

#論文紹介

![LLMニュースまとめ[2024年8月12日~8月18日]](https://assets.st-note.com/production/uploads/images/151831447/rectangle_large_type_2_3b41eeea6fbc3db99218b827126ca3fb.png?width=800)
LLMニュースまとめ[2024年8月12日~8月18日]
2024年8月12日~8月18日のLLM関連のニュースとして有名なもの、個人的に刺さったもの12点を以下にまとめる。
1. The AI Scientist
AIエージェントが、独自の研究実施、研究結果整理、論文執筆を一貫して実施。
2. Grok-2
LMSYS Chatbot ArenaでClaude 3.5 SonnetとGPT-4-Turboを凌駕
3. LongWriter


論文「Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model」の紹介
目次
本記事の概要戦略ゲームにおいてChatGPTに意思決定を行わせるAIを提案する論文「Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model」を紹介する記事となります。
本論文の紹介論文名Self Generated Wargame AI: Double Layer A


【論文紹介】複数トークン予測によるLLMの精度向上と高速化
Meta社の研究チーム(Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve)が発表した論文がXで話題になっていたので、ざっと眺めてみました。理解不足も多々あると思いますので、詳細は原文を参照願います。
複数トークン予測モデルの概要トレーニング:従来のTransformer

LLMの強化学習における新手法:TR-DPOの論文紹介
論文名
Learn Your Reference Model for Real Good Alignment
arXivリンク
https://arxiv.org/pdf/2404.09656.pdf
ひとこと要約
Direct Preference Optimization (DPO)を改良したTrust Region DPO (TR-DPO)を提案。
メモ
背景
従来のアライン
![LLMの学習データの刈り込みに関する論文紹介[Cohere論文紹介No.2]](https://assets.st-note.com/production/uploads/images/137595137/rectangle_large_type_2_f12b2b4ac1234e6b407366efd8e6623f.png?width=800)
LLMの学習データの刈り込みに関する論文紹介[Cohere論文紹介No.2]
論文名
When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale
arXivリンク
https://arxiv.org/pdf/2309.04564.pdf
ひとこと要約
LLMの学習データの質を3つの評価指標で評価し、データを刈り込むことでLLMの性能を上げられることを明らかにした。またシンプ
![LLMの継続学習における論文紹介[Cohere論文紹介No.1]](https://assets.st-note.com/production/uploads/images/137492479/rectangle_large_type_2_8c28d30aec13bade8da4dbb42fe735ed.png?width=800)
LLMの継続学習における論文紹介[Cohere論文紹介No.1]
論文名
Investigating Continual Pretraining in Large Language Models: Insights and Implications
arXivリンク
https://arxiv.org/pdf/2402.17400.pdf
ひとこと要約
LLMの継続学習においてドメインの内容や順序などについて調査。ドメインを類似度順で継続学習した方がド

LLMのアルゴリズム的推論能力向上の論文紹介
論文名
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
arXivリンク
https://arxiv.org/pdf/2404.02575.pdf
ひとこと要約
LLMのアルゴリズム的推論能力を向上させるための新し

言語モデルの記憶のメカニズムについての論文紹介
論文名
Localizing Paragraph Memorization in Language Models
arXivリンク
https://arxiv.org/pdf/2403.19851.pdf
ひとこと要約
言語モデルの記憶のメカニズムについて調査。125Mの言語モデルの記憶には第一層の特定のアテンションヘッド(memorization head)が重要な役割を持っている可能

携帯のGPUでLLMを効率的に実行する論文紹介
論文名
Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
arXivリンク
https://arxiv.org/pdf/2403.20041.pdf
ひとこと要約
モバイル端末のGPUで大規模言語モデル(LLM)を効率的に実行するTransformer-Li

LLaMA-Factoryの論文紹介
論文名
LLAMAFACTORY: Unified Efficient Fine-Tuning of 100+ Language Models
arXivリンク
https://arxiv.org/pdf/2403.13372.pdf
ひとこと要約
簡単かつ効率的にLLMのファインチューニングを行うためのフレームワークであるLLaMA-Factoryの紹介
メモ
LLaMA-Fact

【論文紹介】TDB: トランスフォーマーデバッガを使ったGPTの内部メカニズムの解析例
Transformerベースの言語モデルの内部動作を確認するためのツールを用いて各層の役割について解析する取り組みを行っている以下論文(Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small。うまく訳せませんが、「GPT-2 smallにおける間接目的語識別の解明:(学習から
もっとみる

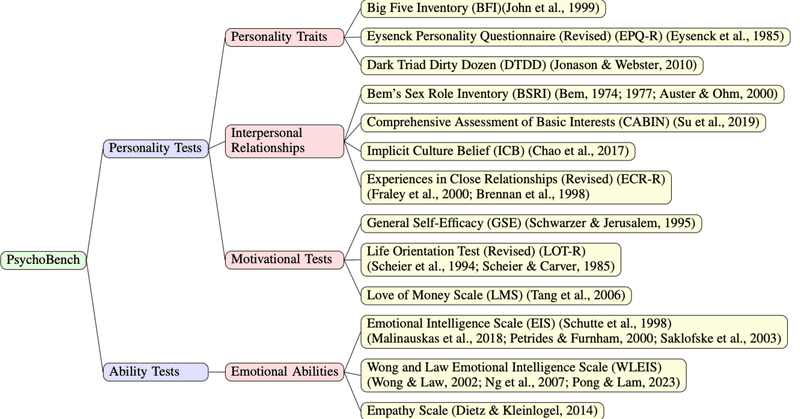
ChatGPT はどんな性格?PsychoBench を使った LLM の心理描写のベンチマーク
こんにちは、PKSHA Technology の AI Solution 事業本部にてシニアアルゴリズムリードを務めている渡邉です。近年、大規模言語モデル(LLM)をはじめとする人工知能技術が革新的な進化を遂げており、当該領域に対する世の中の関心が非常に高まっています。弊社は創業以来、人工知能技術の研究開発・社会実装を通じて様々な知識を蓄積してきました。その知識を皆様に共有し共に成長していく場とし
もっとみる
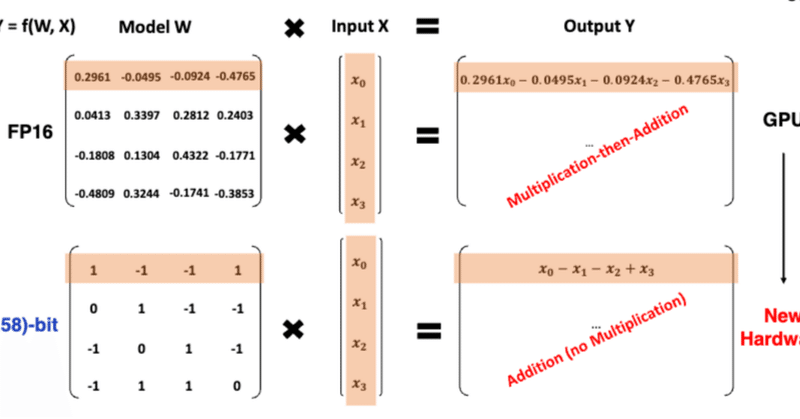
速報:話題の 1ビットLLMとは何か?
2024-02-27にarXiv公開され,昨日(2024-02-28)あたりから日本のAI・LLM界隈でも大きな話題になっている、マイクロソフトの研究チームが発表した 1ビットLLMであるが、これは、かつてB-DCGAN(https://link.springer.com/chapter/10.1007/978-3-030-36708-4_5; arXiv:https://arxiv.org/ab
もっとみる