【営業 データ分析】 448商談130受注/実際の解析結果と方法論。セールスはインサイトが投影された”熱い”データを使おう!

ども、スタートアップで働くなかしま(@nakashimayugo)です。
先日、同業界の友人からこんな相談を受けました。
「インサイドセールスで案件化率の高い商談数を増やしたい。その為にデータを活用したい。」
その際に『(インサイド)セールスのデータの使い方』に色々と思う事があり、頭の整理もしたいなと思ったので、この記事で以下を書こうと思います。
1. セールスはデータを通じて何をしているのか?
2. 448商談130受注を使って具体Howと結果で説明。
3. インサイトが投影された”熱い”データを設計する!
少し長めの記事ですが、実際のデータを隠さずまるっと紹介して具体性を高めたつもりですので「あ、これ明日からやってみよう!」と少しでも参考になれば嬉しいです。
(属性比率や月の商談件数なんかも全部分かっちゃいますが、まあ全然オーケー!)
ちなみに、今回題材にしている商品は市場の追い風と競合がいない状況下でめちゃくちゃ好調で、月によっては初商談から受注までのCVRが50%を超える月も度々あります。
しかし裏を返すと半分は失注案件です。”失注”というと主語が自分ですが「顧客に無駄な時間を使わせてしまった」ということです。
もちろんCVR低×量的戦略も状況によっては必要ですが、CVR改善をある程度までやりきらない事は顧客に失礼です。
データを使うと何が良いかというと、一歩ずつ改善を積み重ねられることでセールス業務をフローからストック型に変えてくれることです。そして結果的に必ずCVRが向上していくので、顧客への還元に繋がります。
1. セールスはデータを通じて何をしているのか?
僕が考えるセールスのゴールは”人を介在させない事”なのですが、その為の業務改善は”モデリング”という考え方が軸になっています。”モデリング”とは受注有無と影響を与える要因を方程式の様に取り扱う事を指します。以下のようなイメージです。
受注確率 = (係数 × アクションAができたかどうか) + (係数 × 顧客属性がBか否か) + (係数 × ヒアリングCが聞けたかどうか) + ・・・
例えば「この案件は受注できそうだな」と思った時に頭の中をイメージしてみてください。”なぜその判断になったのか”を言語化してみます。
