機械学習モデルの実装:AutoEncoder(Pytorch)

1.概要
本記事ではAutoEncoderをPytorchで実装します。ライブラリ紹介ではなく実装がメインのため学習シリーズに近い内容となります。
AutoEncoderの特徴は下記の通りです。
【モデルの特徴】
●自身のデータが教師(ラベル)になるためデータへのラベリングが不要
ー>教師無し学習に該当
●画像データの場合、入力した画像と同じ画像を出力できる(データ圧縮)
【使い方】
●情報を圧縮することで軽い動作で使用できる。
ー>本記事では784次元の画像を200次元(潜在空間)に圧縮
●入力値(正解データ)と出力値の差分をとることで異常検知などが可能
●ノイズ除去や白黒画像の彩色(Colorization)※実用的にはGANを使用
2.AutoEncoder概念の理解
2-1.一般的なモデル(教師あり学習)
まず一般的なモデルを整理すると下記の通りです。
入力値に対して教師データ(ラベル)が1:1である
出力値とラベルの誤差(損失関数で計算)から誤差逆伝搬で学習
誤差が最小になるように学習を繰り返す
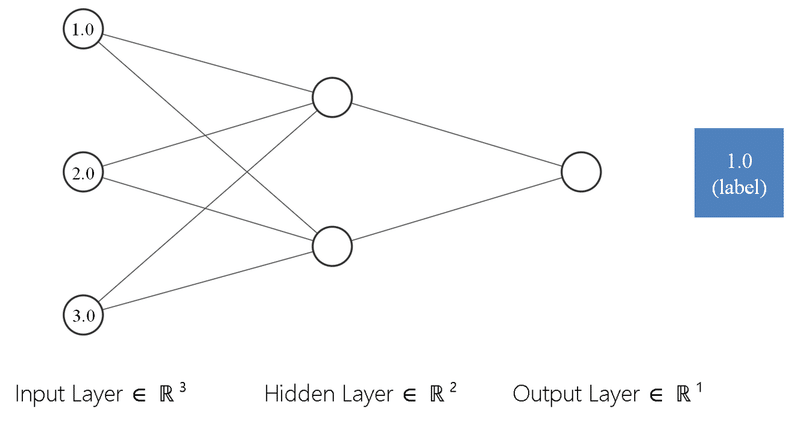
上図のように入力(3次元)->出力(1次元)にする全結合は下記の通りです。
[IN]
import torch
import torch.nn as nn
import torch.optim as optim
from torchinfo import summary
torch.manual_seed(0) #乱数の固定
x = torch.tensor([[1., 2., 3.]]) #入力値
label = torch.tensor([[1.]]) #正解ラベル
model = nn.Sequential(
nn.Linear(3, 2), #入力3次元、出力2次元の全結合層
nn.ReLU(inplace=True), #活性化関数
nn.Linear(2, 1), #入力2次元、出力1次元の全結合層
)
print(f'初期値| x:{x}, label:{label}, pred:{model(x)}')
print(f'x.shape:{x.shape}, label.shape:{label.shape}, pred.shape:{model(x).shape}')
print(summary(model, input_size=(1, 3)))
lr = 0.01
criterion = nn.MSELoss() #損失関数:平均二乗誤差
optimizer = optim.Adam(model.parameters(), lr=lr) #最適化手法:Adam
model, x = model.to('cpu'), x.to('cpu') #モデルと入力をCPUに移動
for epoch in range(200):
optimizer.zero_grad() #勾配の初期化
y = model(x) #順伝播
loss = criterion(y, label) #損失の計算
loss.backward() #誤差逆伝播
optimizer.step() #パラメータの更新
if epoch % 20 == 0:
print(f'epoch: {epoch}, loss: {loss:.3f}')
[OUT]
初期値| x:tensor([[1., 2., 3.]]), label:tensor([[1.]]), pred:tensor([[-0.2039]], grad_fn=<AddmmBackward>)
x.shape:torch.Size([1, 3]), label.shape:torch.Size([1, 1]), pred.shape:torch.Size([1, 1])
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Sequential -- --
├─Linear: 1-1 [1, 2] 8
├─ReLU: 1-2 [1, 2] --
├─Linear: 1-3 [1, 1] 3
==========================================================================================
Total params: 11
Trainable params: 11
Non-trainable params: 0
Total mult-adds (M): 0.00
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
==========================================================================================
epoch: 0, loss: 1.449
epoch: 20, loss: 0.204
epoch: 40, loss: 0.036
epoch: 60, loss: 0.004
epoch: 80, loss: 0.000
...
epoch: 120, loss: 0.000
epoch: 140, loss: 0.000
epoch: 160, loss: 0.000
epoch: 180, loss: 0.000[IN ※学習後の結果出力]
model(torch.tensor([[1., 2., 3.]]))
