l_varの出力の平方根(標準偏差)×サンプリングした値)で求めたガウスノイズとl_meanの出力との和(線形和)を求める
z = mean + torch.sqrt(var)*eps
return z
def lower_bound(self, x):
'''損失関数
再構築ロスと潜在ロスの合計を求める
'''
mean, var = self.encoder(x) # l_meanの出力とl_varの出力を取得
z = self.latent_variable(mean, var) # 潜在変数を作成
y = self.decoder(z) # 潜在変数をデコーダーに入力して画像を生成する
# 再構築ロス(BCE誤差の平均値):E(w)=-1/NΣN(tlog(x)+(1-t)log(1-x))
reconst_loss = - torch.mean(torch.sum(x * torch.log(y) + (1 - x)*torch.log(1 - y),dim=1))
# 潜在ロス:L = -1/2Σ(1+log(σ^2)-μ^2-σ^2)
latent_loss = - 1/2 * torch.mean(torch.sum(1 + torch.log(var) - mean**2 - var, dim=1))
# 再構成ロス + 潜在ロス
loss = reconst_loss + latent_loss
return loss
[OUT]
-上記で”Reparameterization trick”に当たる部分が”latent_variable”です。この出力zが潜在変数(latent variable)であり、学習後には標準正規分布と潜在変数zとDecoderのみで画像を作成できます(入力データやEncoderは不要)。
[コード抽出]
def latent_variable(self, mean, var):
'''潜在変数を作成する
'''
eps = torch.randn(mean.size()).to(self.device) # 平均0、分散1の標準正規分布からl_meanの出力値の数だけサンプリング
# (l_varの出力の平方根(標準偏差)×サンプリングした値)で求めたガウスノイズとl_meanの出力との和(線形和)を求める
z = mean + torch.sqrt(var)*eps
return z”Reparameterization trick”は下記手順で計算しているだけですが、これをすることにより誤差逆伝搬が実行できるようになる(らしい)です。
1.Encoderから出力された2つの(1, 10)次元ベクトルμ, varを入力
2.Varは分散$${\sigma^2}$$と見立てているため$${\sqrt{var}}$$で換算
3.torch.randn()で標準正規分布(ガウス分布)を作成して$${\sqrt{var}}$$にかける(ガウスノイズ)
$$
潜在変数z \sim q_{\mu, \sigma}(z) = \mathcal{N}(\mu, \sigma^2)
$$
$$
ガウスノイズ\epsilon \sim \mathcal{N}(0,1)
$$
$$
潜在変数z = \mu + \epsilon \cdot \sigma
$$
https://www.baeldung.com/cs/vae-reparameterization
3-2-4.損失関数
損失関数は前項コード内の”lower_bound”にあたります。
[コード抽出]
def lower_bound(self, x):
'''損失関数
再構築ロスと潜在ロスの合計を求める
'''
mean, var = self.encoder(x) # l_meanの出力とl_varの出力を取得
z = self.latent_variable(mean, var) # 潜在変数を作成
y = self.decoder(z) # 潜在変数をデコーダーに入力して画像を生成する