『相性のよい企業だった』
『先方担当者の反応が良かった』
『商品説明が上手くできた』
普段の頭の中でも同じ事をしていて、このような抽象的な評価軸があり、それらをトータルして「受注できそうだな」と判断しているのではと思います。
これを細分化、言語化、定量化し、複数データから統計的に判断すれば、頭の中よりは単純化されるものの具体化された方程式(=モデリング)が出来上がります。
この考えでいくと「ステージ」「スコアリング」などのプロセス分解や数値でのメタ表現は、受注と因果関係にある変数を定義するという意味で同じことをやっています。また「BANT」「4つの『不』」「SPIN」などの有名なフレームも上記の一般解と考えることもできます。
後半で紹介しますが実際の商品とデータを例に取るとこの様になります。(コードがあったという理由でロジスティック回帰を例にします)
受注するか確率Y = 1 / {1 + exp(-(-3 + 0.6 ×「事業モデルがToCなら:1」+ 1.3 ×「CTO同席なら:1」 + ・・・)))}
”諸々を棚上げして”この方程式で受注を説明してみるとこうなります。『「事業形態」と「商談出席者」の2要素だけで、8割以上の案件の受注有無を説明できる』という内容です。

とは言えこれを完璧なモデルにしてCVR100%にするのはSF的な話なので、考え方は踏襲しつつ実際には以下のような断片的な判断・使い方になります。
※業務では階層ベイズで、営業メンバーをランダム効果とした一般化線形モデルを作ってます。ここを綺麗にして、「顧客情報」「営業担当情報」「商品情報」「営業プロセス情報」に大分類しつつ、「営業担当情報」「営業プロセス情報」の影響度を下げていく(抽象化した要素をLPやコンテンツで賄う)事が大事だと思っています。ここらへん好きな方は是非お話したいです。
・アクションやセグメントの仮説検証(関係あるか否かの判断)
・変数同士の影響力の大きさの比較(打ち手の優先度などに使う)
・変数をモニタリング(監視)して変化を追う
抽象的な話になってしまったので実際のデータやHowを見ていきます。
2. 448商談130受注を使って具体Howと結果で説明
- 題材にする商品
