
Python機械学習(フレームワーク):Pytorch Lightning

1.概要
Pytorch LightningはPytorchでの機械学習モデルの記法をより簡略化できるPyTorchラッパーとなります。「Pytorch LightningはVersionによりAPIが大幅に変わる」ため別Ver.とまともに動かないので注意が必要です。
本記事では"Ver2.0.1"となります。
参考として、より高位のラッパーとして「Lightning Flash」があります。ただし柔軟性に乏しいため本記事での説明は省略します。
1-1.Pytorch Lightningの特徴
Pytorchでは実装を自由にできる反面、細かい処理を自分で記載する必要があります。一例として下記があります。
【Pytorchで実装に必要な処理】
目的関数(損失関数):lossは計算前に”optimizer.zero_grad()”で初期化
推論値とラベルからlossを計算後に、"loss.backward()"で勾配の計算をして、”loss.step()”で重み・バイアスを更新する必要がある
GPUの有無を確認後に”device=torch.device(<cpu/gpu>)”でDeviceを割り当てて、変数とモデルの重みの両方をdeviceに転送する
Early StoppingやLoggingのような基本的な機能ががない
可視化に関しても基本的には自作する必要がある
Pytorch Lightningでは、上記のような処理をより簡単に実装できるAPIに変更されています。
1-2.環境構築
まず注意点として「仮想環境を使用」してください。私は既存環境でpip installしたらPytorchの環境が壊れました。
インストールは”pip install lightning”が推奨です。なおpypiでは”pip install pytorch-lightning”ですが、GitHubでは前者です。新規の場合は公式Docsを参照してください。
[Terminal]
pip install lightning1-2-1.参考1:仮想環境の作り方
仮想環境を作成します。詳細は別記事にあるため、本記事では実施内容のみです。一括ライブラリインストールは"Pythonの環境構築"記事の添付ファイルを使用して"pip install -r requirements.txt"で実行します。
【Case1:CPU-Onlyの環境作成】
「envpl」と言う名前の仮想環境作成:conda create -n envpl python
仮想環境の一覧表示:conda info -e
「envpl」環境に移動:activate envpl
モジュールの一括インストール:pip install -r requirements.txt
[terminal]
conda create -n envpl python
conda info -e
activate envpl
pip install lightning
pip install -r requirements.txt【Case2:GPUの環境作成】
大前提としてGPUの環境設定は難しいので理解できる人用です。自分の環境だけ出力しておきますのでそれに合わせてVersion設定が必要です。
[terminal]
nvcc -V
[OUT]
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Mon_Oct_12_20:54:10_Pacific_Daylight_Time_2020
Cuda compilation tools, release 11.1, V11.1.105
Build cuda_11.1.relgpu_drvr455TC455_06.29190527_0 2023年4月現在のlightningはPytorch2.0がインストールされます。My PCはCUDA11.1ですが、Pytorch2.0でも動くはずです。
gpu付Pytorchをインストール後にlightningを追加しました。
「plgpu」と言う名前の仮想環境作成:conda create -n plgpu python
仮想環境の一覧表示:conda info -e
「envpl」環境に移動:activate plgpu
モジュールの一括インストール:pip install -r requirements.txt
[terminal]
conda create -n plgpu python
conda info -e
activate plgpu
pip install lightning
pip install -r requirements.txt
環境とVersionは下記の通りです。
[IN]
import torch
import lightning as L
import lightning.pytorch as pl
print(torch.__version__)
print(L.__version__)
torch.cuda.is_available()
[OUT]
2.0.0+cu117
2.0.1.post0
True1-2-2.参考2:Pytorchの環境が壊れた時の修復
仮想環境を作らずにインストールして環境が壊れた場合は再インストールが必要です。詳細は下記記事に記載しています。
1-3.Core APIの紹介
Pytorch LightningにはCORE APIとして大きく「LightningModule」と「Trainer」の2つがあります。
LightningModule:機械学習モデルの設計、学習方法、ハイパーパラメータ調整調整など
Trainer:学習方法の選定

1-4.サンプルデータ
説明用として簡単な自作データセットを事前に作成しました。
[IN]
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import torch
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
#サンプルデータセット作成用
class Dataset_sample(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def plot_linescat(ax, xs, ys, label=None, xlabel='x', ylabel='y', title=None, graph='line', verbose1=False, verbose2=False):
if graph == 'line':
ax.plot(xs, ys, label=label, lw=2.0, color='red')