# 再構築ロス(BCE誤差の平均値):E(w)=-1/NΣN(tlog(x)+(1-t)log(1-x))
reconst_loss = - torch.mean(torch.sum(x * torch.log(y) + (1 - x)*torch.log(1 - y),dim=1))
# 潜在ロス:L = -1/2Σ(1+log(σ^2)-μ^2-σ^2)
latent_loss = - 1/2 * torch.mean(torch.sum(1 + torch.log(var) - mean**2 - var, dim=1))
# 再構成ロス + 潜在ロス
loss = reconst_loss + latent_loss
return loss損失関数に関する特徴は下記の通りです。
【損失関数の特徴】
●VAEでは学習時に2つの損失関数(BCE誤差と潜在ロス)が必要である。
ー>BCE誤差:入力画像と出力画像の誤差(AutoEncoderと同じ)であり再構築ロスとも呼ばれる
ー>潜在ロス:Encoderの出力とガウス分布が一致すると0になる損失関数
$$
BCE誤差:E(w) = -\sum_{i=1}^n[t_{i}\log f_{w}(x_{i}) + (1 - t_{i})\log (1 - f_{w}(x_{i}))]
$$
$$
潜在ロス: L = -\frac{1}{2}\sum_{j=1}^k(1+\log \sigma^2_{j}-\mu^2_{j}-\sigma^2_{j})
$$
$$
潜在ロス(別ver.): L = -\frac{1}{2}\sum_{j=1}^k(1+\gamma_{j}-\exp(\gamma_{j})-\mu^2_{j})
$$
3-3.モデル作成・ハイパーパラメータ設定
前節で作成したVAEクラスをインスタンス化して評価関数(損失関数)および最適化関数を設定します。
[IN]
import torch.optim as optimizers
model = VAE(device=device).to(device) # 変分オートエンコーダーを生成
criterion = model.lower_bound # VAEの損失関数を設定
optimizer = optimizers.Adam(model.parameters()) # オプティマイザー(最適化関数)をAdamに設定
print(model)
[OUT]
VAE(
(encoder): VariationalEncoder(
(l1): Linear(in_features=784, out_features=200, bias=True)
(l_mean): Linear(in_features=200, out_features=10, bias=True)
(l_var): Linear(in_features=200, out_features=10, bias=True)
)
(decoder): VariationalDecoder(
(l1): Linear(in_features=10, out_features=200, bias=True)
(l2): Linear(in_features=200, out_features=784, bias=True)
)
)3-4.学習
通常の流れで学習させます(検証(val)用データは無し)。
モデルを使用して推論値を計算する
損失関数を使用して"正解値(入力値)"と"推論値"から誤差を求める※lower_bound()関数がクラスの中で推論と損失を同時に計算する
loss.backward()で各パラメータの勾配を求める
optimizer.step()によりパラメータを更新する
optimizer.zero_grad()によりパラメータの勾配を初期化する
1~5をループ計算する
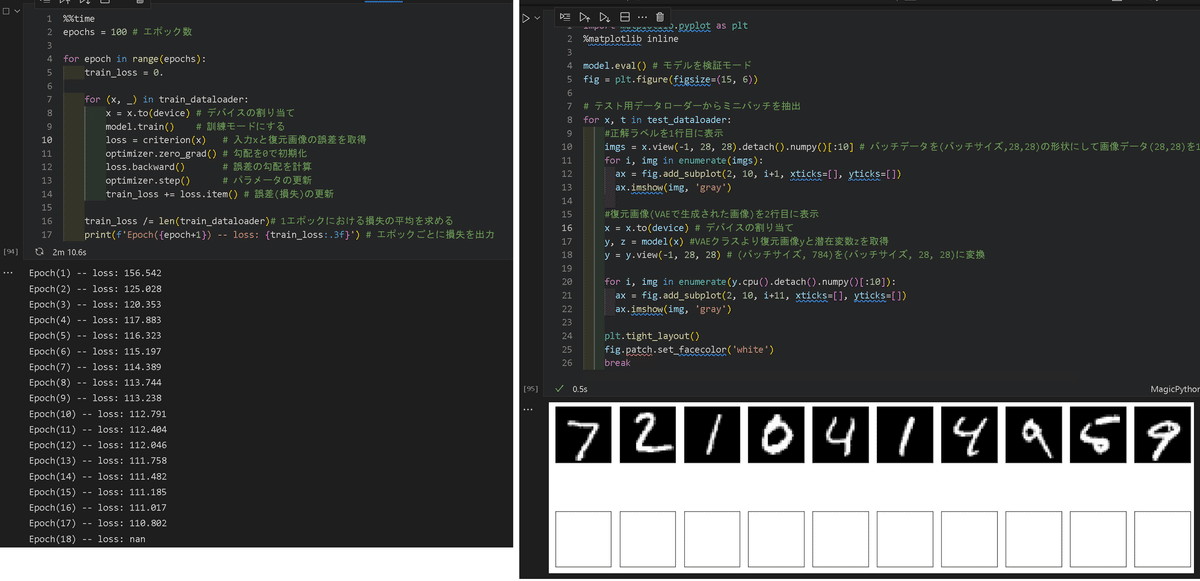
[IN]
%%time
epochs = 10 # エポック数
for epoch in range(epochs):
train_loss = 0.