今回題材にするのは「LAPRAS SCOUT」というエンジニア採用サービスです。特徴として、会員登録型の転職サービスではなくGitHubやTwitterなどの大量のオープンデータからエンジニアさんの情報を解析。採用したいエンジニアにスカウトでコミュニケーションが取れるサービスです。
採用サービスですので採用担当者が顧客です。
今回使ったデータではリードタイムを考慮していないのでCVR29%でしたが実際の商談⇒受注のCVRは30%を超えており、商談回数はほとんどが1回のみ、リードタイムも商談後1ヶ月以内が約60%(2ヶ月以内でも75%)です。おそらく採用系サービス且つ初期費用が3桁の商品としては、非常に優秀な数値かと思います。
ここから実際にデータをどの様に使っているかを紹介していきます。ここで紹介するものは定期的にモニタリングしている内容です。
- 実際にどんな設定をしてどう見ているか
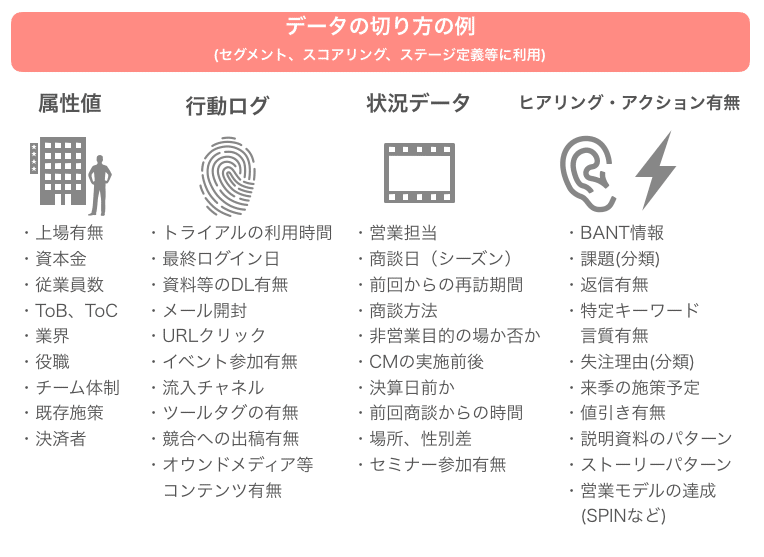
【 設定している変数 】
・スカウトサービスの実施有無 (過去・現在含め3分類)
・顧客の事業モデル (4分類)
・商談時に同席された方の職種 (4分類)
・リードの流入経路 (5分類)
・商談形式 (2分類)
【 数値の見方・集計方法 】
・クロス集計
・要素比率の時系列推移
・多変量解析
(現場あるあるで、営業データはunknownが多くなります)
まずは、上記で設定した各変数毎にクロス集計で割合を見てみます。
仮説検証が目的であればほぼクロス集計で必要な情報は得られます。実際の結果がこちら。
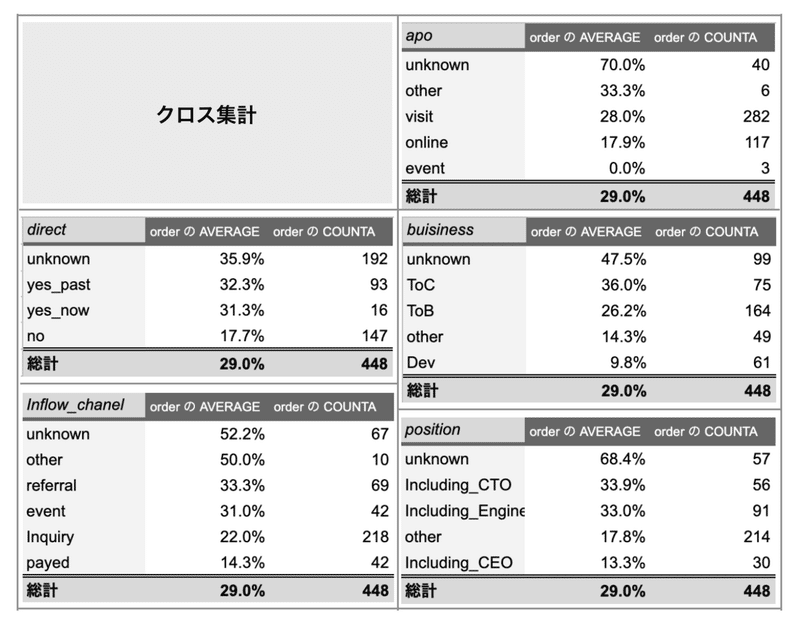
こんな事が言えそうです。
・スカウト(ダイレクトリクルーティング)施策の実施有無は「あり」が「なし」に比べ15%程度高い
・顧客の事業モデルは「C向けサービス」が「開発系」に比べ25%程高い
・商談時にエンジニア職の方の同席有無で15%程度差が出る(社長よりも一般エンジニア同席の方が受注率が2倍高くなる)
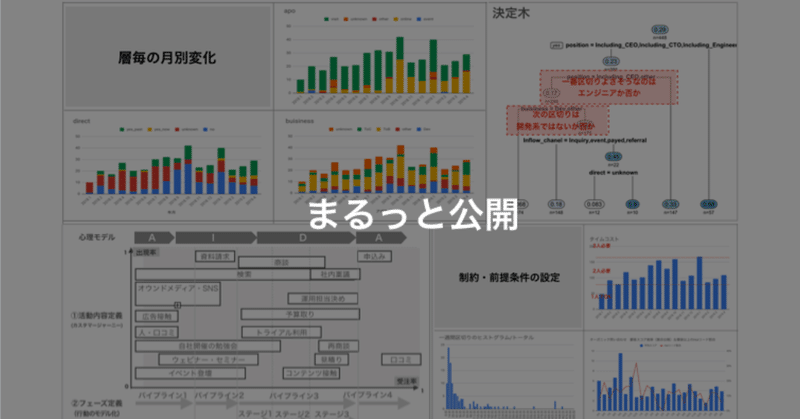
次に時系列での変化を見ていきます。これは定期的にモニタリングしていてマーケに要望を出したり達成有無の要因を時間軸で考察することができます。
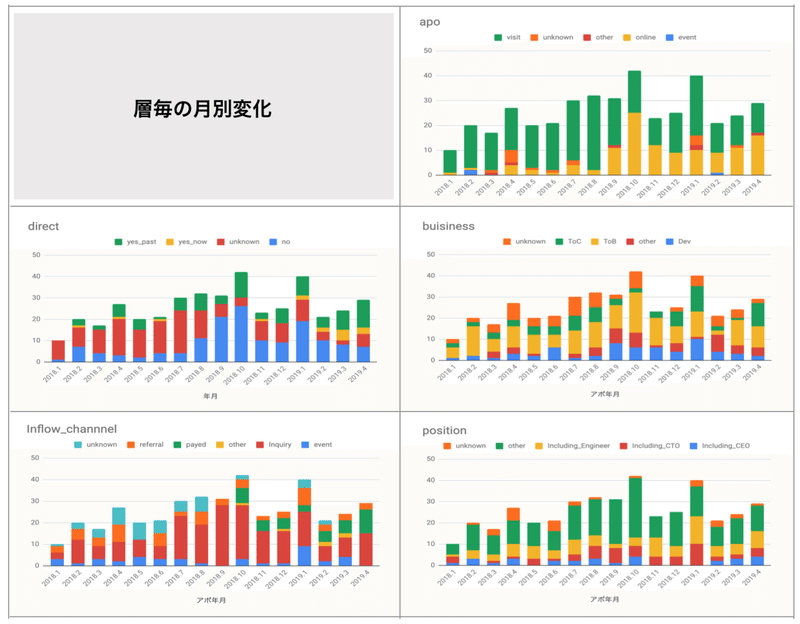
