
開発コラム:カオスエンジニアリングでシステムの信頼性を高める!

先月アップした開発コラムは読んでいただけたでしょうか?いつもと違った内容でしたが、たくさんの方に見ていただけたようで大変うれしく思います。
まだ読んでないよ…という方はぜひこちらもチェックしてくださいね!
医療DXの開発を担当している、クラウドサービス推進部の宮島です。
コラム2回目の今回はカオスエンジニアリングというテスト手法について、考え方や関連サービスの利用方法をご紹介します。
どうぞよろしくお願い致します!
医療DXの製品に関してはこちらをご覧ください↓
この記事は、2022年7月時点の情報にて制作しております。
はじめに
皆さんは、カオスエンジニアリングという言葉を聞いたことがあるでしょうか?
カオスエンジニアリングとは、本番稼働中のシステムに対して疑似的な障害を発生させ、システムの弱点を発見し対策をしていくことで、システムの可用性や耐障害性を高めていくテスト手法です。
この手法は、Netflix社がAWS上の本番環境で実施しているということで注目を浴び、世間に広まりました。また、AWSのWell-Architected Frameworkというクラウド設計におけるベストプラクティスの中でも言及されており、システムの信頼性を高めていく上で有用な手法となります。
今回は、カオスエンジニアリングの考え方と、AWSのカオスエンジニアリングサービスであるAWS Fault Injection Simulatorについてご紹介します。
カオスエンジニアリングの考え方
カオスエンジニアリングは、Netflix社のエンジニアが主体となって作成した「Principles of Chaos Engineering(カオスエンジニアリングの原則)」が主な考え方となります。
この原則によると、カオスエンジニアリングとは、単なる耐障害テストではなく、以下のプロセスで進めることが提唱されています。
① システムの定常状態を定義する
② システムの定常状態がテストを通じても継続すると仮説を立てる
③ ハードウェア、ソフトウェア、ネットワーク障害等、現実世界で起こりうるイベントを発生させ、実験する
④ ③の実施により、②の仮説を反証する
上記プロセス④で、仮説の反証が困難になるほど(=定常状態を乱すことが困難になるほど)、システムの信頼性が高まるということになります。対して、反証が容易であり弱点が発見された場合、速やかに改善の目標を立てる必要があります。
また、詳細な原則として、以下の考え方があります。上記プロセスは、詳細な原則に沿って進める必要があります。
・ 定常状態における振る舞いの仮設を立てる
測定可能なパラメータ(システム全体のスループット、エラーレート、レイテンシー)に注目し、定常状態を定義する必要がある。あくまでシステムがどのように動作するのかを検証するのではなく、システムが動作することを検証する。
・ 実世界の事象を変化させ実験する
実験は現実世界で起こりうるイベントを発生させる必要がある。イベントは、障害だけでなく、トラフィックの急増やスケーリングイベントのような非障害イベントも考慮する。イベントの優先度は、影響度と推定頻度のいずれかにより決定すること。
・ 本番環境で実験を実施する
システムは環境やトラフィックパターンによって異なる動作をする。システムの信頼性を高めるため、実験は本番環境のトラフィック上で実施することが推奨される。
・実験を自動化し継続的に実行する
手動での実験は、運用負荷が高く継続が難しい。実験は自動化し、継続的に実施する必要がある。
・影響範囲を局在化する
本番環境での実験は、想定以上のトラブルが発生する可能性がある。顧客に被害を与えないよう、影響を最小限に抑えて封じる必要がある。
代表的なサービス、ツール
カオスエンジニアリングの実験を行うための代表的なサービス、ツールを紹介します。
Netflix社 「Chaos Monkey」 「Chaos Gorilla」 「Chaos Kong」
Gremlin社 「Gremlin」
Amazon社 「AWS Fault Injection Simulator」
Microsoft社 「Azure Chaos Studio(preview)」
上記の他にも様々なサービスやツールが公開されてますので、自分の環境にあったサービスやツールを選択することができます。
AWS Fault Injection Simulatorを使ったAWS環境への実験
実際にAWSのサービスであるAWS Fault Injection Simulatorを使用して、AWS環境への実験を行います。
今回は、以下の構成のAWS環境上で、片系のAZ(データセンター群)に疑似障害を発生させてみます。

まずは、AWSマネジメントコンソールからAWS Fault Injection Simulatorのサービスページへアクセスします(ページ上はAWS FISというサービス名となります)。