[OUT]
tensor([[1.0000]], grad_fn=<AddmmBackward>)2-2.AutoEncoderのモデル概要
AutoEncoderのモデルを整理すると下記の通りです。
入力値と同じ次元数の出力を作成
教師データは入力値となるため、出力値と入力値の誤差(損失関数で計算)から誤差逆伝搬で学習
誤差が最小になるように学習を繰り返す
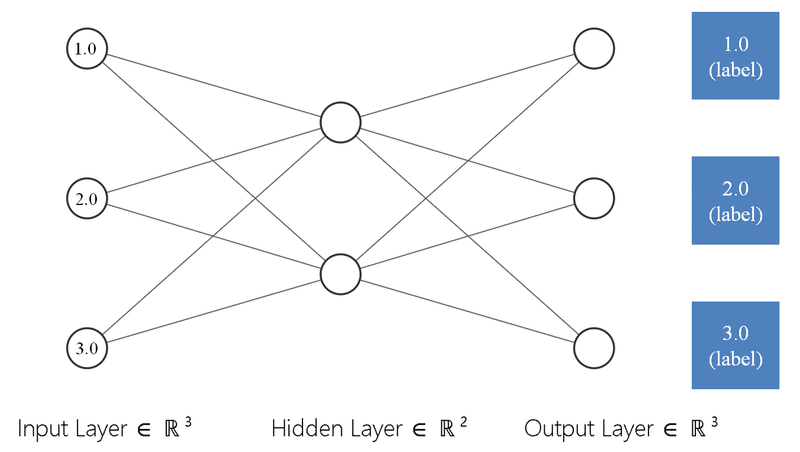
上図のように入力値(torch.tensor([[1., 2., 3.]]))から出力値(入力値と同じ形)を自身から学習するのは下記の通りです。
なお今回は損失関数はMSEを使用しており3つのノードがあるため、N=3となります。
$$
平均二乗誤差(MSE)=\frac{1}{N}\sum_{i=1}^{N}(y_{pred}-y_{label})^2
$$
[IN]
import torch
import torch.nn as nn
import torch.optim as optim
from torchinfo import summary
torch.manual_seed(0) #乱数の固定
x = torch.tensor([[1., 2., 3.]]) #入力値 ※labelデータは無し(xがlabelになる)
AutoE = nn.Sequential(
nn.Linear(3, 2), #入力3次元、出力2次元の全結合層
nn.ReLU(inplace=True), #活性化関数
nn.Linear(2, 3), #入力2次元、出力1次元の全結合層
)
print(f'初期値| x:{x}, label:{label}, pred:{AutoE(x)}')
print(f'x.shape:{x.shape}, label.shape:{label.shape}, pred.shape:{AutoE(x).shape}')
print(summary(AutoE, input_size=(1, 3)))
lr = 0.01
criterion = nn.MSELoss() #損失関数:平均二乗誤差
optimizer = optim.Adam(AutoE.parameters(), lr=lr) #最適化手法:Adam
AutoE, x = AutoE.to('cpu'), x.to('cpu') #モデルと入力をCPUに移動
for epoch in range(1000):
optimizer.zero_grad() #勾配の初期化
y = AutoE(x) #順伝播
loss = criterion(y, x) #損失の計算 ※label=x
loss.backward() #誤差逆伝播
optimizer.step() #パラメータの更新
if epoch % 100 == 0:
print(f'epoch: {epoch}, loss: {loss:.3f}')
[OUT]
初期値| x:tensor([[1., 2., 3.]]), label:tensor([[1.]]), pred:tensor([[-0.2816, 0.0189, 0.2549]], grad_fn=<AddmmBackward>)
x.shape:torch.Size([1, 3]), label.shape:torch.Size([1, 1]), pred.shape:torch.Size([1, 3])
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Sequential -- --
├─Linear: 1-1 [1, 2] 8
├─ReLU: 1-2 [1, 2] --
├─Linear: 1-3 [1, 3] 9
==========================================================================================
Total params: 17
Trainable params: 17
Non-trainable params: 0
Total mult-adds (M): 0.00
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
==========================================================================================
epoch: 0, loss: 4.368
epoch: 100, loss: 1.522
epoch: 200, loss: 0.461
epoch: 300, loss: 0.119
epoch: 400, loss: 0.025
...
