
文系Python初学者のデータ分析~Jリーグの"走り"と"勝ち"について~

これでもかってぐらいハードルを下げたタイトルですみません。
”エンジニア”という単語に憧れて、昨年6月からPythonを学習しています。
もとは文系の体育会出身なので、プログラミングとは無縁でしたが30歳になるタイミングで一念発起し、コードと向き合い試行錯誤の日々です。
ある日、趣味のJリーグ、サガン鳥栖の試合を観戦しに行きました。
相手は”ブラボー”こと長友選手など代表クラスが多く在籍するFC東京。
その試合、サガン鳥栖は5-0で圧勝しました。
この結果を引き寄せた、ある興味深いデータがあります。チームの『走行距離』です。
サガン鳥栖120キロに対してFC東京は110キロ弱でした。
確かにこの試合を現地で観戦していると鳥栖の方が数的優位を作っているような錯覚がありました。
他のスポーツでも使われる『走る』という超シンプルなプレーを他のチームが真似できないレベルでやっているってエグいですね。
前置きが長くなりました。
この試合を見たときにサッカーもプログラミングも素人の私は実際にデータを抽出し、走行距離がどれほど勝点と相関するのか、エンジニアっぽいことをやってみようと思いました。
今回はそのコードを記載していきますが、うまくいかない過程もあえて綴っていきます。また無駄なコードも含まれているかもしれませんが、どうかご容赦ください。
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import requestsまずは必要なライブラリをインポートします。
データを読み込むのでpandasを使います。
matplotlibはグラフを描画します。
また今回はJリーグのデータサイト(J. League Data Site (j-league.or.jp)からrequestsを使って情報を取得します。
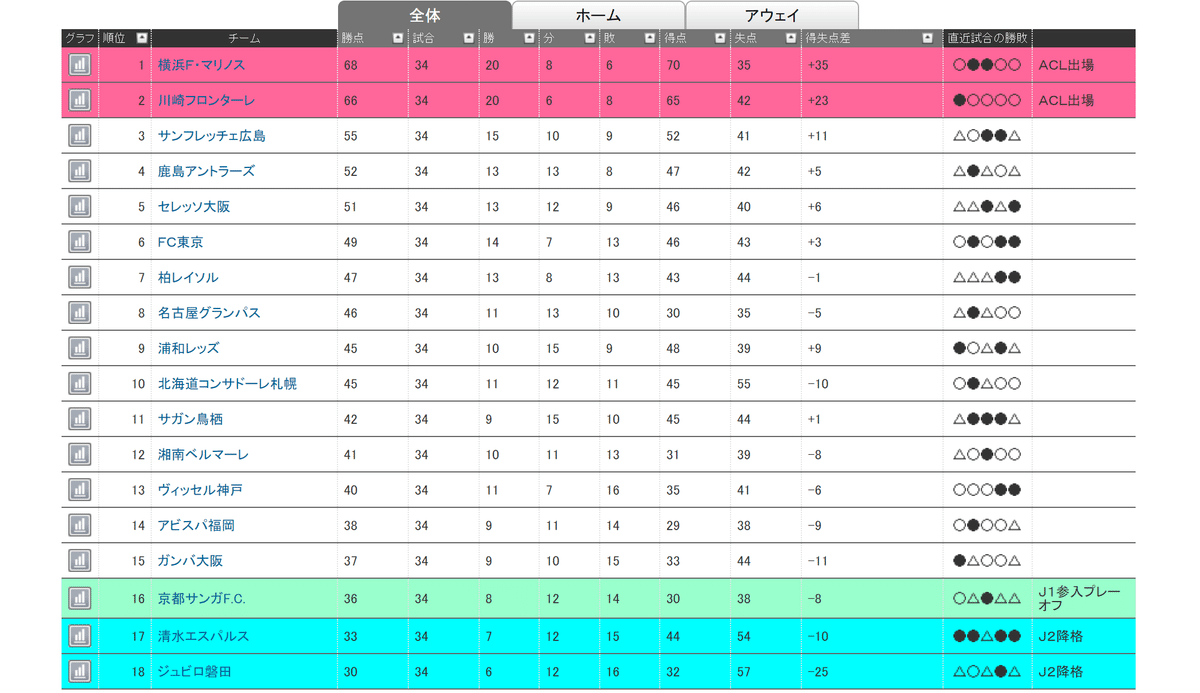
サイトに行くと下のような順位表がありました。これは使えそうですね。
url="https://data.j-league.or.jp/SFRT01/?competitionSectionIdLabel=%E6%9C%80%E6%96%B0%E7%AF%80&competitionIdLabel=%E6%98%8E%E6%B2%BB%E5%AE%89%E7%94%B0%E7%94%9F%E5%91%BD%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&yearIdLabel=2022%E5%B9%B4&yearId=2022&competitionId=521&competitionSectionId=0&search=search"
data = pd.read_html(requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text,header=0)
data[0]
欠損値が出ていたり、0始まりだったりするので表を整えていきます。
data[0].index = data[0].index + 1
rank = data[0][['チーム','勝点', '勝', '分', '敗', '得点', '失点', '得失点差']]
rank
次は走行距離のデータを取ってきます。
これはJリーグ公式サイト(【公式】成績・データ:Jリーグ公式サイト(J.LEAGUE.jp) (jleague.jp)にありました。

url2="https://www.jleague.jp/stats/2022/distance.html?s=TEAM"
data2=pd.read_html(requests.get(url2, headers={'User-agent': 'Mozilla/5.0'}).text,header=0)
data2[5].index = data2[5].index + 1
run=data2[5][['チーム','走行距離', ]]
run先程の順位表と手順は一緒です。
しかしサイト内にデータが複数あるので、データの番手を[5]で選択しています。