時系列で定期的にモニタリングしていると売上が下がった時に対応が早くなります。
また振り返りを行う際にも非常に有効です。その変化が”コントロールした結果”なのか”意図せずそうなってしまったのか”は振り返り時に混ざることがないよう注意したいです。
・2018年9月頃からオンライン商談の比率を増加させた
・問い合わせ数はある程度一定化してきた
・以前はリファラル案件の依存度が高く最近減ってきている
ここまででデータの”解析方法”という意味では十分だと思っています。
ただ営業データの特性として非常に偏りが強く集計を比較しただけでは少し心配です。(もちろんそれを加味し変数を設定すべきですが)
また変数同士の影響力の大きさを、できるだけ他の変数の偏りを除いて考えたいので、そういう場合は以下のような多変量解析の手法を試しています。(もちろんデータ数が十分であれば、BIツールやEXCELピポット機能もあり)
受注か失注か(二値分類)なので、詳しくは書きませんが以下のような手法を使います。
- 判別分析
- 決定木
- ナイーブベイズ
もっと”それっぽい”手法はたくさんありますが、セールスデータではあまり難しい手法は不要かと思います。
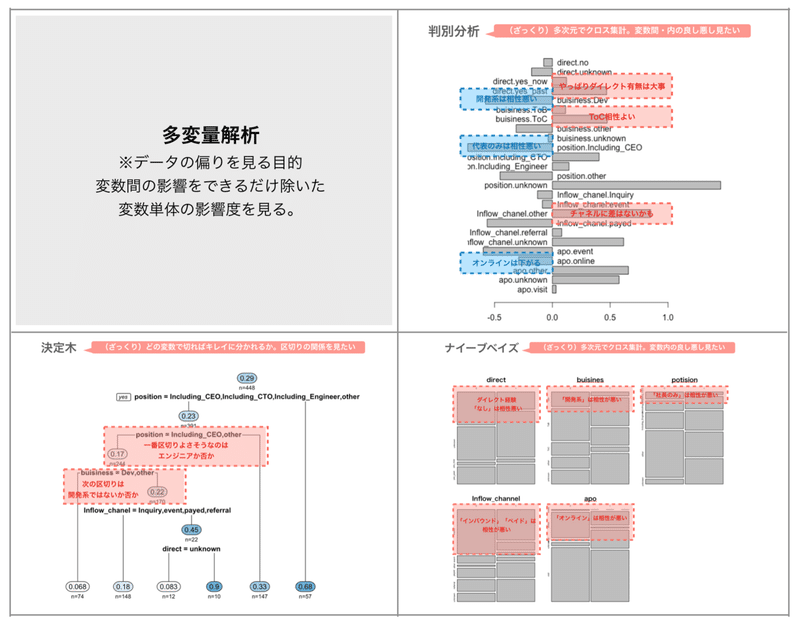
ここから、クロス集計の結果と合わせて以下のような解釈をしました。
・実はイベントやリファラルの流入経路自体はあまり関係ないかもしれない
・受注有無を決めるのはエンジニア関連職の同席有無と顧客の事業モデルで同じぐらい影響度が強そうだ
ここから読み取れた考察に対して、打ち手や別データの仮説検証・後述するカスタマージャーニーの修正を行います。この記事ではそちらの具体内容は書きませんが、設計の考え方をこの後書いていきます。
※今回は受注”数”ですが、”取引単価”でも、”商談化数”でも良いわけです。その場合は集計単位を変えこの形に持っていきます。
[ ■■(最大化・最小化させたい数値) / ●●(区切りたい単位、人・案件・時間)]
- (備考)制約・前提条件は設定しているか?
本題からそれるのですが、制約・前提条件について少しだけ書きます。このような条件設定をしていないとチームで共通認識を持てなかったりするので、もし設定していない方はオススメです!