elif graph == 'scatter':
if label == 'train':
ax.scatter(xs, ys, s=10, label=label, marker='o', color='blue')
elif label == 'val':
ax.scatter(xs, ys, s=10, label=label, marker='^', color='orange')
elif label == 'test':
ax.scatter(xs, ys, s=10, label=label, marker='x', color='green')
else:
ax.scatter(xs, ys, s=10, label=label)
else:
assert False, f'graphの値が不正です。graph={graph}'
if title:
ax.set(xlabel=xlabel, ylabel=ylabel, title=title)
else:
ax.set(xlabel=xlabel, ylabel=ylabel)
if verbose1:
ax.legend()
if verbose2:
ax.grid()
#サンプルデータ作成
x = torch.linspace(0, 10, 1000)
y = 2*x + 1 + torch.randn(1000)
x, y = x.reshape(-1, 1), y.reshape(-1, 1) #Pytorchで学習できるように2次元配列
#学習・検証・テストデータに分割
#テストデータ:元のデータの後ろ10%を使用(学習しないためシャッフル不要)
X_test, y_test = x[900:], y[900:]
#学習・検証データに分割
X_train, X_val, y_train, y_val = train_test_split(x[:900], y[:900], test_size=0.2, random_state=0) #学習データと検証データに分割
train_dataset, val_dataset, test_dataset = Dataset_sample(X_train, y_train), Dataset_sample(X_val, y_val), Dataset_sample(X_test, y_test)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
print(f'データ形状 学習X:{X_train.shape} 検証X:{X_val.shape} テストX:{X_test.shape}')
print(f'データ形状 学習y:{y_train.shape} 検証y:{y_val.shape} テストy:{y_test.shape}')
print(f'Dataset 学習:{len(train_dataset)} 検証:{len(val_dataset)} テスト:{len(test_dataset)}')
print(f'DataLoader 学習:{len(train_dataloader)} 検証:{len(val_dataloader)} テスト:{len(test_dataloader)}')
fig, ax = plt.subplots(1, 1, figsize=(10, 5), facecolor='w')
ax.set(xlim=(0, 11), ylim=(0, 24), xticks=np.arange(0, 12, 1), yticks=np.arange(0, 25, 2))
plot_linescat(ax, x, 2*x+1, label=r'$y=2x+1$', xlabel='x', ylabel='y', graph='line', verbose1=False, verbose2=False)
plot_linescat(ax, X_train, y_train, label='train', xlabel='x', ylabel='y', graph='scatter', verbose1=False, verbose2=False)
plot_linescat(ax, X_val, y_val, label='val', xlabel='x', ylabel='y', graph='scatter', verbose1=False, verbose2=False)
plot_linescat(ax, X_test, y_test, label='test', xlabel='x', ylabel='y', title='自作サンプルデータ', graph='scatter', verbose1=True, verbose2=True)
[OUT]
データ形状 学習X:torch.Size([720, 1]) 検証X:torch.Size([180, 1]) テストX:torch.Size([100, 1])
データ形状 学習y:torch.Size([720, 1]) 検証y:torch.Size([180, 1]) テストy:torch.Size([100, 1])
Dataset 学習:720 検証:180 テスト:100
DataLoader 学習:23 検証:6 テスト:4
2.LightningModule(基礎編)
まずはLightning Moduleについて紹介します。まずはモジュールをインポートして乱数値を固定しておきます。
[IN]
import lightning.pytorch as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchinfo import summary
def fix_randomseed(seed=0):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
fix_randomseed() #乱数固定
[OUT] Pytorchではモデル作成のために"nn.Module"を継承しましたが、Pytorch Lightningでは"pl.LightningModule"を使用します。このモジュールを継承すると、モデルだけでなく学習・検証・テスト・推論ループや最適化関数設定などを一つのクラス内で設定可能になります。
"LightningModule"は6つのセクションに分かれます。なお各Phase(訓練・検証・テストなど)で使用する関数名はあらかじめ決まっているため、関数名の定義には注意が必要です。
Initialization (__init__ and setup()).