こうやって見るとサガン鳥栖の運動量、際立ちますね!
先ほどの表と合体させます。
df=pd.merge(rank ,run)
df.index = df.index + 1
df
いい感じ!
走行距離で断トツだった鳥栖が11位と沈んでいるのが歯痒い・・・。
てかこの時点で勝点との相関は少なそうですよね。
無視して続けます。
ここで一度散布図を確認します。
散布図はplt.scatterを使い、x軸とy軸を指定します。
plt.scatter(df['勝点'], df['走行距離'])
plt.xlabel('win')
plt.ylabel('run')
plt.ylim(18,-1)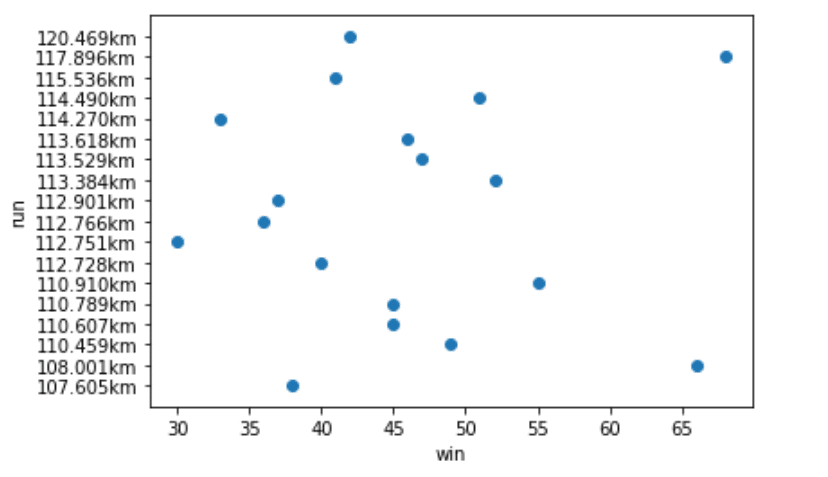
目視ですが、全く相関なさそうですね。勝点1位のマリノスがかなりの距離を走っていますが、2位のフロンターレの走行距離は下から2番目です。
この辺りはチームの特色と言えそうです。
念の為、相関係数(corr()を使用)を見てみます。
r=df[["勝点","走行距離"]].corr()
r
走行距離が表示されないエラーが発生・・・。
よくよく調べると走行距離に単位(㎞)がついていて、数値ではなく文字として認識されていることが原因のようです。
「普通、数値ってわかるやん!」って言いたくなるけど、そんなのPythonには通用しません。
この単位を削りつつ、文字(str)を数値(int)に変える方法、かなりややこしそうですが、全く同じ悩みを持たれた方がいました。
pandasのデータフレームの単位を消したい (teratail.com)
しかもプロ野球選手のデータを集めておられるようなので、仲良くなれそうな気がしました。
この中にあるベストアンサーを参考に下記のコードにたどり着きました。
df['走行距離'].str.replace('km','').astype(float)replace('km', ' ')を使って単位を消しています。
そして走行距離には小数点がついているので、astypeで文字列(str)を変換する時はintではなく、floatを入力するようです。

いけました!単位が外れ、少数付きの値(float)として認識されました。
これ、さらっと書きましたが、かなり苦労しました。
これを先ほどのデータフレームに追加し、同じように相関係数を確認します。
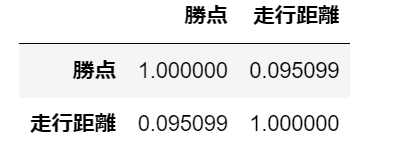
走行距離の相関係数が出ました!
相関係数の絶対値0.0~0.2は、ほとんど相関関係がない値らしいです。
0.095なので目視で見た通りでしたね。
係数を用いた上で確認できたので満足です。
ちなみにこちらのサイト【2022年 サッカーJリーグ チーム別年俸ランキング|サカマネ.net (soccer-money.net)】ではチームの年俸に関するデータがありました。サガン鳥栖のチーム年俸はなんと1番下!
今回と同じように分析し、J1の"コスパ"も検証できたらと考えましたが、「億」「万円」という単位がついてきて、今回よりもややこしそうなのでやめました。
以上、初めてnoteでpythonのコードを記録しました。
初学者のシンプルなコードですが、誰かの参考になれば嬉しいです。
この記事が気に入ったらサポートをしてみませんか?