次に、実験テンプレートを作成します。
実験テンプレートでは、アクションの内容、ターゲットの設定を行います。
今回は、片系のAZ(ap-northeast-1c)にあるEC2インスタンスを停止するアクション設定を行います。

また、実験テンプレートの中には、停止条件という設定項目があります。
この設定は、実験による影響が想定外の範囲となり、顧客へ被害を与えてしまう事態(システムが定常状態を維持できなくなるような事態)が発生したときに、自動的に実験を停止するための設定となります。
停止条件にはCloudWatchアラームを設定することができ、システム全体のAPIエラー率やレイテンシーのような、システムの定常状態を示すものを指定します。

実験テンプレートの作成完了後、実験を開始します。
実験を開始すると、実験の状態が確認できるページへ遷移します。
実験が完了すると、以下の画像のように状態がCompletedとなります。
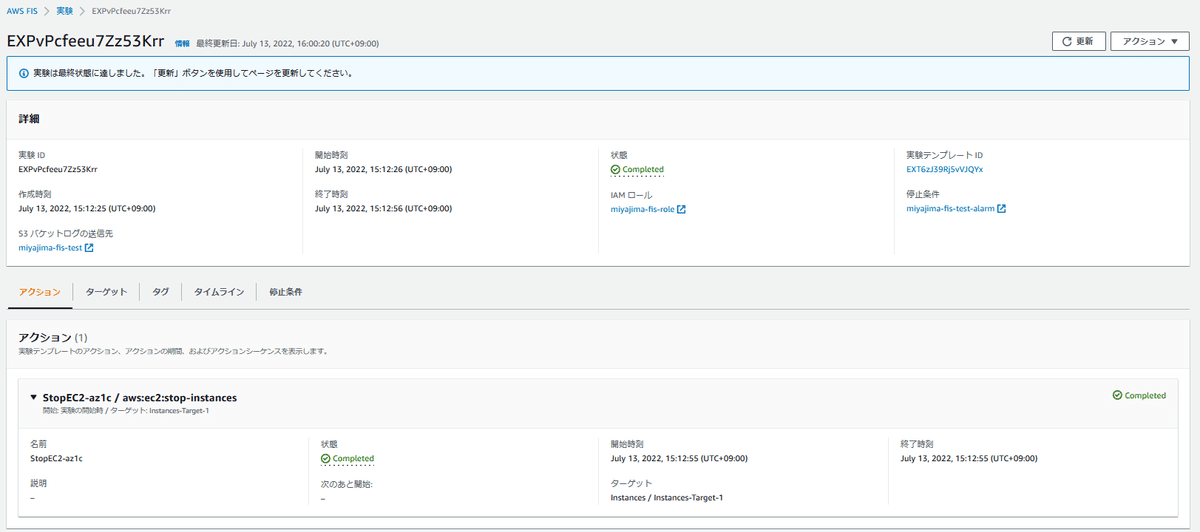
以上で、AWS Fault Injection Simulatorを使用し、片系のAZ疑似障害を発生させる実験を行うことができました。
カオスエンジニアリングのプロセスとしては、実験テンプレートで設定した停止条件によって実験が停止すれば、システムの定常状態がテストを通じても継続するという仮説が反証されたことになるので、システムの弱点を調査し、速やかに改善の目標を立てる必要が出てきます。
対して、停止条件によって実験が停止せず、Completedとなれば、システムの信頼性を高めることができているといえます。
おわりに
今回はカオスエンジニアリングというテスト手法についてご紹介しました。
カオスエンジニアリングは、システムの信頼性を向上させる上で有用ですが、実際に顧客へ影響を及ぼす可能性があるため、慎重にプロセスを検討する必要があります。
まずは、本番環境で実験を行う前に検証環境で実施する等、実験の検証も行うのが良いかと思います。
中々ハードルの高い内容ですが、皆さんが運用中のシステムや、これから開発するシステムにおいて、カオスエンジニアリングの実施を検討してみてはいかがでしょうか。
キヤノンITソリューションズでは高い技術力を元にDXにお役にたてるソリューションを多数ご用意しております。
お困りのことがありましたら、お気軽にご相談ください。
※本記事に記載されている会社名、製品名は、それぞれの会社の商標または登録商標です。
★―☆。.:*:・゜――――――――――――――――――――――――
キヤノンITソリューションズ 公式Webサイト
医療DX関連ページ