for (x, _) in train_dataloader:
x = x.to(device) # デバイスの割り当て
model.train() # 訓練モードにする
loss = criterion(x) # 入力xと復元画像の誤差を取得
optimizer.zero_grad() # 勾配を0で初期化
loss.backward() # 誤差の勾配を計算
optimizer.step() # パラメータの更新
train_loss += loss.item() # 誤差(損失)の更新
train_loss /= len(train_dataloader)# 1エポックにおける損失の平均を求める
print(f'Epoch({epoch+1}) -- loss: {train_loss:.3f}') # エポックごとに損失を出力
[OUT]
Epoch(1) -- loss: 155.617
Epoch(2) -- loss: 125.080
Epoch(3) -- loss: 120.417
Epoch(4) -- loss: 117.855
Epoch(5) -- loss: 116.243
Epoch(6) -- loss: 115.136
Epoch(7) -- loss: 114.379
Epoch(8) -- loss: 113.715
Epoch(9) -- loss: 113.212
Epoch(10) -- loss: 112.736
Wall time: 1min 11s【エラー:未解決】
たくさん学習するほどきれいな画像が出ると思ったのですが本ケースでは”epoch数が15回を超えるとnanが出て最終的に画像が出力されなくなる”状態が発生します。
原因不明ですが突然再構築ロスの方がnanになる現象が発生しています

logは入力値x=0で-inf, x<0でnanになるためBCEに使用する値はsigmoid関数に通すなどして0を超過する必要があります。(今回はsigmoidを通しているので別の部分のエラーだとは思います)
[IN]
torch.log(torch.tensor(-1)), torch.log(torch.tensor(0))
[OUT]
(tensor(nan), tensor(-inf))3-5.推論1:画像データを復元
学習が完了したら、未知画像(学習に使用していないテストデータ)を使用して入力画像をVAEにいれても画像が復元されるか確認します。
コードとしては1行目にテストデータを10枚表示、2行目にはそれぞれのテスト画像をVAEに通した後の出力値(復元画像)を表示しました。
[IN]
import matplotlib.pyplot as plt
%matplotlib inline
model.eval() # モデルを検証モード
fig = plt.figure(figsize=(15, 6))
# テスト用データローダーからミニバッチを抽出
for x, t in test_dataloader:
#正解ラベルを1行目に表示
imgs = x.view(-1, 28, 28).detach().numpy()[:10] # バッチデータを(バッチサイズ,28,28)の形状にして画像データ(28,28)を10個抽出し、ndarrayに変換
for i, img in enumerate(imgs):
ax = fig.add_subplot(2, 10, i+1, xticks=[], yticks=[])
ax.imshow(img, 'gray')
#復元画像(VAEで生成された画像)を2行目に表示
x = x.to(device) # デバイスの割り当て
y, z = model(x) #VAEクラスより復元画像yと潜在変数zを取得
y = y.view(-1, 28, 28) # (バッチサイズ, 784)を(バッチサイズ, 28, 28)に変換
for i, img in enumerate(y.cpu().detach().numpy()[:10]):
ax = fig.add_subplot(2, 10, i+11, xticks=[], yticks=[])
ax.imshow(img, 'gray')
plt.tight_layout()
fig.patch.set_facecolor('white')
break
[OUT]
結果はそれなりの形で復元されていますが比較的かすれが大きいです。
3-6.推論2:標準正規分布のランダム値から画像生成
完全に学習されたVAEでは”Reparameterization trick”による出力値は標準正規分布となります。よって画像データを"Encoder+latent_variable"に通して出力zを作成しなくとも、標準正規分布を潜在変数に入力すれば何かしらの画像が出力されます。
まずは入力する標準正規分布となる乱数値を作成します。
[IN]
torch.manual_seed(0) # 乱数の固定
batch_size=30
z = torch.randn(batch_size, 10, device = device)
print(z[0])
print(z.shape, torch.mean(z, dim=1), torch.var(z, dim=1))
[OUT]
tensor([-0.9247, -0.4253, -2.6438, 0.1452, -0.1209, -0.5797, -0.6229, -0.3284,
-1.0745, -0.3631], device='cuda:0')
torch.Size([30, 10])
tensor([-0.6938, 0.6776, -0.2208, -0.0309, 0.1640, 0.0177, -0.2325, -0.1611,
-0.0731, 0.0579, 0.0522, -0.0108, -0.0712, -0.2779, 0.0749, 0.0623,
-0.1061, -0.1265, -0.0851, -0.5171, -0.5069, -0.1617, 0.3769, 0.0801,
-0.5280, 0.2894, 0.2722, -0.2616, -0.1286, -0.1590], device='cuda:0')
tensor([0.5962, 1.2443, 0.9752, 0.7753, 0.7877, 0.4414, 0.5810, 0.5045, 1.4193,
1.0641, 0.6361, 1.6913, 1.2194, 1.5255, 0.4857, 0.6717, 0.7158, 1.0763,
