
[翻訳]教育・研究における生成AIのためのガイダンス by UNESCO

2023年9月、UNESCOがGuidance for generative AI in education and researchを公開しました。
https://unesdoc.unesco.org/ark:/48223/pf0000386693
4月に公開された高等教育におけるChatGPT利用のクイックスタートガイドをさらに洗練・充実させた包括的ガイダンスです。
今回はChatGPT(GPT-4)を使用し、ガイダンスの本文・全セクションを機械翻訳しました。以下に対話URLも共有しますので、要約等にご利用ください。
要約📝
生成AI(GenAI)の技術は、教育と研究の領域に深い影響を与える可能性があり、これがどのように発展するかはまだ完全に理解されていません。GenAIの出現により、知的財産や教育の内容、思考プロセスなど、多くの分野での新しい倫理的問題や考慮すべき点が浮き彫りになっています。特に、GenAIが提供する情報や支援が人間の独立した思考や学びを制限する恐れがあるため、教育と研究のアプローチを再評価する必要があります。最終的には、AIは人間の知的能力や社会的スキルを拡張するツールとしての役割を果たすべきであり、その使用は人間中心のアプローチに基づいて検討されるべきです。これにより、AIの真の潜在力が包括的なデジタル未来を構築するために最大限に活用されることが保証されます。
注意👷
翻訳文の内容や意味をほとんど精査していないので、
ざっくり日本語で把握する程度の用途でご利用ください。
※ 目に余る部分は随時改良します。
1. 生成AIとは何か、それはどのように機能するのか?
1.1 生成AIとは何か?
生成AI(GenAI)は、自然言語の会話インターフェイスに書かれたプロンプトに対して内容を自動生成する人工知能(AI)技術です。既存のウェブページを単純にキュレーションするのではなく、既存のコンテンツを基にして、GenAIは新しいコンテンツを実際に生み出します。その内容は、人間の思考の象徴的な表現すべての形式で出力できます:例えば、自然言語で書かれたテキスト、画像(写真からデジタルペインティングやカートゥーンまで)、動画、音楽、ソフトウェアコードなどです。GenAIは、ウェブページ、ソーシャルメディアの会話、その他のオンラインメディアから収集されたデータを使用してトレーニングされています。それは、摂取したデータの中の単語、ピクセル、または他の要素の分布を統計的に分析し、一般的なパターン(例えば、どの単語が通常どの単語の後に続くかなど)を識別して繰り返すことによって、その内容を生成します。
GenAIは新しいコンテンツを生成することができますが、実世界の物体や言語の基盤となる社会関係を理解していないため、新しいアイデアや実世界の課題への解決策を生成することはできません。さらに、流暢で印象的な出力にも関わらず、GenAIの正確さを信頼することはできません。実際、ChatGPTの提供者も次のように認めています。「ChatGPTのようなツールは、合理的に聞こえる回答をしばしば生成することができますが、正確性を信頼することはできません。」(OpenAI、2023年)。ほとんどの場合、ユーザーが質問のトピックについてしっかりとした知識を持っていない限り、エラーは気づかれません。
1.2 生成AIはどのように動作するのか?
GenAIの背後にある具体的な技術は、AI技術のファミリーである機械学習(ML)の一部であり、これによりデータから継続的かつ自動的にパフォーマンスを向上させるためのアルゴリズムを使用しています。最近の年に見られたAIの進歩、たとえば顔認識のためのAIの使用など、多くをもたらしてきたMLのタイプは、人間の脳の動作と神経細胞間のシナプス接続に触発された人工ニューラルネットワーク(ANN)として知られています。ANNには多くの種類があります。テキストと画像の生成AI技術は、研究者たちが数年間利用してきたAI技術のセットに基づいています。1 例として、ChatGPTはGenerative Pre-trained Transformer(GPT)を使用しており、画像のGenAIは通常、Generative Adversarial Networks(GANs)として知られているものを使用しています(Table 1参照)。3
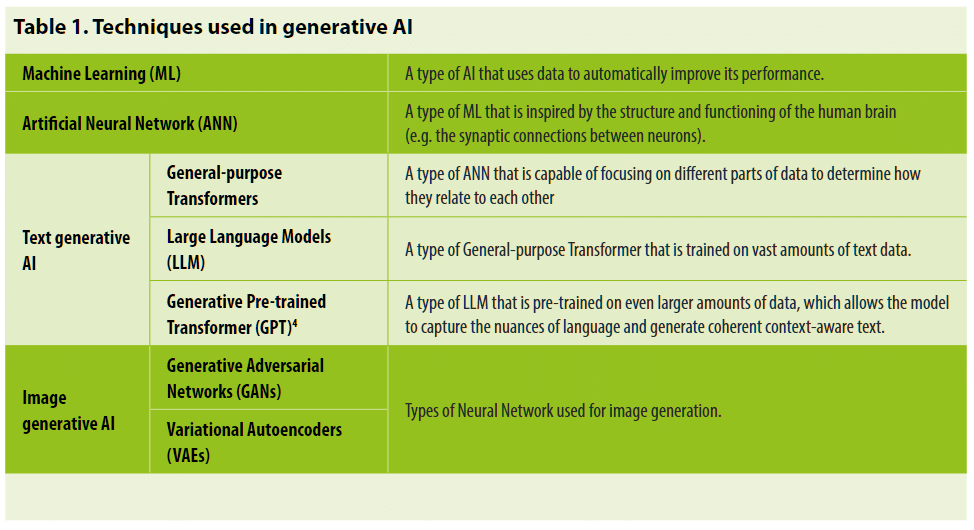
1.2.1 テキスト生成AIモデルの動作方法
テキスト生成AIは、General-purpose Transformerとして知られるANNのタイプと、Large Language Modelと呼ばれるGeneral-purpose Transformerのタイプを使用しています。これが、AIのテキスト生成AIシステムがしばしばLarge Language Models、またはLLMsとして参照される理由です。テキスト生成AIが使用するLLMのタイプはGenerative Pre-trained Transformer、またはGPTとして知られています(「ChatGPT」の「GPT」の由来)。ChatGPTはOpenAIによって開発されたGPT-3をベースにしています。これは彼らのGPTの第三のバージョンであり、最初のものは2018年に、最新のGPT-4は2023年3月にローンチされました(テーブル2参照)。各OpenAI GPTは、AIアーキテクチャ、訓練方法、最適化技術の進歩を通じて、前のものを反復的に改善しました。この連続した進歩のよく知られた面は、指数関数的に増加する「パラメータ」の数を訓練するためのデータの量を増やすことです。パラメータは、GPTのパフォーマンスを微調整するために調整できる比喩的なノブと考えることができます。これには、モデルが入力を処理し、出力を生成する方法を決定する数値パラメータであるモデルの「重み」が含まれます。AIアーキテクチャと訓練方法の最適化の進歩に加えて、この迅速なバージョンアップは、大企業が利用できる大量のデータ5と計算能力の向上にもよるものです。2012年以来、GenAIモデルの訓練に使用される計算能力は、毎3-4ヶ月ごとに倍増してきました。比較すると、ムーアの法則は2年間の倍増期間を持っていました(OpenAI, 2018; スタンフォード大学, 2019)。

GPTが訓練された後、プロンプトへのテキスト応答を生成するには、以下の手順が含まれます:
プロンプトは、GPTへの入力として使用されるより小さな単位(トークンと呼ばれる)に分解されます。
GPTは、プロンプトに対する首尾一貫した応答を形成する可能性のある単語やフレーズを予測するための統計的なパターンを使用します。
GPTは、事前に構築された大規模なデータモデル(インターネットやその他の場所からスクレイプされたテキストで構成)で一般的に共起する単語やフレーズのパターンを識別します。
これらのパターンを使用して、GPTは特定の単語やフレーズが特定の文脈で表示される確率を推定します。
ランダムな予測から始めて、GPTはこれらの推定確率を使用して、応答の次の可能性のある単語やフレーズを予測します。
予測された単語やフレーズは、読みやすいテキストに変換されます。
読みやすいテキストは、「ガードレール」として知られるものを通してフィルタリングされ、不快なコンテンツが削除されます。
ステップ2から4が、応答が完成するまで繰り返されます。応答は、最大トークン制限に達するか、事前に定義された停止基準を満たすと、完成とみなされます。
応答は、フォーマット、句読点、およびその他の強化(「確かに」、「もちろん」、「申し訳ありません」といった、人間が使用する可能性のある単語で応答を始めるなど)を適用することで、可読性を向上させるために後処理されます。
2018年以降、研究者らは、GPTや自動的にテキストを生成する能力を利用可能でしたが、ChatGPTのローンチが画期的だったのは、簡単に使用できるインターフェースを介した無料アクセスが提供されたことです。つまり、インターネットアクセスがあれば、誰でもこのツールを探索できました。ChatGPTのローンチは、世界中に衝撃を与え、他のグローバルテクノロジー企業が追いつくように急速に行動を起こし、多くのスタートアップ企業が自らの類似のシステムをローンチするか、新しいツールを上に構築することで参入しました。
2023年7月までに、ChatGPTの代替品として以下のものが挙げられます:
Alpaca:7
スタンフォード大学からのMetaのLlamaのファインチューンされたバージョンで、LLMsの偽情報、社会的ステレオタイプ、および有害な言語に対処することを目指しています。Bard:8
GoogleのLaMDAおよびPaLM 2システムを基にしたLLMで、リアルタイムでインターネットにアクセスできるため、最新の情報を提供できます。Chatsonic:9
Writesonicによって作られ、ChatGPTをベースにしながらも直接データをクロールします。Ernie (または Wenxin Yiyan文心一言としても知られています):10
BaiduからのバイリンガルLLMで、まだ開発中ですが、テキストと画像を生成するために大量のデータセットと幅広い知識を統合します。Hugging Chat:11
HuggingFaceによって作られ、開発、トレーニング、およびデプロイの全体を通じて倫理と透明性を重視しています。さらに、モデルをトレーニングするために使用されるすべてのデータはオープンソースです。Jasper:12
例えば、ユーザーの特定の好みのスタイルで書くようにトレーニングできるツールやAPIのスイート。画像も生成できます。Llama:13
新しいアプローチをテストするための計算能力とリソースが少なくても済むMetaのオープンソースLLM。他の作業を検証し、新しい使用ケースを探求します。Open Assistant:14
十分な専門知識を持つ誰でも自分のLLMを開発できるように設計されたオープンソースのアプローチ。ボランティアによってキュレーションされたトレーニングデータに基づいて構築されました。Tongyi Qianwen (通义千问):15
英語または中国語でプロンプトに応答できるAlibabaのLLM。Alibabaのビジネスツールスイートに統合されています。YouChat:16
追加のコンテキストと洞察を提供するためのリアルタイム検索機能を組み込んだLLM。より正確で信頼性のある結果を生成します。