epoch: 600, loss: 0.001
epoch: 700, loss: 0.000
epoch: 800, loss: 0.000
epoch: 900, loss: 0.000[IN]
AutoE(torch.tensor([[1., 2., 3.]]))
[OUT]
tensor([[1.0000, 2.0000, 2.9998]], grad_fn=<AddmmBackward>)3.MNISTによる画像データの生成
MNISTを使用して入力画像から同じ画像を生成します。これで何ができるとかではなく、あくまで学習用です。
3-1.MNISTデータの理解およびデータ取得
MNIST(Mixed National Institute of Standards and Technology database)とは手書きの数値であり下記特徴があります。
学習用データ数:60,000枚、テスト用データ数:10,000枚
画像サイズは(1, 28, 28)の白黒データ
データサイズは8bitグレースケールであり0~255(int)である
MNISTデータは”torchvision.datasets”でラベルと合わせて取得可能です。
[IN]
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# トランスフォームオブジェクトを生成
transform = transforms.Compose(
[transforms.ToTensor(), # Tensorオブジェクトに変換
nn.Flatten()]) # データの形状を(28, 28)から784,)に変換
# MNISTの訓練用データ
mnist_train = torchvision.datasets.MNIST(
root='MNIST',
download=True, # ダウンロードを許可
train=True, # 訓練データを指定
transform=transform) # トランスフォームオブジェクト
# MNISTのテスト用データ
mnist_test = torchvision.datasets.MNIST(
root='MNIST',
download=True, # ダウンロードを許可
train=False, # テストデータを指定
transform=transform) # トランスフォームオブジェクト
# データローダーを生成
train_dataloader = DataLoader(mnist_train, # 訓練データ
batch_size=124, # ミニバッチのサイズ
shuffle=True) # 抽出時にシャッフル
test_dataloader = DataLoader(mnist_test, # テストデータ
batch_size=1, # テストなので1
shuffle=False) # 抽出時にシャッフルしない
[OUT]
MNISTフォルダが作成され、その中にデータが格納される
(※データそのものはtorchvision.datasets.MNISTのインスタンス化時に自動で取得)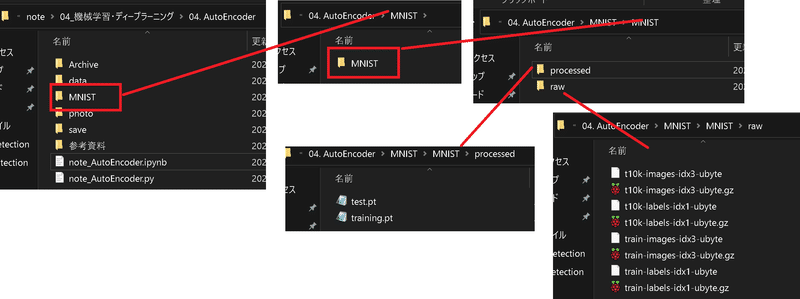
なおサンプルを1つ取り出して中身を見ると、下記が確認できます。
”torchvision.datasets”で取得したデータは(data, label)のTuple型
データセット取得時に"transform"で前処理しているため、画像データは1次元配列であり正規化(min:0, max:1)されている。
[IN]
import matplotlib.pyplot as plt
_ = mnist_train[0]
print(f'type:{type(_)}, data:{_[0].shape}, label:{_[1]}')
print(f'最大値:{_[0].max()}, 最小値:{_[0].min()}')
plt.imshow(_[0].reshape(28, 28), cmap='gray')
[OUT]
type:<class 'tuple'>, data:torch.Size([1, 784]), label:5
最大値:1.0, 最小値:0.0
3-2.AutoEncoderモデル作成/パラメータ設定
AutoEncoderのモデルを作成します。今回は全結合モデルとして784ノードを200に圧縮(Encode)したのち復元(Decode)します。モデルの注意点は下記の通りです。
活性化関数:中間層はReLUを使用するが最終層は「正規化されたデータに合わせる+BCEを使用(0~1の確率値)」のためsigmoid関数を使用
損失関数はバイナリークロスエントロピー(BCE)を使用:正規化されたデータの場合MSE(平均2乗誤差)より学習速度が速いため良い。
入力値も出力値も同様に形状は"[batch, 1, 784]"となる。BCEでは784個のデータのlossを計算して誤差逆伝搬により学習する

コード化すると下記の通りです(私はPCではCUDAを利用)。
[IN]