0.9264, 0.3349, 0.9197, 1.1440, 1.3931, 0.7919, 1.6299, 2.2360, 0.6088,
0.6666, 0.6944, 0.8321], device='cuda:0')それではEncoderも入力画像も使用せず、標準正規分布に従う乱数値から画像を生成します。
[IN]
model.eval() # VAEモデルを評価モードにする
images = model.decoder(z) # 潜在変数zをデコーダーに入力して画像を生成する
images = images.view(-1, 28, 28) # 出力されたデータの形状を(バッチサイズ,28,28)にする
images = images.detach().cpu().numpy() # detach().cpu()でテンソルを抽出してndarrayに変換
fig = plt.figure(figsize=(15, 6))
# 生成された画像をインデックスと共に抽出して描画する
for i, image in enumerate(images):
plt.subplot(3, 10, i+1) # 2×4のマス目に描画
plt.imshow(image, cmap='binary_r') # グレースケールで描画
plt.axis('off')
plt.tight_layout()
plt.show()
[OUT]
結果としてそれっぽい画像が生成されました。つまり潜在変数には学習させたMNIST(手書き数値)の情報が圧縮されており、標準正規分布に従う入力値を潜在変数に入力してDecodeするだけで複数の手書き画像が作成できることが確認できました。
4.VAEのさらなる理解へ
VAEは潜在変数(Latent variable)に学習した記憶(重み)をもっておりますが、それがどういうものなのかを可視化して理解していきたいと思います。
4-1.潜在変数の可視化
追って※潜在空間の次元数が2次元でうまく学習できないため
5.参考:動作確認用コード
5ー1.ガウスノイズ(標準正規分布):torch.randn()
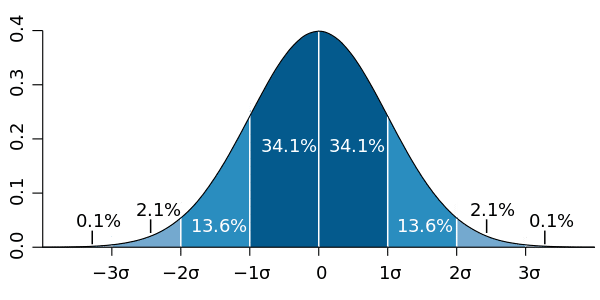
正規分布(ガウス分布)は下記の特徴を持ちます。
※$${平均値 :\mu}$$、$${標準偏差 :\sigma}$$、$${分散 :\sigma^2}$$
【正規分布(ガウス分布)の特徴】
●確率論や統計学で使用される確率分布の一つ
●左右対称,の形状をもち、データが平均値周辺に集積している。
●μ±σの範囲内に入るか確率は68.27%, μ±2σだと95.45%となる。
ー>品質管理で使用される「シックスシグマ」などでも使用される
●平均値μ=0, 分散=1の正規分布を標準正規分布という。
$$
正規分布f(x)=\dfrac{1}{\sqrt{2\pi\sigma^2}}\exp(-\dfrac{(x-\mu)^ 2}{2\sigma^ 2})
$$
$$
標準正規分布f(x)=\dfrac{1}{\sqrt{2\pi}}\exp(-\dfrac{x^ 2}{2})
$$
この正規分布しているデータをノイズとして使用するものを「ガウスノイズ」と言います。
kerasであれば「tf.keras.layers.GaussianNoise」が使用できますが、Pytorchであればtorch.randn()で標準正規分布の生成が可能です。
[IN]
import torch
import seaborn as sns
import matplotlib.pyplot as plt
tensor = torch.randn((1,10)) #(batch数, 潜在変数の次元数)
print(tensor)
t = torch.randn(10000)
print(f'torch.randnの平均μ: {t.mean():.3f}, 標準偏差σ: {t.std():.3f}, 分散var: {t.var():.3f}')
sns.histplot(torch.randn(30000))
plt.xticks([-4+i for i in range(9)])
plt.grid()
plt.show()
[OUT]
tensor([[ 1.6800, -0.7341, -0.1988, 0.4247, 1.1501, 0.1086, -0.2672, 3.0587,
-0.3651, -0.8004]])
torch.randnの平均μ: -0.010, 標準偏差σ: 1.010, 分散var: 1.021
5-2.Tensorの合計Σと平均の計算
損失関数を計算する時に各データにおける損失値の合計を計算して平均値を取得します。
$$
BCE誤差:E(w) = -\sum_{i=1}^n[t_{i}\log f_{w}(x_{i}) + (1 - t_{i})\log (1 - f_{w}(x_{i}))]
$$
$$
潜在ロス: L = -\frac{1}{2}\sum_{j=1}^k(1+\log \sigma^2_{j}-\mu^2_{j}-\sigma^2_{j})
$$
Pytorchでは合計はtorch.sum(<data>)、平均値はtorch.mean(<data>)で計算します。また合計値は引数のdimを使用することで行方向や列方向の合計を取得できます。
[IN]
t = torch.arange(1, 13).reshape(3, 4).float()
print(t)
print(torch.sum(t)) #全要素の和
print(torch.mean(t)) #全要素の平均
print(torch.sum(t, dim=1)) #行ごとの和
print(torch.mean(torch.sum(t, dim=1))) #行ごとの和の平均
[OUT]
tensor([[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.]])
tensor(78.)
tensor(6.5000)
tensor([10., 26., 42.])
tensor(26.)参考資料
https://www.baeldung.com/cs/vae-reparameterization
あとがき
損失関数を重ねてた場合、学習時の誤差逆伝搬の挙動を完全に理解できていないので理解出来たら追記。
本当は異常検知をやりたいけど、まだまだ知識不足なので追って
この記事が気に入ったらサポートをしてみませんか?