これらの多くは(一定の制限内で)無料で使用できる一方、いくつかはオープンソースです。これらのLLMsのいずれかに基づいて多くの他の製品が発売されています。例として以下が挙げられます:
ChatPDF:17
提出されたPDFドキュメントに関する要約や質問の回答を行います。Elicit: The AI Research Assistant:18
研究者のワークフローの一部を自動化し、関連する論文を特定し、主要な情報を要約することを目指しています。Perplexity:19
彼らのニーズに合わせた迅速かつ正確な答えを求める人々のための「知識ハブ」を提供します。
同様に、LLMベースのツールは、ウェブブラウザーなどの他の製品に組み込まれています。例として、ChatGPTに基づいて構築されたChromeブラウザの拡張機能には以下があります:
WebChatGPT:20
より正確で最新の会話を可能にするために、ChatGPTにインターネットアクセスを提供します。Compose AI:21
メールや他の場所での文章をオートコンプリートします。TeamSmart AI:22
「バーチャルアシスタントのチーム」を提供します。Wiseone:23
オンライン情報を単純化します。
さらに、ChatGPTはいくつかの検索エンジンに組み込まれており、大規模な生産性ツールのポートフォリオ(例:Microsoft WordやExcel)に実装されているため、世界中のオフィスや教育機関でさらに利用可能になっています(Murphy Kelly、2023)。
最後に、画像GenAIへの興味深い移行として、OpenAIの最新のGPT、GPT-4は、テキストだけでなく、プロンプトとしての画像も受け入れることができます。この意味で、それはマルチモーダルです。したがって、一部の人々は、「Large Language Model」(LLM)という名前が適切でなくなってきていると主張しており、これがスタンフォード大学の研究者が「foundation model」という用語を提案した理由の一つです(Bommasani et al., 2021)。この代替案はまだ広く採用されていません。
1.2.2. 画像GenAIモデルの仕組み
画像GenAIや音楽GenAIは、通常、Generative Adversarial Networks(GANs)として知られる異なるタイプのANNを使用し、Variational Autoencodersと組み合わせることもできます。 GANには二つの部分(二つの「対立者」)があり、それは「生成器」と「識別器」です。 画像GANの場合、生成器はプロンプトに対するランダムな画像を生成し、識別器はこの生成された画像と実際の画像を区別しようとします。 生成器は次に、識別器の結果を使用してそのパラメータを調整し、別の画像を作成します。 このプロセスは、生成器が識別器が実際の画像と区別できるようになる、より現実的な画像を作成するように何千回も繰り返されます。 例えば、何千もの風景写真のデータセットで訓練された成功したGANは、実際の写真とほとんど見分けがつかない新しいが実在しない風景の画像を生成するかもしれません。 一方、人気のある音楽(または単一のアーティストによる音楽)のデータセットで訓練されたGANは、元の音楽の構造と複雑さに従って新しい音楽の部分を生成するかもしれません。
2023年7月時点で、利用可能な画像GenAIモデルには以下のものが含まれており、すべてテキストプロンプトから画像を生成します。ほとんどは、一定の制限内で無料で使用できます:
Craiyon:25
以前はDALL•E miniとして知られていました。DALL•E 2:26
OpenAIの画像GenAIツール。DreamStudio:27
Stable Diffusionの画像GenAIツール。Fotor:28
画像編集ツールの範囲でGenAIを組み込む。Midjourney:29
独立した画像GenAIツール。NightCafe:30
Stable DiffusionとDALL•E 2へのインターフェース。Photosonic:31
WriteSonicのAIアートジェネレーター。
アクセスしやすいビデオGenAIの例には、以下のものがあります:
Elai:32
プレゼンテーション、ウェブサイト、テキストをビデオに変換できます。GliaCloud:33
ニュースコンテンツ、ソーシャルメディアの投稿、ライブスポーツイベント、統計データからビデオを生成できます。Pictory:34
長いコンテンツから自動的に短いビデオを作成できます。Runway:35
ビデオ(およびイメージ)の生成および編集ツールの範囲を提供します。
最後に、これらはアクセスしやすい音楽GenAIの一部の例です:
Aiva:36
自動的にパーソナライズされたサウンドトラックを作成できます。Boomy:37
Soundraw,38 およびVoicemod:39 任意のテキストから曲を生成でき、音楽作曲の知識は必要ありません。
1.3 望ましい出力を生成するためのプロンプトエンジニアリング
GenAIの使用は、質問や他のプロンプトを入力するだけで簡単にできるように思えますが、実際にはユーザーがまさに望む出力を得るのはまだ簡単ではありません。例えば、米国コロラド州フェアで賞を受賞した画期的なAI画像「Théâtre D’opéra Spatial」は、最終提出を生成するために何週間ものプロンプトの書き込みと数百の画像の微調整が必要でした(Roose, 2022)。テキストGenAIの効果的なプロンプトを書くという同様の課題は、求人ウェブサイトにプロンプトエンジニアリングの仕事が増えていることにつながっています(Popli, 2023)。'プロンプトエンジニアリング'は、GenAIの出力がユーザーの望む意図により近いものとなるような入力を作成するためのプロセスと技術を指します。
プロンプトが特定の問題や論理的な順序での思考の連鎖を中心とした矛盾のない論理的連鎖を明確に述べるとき、プロンプトエンジニアリングは最も成功します。具体的な推奨事項は以下のとおりです:
複雑または曖昧な言葉を避け、簡単で明確でわかりやすい言語を使用する。
生成される完成品の望ましい応答や形式を示す例を含める。
関連性があり、意味のある完成品を生成するためには、文脈を含めることが重要である。
必要に応じて調整し、異なるバリエーションで実験する。
不適切、偏見がある、または有害なコンテンツを生成する可能性のあるプロンプトを避けるため、倫理的であること。
また、GenAIの出力は批判的な評価なしには頼りにできないことをすぐに認識することも重要です。OpenAIが最も洗練されたGPTについて書いているように:40
GPT-4は高度な能力を持っているにもかかわらず、以前のGPTモデルと同様の制約があります。最も重要なのは、それがまだ完全に信頼性があるわけではないことです(事実を「幻視する」と推論の誤りを犯します)。言語モデルの出力を使用する際には、特に高いリスクを伴う文脈で、特定の使用ケースのニーズに合わせて正確なプロトコル(人間によるレビュー、追加の文脈での根拠付け、あるいは高リスクの使用を完全に避けるなど)を使用して非常に慎重に行動する必要があります。
GenAIの出力の品質を考慮すると、大規模または高リスクの採用のためのツールを検証する前に、厳格なユーザーテストとパフォーマンス評価を行う必要があります。このような演習は、ユーザーがGenAIに出力を提供するよう要求するタスクのタイプに最も関連するパフォーマンスメトリクスで設計する必要があります。例えば、数学の問題を解決するためには、「正確さ」を主要なメトリクスとして使用して、GenAIツールが正しい答えをどれだけの頻度で生成するかを量ることができます。センシティブな質問に対応するためには、パフォーマンスを測定する主要なメトリックは「回答率」(GenAIが質問にどれだけの頻度で直接答えるか)となるかもしれません。コード生成の場合、メトリックは「生成されたコードの実行可能な割合」(生成されたコードがプログラミング環境で直接実行でき、ユニットテストを通過するかどうか)となるかもしれません。視覚的な推論のためには、メトリックは「完全一致」(生成された視覚オブジェクトが基準の真実と完全に一致するかどうか)となるかもしれません(Chen, Zaharia, and Zou, 2023)。
要するに、表面的なレベルでは、GenAIは使いやすいですが、より高度な出力は熟練した人間の入力が必要であり、使用される前に批判的に評価されなければなりません。
💡教育と研究への影響
GenAIは教師や研究者が彼らの仕事をサポートするための有用なテキストや他の出力を生成するのを助けるかもしれませんが、必ずしも簡単なプロセスではありません。望む出力が得られるまでに、何度もプロンプトを繰り返すことが必要な場合があります。心配なのは、学生たちが定義上教師よりも専門的でないため、表面的で不正確、またはさらに有害なGenAIの出力を知らず知らずのうちに、そして批判的に関与することなく受け入れてしまう可能性があることです。
1.4 新興のEdGPTとその意義
GenAIモデルがより専門的またはドメイン固有のモデルを開発するための基盤または出発点として機能できることを考慮すると、一部の研究者は、GPTを「ファンデーションモデル」と改名すべきだと提案しています(Bommasani et al., 2021)。教育の分野では、開発者や研究者は、基盤モデルを微調整して「EdGPT」を開発し始めています。41 EdGPTモデルは、教育の目的を果たすために特定のデータで訓練されています。言い換えれば、EdGPTは、大量の一般的なトレーニングデータから派生したモデルを、高品質のドメイン固有の教育データの少量で微調整することを目指しています。