Train Loop (training_step())
Validation Loop (validation_step())
Test Loop (test_step())
Prediction Loop (predict_step())
Optimizers and LR Schedulers (configure_optimizers())
2-1.カスタムクラス:pl.LightningModule
Pytorchではカスタムクラスを作成するために”nn.Module”クラスを継承しましたが、Pytorch Lightningでは”pl.LightningModule”を継承します。前述の通り継承クラスでのメソッド名は決まっているため変更はできません。
APIはたくさんあるため公式Docsから一部抽出しました。
__init__(): モデルの初期化
forward(): モデルの順伝搬(推論)
training_step(): モデルの学習用
training_epoch_end(): 訓練エポックの終了時に呼び出し
validation_step(): 検証時に使用されるステップ
validation_epoch_end(): 検証エポックの終了時に呼び出し
test_step(): テスト時に使用されるステップ
test_epoch_end(): テストエポックの終了時に呼び出し
configure_optimizers(): オプティマイザーの設定
lr_scheduler(): 学習率スケジューラーの設定
train_dataloader(): 訓練データローダーを返す
val_dataloader(): 検証データローダーを返す
test_dataloader(): テストデータローダーを返す
これ以降ではそれぞれのAPIを紹介します。
2-2.カスタムクラスの初期化:__init__()
一番簡単なモデルを作成していきます。過去記事「Pythonライブラリ:scikit-learn (前処理・Score確認編)」で説明の通り、機械学習をするには最低限①機械学習モデルの作成、②学習(損失関数の設定)、③最適化関数の設定、④推論 が必要になるため、まずはこれらを実装します。

モデルの初期化をするにはPytorchの”nn.Module”と同様にクラスに渡した"pl.LightningModule"を継承します。これにより様々なAPIを使用することが出来ます。
[IN]
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
#モデルの作成
net = Net()
print(net)
print(net.state_dict())[OUT]
Net(
(fc): Linear(in_features=1, out_features=1, bias=True)
)
OrderedDict([('fc.weight', tensor([[-0.0075]])), ('fc.bias', tensor([0.5364]))]) "pl.LightningModule"を継承することでモデル作成できることが確認できます(重み、バイアスは学習前のため乱数値)。
ただし現状クラス内にはモデルしか定義しておらずこのままでは全く使えないため、その他処理をクラス内に追加していきます。
2-3.学習ステップ:training_step()
機械学習モデルの学習ステップとして"training_step()"があります。本メソッドでは下記処理フロー(概要)を一括で実施してくれます。
学習モードへの変更:model.train()
勾配の設定(学習時はrequires_grad=Trueに設定):
torch.set_grad_enabled(True)
データローダーのforループ:
for batch_idx, batch in enumerate(train_dataloader)
損失関数の計算:loss = training_step(batch, batch_idx)
最適化関数の勾配初期化:optimizer.zero_grad()
損失関数の勾配計算(誤差逆伝搬):loss.backward()
重み・バイアスの更新:optimizer.step()
(オプション)ログの記録:データローダー学習時のLossをリストに格納して、学習後にLossの平均値を保存
メソッド作成時の注意点としては下記の通りです。
引数は"batch"と"batch_idx"の2つ
"batch_idx"はコードの中では定義されないが裏側でDataLoaderのデータとIndexを取得するため要記載(無くてもエラーは出ないけど念のため)
trainig_step()の中で最適化関数の処理をしてくれるが、最適化関数の定義は別途"configure_optimizers()"で設定
ログを残す場合は別途”self.log()”を追加するか"on_train_epoch_end"メソッドを作成する
[IN]
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
def training_step(self, batch, batch_idx):
x, y = batch #データセット->説明変数と目的変数を抽出
y_pred = self.fc(x) #推論
loss = F.mse_loss(y_pred, y) #損失関数
return loss
#モデルの作成
net = Net()
print(net)
print(net.state_dict())
[OUT]学習を定義しましたがこれだけだと重みの更新方法(最適化)がないためエラーが発生しますので次に最適化関数を定義します。
[IN]※最適化関数の設定がないためエラー
net = Net() #モデルの作成
trainer = pl.Trainer(max_epochs=10) #学習器の作成
trainer.fit(net, train_dataloaders=train_dataloader) #学習
[OUT]
MisconfigurationException: No `configure_optimizers()` method defined. Lightning `Trainer` expects as minimum a `training_step()`, `train_dataloader()` and `configure_optimizers()` to be defined.2-3-1.学習時のログ保存:self.log()
紹介のみ

2-3-2.学習時の全ログ取得:def on_train_epoch_end
紹介のみ

2-4.最適化関数の設定:configure_optimizers()
クラス内に最適化関数を設定するには"configure_optimizers()"を使用します。最適化関数はPytorchのoptimから選定可能です。
モデルの定義・学習ステップ・最適化関数まで選定すればモデルの学習が可能になります(実際に学習させるためのTrainerは後述)。
[IN]
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
def training_step(self, batch, batch_idx):
x, y = batch #データセット->説明変数と目的変数を抽出
y_pred = self.fc(x) #推論
loss = F.mse_loss(y_pred, y) #損失関数
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
#モデルの作成
net = Net()
print(net)
print(net.state_dict())
trainer = pl.Trainer(max_epochs=20) #学習器の作成
trainer.fit(net, train_dataloaders=train_dataloader) #学習
print(net.state_dict())[OUT]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
--------------------------------
0 | fc | Linear | 2
--------------------------------
2 Trainable params
0 Non-trainable params
2 Total params
0.000 Total estimated model params size (MB)
Net(
(fc): Linear(in_features=1, out_features=1, bias=True)
)
学習前 Model Params:OrderedDict([('fc.weight', tensor([[-0.0075]])), ('fc.bias', tensor([0.5364]))])
`Trainer.fit` stopped: `max_epochs=20` reached.
