
OCRを試す - Tesseract OCR -

1.前書き
文字をコピーできないファイルをデジタル化するためにOCRを活用する。6年前調べた限りでは、世界中みても識字率100%を達成したところはなかった。当時、あのAdobe Acrobat(有料版)でさえ、識字率は最悪で使いものにならなかった。
最近は、AI-OCRなどと騒がれているけど、前述の先進企業が達成できなかった課題を他企業が達成出来ているとは思っていない。特にAIという言葉が先行し、有用性が高く価値あるものと皆が思い込んでいるかもしれない。しかし実態は、自分にとってまったく使い物にならないゴミ同然の代物なので、実用に耐えられるようになるまでには、まだまだ課題はあると思っている。
ただ、100%であれば嬉しいが、全て100%でなくても自分が使う分だけでも高精度を誇る、使用できればいい形に落とし込みたい。
今回はオープンソースである「Tesseract OCR」を試すことにする。
2.Tesseract installer for Windows
Windowsユーザーはバイナリが用意されているのでインストールが簡単である。詳細は「5.参考」のリンクを読んでみてほしい。
3.試した結果
とりあえず、 Linus Torvaldsの名言(画像データ)をOCRしてみる。

結果はこのように。元々、Windowsのフォントを使用した画像なので判別しやすかったかもしれない。
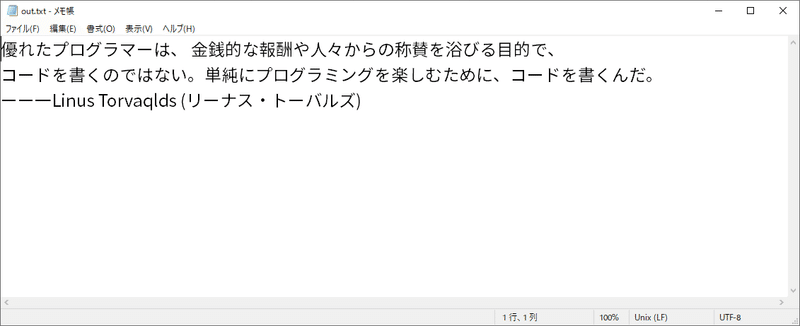
※他にも、時間があるときに印刷物や手書きのデータがどこまで対応できるか確かめたいと思う。
4.展望
今回はテキスト編集(文字をコピー)できないファイルをデジタル化する目的でOCRを使用した。今後はデジタル化した文字を整理して、データベース化することも検討できるかと思う。プログラミングを活用すれば、任意の文字を取り出すといった行為もできるかと思う。
5.参考
github
ユーザーマニュアル
Tesseract OCRのインストールに関して
おわり!