これにより、セクション4.3で挙げられた変換の実現をサポートするためのEdGPTの範囲が拡大する可能性があります。例えば、カリキュラムの共同設計をターゲットとしたEdGPTモデルは、効果的な教育手法と特定のカリキュラムの目的および特定の学習者の挑戦レベルに密接に合致した適切な教育資料(例:レッスンプラン、クイズ、インタラクティブなアクティビティ)を生成することができるかもしれません。同様に、1:1の言語スキルコーチの文脈では、特定の言語に適したテキストで微調整された基盤モデルが、練習のための模範となる文、段落、または会話を生成するために使用されるかもしれません。学習者がモデルと対話すると、モデルは彼らの適切なレベルで関連性があり文法的に正確なテキストで応答することができます。理論的には、EdGPTモデルの出力は標準のGPTよりも一般的なバイアスやその他の問題の内容を含む可能性が少ないかもしれませんが、まだエラーを生成する可能性があります。基本的なGenAIモデルやアプローチが大きく変わらない限り、EdGPTはまだエラーを生成する可能性があり、レッスンプランや教育戦略の提案などの他の方法で制限されているということを認識することが重要です。そのため、EdGPTの主要なユーザー、特に教師や学習者は、出力に対して批判的な視点を持つ必要があります。
現在、教育におけるGPTのよりターゲット指向の使用のための基盤モデルの微調整は初期段階にあります。存在する例としては、EduChatがあります。これは、東中国師範大学が開発した基盤モデルで、教育と学習のサービスを提供するものであり、そのコード、データ、パラメータはオープンソースとして共有されています。42もう一つの例は、TAL教育グループによって開発されているMathGPTであり、これは数学関連の問題解決と講義を世界中のユーザーのために提供するLLMです。43
しかし、大きな進展が可能となる前に、主題知識の追加や偏見の除去だけでなく、関連する学習方法の知識の追加、およびこれがアルゴリズムとモデルの設計にどのように反映されるかについての取り組みを行うことが不可欠です。課題は、EdGPTモデルが主題知識を超えて、学生中心の教育方法や肯定的な教師-生徒の対話をどの程度ターゲットとできるかを判断することです。さらなる課題は、学習者と教師のデータをどの程度、どのようにして倫理的に収集し、EdGPTを通知するために使用できるかを判断することです。最後に、EdGPTが学生の人権を侵害したり、教師を権力を剥奪したりしないことを保証するための堅実な研究が必要です。
2. 生成AIをめぐる論争とその教育への影響
前のセクションでGenAIが何であるか、そしてそれがどのように機能するかを議論しました。このセクションではすべてのGenAIシステムによって提起される論争や倫理的リスクを検討し、教育に対するいくつかの意味合いを考慮します。
2.1 デジタル貧困の悪化
前述の通り、GenAIは大量のデータと膨大な計算能力に依存しており、AIのアーキテクチャと訓練方法の繰り返しの革新に加えて、これは主に最大の国際技術企業と少数の経済(主にアメリカ、中華人民共和国、そしてある程度ヨーロッパ)のみが利用可能です。これは、ほとんどの企業やほとんどの国、特にグローバルサウスの国々にとって、GenAIを作成し制御する可能性が手の届かないものであることを意味します。
データへのアクセスが国の経済発展や個人のデジタルチャンスにとってますます不可欠になる中で、データへのアクセスを持たないか、十分なデータを手に入れることができない国や人々は「データ貧困」の状況に置かれています(Marwala, 2023)。計算能力へのアクセスの状況も同様です。技術的に進んだ国や地域でのGenAIの急速な浸透は、データの生成と処理を指数関数的に加速させ、同時にグローバルノースにおけるAI富の集中を強化しました。直接的な結果として、データが貧弱な地域はさらに排除され、GPTモデルに組み込まれた基準によって植民地化される長期的なリスクにさらされています。現在のChatGPTモデルは、オンラインユーザーからのデータに基づいて訓練されており、これはグローバルノースの価値観と規範を反映しています。これにより、グローバルサウスの多くの部分や、グローバルノースのより不利なコミュニティにおける地域に関連するAIアルゴリズムには不適切となっています。
💡教育と研究への影響
研究者、教師、学習者は、GenAI訓練モデルに組み込まれた価値指向、文化的基準、社会的慣習について批判的な視点を持つべきです。政策立案者は、GenAIモデルの訓練と制御における格差の拡大によって引き起こされる不平等の悪化を認識し、それに対処する行動を取るべきです。
2.2 国家による規制適応の壁を超える
主要なGenAIプロバイダーは、システムを厳格な独立した学術的審査の対象としていないことで批判されてきました(Dwivedi et al., 2023)。44会社のGenAIの基盤技術は、企業の知的財産として保護される傾向があります。一方、GenAIを利用し始めている多くの企業は、システムのセキュリティを維持することがますます難しくなっていると感じています(Lin, 2023)。さらに、AI産業自体からの規制の要求にもかかわらず、45GenAIを含む全てのAIの作成と使用に関する法律の起草は、急速な開発のペースに追いついていないことが多い。これは、国や地方の機関が法的および倫理的問題を理解し、統治する上での課題を部分的に説明している。46
GenAIが特定のタスクの完了における人間の能力を増強するかもしれませんが、GenAIを推進している企業の民主的なコントロールは限られています。これは、特に、地域の機関や個人のデータ、および国の領土で生成されたデータを含む国内データへのアクセスや使用に関する規制の問題を提起します。適切な法律が必要であり、地元の政府機関がGenAIの急増する波に対して一定のコントロールを持ち、公共の利益としてのその統治を確保できるようにする必要があります。
💡教育と研究への影響
研究者、教師、学習者は、国内の機関や個人の所有権を保護し、GenAIの国内ユーザーの権利を守るための適切な規制の不足、およびGenAIによって引き起こされる法律問題に対応することを認識する必要があります。
2.3 承諾なしでのコンテンツの使用
前述の通り、GenAIモデルは、インターネットから収集した大量のデータ(例:テキスト、音、コード、画像)を基に構築されており、その多くは所有者の許可なしに使用されています。このため、多くの画像GenAIシステムや一部のコードGenAIシステムは知的財産権を侵害しているとの非難を浴びています。執筆時点で、この問題に関連するいくつかの国際的な法的な事件が進行中です。さらに、一部の人々は、GPTが欧州連合(2016)の一般データ保護規則(GDPR)などの法律に違反している可能性があると指摘しています。特に、「忘れられる権利」という人々の権利に関して、一度GPTモデルでトレーニングが行われると、そのデータ(またはそのデータの結果)をGPTモデルから削除することは現在不可能です。
💡教育と研究への影響
* 研究者、教師、学習者は、データ所有者の権利を知る必要があり、使用しているGenAIツールが既存の規制に違反していないか確認するべきです。
* 研究者、教師、学習者は、GenAIで作成された画像やコードが他者の知的財産権を侵害する可能性があり、また、彼らが作成しインターネットで共有した画像、音、またはコードが他のGenAIによって悪用されるかもしれないということを意識するべきです。
2.4 出力を生成するための説明不可能なモデル
長らく、人工ニューラルネットワーク(ANN)は通常「ブラックボックス」であると認識されてきました。つまり、その内部の動作は検査の対象とならないということです。その結果、ANNは「透明」でも「説明可能」でもなく、その出力がどのように決定されたかを確認することはできません。
全体的なアプローチ、使用されるアルゴリズムを含む、は一般的には説明可能ですが、特定のモデルとそのパラメータや重みは検査できません。これが、生成される特定の出力を説明できない理由です。GPT-4のようなモデルには何十億ものパラメータ/重みがあり(表2参照)、それはモデルが出力を生成するために使用する学習したパターンを集約して保持しています。ANNのパラメータ/重みは透明ではない(表1参照)ため、これらのモデルによって特定の出力がどのように作成されたかを正確に説明することはできません。
GenAIの透明性と説明性の欠如は、GenAIがますます複雑になるにつれて(表2参照)、しばしば予期しない、または望ましくない結果を生むようになるため、問題となっています。さらに、GenAIモデルはそのトレーニングデータに存在するバイアスを受け継ぎ、増幅します。これは、モデルの非透明性のため、検出し対処するのが難しいです。最後に、この不透明性は、GenAI周辺の信頼問題の主要な原因でもあります(Nazaretsky et al.、2022a)。ユーザーがGenAIシステムが特定の出力にどのように到達したかを理解していない場合、それを採用したり使用したりすることは少なくなるでしょう(Nazaretsky et al.、2022b)。
💡教育と研究への影響
研究者、教師、学習者は、GenAIシステムがブラックボックスとして動作し、特定のコンテンツがなぜ作成されたのかを知ることが非常に難しい、あるいは不可能であることを認識する必要があります。出力がどのように生成されるかの説明の欠如は、ユーザーをGenAIシステムで設計されたパラメータによって定義されたロジックに閉じ込める傾向があります。これらのパラメータは、生成されたコンテンツに暗黙的な偏見をもたらす特定の文化的または商業的な価値観や規範を反映している可能性があります。
2.5 生成AIコンテンツによるインターネット汚染
GPTのトレーニングデータは通常、インターネットから取得されるもので、これには差別的な言語や他の受け入れがたい言葉が頻繁に含まれるため、開発者はGPTの出力が攻撃的であり/または非倫理的でないようにするために「ガードレール」と呼ばれるものを実装する必要がありました。しかしながら、厳格な規制と効果的な監視機構の不在のため、GenAIによって生成された偏った資料がインターネット全体にますます広がっており、世界中のほとんどの学習者にとっての主要なコンテンツや知識の源を汚染しています。これは、GenAIによって生成される資料が非常に正確で説得力があるように見える場合でも、しばしばそれには誤りや偏見のある考えが含まれているため、特に重要です。これは、該当するトピックに関する十分な事前知識を持っていない若い学習者にとって高いリスクをもたらします。また、GPTモデル自体が作成したテキストから収集されたテキストで訓練される将来のGPTモデルにとってのリスクもあり、それにはそのバイアスや誤りも含まれます。
💡教育と研究への影響
* 研究者、教師、そして学習者は、GenAIシステムが攻撃的で非倫理的な資料を出力する可能性があることを認識する必要があります。