学習後 Model Params:OrderedDict([('fc.weight', tensor([[2.0124]])), ('fc.bias', tensor([0.9468]))])(nn.Moduleと同様に)推論時は学習済みモデルにそのままデータを入れてもエラーがでるため、事前に"forward()"メソッドの定義が必要です。
[IN]
net(X_test) #テストデータを推論
net.forward(X_test) #テストデータを推論
[OUT]
NotImplementedError: Module [Net] is missing the required "forward" function2-5.推論:forward()
機械学習モデルが入力値から推論値を出力できるようにするために継承したカスタムクラスにforward()メソッドを定義する必要があります。
これで機械学習をするには最低限①機械学習モデルの作成、②学習(損失関数の設定)、③最適化関数の設定、④推論の機能を追加できました。
[IN]
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
def training_step(self, batch, batch_idx):
x, y = batch #データセット->説明変数と目的変数を抽出
y_pred = self.fc(x) #推論
loss = F.mse_loss(y_pred, y) #損失関数
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
def forward(self, x):
return self.fc(x)
net = Net()
trainer = pl.Trainer(max_epochs=20) #学習器の作成
trainer.fit(net, train_dataloaders=train_dataloader) #学習
y_pred_test = net(X_test) #テストデータを推論
print(f'テストデータ X:{X_test.shape}, y:{y_test.shape}, y_pred:{y_pred_test.shape}')
print(f'学習後 Model Params:{net.state_dict()}')
summary(net, input_size=(1, 1))[OUT]
テストデータ X:torch.Size([100, 1]), y:torch.Size([100, 1]), y_pred:torch.Size([100, 1])
学習後 Model Params:OrderedDict([('fc.weight', tensor([[1.9948]])), ('fc.bias', tensor([1.0544]))])
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Net [1, 1] --
├─Linear: 1-1 [1, 1] 2
==========================================================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 0.00
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
==========================================================================================結果を可視化しました。問題なく学習・推論できております。
[IN]
#可視化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6), facecolor='white')
#オリジナルデータプロット
plot_linescat(ax1, X_train, y_train, label='train', xlabel='x', ylabel='y', graph='scatter')
plot_linescat(ax1, X_val, y_val, label='val', xlabel='x', ylabel='y', graph='scatter')
plot_linescat(ax1, X_test, y_test, label='test', xlabel='x', ylabel='y', graph='scatter')
#推論結果プロット
plot_linescat(ax1, X_test, y_pred_test.detach().numpy(), label='predict', xlabel='x', ylabel='y',
title='全データとテストデータの推論値', graph='line', verbose1=True, verbose2=True)
#テストデータにおける正解値と予想値のプロット
plot_linescat(ax2, X_test, y_test, label='test', xlabel='x', ylabel='y', graph='scatter')
plot_linescat(ax2, X_test, y_pred_test.detach().numpy(), label='predict', xlabel='x', ylabel='y',
title='テストデータにおける正解値と予想値のプロット', graph='line', verbose1=True, verbose2=True)