・マーケットサイズ / ターゲット出現率
⇒全体のボリューム算定と共に、顧客スコアリングを行い定点観測することで相性の良い顧客の出現率が下がってきていないかを確認します。ここでいうマーケットサイズとは今の商談スタイルでCVRが一定という仮設の耐久性みたいなものです。この設定がないとターゲットがずれている場合に感知できず営業が頑張っていないという根性論になりがちなので是非設定しましょう。
・タイムコスト(一人当たりの商談に使える時間)
⇒商談時間に契約やその他対応時間を加えた1案件に支払う時間コストです。僕の場合はオンライン商談を3h、訪問商談を5hと設定し、一人100h/月に使えるという設定をします。この設定がないと必要な受注数から単純に逆算しただけの商談目標が設定され、現実味のない目標を意味もなく追いかける事になります。人員計画やオンライン・訪問割合の調整に使います。
・リードタイム
⇒これは解説不要かと思いますが、リードタイムで逆算をしないと常に活動と結果がビハインドしてしまいます。各営業活動が”いつの為”のものなのかを定義し、それに向けて計画を逆算します。ヒストグラムを使うと全体の傾向が見えます。リードタイムを時系列で棒グラフ化にしてみると非常に示唆に富んだ結果が出ることがあるのでオススメです。
▼実際の制約・前提条件のグラフ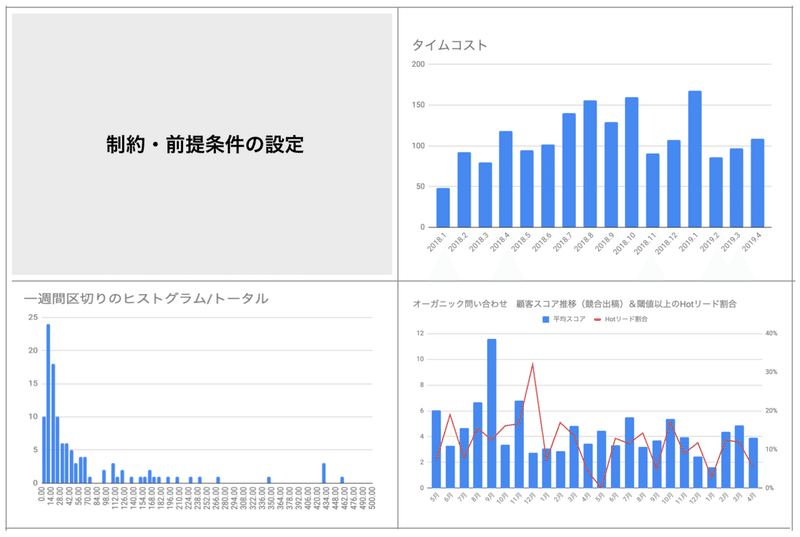
3. インサイトが投影された”熱い”データを設計する!
ここまででデータの”使い方”について書きましたが、一番焦点を当ててほしいのは『キーになる変数には、顧客のインサイトやプロダクトの課題が濃く詰まっている』ということです。
データの取扱い云々という内容を先に出しましたが『何のデータを設定するか』の思考プロセスにこそ最も価値があると思っていて(多分に自戒を込めて)ここからはその考え方・設計方法について書こうと思います。
※もちろん変数だけでなく選択肢の設定にも同じ事が言えます。例えば「従業員人数」という変数を使うにしても<1~100><101〜1000><1001~>という3分類にするのか、<1~30><31~>という2分類にするのかという設計の違いにこそ愛と手間とインサイトを詰め込むべきです。
ちなみにFORCASやSalesforceというサービスは(インフラ化しているのでご存知の通りかと思いますが)めちゃくちゃイケているサービスで、外部のデータベースとして接続したり自動分析機能を併せ持っているので、これらを利用するのは非常に良いことだと思っています。ただし上記の考えを放棄して”そこに落ちていたデータ”を使った自動分析は本末転倒になるので、プロダクト課題や顧客インサイトをしっかり落とし込んだ上で使うのが良いと考えています。
少しお気持ちになり恐縮ですが、ここから僕なりの設計フローを紹介していきます。(当たり前の事をそれっぽく書いているだけですが笑)
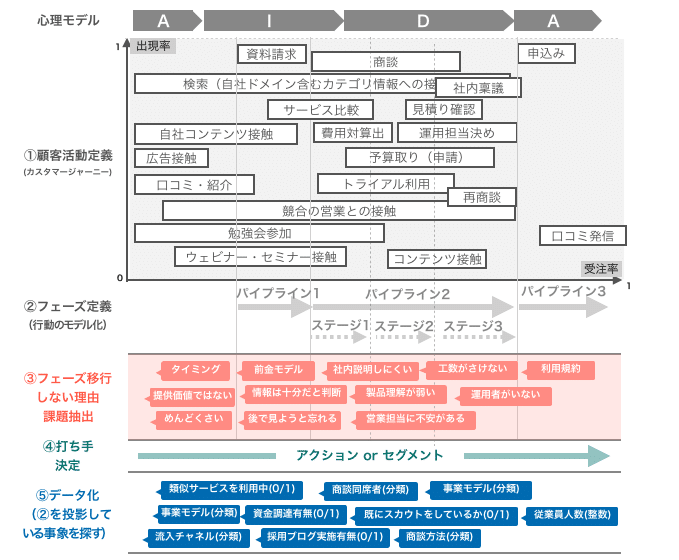
①カスタマージャーニーを作る(顧客活動を出現率とともにマップ化)
②顧客インサイトとして"決定障壁・アクション障壁"がある所にラインを引く(ステージや読みの区切り)