* また、先のGPTモデルが生成したテキストに基づいている未来のGPTモデルの知識の信頼性に潜在的に生じる長期的な問題についても知る必要があります。
2.6 実世界の理解の欠如
テキストGPTは、時折「確率的なオウム」と揶揄的に言及されることがあります。これは、GPTが納得のいくテキストを生成できるものの、そのテキストはしばしば誤りを含み、有害な発言を含むことがあるためです(Bender et al., 2021)。これは、GPTがそのトレーニングデータ(通常はインターネットから引用したテキスト)に見られる言語のパターンを繰り返すだけで、その意味を理解することなく、ランダム(または「確率的」)なパターンから開始するためです。これは、オウムが実際に何を言っているのかを理解せずに音を模倣できるようにです。
GenAIモデルが使用して生成するテキストを「理解している」ように「見える」と、実際には言語や実世界を理解していないという「現実」との乖離は、教師や学生がその出力に適切でない信頼を置く原因となることがあります。これは、未来の教育にとって深刻なリスクをもたらす可能性があります。実際、GenAIは実世界の観察や科学的方法の他の重要な側面に基づいておらず、人間や社会の価値とも一致していません。このため、実世界、物体やその関係、人々や社会関係、人間と物体の関係、人間と技術の関係に関する真に新しいコンテンツを生成することはできません。GenAIモデルによって生成された見かけ上の新しいコンテンツが科学的知識として認識されるかどうかは議論の余地があります。
既に指摘されているように、GPTはしばしば不正確または信頼性の低いテキストを生成します。実際、GPTが実生活には存在しない何かを作り出すことはよく知られています。これを「幻覚」と呼ぶ人もいますが、そのような擬人化された、したがって誤解を招きやすい用語を使うことを批判する人もいます。これは、GenAIを製造している企業にも認識されています。たとえば、ChatGPTの公開インターフェイスの最下部には「ChatGPTは、人々、場所、または事実に関する不正確な情報を生成する可能性があります」と記載されています。
また、一部の支持者は、GenAIが人間よりも賢いAIのクラスを示唆する用語であるArtificial General Intelligence(AGI)への道のりの重要なステップを代表していると提案しています。しかし、これは長い間批判されてきました。少なくとも知識ベースのAI(シンボリックAIやルールベースのAIとしても知られている)とデータベースのAI(マシンラーニングとしても知られている)の両方を何らかの形で結合するまで、AIはAGIに進化することはないという主張があります(Marcus, 2022)。AGIや知覚の主張は、AIを使って既に差別されているグループに対する隠れた差別のような、現在の害から私たちの注意をそらすものでもあります(Metz, 2021)。
💡教育と研究への影響
* テキストGenAIの出力は、生成したテキストを理解しているかのように見えるほど人間らしく見えることがあります。しかし、GenAIは何も理解していません。代わりに、これらのツールはインターネット上で一般的な方法で言葉を綴じています。生成されるテキストも間違っていることがあります。* 研究者、教師、学習者は、GPTが生成したテキストを理解していないこと、間違った声明を生成することができ、実際にはそうすることが多いこと、そしてそれゆえに、それが生成するすべてのものに対して批判的なアプローチをとる必要があることを認識する必要があります。
2.7 意見の多様性の減少と、既に疎外されている声のさらなる疎外
ChatGPTや同様のツールは、モデルを訓練するために使用されたデータの所有者/作成者の価値観を前提とした標準的な答えのみを出力する傾向があります。実際、トレーニングデータに頻繁に出現する単語の並び(一般的で物議を醸すことのないトピックや主流または支配的な信念の場合)は、その出力でGPTによって繰り返される可能性があります。
これにより、多数の意見やアイデアの多様な表現の発展が制約され、損なわれるリスクがあります。データに乏しい人口、特にグローバルノースの疎外されたコミュニティは、オンラインでのデジタルプレゼンスが最小または限定的です。そのため、彼らの声は聞かれず、GPTを訓練するために使用されるデータに彼らの懸念が代表されていないため、出力にはほとんど現れません。これらの理由から、インターネットのウェブページやソーシャルメディアの会話に基づく事前トレーニングの方法論を考えると、GPTモデルは既に不利な人々をさらに疎外する可能性があります。
💡教育と研究への影響
* GenAIモデルの開発者や提供者は、これらのモデルのデータセットや出力における偏見を継続的に対処する主要な責任を持っていますが、ユーザー側の研究者、教師、学習者は、テキストGenAIの出力がそのトレーニングデータが生成された時点での世界の最も一般的または支配的な見解を代表しており、その中には問題があるか偏見を持っているもの(例:ステレオタイプな性別の役割)もあることを知る必要があります。
* 学習者、教師、研究者は、GenAIによって提供される情報をそのまま受け入れることなく、常に批判的に評価するべきです。
* 研究者、教師、学習者は、トレーニングデータ内で少数派の声が定義上少ないため、少数派の声が省かれる方法にも気を配る必要があります。
2.8 より深いディープフェイクの生成
すべてのGenAIに共通の論争に加えて、GAN GenAIは、既存の画像や動画を変更または操作して、本物と区別がつかない偽のものを生成するために使用することができます。GenAIは、これらの「ディープフェイク」やいわゆる「フェイクニュース」を作成することがますます容易になっています。言い換えれば、GenAIは、デマを広めたり、憎悪の言葉を広めたり、人々の顔を彼らの知識や同意なしに完全に偽物で、時には妥協する映画に組み込むような非倫理的、非道徳的、犯罪的な行為を特定の行為者が犯すことを容易にしています。
💡教育と研究への影響
GenAIの提供者がユーザーの著作権と肖像権を保護する義務がある一方で、研究者や教育者、学習者も、インターネット上で共有した画像がGenAIのトレーニングデータに取り込まれ、不道徳な方法で操作・利用される可能性があることを認識しておく必要があります。
3. 教育における生成AIの使用の規制
生成AIの周りの論争を解決し、教育におけるGenAIの潜在的な利点を活用するためには、まず規制が必要です。教育目的のGenAIの規制は、その倫理的、安全で公平で意味のある使用を確保するための人間中心のアプローチに基づいて、いくつかのステップと方針措置を必要とします。
3.1 AIに対する人間中心のアプローチ
2021年の人工知能の倫理に関する勧告は、教育と研究に関連する生成AI周辺の複数の論争を解決するための規範的な枠組みを提供しています。これは、AIの使用が包括的で公正で持続可能な未来のための人間の能力の発展の奉仕となるようにという人間中心のアプローチに基づいています。このようなアプローチは、人権の原則によって導かれる必要があり、人間の尊厳と知識の共通点を定義する文化的多様性を保護する必要があります。ガバナンスの観点から、人間中心のアプローチは、人間の代理、透明性、公的説明責任を確保できる適切な規制を必要とします。
2019年の北京合意書「人工知能(AI)と教育」は、教育の文脈でのAIの使用に関する人間中心のアプローチが何を意味するかをさらに詳述しています。合意書は、教育でのAI技術の使用は、持続可能な発展のための人間の能力と生活、学習、仕事における効果的な人間と機械の協力を強化するべきであると主張しています。また、言語的・文化的な多様性を促進しながら、疎外された人々をサポートし、不平等を解消するためのAIへの公平なアクセスを確保するためのさらなる行動を求めています。合意書は、教育におけるAIの方針の計画に、政府全体、異分野、多数の関係者のアプローチを採用することを提案しています。
AIと教育:政策立案者のための指南(UNESCO, 2022b)は、教育におけるAIの利益とリスク、およびAIの能力を開発する手段としての教育の役割を考察する際の人間中心のアプローチが何を意味するかをさらに洗練させています。これは、(i) 障害を持つ学習者などの脆弱なグループに特に学習プログラムへの包括的なアクセスを可能にする、(ii) 個別化されたオープンな学習オプションをサポートする、(iii) アクセスを拡大し、学習の品質を向上させるためのデータベースの提供と管理を改善する、(iv) 学習プロセスを監視し、教師に失敗のリスクを警告する、および(v) AIの倫理的で意味のある使用のための理解とスキルを開発するための方針の策定のための具体的な推奨事項を提案しています。
3.2 教育におけるGenAIを規制するためのステップ
ChatGPTのリリース前、政府はデータの収集と使用、教育を含むセクター全体でのAIシステムの採用を規制するためのフレームワークを開発または適応していました。これは新しく出現したAIアプリケーションの規制のための法的および政策的文脈を提供しました。2022年11月から複数の競合するGenAIモデルがリリースされた後、政府は異なる政策対応を採用してきました - GenAIの禁止から、既存のフレームワークの適応のニーズの評価、新しい規制の緊急策定まで。
GenAIの創造的な使用を規制および促進するための政府戦略は、2023年4月にマップ化およびレビューされました(UNESCO, 2023b)。このレビューは、政府機関がセクター全体、特に教育において、その潜在能力を活用するために生成AIを規制し、公的なコントロールを再確認するために取ることができる6つのステップのシリーズを提案しています。
ステップ1: 国際的または地域的な一般データ保護規則(GDPRs)を承認するか、国内のGDPRsを開発する
GenAIモデルのトレーニングには、多くの国の市民からのオンラインデータを収集し、処理することが含まれています。GenAIモデルによる同意なしのデータおよびコンテンツの使用は、データ保護の問題をさらに難しくしています。