plt.savefig('output/自作サンプルデータによる線形回帰のプロット1.png')
plt.show()
[OUT]
3.LightningModule(応用編)
前述で紹介していない”LightningModule”のメソッドを紹介します。
3-1.検証ステップ:validation_step()
一般的に過学習を防止するためにデータセットは「学習・検証・テスト」用に分割して学習・検証します。

モデル内で検証データによる性能確認する場合は"validation_step()"を定義します。本メソッドは下記処理フロー(概要)を一括で実施してくれます。
学習ステップを実行:training_step()
学習モード(train()), 勾配設定(torch.set_grad_enabled(True))
学習データローダーをforループで回す
Loss計算、勾配初期化、勾配計算、重み・バイアスの更新
評価モードへの変更:model.eval()
重み・バイアスの更新防止:torch.set_grad_enabled(False)
検証用データローダーのforループ:
損失関数の計算:loss = training_step(batch, batch_idx)
最適化関数の勾配初期化:optimizer.zero_grad()
損失関数の勾配計算(誤差逆伝搬):loss.backward()
重み・バイアスの更新:optimizer.step()
次の学習のために学習モード、勾配=Trueへ再設定
実装は下記の通りです。
[IN]
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
def training_step(self, batch, batch_idx):
x, y = batch #データセット->説明変数と目的変数を抽出
y_pred = self.fc(x) #推論
loss = F.mse_loss(y_pred, y) #損失関数
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
def forward(self, x):
return self.fc(x)
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self.fc(x)
loss = F.mse_loss(y_pred, y)
return loss
net = Net()
trainer = pl.Trainer(max_epochs=20)
trainer.fit(net,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader) #学習[OUT]
-3-2.テストステップ:test_step()
検証ステップと同様にテスト用は"test_step()"で実装できます。またテストの実行はTrainerオブジェクトのtest()メソッドで可能です(後述)。
[API]
Trainer.test(model=None, dataloaders=None,
ckpt_path=None, verbose=True, datamodule=None)テストデータは学習で使用しないためTrainerにtest_dataloadersのような引数はありません。
[IN]
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
def training_step(self, batch, batch_idx):
x, y = batch #データセット->説明変数と目的変数を抽出
y_pred = self.fc(x) #推論
loss = F.mse_loss(y_pred, y) #損失関数
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
def forward(self, x):
return self.fc(x)
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self.fc(x)
loss = F.mse_loss(y_pred, y)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
y_pred = self.fc(x)
loss = F.mse_loss(y_pred, y)
return loss
net = Net()
trainer = pl.Trainer(max_epochs=20)
trainer.fit(net,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader)
[OUT]
-4.Trainer(学習時の設定)
Pytorch LightningのCORE APIの2つめ「Trainer」を紹介します。”LightningModule”でモデルの定義や学習条件を設定しましたが、Trainerはそれ以外の部分を全て実装してくれます(下記は参考例)。
学習⇔検証・テスト時の勾配条件(requires_grad)を設定
training, validation, test dataloadersの実行
適切なタイミングでCalbackslの呼び出し
[API]
lightning.pytorch.trainer.trainer.Trainer(*, accelerator='auto', strategy='auto',
devices='auto', num_nodes=1,
precision='32-true', logger=None,