class Autoencoder(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(784, 200) # エンコーダー(200ユニット)
self.l2 = nn.Linear(200, 784) # デコーダー(784ユニット)
def forward(self, x):
h = self.l1(x) # エンコーダーに入力
h = torch.relu(h) # ReLU関数を適用
h = self.l2(h) # デコーダーに入力
y = torch.sigmoid(h) # シグモイド関数を適用
return y
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
import torch.optim as optimizers
model = Autoencoder().to(device) # オートエンコーダーを生成
criterion = nn.BCELoss() # 損失関数はバイナリクロスエントロピー誤差
optimizer = optimizers.Adam(model.parameters()) # オプティマイザー(最適化関数)をAdamに設定
[OUT]
cuda3-3.学習/推論
通常の流れで学習させます(特に検証(val)は無し)。
モデルを使用して推論値を計算する
損失関数を使用して"正解値(入力値)"と"推論値"から誤差を求める
loss.backward()で各パラメータの勾配を求める
optimizer.step()によりパラメータを更新する
optimizer.zero_grad()によりパラメータの勾配を初期化する
1~5をループ計算する
[IN]
%%time
epochs = 10 # エポック数
# 学習の実行
for epoch in range(epochs):
train_loss = 0.
# ミニバッチのループ(ステップ)
for (x, _) in train_dataloader:
x = x.to(device) # デバイスの割り当て
model.train() # 訓練モードにする
preds = model(x) # モデルの出力を取得
loss = criterion(preds, x) # 入力xと復元predsの誤差を取得
optimizer.zero_grad() # 勾配を0で初期化
loss.backward() # 誤差の勾配を計算
optimizer.step() # パラメーターの更新
train_loss += loss.item() # 誤差(損失)の更新
# 1エポックあたりの損失を求める
train_loss /= len(train_dataloader)
# 1エポックごとに損失を出力
print('Epoch({}) -- Loss: {:.3f}'.format(
epoch+1,
train_loss
))
[OUT]
Epoch(1) -- Loss: 0.162
Epoch(2) -- Loss: 0.090
Epoch(3) -- Loss: 0.077
Epoch(4) -- Loss: 0.072
Epoch(5) -- Loss: 0.070
Epoch(6) -- Loss: 0.069
Epoch(7) -- Loss: 0.068
Epoch(8) -- Loss: 0.067
Epoch(9) -- Loss: 0.067
Epoch(10) -- Loss: 0.066
Wall time: 53.5 s学習後の入力・出力値を可視化すると下記の通りです。学習させていないテストデータ画像でも1つのモデルから入力と同じ画像を出力できてます。
[IN]
import matplotlib.pyplot as plt
# テストデータを1個取り出す
_x, _ = next(iter(test_dataloader))
_x = _x.to(device)
model.eval() # ネットワークを評価モードにする
x_rec = model(_x) # テストデータを入力して結果を取得
# 入力画像、復元画像を表示
titles = {0: 'Original', 1: 'Autoencoder:Epoch=10'}
for i, image in enumerate([_x, x_rec]):
image = image.view(28, 28).detach().cpu().numpy()
plt.subplot(1, 2, i+1)
plt.imshow(image, cmap='binary_r')
plt.axis('off'), plt.title(titles[i])
plt.show()
[OUT]
なお各Epochでの画像は下記の通りであり今回のケースでは比較的早い段階で高い精度が出ております(学習データが大量にあるためと思います)。

参考資料
あとがき
AutoEncoderを用いた差分検出による異常検知はさらに理解が深まったら実装してみたい。
この記事が気に入ったらサポートをしてみませんか?