一般データ保護規則、2018年に施行されたEUのGDPRを先駆ける例として、GenAIのサプライヤーによる個人データの収集および処理を規制するための必要な法的枠組みを提供します。国際連合貿易開発会議(UNCTAD)のデータ保護およびプライバシー法規ワールドラインポータルによれば、194カ国中137カ国がデータ保護とプライバシーを保護するための法律を制定しています。しかし、これらのフレームワークがそれらの国でどの程度実施されているかは、まだはっきりしていません。したがって、これらが適切に実施されていることを確認することは、今まで以上に重要です。これには、GenAIシステムの操作の定期的な監視も含まれます。また、まだ一般的なデータ保護法を持っていない国がそれらを開発することも急募されています。
ステップ2:AIに関する全体政府戦略を採用/改訂し、資金を提供する
生成AIの規制は、教育を含む開発セクター全体でのAIの安全で公平な使用を確保できる、より広範な国家AI戦略の一部でなければなりません。国家AI戦略の策定、承認、資金提供、および実施には、全体政府のアプローチが必要です。このようなアプローチだけが、新たに出現する課題への統合された対応に必要な相互セクター間の行動の調整を保証できます。
2023年初頭までに、67カ国がAIに関する国家戦略を開発または計画しており、そのうち61カ国がスタンドアロンのAI戦略の形を取り、7カ国がAIに関する章をより広範な国家ICTまたはデジタル化戦略に統合しています。その新奇性を考慮すると、これらの国家戦略のいずれも、執筆時点で生成AIを特定の問題としてまだ取り上げていませんでした。
国々が既存の国家AI戦略を改訂するか、またはそれらを開発して、教育を含むセクター全体でAIの倫理的な使用を規制するための条項を確保することが重要です。
ステップ3:AIの倫理に関する具体的な規制を確立し、実施する
AIの使用によって生じる倫理的側面を対処するために、具体的な規制が必要です。
UNESCOの2023年の既存の国家AI戦略のレビューによれば、このような倫理的問題の特定および指導原則の策定は、約40の国家AI戦略にのみ共通しています。50 そしてここでも、倫理的原則を実施可能な法律や規制に翻訳する必要があります。これはまれなケースです。実際、国家AI戦略の一部として、またはそれ以外の方法で、教育に関連するAIの倫理に関する明確な規制を定義した国は約20カ国しかありませんでした。興味深いことに、教育は約45の国家AI戦略全体で政策領域として強調されているが、51の教育への言及は、国家の競争力をサポートするために必要なAIのスキルや才能の開発の観点から、倫理的問題の観点からはあまり詳しく説明されていません。
まだAIの倫理に関する規制を持っていない国は、それらを緊急に明確にし、実施する必要があります。
ステップ4:AIが生成するコンテンツを規制するために既存の著作権法を調整または強化する
GenAIの使用が増加していることは、モデルが訓練されている著作権のあるコンテンツや作品に関して、またそれらが生み出す「非人間」の知識のアウトプットのステータスに関して、著作権に新しい課題をもたらしています。
現在、中国、ヨーロッパ連合(EU)の国々、およびアメリカ合衆国のみが、生成AIの影響を考慮に入れて著作権法を調整しています。例えば、米国著作権局は、ChatGPTのようなGenAIシステムの出力は、米国の著作権法で保護されていないと規定しており、「著作権は人間の創造性の産物である材料のみを保護できる」と主張しています(US Copyright Office, 2023)。一方、EUでは、提案されているEU AI法案が、AIツールの開発者に、システムを構築する際に使用した著作権のある資料を開示するよう要求しています(European Commission, 2021)。中国は、2023年7月に公表されたGenAIに関する規制を通じて、GenAIの出力をAIが生成するコンテンツとしてのラベル付けを要求し、デジタル合成のアウトプットとしてのみそれらを認識します。
GenAIモデルの訓練における著作権のある材料の使用を規制し、GenAI出力の著作権ステータスを定義することは、著作権法の新しい責任として浮上してきています。これを考慮に入れて既存の法律を調整することが緊急に求められています。
ステップ5:生成AIに関する規制の枠組みを詳細化する
AI技術の急速な発展は、国や地方のガバナンス機関に規制の更新を速めるよう強いています。2023年7月時点で、中国のみがGenAIに関する特定の公式規制を公表しています。2023年7月13日に公表された「生成AIサービスのガバナンスに関する暫定規定」(中国サイバースペース行政庁, 2023a)は、GenAIシステムの提供者に、既存のオンライン情報サービスの枠組みにおけるディープシンセシスの規定に従って、AIによって生成されたコンテンツ、画像、およびビデオを適切かつ合法的にラベル付けするよう要求しています。既存の地方の規制や法律のギャップの評価に基づいて、このような国のGenAI固有の枠組みをさらに開発する必要があります。
ステップ6:教育と研究におけるGenAIの適切な利用のための能力を構築する
学校やその他の教育機関は、教育のためのAI(生成AIを含む)の潜在的な利点とリスクを理解する能力を開発する必要があります。このような理解に基づいてのみ、彼らはAIツールの採用を検証することができます。さらに、教師や研究者は、トレーニングや継続的なコーチングを通じて、GenAIの適切な利用のための能力を強化するサポートが必要です。いくつかの国がこのような能力構築プログラムを開始しており、シンガポールは、AI Government Cloud Clusterを通じて教育機関のAI能力開発のための専用のプラットフォームを提供しており、これにはGPTモデルの専用のリポジトリが含まれています(Ocampo、2023年)。
ステップ7:教育と研究におけるGenAIの長期的な影響を反映する
現在のGenAIの影響はまだ始まったばかりであり、その教育への影響はまだ完全に探求され、理解されているわけではありません。一方で、GenAIのより強力なバージョンや他のAIのクラスが継続的に開発され、展開されています。しかし、GenAIの知識の創出、伝達、検証の意味合いについて、また教育と学習、カリキュラムデザインと評価、そして研究と著作権についての重要な疑問が残っています。多くの国が教育におけるGenAIの採用の初期段階にありますが、長期的な影響はまだ理解されていません。AIの人間中心の利用を確保するために、長期的な意味合いに関する公開の議論や政策対話を緊急に行うべきです。政府、民間部門、その他のパートナーを含む包括的な議論は、規制や政策の反復的な更新のための洞察と入力を提供する役割を果たすべきです。
3.3 GenAIに関する規制: 主要な要素
すべての国は、教育や他の文脈での発展を保証するために、GenAIを適切に規制する必要があります。このセクションでは、次のキーとなる要素を中心に行動を提案します:(1) 政府の規制機関、(2) AIを活用したツールの提供者、(3) 機関の利用者、および(4) 個別の利用者。フレームワーク内の多くの要素は国際的な性質を持っていますが、すべての要素は、特定の国の教育制度や既存の一般的な規制フレームワークという地域的な文脈を考慮して検討するべきです。
3.3.1. 政府の規制機関
GenAIに関する規制の設計、調整、実施の調整には、全政府的なアプローチが必要です。以下の7つの主要な要素と行動が推奨されます:
セクター間の調整:
GenAIへの全政府的アプローチを主導し、セクター間での協力を調整する国家機関を設立する。法律の調整:
各国の関連する法律・規制の文脈との整合性を図るためのフレームワークを整える。例として、一般のデータ保護法、インターネットのセキュリティに関する規制、市民のデータのセキュリティに関する法律などの他の関連する法律との通常の慣行を整える。GenAIが提起する新しい問題に対応して、既存の規制の適切性と必要な適応を評価する。GenAIの規制とAI革新の促進のバランス:
企業、産業ガバナンス組織、教育研究機関、関連する公共機関間でのセクター間の協力を促進する。信頼性の高いモデルの共同開発を奨励する;オープンソースのエコシステムの構築を奨励し、スーパーコンピューティングリソースおよび高品質の事前トレーニングデータセットの共有を促進する;そして、セクター間でのGenAIの実用的な適用と公共の利益のための高品質なコンテンツの作成を奨励する。AIの潜在的なリスクの評価と分類:
GenAIサービスの効果、安全性、セキュリティの評価とカテゴリ化の原則とプロセスを確立する。それが展開される前やシステムのライフサイクルを通じて。GenAIが市民にもたらすリスクのレベルに基づく分類メカニズムを検討する。それらを厳格な規制(すなわち、許容できないリスクを持つAIを有効にしたアプリケーションやシステムを禁止する)、高リスクのアプリケーションの特別な規制、および高リスクとしてリストされていないアプリケーションの一般的な規制に分類する。このアプローチの一例としてEUのAI法案の草案を参照する。データプライバシーの保護:
GenAIの使用は、ほとんどの場合、ユーザーがGenAIプロバイダーと自分のデータを共有することを伴うという事実を考慮に入れる。ユーザーの個人情報の保護のための法律の策定と実施を義務付け、不法なデータの保存、プロファイリング、共有を特定し、対抗する。GenAIの使用の年齢制限の定義と施行:
ほとんどのGenAIアプリケーションは主に成人のユーザー向けに設計されています。これらのアプリケーションは、子供にとっての不適切なコンテンツへの露出や操作の潜在的なリスクを含む、多くのリスクを伴っています。これらのリスクを考慮して、反復的なGenAIアプリケーションにまだ存在する大きな不確実性を考慮に入れると、子供の権利と福祉を保護するために、一般的な目的のAI技術に対して年齢制限が強く推奨されます。現在、ChatGPTの利用規約では、ユーザーは13歳以上でなければならず、18歳未満のユーザーは親または法的後見人の許可を得てサービスを使用しなければなりません。これらの年齢制限やしきい値は、アメリカ合衆国の子供のオンラインプライバシー保護法(連邦取引委員会、1998)に由来しています。1998年に広範なソーシャルメディアの使用前と、ChatGPTのような使いやすくて強力なGenAIアプリケーションの作成の前に制定されたこの米国の法律は、組織や個人のソーシャルメディアのプロバイダーが親の許可なしに13歳未満の子供にサービスを提供することを許可しないと規定しています。多くの評論家はこのしきい値を若すぎると考えており、年齢を16歳に引き上げるための法律を提案しています。欧州連合のGDPR(2016)は、親の許可なしにソーシャルメディアのサービスを利用するためには、ユーザーは少なくとも16歳でなければならないと規定しています。さまざまなGenAIチャットボットの登場により、国々はGenAIプラットフォームとの独立した会話のための適切な年齢しきい値を慎重に検討し、公に審議する必要があります。最小のしきい値は13歳であるべきです。国々はまた、自己申告の年齢が年齢確認の適切な手段であるかどうかを決定する必要があります。国々は、GenAIプロバイダーの年齢確認の責任と、未成年の子供の独立した会話を監視する親や後見人の責任を義務付ける必要があります。国家データ所有権とデータの貧困のリスク:
国家データ所有権を保護するための立法措置を講じ、国境内で運営するGenAIのプロバイダーを規制する。市民によって生成され、商業目的で使用されているデータセットについて、このカテゴリのデータがBig Tech企業によって独占的に利用されることなく国から抜け出さないように、相互に有益な協力を促進する規制を制定する。
3.3.2. GenAIツールの提供者
GenAIの提供者には、GenAIツールの開発や提供、またはプログラマブルなアプリケーションプログラミングインターフェース(API)を通じたサービス提供など、GenAI技術を使用している組織や個人が含まれます。最も影響力のあるGenAIツールの提供者の多くは、非常に資金力のある企業です。彼らは、規制で規定されている倫理的原則を実施することを含む、デザインにおける倫理に対して責任を持ちます。以下の10の責任カテゴリが網羅されるべきです:
人間の責任:
GenAIの提供者は、核となる価値や合法的な目的への順守、知的財産の尊重、倫理的実践の維持を確保するための責任を持つとともに、偽情報や憎悪発言の拡散を防ぐべきです。信頼性のあるデータとモデル:
GenAIの提供者は、モデルや出力で使用されるデータソースと方法の信頼性と倫理性を示す必要があります。彼らは、合法的なソースを持つデータと基盤モデルを採用し、関連する知的財産法を遵守する必要があります(例:データが知的財産権で保護されている場合)。さらに、モデルが個人情報を使用する必要がある場合、その情報の収集は所有者の明示的で情報を持った同意のもとでのみ行われるべきです。差別的でないコンテンツ生成:
GenAIの提供者は、人種、国籍、性別、またはその他の保護された特性に基づいて偏ったり差別的なコンテンツを生成するGenAIシステムの設計と展開を禁止する必要があります。彼らは、GenAIが攻撃的、偏見を持った、または偽のコンテンツを生成するのを防ぐための頑丈な「ガードレール」が適切に配置されていることを確保し、ガードレールを情報提供する人々が保護されており、搾取されていないことを確保する必要があります。GenAIモデルの説明可能性と透明性:
提供者は、公共のガバナンス機関に、モデルが使用するデータのソース、規模、タイプ、前処理でのデータのラベリングルール、モデルがコンテンツやレスポンスを生成するために使用する方法やアルゴリズム、そしてGenAIツールが提供するサービスについての説明を提出すべきです。必要に応じて、ガバナンス機関が技術とデータを理解するのを支援すべきです。GenAIがエラーや議論の余地のあるレスポンスを生成する傾向は、ユーザーのために透明にすべきです。GenAIコンテンツのラベリング:
AIによるオンライン情報の合成に関する関連法または規制に従い、提供者はGenAIによって生成された論文、レポート、画像、動画を適切かつ合法的にラベル付けする必要があります。例えば、GenAIの出力は、機械によって生成されたものであることが明確にラベル付けされるべきです。セキュリティと安全性の原則:
GenAIの提供者は、GenAIシステムのライフサイクル全体で安全で堅牢で持続可能なサービスを確保すべきです。アクセスと使用の適切性に関する仕様:
GenAIの提供者は、サービスの適切な対象者や使用のシナリオや目的に関する明確な仕様を提供し、GenAIツールのユーザーが合理的で責任ある決定を下すのを支援すべきです。制約の認識と予測可能なリスクの防止:
GenAIの提供者は、システムやその出力で使用される方法の制約を明確に広告する必要があります。彼らは、入力データ、方法、および出力がユーザーに予測可能な害を及ぼさないようにする技術を開発し、発生した場合の予測不可能な害を緩和するためのプロトコルとともにこれを実施する必要があります。また、ユーザーが倫理的原則に基づいてGenAIによって生成されたコンテンツを理解し、生成されたコンテンツへの過度な依存や中毒を防ぐためのガイダンスを提供する必要があります。苦情と救済のためのメカニズム:
GenAIの提供者は、ユーザーや広く公衆からの苦情の収集のためのメカニズムやチャンネルを確立し、これらの苦情を受け入れて処理するための迅速な行動を取る必要があります。違法使用の監視と報告:
提供者は、公共のガバナンス機関と協力して、違法使用の監視と報告を容易にすべきです。これには、人々がGenAI製品を使用して違法行為や倫理的または社会的価値を侵害する方法で使用する場合、偽情報や憎悪発言の促進、スパムの生成、またはマルウェアの作成などが含まれます。
3.3.3. 機関利用者
機関利用者には、GenAIを採用するかどうかを決定し、機関内でどのタイプのGenAIツールを調達し、展開するべきかの責任を持つ、大学や学校などの教育当局や機関が含まれます。
GenAIのアルゴリズム、データ、出力の機関監査:
GenAIツールが使用するアルゴリズムやデータ、そして生成する出力をできるだけ監視するためのメカニズムを実装します。これには、定期的な監査と評価、ユーザーデータの保護、不適切なコンテンツの自動フィルタリングが含まれます。適切性の検証とユーザーの安全の保護:
GenAIシステムとアプリケーションをカテゴリ分けし、検証するための国家分類メカニズムを実装するか、機関のポリシーを構築します。機関が採用するGenAIシステムが、地域で検証された倫理的枠組みに沿っており、目標とするユーザー、特に子供や脆弱なグループに予測可能な害を与えないように確認する必要があります。長期的な影響の検討と対処:
時間の経過とともに、教育においてGenAIツールやコンテンツに頼ることは、批判的思考能力や創造性などの人間の能力の発展に深い影響を与える可能性があります。これらの潜在的な効果は評価し、対処する必要があります。年齢の適切性:
機関内でのGenAIの独立した使用に対する最低年齢制限を実施することを検討してください。
3.3.4. 個人利用者
個人利用者には、インターネットへのアクセスがあり、少なくとも1つのタイプのGenAIツールを持つ世界中のすべての人々が潜在的に含まれます。「個人利用者」という用語は、ここでは、主に正規の教育機関の個別の教師、研究者、学習者、または非正規の学習プログラムに参加する者を指します。
GenAIの使用に関する参照条件の認識:
サービス契約に署名するか、同意を表明する際、ユーザーは、契約に規定されているToRを順守する義務や、契約の背後にある法律や規則を認識している必要があります。GenAIアプリケーションの倫理的使用:
ユーザーは、GenAIを責任を持ってデプロイし、他の人々の評判や法的権利を損なう可能性のある方法でそれを悪用することを避けるべきです。違法なGenAIアプリケーションの監視と報告:
1つ以上の規制に違反するGenAIアプリケーションを発見した場合、ユーザーは政府の規制機関に通知すべきです。
4. 教育および研究における生成AIの利用に向けた政策枠組みの構築
教育および研究のための潜在的な利益を引き出すためのGenAIの規制は、適切な政策の開発を必要とします。上記の2023年の調査データによれば、AIを教育での使用に関する特定の方針や計画を採用している国はほんの一握りであることが示されています。先行するセクションでは、ビジョン、必要な手順、さまざまなステークホルダーによって取られる可能性がある主要な要素とアクションを概説しました。このセクションでは、教育および研究におけるGenAIの使用を規制するための総合的で包括的な政策枠組みを開発するために取ることができる措置を提供します。
このための出発点として、2022年のAIと教育:政策立案者のためのガイダンス(UNESCO、2022b)があります。これは、質の高い教育、社会的平等、そして包摂を促進することに焦点を当てて、AIと教育に関するセクター全体の方針の開発と実施を政府にガイドするための包括的な推奨事項のセットを提案しています。ほとんどの推奨事項は引き続き適用可能であり、教育におけるGenAIに関する特定の政策の策定をガイドするためにさらに適応させることができます。ここでは、教育および研究におけるGenAIに関する方針の計画のための次の8つの具体的な措置が提案されており、これによって既存のガイダンスを補完することができます。
4.1 包摂、平等、言語的および文化的多様性の促進
包摂の重要性は極めて高く、GenAIのライフサイクル全体で認識され、対処されるべきです。具体的には、GenAIツールが教育の基本的な課題やSDG 4のコミットメントの達成をサポートしない限り、これらのツールが包摂的にアクセス可能になっていない(性別、民族、特別な教育ニーズ、社会経済的地位、地理的位置、移動状態などに関係なく)、そしてデザインによって平等、言語的多様性、文化的多元主義を進めていない限り、これらのツールは役立たないでしょう。これを達成するために、以下の3つの政策措置が推奨されます:
インターネット接続やデータを持っていない、またはそれを手に入れることができない人々を特定し、AIアプリケーションへの公平で包摂的なアクセスの障壁を減少させるために普遍的な接続性とデジタル能力の促進を行いなさい。障害や特別なニーズを持つ学習者のためのAIを活用したツールの開発と提供のための持続可能な資金調達メカニズムを確立します。全ての年齢、場所、背景の生涯学習者をサポートするためのGenAIの使用を促進します。
データやアルゴリズムに組み込まれたジェンダーバイアス、疎外されたグループに対する差別、またはヘイトスピーチがないことを保証するためのGenAIシステムの検証基準を開発します。