callbacks=None, fast_dev_run=False,
max_epochs=None, min_epochs=None,
max_steps=- 1, min_steps=None,
max_time=None,
limit_train_batches=None, limit_val_batches=None,
limit_test_batches=None, limit_predict_batches=None,
overfit_batches=0.0, val_check_interval=None,
check_val_every_n_epoch=1, num_sanity_val_steps=None,
log_every_n_steps=None,
enable_checkpointing=None,
enable_progress_bar=None,
enable_model_summary=None,
accumulate_grad_batches=1, gradient_clip_val=None, gradient_clip_algorithm=None,
deterministic=None, benchmark=None,
inference_mode=True,
use_distributed_sampler=True,
profiler=None, detect_anomaly=False,
barebones=False, plugins=None,
sync_batchnorm=False, reload_dataloaders_every_n_epochs=0,
default_root_dir=None)【参考1:スクリプト化】
Pythonスクリプト化する場合"main function"使用が推奨されますが、私はJupyterでしか使わないと思うので紹介まで(フラグは”LightningCLI”で設定可能)。

【参考2:より高度な最適化(スケーリング技術)】
Trainer()を使いこなすことで高度な最適化/高速化が可能ですが紹介のみ
4-1.乱数値の固定:seed_everything
Trainerオブジェクトではありませんが、"seed_everything"関数で乱数の固定ができます。乱数を固定することで再現性を確保できます。
[API]
seed_everything(seed=None, workers=False)下記の通り"lightning.pytorch "から呼び出すことが出来ます。
workers (bool):Trueの場合、Trainerに渡した"worker_init_fn"を全てのデータローダーに適切に設定する
[IN]
from lightning.pytorch import seed_everything
seed_everything(seed=0, workers=True)
[OUT]4-2.学習器の作成:pl.Trainer()
モデルの学習をするための学習器(trainer)オブジェクトは”pl.Trainer()”で作成します。pl.Trainer()に渡す引数を設定することで学習時の詳細な条件を設定できます。
4-2-1.学習の回数・時間設定
学習の回数などの設定が可能です。max_stepsが設定されていない場合はmax_epochsの値が使用されます。
max_epochs{defaluts:1000}:学習時における最大エポック数
min_epochs:学習時における最小エポック数
max_steps{defaluts:-1}:最適化関数が勾配を更新する最大回数
min_steps:最適化関数が勾配を更新する最小回数
max_time{default:None}:学習する最大の時間
[IN]
net = Net()
trainer = pl.Trainer(max_epochs=20)
trainer.fit(net, train_dataloader)
[OUT]
-なお学習時の各用語の意味は下記の通りです。
エポック:データセットを1回処理すること
バッチ:機械学習モデルに学習させるデータ数
イテレーション:指定したバッチ数で1エポックを処理するための回数
4-2-2.GPU/最適条件の設定
pl.Trainer()で使用するDeviceの種類・下図、最適条件を設定できます。
accelerator:計算処理のプロセッサ選択->"cpu", "gpu", "tpu", "ipu", "auto"
devides:プロセッサの数(普通の人のPCなら1)
strategy:計算処理の最適処理選択("ddp":GPU並列化設定)
num_nodes{defalut:1}:GPUノードの数
[IN]
net = Net()
trainer = pl.Trainer(max_epochs=20,
accelerator='gpu', #GPUを使用
devices=1, #GPUの数
)
trainer.fit(net, train_dataloader)
[OUT]
-Strategyの設定は難しそうですが高速化が必要な場合は検討する価値はあると思います。
4-2-3.コールバック:callbacks
コールバックとは「ある関数などを呼び出す際に別の関数などを途中で実行するよう指定する手法のこと」であり、Pytorch lightningでは"Callback"を使用します。
例として学習前後で開始と終了を教える処理を追加しました。
[IN]
from lightning.pytorch.callbacks import Callback
class PrintCallback(Callback):