③そのラインを超えない(ステージ移行しない)理由を考える
④打ち手の検討と実施(アクションかセグメント)
⑤データ化されていない場合、課題感やインサイトが投影された定量化できる指標を考える
具体的に図に落とすとこんな感じ。実際には図に綺麗にまとめるよりホワイトボードや紙にかき散らかす方が好きです。
▼設計フロー
▼あれも違う、これも違うとウンウン言いながらこういうのを良く書きます
ここで、セールスの人はインサイトをメタ的に把握するのは得意だと思うのですが(いい意味で人間理解力が高い)、データ化については考えるのが苦手な人が多いと思っています。これらを混合して使ってしまうと最終的にふわっとして終わることが多いので、僕自身の頭の整理も兼ねてこんなリストを作ってみました。参考になれば嬉しいです。
この事象化は結構面白くて、例えば血糖値が判断に影響するという心理効果を信じるなら、食後の時間帯かどうかを変数に設定する事ができるかもしれませんし、ウェアラブルの心拍数でも良ければ、商談を文字起こしし特徴語を言ったかどうかを設定することもできます。(いずれもうまくいきませんでしたが笑)
逆に示唆が得られて面白かったものとしては、Wantedlyさんはインフラ的なサービスなので「その"メンバー"ページにひも付くエンジニアの人数」などがあります。多いと受注との相関性があったので、うちと既存顧客に多い「エンジニアを巻き込んで採用活動を行っている企業」という属性情報がメンバーページのひも付きの背景情報として投影されていた(という仮説)ということです。
ここで決めた変数を、上記2.の様にモニタリングするもよし打ち手を打つもよし、という流れになります。
今回打ち手は紹介しませんでしたが、一例として少し面白いものを紹介すると問い合わせが入ったら類似サイトに掲載されているかを自動で教えてくれるBotを間に挟み、顧客に伝える情報を出し訳したりしています。(他に企業情報や資金調達有無など)

またその情報をスコアリングの一部として利用し、ターゲットにアプローチできているのか、ターゲットに商品が理解されているのかを判断したりというのもモニタリング方法としてあります。
(打ち手に付いてももっとレパートリーを増やさないとと、書いていてやる気が出てきました)
まとめ
・モデリングの考え方をベースに断片的でもデータを使うことで、カイゼンを積み重ねストック型の仕事をする。
・実際のやり方は具体例を交えて紹介しているので参考にしてみてほしい。「うちはこんなやり方しているよ」というのもあれば教えてくださいね。
・データは闇雲に設定しても意味がない。設計プロセスにこそ価値がある。顧客のインサイト・プロダクトの課題を明確にして良い商品を届ける為に”熱い”データを作る。
よければTwitterもフォローお願いします!(@nakashimayugo)
※用語や解析方法はあくまで”僕なり”ですが、間違いや誤解を与えてしまう表現があれば教えていただけると嬉しいです!
いつもありがとうございます!Twitterも良ければフォローお願いします!https://twitter.com/nakashimayugo