GenAIシステムの包摂的な仕様を開発・実施し、大規模な教育および研究でGenAIを導入する際に、言語的および文化的な多様性を保護する制度的措置を実施します。関連する仕様は、GenAIの提供者に、GPTモデルのトレーニングにおいて特に地元や先住民の言語を含む複数の言語のデータを含めるように要求するべきです。仕様と制度的措置は、AIの提供者が少数言語の意図的または非意図的な削除や、先住民の言語の話者に対する差別を厳しく防ぐべきであり、提供者には主要言語や文化的規範を促進するシステムの停止を要求するべきです。
4.2 人間の能動性を保護する
GenAIがますます洗練されてきた中、一つの主要な危険性は、人間の能動性を損なう可能性があることです。より多くの個人ユーザーが自らの執筆や他の創造的活動をサポートするためにGenAIを使用するようになると、それに無意識に頼るようになるかもしれません。これにより、知的なスキルの発展が妨げられる可能性があります。GenAIは人間の考えを挑戦し、拡張するために使用されるかもしれませんが、人間の考えを奪ってはいけません。人間の能動性の保護と強化は、以下の7つの観点からGenAIを設計・採用する際の常に中心的な考慮事項であるべきです:
学習者にGenAIが彼らから収集する可能性のあるデータの種類、これらのデータがどのように使用され、教育やより広い生活にどのような影響を与えるかを通知する。
学習者が個人として成長し、学ぶための固有の動機を保護します。ますます洗練されたGenAIシステムを使用する文脈での研究、教育、学習への独自のアプローチに対する人間の自律性を強化します。
実際の世界の観察、実験などの経験的な実践、他の人間との議論、独立した論理的推論を通じて認知能力と社会的スキルを発展させる機会を学習者から奪うようなGenAIの使用を防止します。
十分な社会的交流を確保し、人間によって生み出された創造的な出力に適切に触れさせるとともに、学習者がGenAIに依存するか、それに依存することを防止します。
宿題や試験のプレッシャーを増やすのではなく、減少させるためにGenAIツールを使用します。
研究者、教師、学習者にGenAIに対する意見を聞き、フィードバックを使用して特定のGenAIツールを機関のスケールでどのように展開するかを決定します。学習者、教師、研究者に、AIシステム背後の方法論、出力コンテンツの正確さ、およびそれらが課す可能性のある規範や教育法を批評・疑問視するように奨励します。
高リスクな決定を下す際に、人間の説明責任をGenAIシステムに委ねることを防止します。
4.3 教育のためのGenAIシステムの監視と検証
述べられたように、GenAIの開発と展開は設計段階から倫理的であるべきです。その後、GenAIが使用されるようになったら、そのライフサイクル全体を通じて、倫理的リスク、教育的適切性と厳格さ、そして学生、教師、教室/学校関係への影響の面で慎重に監視および検証される必要があります。この点に関して、以下の5つの行動が推奨されます:
教育および研究で使用されるGenAIシステムが偏見、特にジェンダーに関する偏見を持たないか、また、多様性(ジェンダー、障害、社会経済的地位、民族文化的背景、地理的位置などの面で)を代表するデータで訓練されているかどうかを検証するための機構を構築します。
子供や他の脆弱な学習者が真に情報を提供する能力を持たない文脈での情報提供に関する複雑な問題を取り上げます。
GenAIの出力がディープフェイク画像、フェイク(不正確または偽の)ニュース、またはヘイトスピーチを含むかどうかを監査します。GenAIが不適切なコンテンツを生成していると判明した場合、機関や教育者は、問題を軽減または排除するために迅速かつ強力な対応を取る意欲と能力を持っているべきです。
教育または研究機関で公式に採用される前に、GenAIアプリケーションの厳格な倫理的検証を実施します(つまり、設計段階からの倫理アプローチを採用します)。
機関での採用に関する決定を下す前に、対象のGenAIアプリケーションが学生に予測可能な損害を与えないこと、対象学習者の年齢と能力に対して教育的に効果的であり、有効であること、そして健全な教育原則と整合していることを確認します(つまり、関連する知識の領域および予想される学習成果や価値の発展に基づいています)。
4.4 学習者のGenAI関連スキルを含むAI能力の開発
学習者のAI能力の開発は、教育およびその他の分野でのAIの安全で、倫理的で、意味のある使用にとって鍵となる要素です。しかし、UNESCOのデータによれば、2022年初頭には、わずか15か国が学校での政府が承認したAIカリキュラムを開発・実施しているか、または開発中でした(UNESCO、2022c)。GenAIの最新の発展は、AIの人間的および技術的側面の両方における適切なレベルのリテラシーを全員が達成するための緊急性をさらに強化しています。これを行うために、以下の5つの行動が今すぐ必要です:
学校教育、技術および職業教育と研修、さらには生涯学習のための政府が認可したAIカリキュラムの提供を確約します。AIカリキュラムは、私たちの生活へのAIの影響、それに関連する倫理的問題、年齢に応じたアルゴリズムとデータの理解、およびAIツール、GenAIアプリケーションを含む、適切かつ創造的な使用のためのスキルを網羅すべきです。
地域のAIの才能を開発するためのプログラムを強化するために、高等教育および研究機関を支援します。
高度なAI能力の開発においてジェンダー平等を推進し、プロフェッショナルのジェンダーバランスの取れたプールを作成します。
最新のGenAIオートメーションによって引き起こされる国内および国際的な職の移動の予測を行い、需要の予想される変化に基づいて、すべての教育レベルと生涯学習システムでの未来に備えたスキルを強化します。
新しいスキルを学び、新しい環境に適応する必要があるかもしれない高齢の労働者や市民のための特別なプログラムを提供します。
4.5 教師と研究者がGenAIを適切に使用するための能力を構築する
2023年のAI教育利用に関する政府の調査データによれば(UNESCO、2023c)、教師のためのAIに関するフレームワークやトレーニングプログラムを開発したか、または開発中であると報告した国はわずか7か国(中国、フィンランド、ジョージア、カタール、スペイン、タイ、トルコ)だけでした。シンガポールの教育省のみが、教育と学習におけるChatGPTの使用を中心にしたオンラインリポジトリの構築を報告しています。これは、ほとんどの国の教師が教育におけるAIの使用、とりわけGenAIの使用に関する整然としたトレーニングにアクセスしていないことを明確に示しています。教師をGenAIの責任ある効果的な使用に備えるために、各国は以下の4つの行動を取る必要があります:
研究者と教師が広く利用可能なGenAIツールをナビゲートし、新しいドメイン固有のAIアプリケーションの設計を指導するのを助けるために、地域のテストに基づくガイダンスを整理または調整します。
GenAIを使用する際の教師や研究者の権利と、その実践の価値を保護します。具体的には、高次の思考を促進する教師の独自の役割、人間の相互作用を整理すること、人間の価値を育てることを分析します。
教師がGenAIシステムを効果的かつ倫理的に理解し、使用するために必要な価値の方向性、知識、およびスキルを定義します。教師が教室での学習と自身の専門的な発展を促進するための特定のGenAIベースのツールを作成できるようにします。
教師が教育、学習、および彼らの専門的な学習のためにAIを理解し、使用するために必要な能力を動的に見直します。AIに関する新しい価値観、理解、およびスキルのセットを、職業内および職業前の教師のトレーニングのための能力フレームワークとプログラムに統合します。
4.6 多元的な意見とアイディアの多元的な表現を推進する
前述の通り、GenAIはプロンプトも応答も理解していません。代わりに、その応答はモデルが訓練された際に摂取したデータ(インターネットからのもの)に見られる言語パターンの確率に基づいています。その出力の根本的な問題を解決するために、現在、知識データベースや推論エンジンとGenAIを接続するなどの新しい方法が研究されています。しかし、それがどのように動作するか、そのソース素材、そして開発者の暗黙の視点のために、GenAIはその出力において支配的な世界観を再生し、少数派や多元的な意見を損ないます。そのため、人間の文明が繁栄するためには、GenAIがそれが取り組むどんなトピックに対しても知識の権威あるソースになることはできないと認識することが不可欠です。
その結果、ユーザーはGenAIの出力を批判的に見る必要があります。特に:
GenAIの役割を高速だがしばしば信頼できない情報源として理解する。前述のいくつかのプラグインやLLMベースのツールは、検証済みで最新の情報にアクセスする必要をサポートするように設計されていますが、これらが効果的であるという堅固な証拠はまだほとんどありません。
学習者や研究者にGenAIが提供する応答を批判するように奨励する。GenAIは通常、確立されたまたは標準的な意見を繰り返すだけで、多元的かつ少数派の意見およびアイディアの多元的な表現を損なうことを認識する。
学習者に、試行錯誤、経験的実験、実世界の観察から学ぶ十分な機会を提供する。
4.7 地域に関連したアプリケーションモデルをテストし、累積的な証拠基盤を構築する
GenAIモデルは、これまでにグローバルノースの情報によって支配され、グローバルサウスや先住民のコミュニティの声が不足しています。特に、合成データを活用するなどの決定的な努力により、GenAIツールが特にグローバルサウスからの地域社会の文脈やニーズに敏感になるでしょう。地域のニーズに関連するアプローチを探求しつつ、より広範に協力するために、以下の8つの行動が推奨されます:
GenAIの設計と採用が、受動的で非批判的な調達プロセスを容易にするのではなく、戦略的に計画されていることを確認する
GenAIのデザイナーに、オープンエンデッド、探索的、多様な学習オプションをターゲットとするようにインセンティブを与える。
目新しさや神話、誇大広告ではなく、教育の優先順位に従って、教育や研究にAIを適用するためのエビデンスに基づくユースケースをテストし、スケールアップする。
研究の革新を引き起こすためのGenAIの使用をガイドする。これには、計算能力、大規模データ、GenAIの出力を活用して、研究方法論の改善を情報提供および促進することが含まれます。