def on_train_start(self, trainer, pl_module):
print("Training is started!")
def on_train_end(self, trainer, pl_module):
print("Training is done.")
net = Net()
trainer = pl.Trainer(max_epochs=20,
callbacks=[PrintCallback()]
)
trainer.fit(net, train_dataloader)
[OUT]
Training is started!
Epoch 19: 100%
23/23 [00:00<00:00, 338.23it/s, v_num=43]
`Trainer.fit` stopped: `max_epochs=20` reached.
Training is done.4-2-4.チェックポイント作成:enable_checkpointing
Pytorch lightningではtrainer.fit()後に”lightning_logs”フォルダ内にデータが保存されます。この時"checkpoints"を作成するかどうかを設定できます(Default:True)。
[IN]
net = Net()
trainer = pl.Trainer(max_epochs=20,
enable_checkpointing=True)
trainer.fit(net, train_dataloader)
[OUT]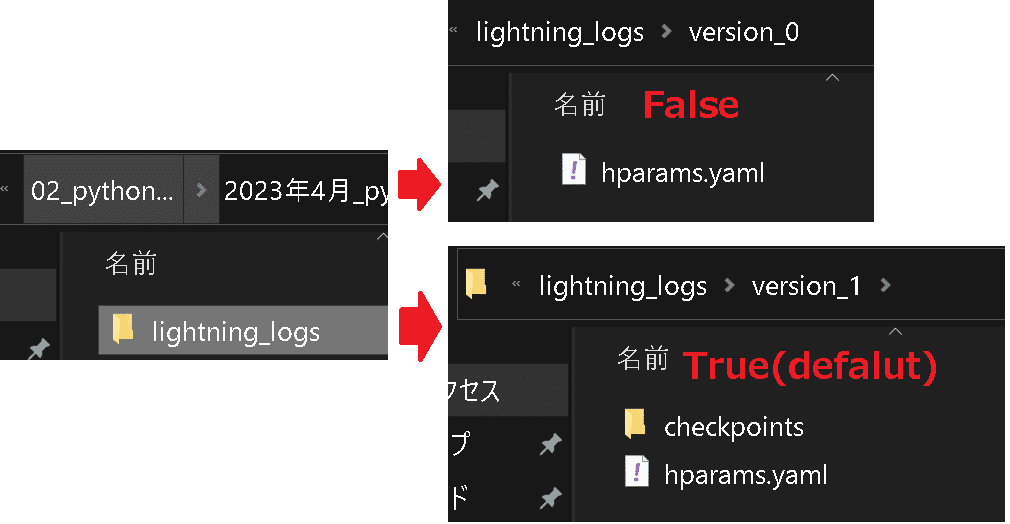
4-2-4.プログレスバー表示:enable_progress_bar
プログレスバー表示を"enable_progress_bar{defalut:True}"で設定可能です。なおプログレスバーをカスタムすることも可能です(以下記事参照)。
[IN]
net = Net()
trainer = pl.Trainer(max_epochs=20,
enable_progress_bar=True)
trainer.fit(net, train_dataloader)
[OUT]
4-3.学習:trainer.fit()
pl.Trainer()で学習条件を設定したらfitメソッドで実際に学習を行います。
model (LightningModule):学習させるモデル
train_dataloaders (Union[Any, LightningDataModule, None]) :学習用データセット(イテラブルなデータ:今回はデータローダーを使用)
datamodule (Optional[LightningDataModule]) : LightningDataModule
[API]
Trainer.fit(model, train_dataloaders=None,
val_dataloaders=None, datamodule=None, ckpt_path=None)学習させるだけでいいならモデルと学習用データを渡すだけです。
[IN]
net = Net()
trainer = pl.Trainer(max_epochs=20,
enable_progress_bar=True)
trainer.fit(net, train_dataloader)
[OUT]
`Trainer.fit` stopped: `max_epochs=20` reached.4-3-1.学習時の注意点:分類問題
分類問題においてラベルには一般的に整数値を割り当てます。ラベリングの値が0開始出ない場合、下記のようなエラーが発生する可能性があります。もしエラーが発生してどうしようもない場合はラベル値を確認のうえ、変更するとエラーが解消される可能性があります。
【Error】
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.参考例として下記では元ラベル"1~7"を"0~6"に修正しました。元に戻す処理はコメントアウトしておりますのでご参考までに。
[IN] #ラベルを1 ->0, 2->1, 3->2, 4->3, 5->4, 6->5, 7->6に変換
df_trainpl['Type'] = df_trainpl['Type'].replace({1:0, 2:1, 3:2, 4:3, 5:4, 6:5, 7:6}) #ラベルを元に戻す
# df_trainpl['Type'] = df_trainpl['Type'].replace({0:1, 1:2, 2:3, 3:4, 4:5, 5:6, 6:7})
[OUT]
4-4.検証:trainer.validate()
モデルを検証する場合は"trainer.validate()"を使用します。
model (Optional[LightningModule]):検証させるモデル
dataloaders (Union[Any, LightningDataModule, None]):検証用データセット(イテラブルなデータ:今回はデータローダーを使用) :class:`~lightning.pytorch.core.hooks.DataHooks.val_dataloader hook.
"best", "last", "hpc" か検証したいチェックポイントのパス
もしNoneかつモデルのインスタンスが渡されてたなら今の重みを使用
verbose (bool):Trueなら検証結果を出力
datamodule (Optional[LightningDataModule]): LightningDataModule.
[API]
Trainer.validate(model=None, dataloaders=None,
ckpt_path=None, verbose=True, datamodule=None)4-4.テスト:trainer.test()
モデルをテストする場合は"trainer.validate()"を使用します。
[API]
Trainer.test(model=None, dataloaders=None,
ckpt_path=None, verbose=True, datamodule=None)4-5.推論:trainer.predict()
trainerを用いて推論実施可能であり出力はリスト形式で「Union[List[Any], List[List[Any]], None]」となります。
[API]
Trainer.predict(model=None, dataloaders=None,
datamodule=None, return_predictions=None, ckpt_path=None)基本的にはLightningModule内で定義したforwardメソッドの呼び出しですが、得られる出力の形が異なる点に注意が必要です。
[IN]
y1 = net(X_test)
y2 = trainer.predict(net, X_test)
print(f'型 net(X_test):{type(y1)}, trainer.predict(net, X_test):{type(y2)}')
print(f'形状・サイズ net(X_test):{y1.shape}, trainer.predict(net, X_test):{len(y2)}')[OUT]
型 net(X_test):<class 'torch.Tensor'>, trainer.predict(net, X_test):<class 'list'>
形状・サイズ net(X_test):torch.Size([100, 1]), trainer.predict(net, X_test):1005.便利な追加機能
今までは基本的な機能を紹介しました。本章では機械学習をより効率的に実行できる機能を紹介します。
5-1.Early Stopping
PytorchではEarly Stoppingは別モジュール使用(下記記事)しましたが、Pytorch lightningでは機能が追加されています。
[API]
lightning.pytorch.callbacks.EarlyStopping(monitor, min_delta=0.0, patience=3,
verbose=False, mode='min', strict=True,
check_finite=True, stopping_threshold=None,
divergence_threshold=None,
check_on_train_epoch_end=None,
log_rank_zero_only=False)pl.Trainer()にEarlyStoppingを組み込むことで簡単に実装できます。
[IN]
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
class Net(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1) #y = ax + b
def training_step(self, batch, batch_idx):
x, y = batch #データセット->説明変数と目的変数を抽出
y_pred = self.fc(x) #推論
loss = F.mse_loss(y_pred, y) #損失関数
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
def forward(self, x):
return self.fc(x)
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self.fc(x)
loss = F.mse_loss(y_pred, y)
self.log('val_loss', loss)
return loss
net = Net()
trainer = pl.Trainer(max_epochs=20,
callbacks=[EarlyStopping(monitor='val_loss', patience=3, verbose=True)])
trainer.fit(net, train_dataloader, val_dataloader)[OUT]
23/23 [00:00<00:00, 239.59it/s, v_num=16]
Metric val_loss improved. New best score: 0.945
Metric val_loss improved by 0.032 >= min_delta = 0.0. New best score: 0.913
Metric val_loss improved by 0.027 >= min_delta = 0.0. New best score: 0.886
Metric val_loss improved by 0.018 >= min_delta = 0.0. New best score: 0.868
Metric val_loss improved by 0.047 >= min_delta = 0.0. New best score: 0.821
Metric val_loss improved by 0.012 >= min_delta = 0.0. New best score: 0.809
Metric val_loss improved by 0.025 >= min_delta = 0.0. New best score: 0.784
Metric val_loss improved by 0.015 >= min_delta = 0.0. New best score: 0.769
Metric val_loss improved by 0.003 >= min_delta = 0.0. New best score: 0.766
Metric val_loss improved by 0.002 >= min_delta = 0.0. New best score: 0.764
Monitored metric val_loss did not improve in the last 3 records. Best score: 0.764. Signaling Trainer to stop.5-2.モデルの保存:ModelCheckpoint
定期的にモデルを保存する場合は"ModelCheckpoint"を使用します。こちらは別記事参照のこと。
[API]
lightning.pytorch.callbacks.ModelCheckpoint(dirpath=None, filename=None, monitor=None,
verbose=False, save_last=None, save_top_k=1,
save_weights_only=False, mode='min',
auto_insert_metric_name=True,
every_n_train_steps=None,
train_time_interval=None, every_n_epochs=None,
save_on_train_epoch_end=None)5-3.記録(log)の確認
ログの記録(追って)
[API]
LightningModule.log(name, value, prog_bar=False, logger=None, on_step=None,
on_epoch=None, reduce_fx='mean', enable_graph=False,
sync_dist=False, sync_dist_group=None, add_dataloader_idx=True,
batch_size=None, metric_attribute=None, rank_zero_only=False)6.可視化
6-1.Webアプリ:tensorboard
Tensorboardで可視化(追って)
[API]
lightning.pytorch.loggers.tensorboard.TensorBoardLogger(save_dir, name='lightning_logs',
version=None, log_graph=False,
default_hp_metric=True,
prefix='',
sub_dir=None, **kwargs)7.モジュール化
モデルをモジュール化することでCLIでの使用が可能です(コマンドプロンプトで使用)。私はJupyterでしか使用しないため紹介のみとなります。

8.クラウドとの連携
クラウドを利用したモデル開発も可能です。
クラウド上のGPU・TPUを使用(TPUsの使い方も紹介)
クラウド上でモデルを学習
クラウド上にCheckpointsを作成
私は使用しないため紹介のみとなります。

参考資料
Python
Pytorch Lightning
あとがき
追って適宜追加。
ただ、記載していると学習コストが高いので「これならtensorflow/kerasでよくね???」ってなりそうです。
この記事が気に入ったらサポートをしてみませんか?