研究プロセスにGenAIを組み込むことの社会的および倫理的な意味合いを見直す。
証拠に基づく教育研究と方法論に基づいた具体的な基準を確立し、GenAIの効果に関する証拠基盤を構築する。これには、包括的な学習機会の提供、学習および研究の目的の達成、および言語的および文化的多様性の促進の点でのサポートを含む。
GenAIの社会的および倫理的な影響に関する証拠を強化するための反復的なステップを踏む。
大規模にAI技術を活用する際の環境コスト(例:GPTモデルのトレーニングに必要なエネルギーやリソース)を分析し、気候変動に追加することを避けるために、AIプロバイダーが達成するべき持続可能なターゲットを開発する。
4.8 長期的な影響をセクター間および学際的な方法で検討する
セクター間および学際的なアプローチは、教育および研究におけるGenAIの効果的かつ倫理的な使用のために不可欠です。さまざまな専門知識を活用し、複数のステークホルダーをまとめることによってのみ、主要な課題が迅速に特定され、長期的な負の影響を最小限に抑えながら進行中および累積的な利益を活用するために効果的に対処されます。したがって、以下の3つの行動が推奨されます:
AIプロバイダー、教育者、研究者、並びに親や学生の代表者と協力して、教育および研究のためのGenAIの潜在的なリスクを完全に活用し、軽減するためのカリキュラムフレームワークと評価方法論に関するシステム全体の調整を計画する。
教育者、研究者、学習科学者、AIエンジニア、およびその他のステークホルダーの代表者を含むセクター間および学際的な専門知識をまとめて、学習および知識生産、研究および著作権、カリキュラムおよび評価、および人間の協力および社会的ダイナミクスに関するGenAIの長期的な影響を調査する。
規制およびポリシーの反復的な更新を通知するための適時のアドバイスを提供する。
5. GenAIを教育および研究で創造的に使用するための促進
ChatGPTが初めて導入されたとき、世界中の教育者たちは、エッセイを生成する潜在能力や、学生がカンニングを助ける方法についての懸念を表明しました。最近では、世界のトップの大学を含む多くの人々や組織が「ジーニーは瓶から出てきた」と主張し、ChatGPTのようなツールはここに留まることが確定しており、教育の現場で生産的に使用することができるとしています。一方で、インターネットは現在、教育および研究でのGenAIの使用に関する提案であふれています。これには、新しいアイディアを触発する、多角的な例を生成する、授業計画やプレゼンテーションを開発する、既存の資料を要約する、画像作成を刺激するなどの用途が含まれます。新しいアイディアがほぼ毎日インターネットに登場する一方で、研究者や教育者は、教育、学習、および研究におけるGenAIの意味を正確に理解しようとしています。特に、提案された使用法の背後にいる多くの人々は、倫理的原則を適切に考慮していないか、GenAIの技術的な潜在能力に駆り立てられている可能性があり、研究者、教育者、または学習者のニーズではない。このセクションでは、教育でのGenAIの創造的な使用を促進する方法を概説します。
5.1 GenAIの責任ある創造的な使用を促進するための機関戦略
前述の通り、教育および研究機関は、教育、学習、および研究のニーズを満たすためのGenAIシステムとアプリケーションの責任あるおよび倫理的な使用を指導する適切な戦略と倫理的フレームワークを開発、実施、および検証する必要があります。これは、以下の4つの戦略を通じて達成することができます:
倫理的原則の機関的実施:
研究者、教育者、および学習者がGenAIツールを責任を持って倫理的に使用し、出力の正確性と妥当性に批判的にアプローチすることを確保します。ガイダンスとトレーニング:
研究者、教師、学習者にGenAIツールに関するガイダンスとトレーニングを提供し、データのラベリングやアルゴリズムのバイアスなどの倫理的問題を理解し、データプライバシーや知的財産に関する適切な規制を順守するようにします。GenAIプロンプトエンジニアリングの能力構築:
科目固有の知識に加えて、研究者や教師はGenAIによって生成されたプロンプトをエンジニアリングし、批判的に評価する専門知識も必要です。GenAIによって提起される課題が複雑であるため、研究者と教師はこれを行うための高品質のトレーニングとサポートを受け取る必要があります。書かれた課題におけるGenAIベースの盗作の検出:
GenAIを使用すると、学生が自分の作品として書かれていないテキストを提出することができ、新しいタイプの「盗作」となる可能性があります。GenAIの提供者は、出力に「AIによって生成されました」という透かしを付けることが求められていますが、AIによって生成された資料を識別するツールが開発されています。しかし、これらの措置やツールが効果的であるという証拠はほとんどありません。直接的な機関戦略としては、学問的な誠実さを維持し、厳格な人間による検出を通じて説明責任を強化することです。長期的な戦略として、機関や教育者は、GenAIツールが人間の学習者よりもよくできるタスクを評価するために使用されないように、書かれた課題のデザインを再考する必要があります。代わりに、GenAIや他のAIツールができないこと、つまり、共感や創造性などの人間の価値観を複雑な実際の課題に適用することを対象とする必要があります。
5.2 「人間中心で教育的に適切な対話」のアプローチ
研究者や教育者は、GenAIを使用するかどうか、およびどのように使用するかを決定する際に、人間のエージェンシーと責任ある、教育的に適切な対話をAIツールとの間で優先すべきです。これには以下の5つの考慮点が含まれます:
ツールの使用は、人間のニーズに貢献し、学習や研究をノーテックや他の代替アプローチよりも効果的にすべきです。
教育者や学習者のツールの使用は、彼らの内発的な動機に基づいているべきです。
ツールを使用するプロセスは、人間の教育者、学習者、または研究者によって制御されるべきです。
ツールの選択と組織、およびそれらが生成する内容は、学習者の年齢範囲、期待される結果、およびターゲットとなる知識(例:事実的、概念的、手続き的、またはメタ認知的)またはターゲットとなる問題(例:よく構造化されているか、構造化されていないか)に基づいて、適切であるべきです。
使用のプロセスは、GenAIとの対話的な関与や高次の思考を保証し、AIによって生成されたコンテンツの正確性、教育または研究戦略、および人間の行動への影響に関連する決定に対する人間の説明責任を確保するべきです。
5.3 教育と研究におけるGenAIの使用を共同でデザインする
教育と研究におけるGenAIの使用は、トップダウンのアプローチで強制されるべきではなく、商業的な誇張によって駆動されるべきでもありません。代わりに、その安全で効果的な使用は、教師、学習者、研究者によって共同でデザインされるべきです。さらに、異なる使用法の効果性と長期的な影響を調査するための堅実な試験と評価のプロセスが必要です。
推奨される共同デザインを促進するために、このガイダンスは、教育的に適切な対話の統合と人間のエージェンシーの優先を確固たるものとするための次の6つの視点で構成されるフレームワークを提案しています:
適切な知識の領域または問題;
期待される結果;
適切なGenAIツールと相対的な利点;
ユーザーの要件;
必要な人間の教育方法と例示的なプロンプト;そして
倫理的リスク
このセクションでは、共同デザインのプロセスが研究の慣行にどのように情報提供できるか、教育をサポートするか、基礎的なスキルの自己ペースでの習得のコーチングを提供するか、高次の思考を促進するか、特別なニーズを持つ学習者をサポートするかについての例を提供します。これらの例は、GenAIが潜在的に持つ可能性の増加するドメインの氷山の一角に過ぎません。
5.3.1 研究のための生成AI
GenAIモデルは、研究の概要に対する見解を拡大し、データの探索や文献レビューを豊かにするという潜在能力を示しています(表3を参照)。より広範な使用例が出現するかもしれませんが、新しい研究は、研究の問題の潜在的なドメインと期待される結果を定義し、効果と正確性を示し、研究を通じて現実の世界を理解するための人間のエージェンシーがAIツールの使用によって損なわれないことを確実にするために必要です。

5.3.2 教育を促進するための生成AI
一般的なGenAIプラットフォームの使用と特定の教育的GenAIツールの設計の両方が、教師の教科の理解と教育方法論に関する知識を向上させるように設計されるべきです。これには、レッスンプラン、コースパッケージ、または全体のカリキュラムの教師-AI共同設計を通じて行います。経験豊富な教師や図書館のデータに基づいて事前に訓練されたGenAI支援の会話型教師のアシスタントや「教育アシスタントの生成的ツイン」53は、一部の教育機関でテストされており、未知の可能性や未探査の倫理的リスクを持つ可能性があります。これらのモデルの実際の適用プロセスとさらなる反復は、このガイダンスで推奨されるフレームワークを通じて慎重に監査される必要があり、表4で例示されるように人間の監督によって保護されるべきです。
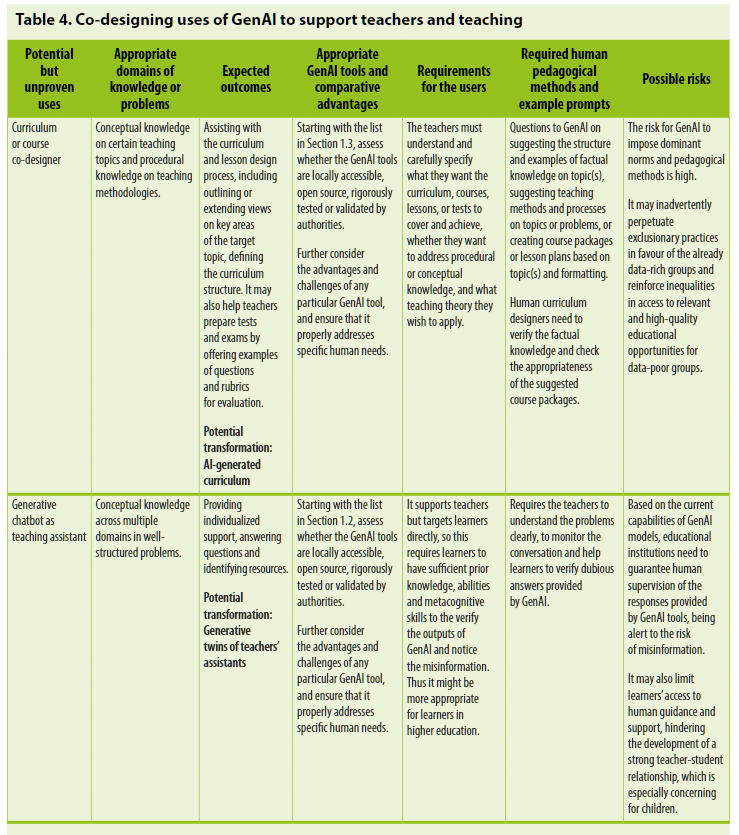
5.3.3 基礎スキルの自己ペースでの習得のための1対1のコーチとしての生成AI
学習成果を定義する際に高次の思考や創造性がますます注目されている一方で、子供たちの心理的発達や能力の進化における基礎スキルの重要性を疑うことはありません。広範な能力の中でも、これらの基礎スキルには、母国語や外国語のリスニング、発音、書き取り、基本的な計算、アート、コーディングが含まれます。'ドリルと実践'は古くさい教育法と考えるべきではなく、むしろ生成AI技術を用いてアップグレードされ、学習者が基礎スキルのリハーサルを自己ペースで行うのを促進するべきです。倫理的および教育的原則に導かれるならば、生成AIツールはこのような自己ペースでの練習のための1対1のコーチになる可能性があり、表5で示されています。

5.3.4 問い掛け型やプロジェクトベースの学習を促進するための生成AI
高次の思考や創造性を促進する目的で意図的に使用されない限り、生成AIツールは、盗作や浅い「確率的なおしゃべり」の出力を奨励する傾向があります。しかし、生成AIモデルは大規模なデータに基づいて訓練されているため、ソクラテス式の対話における対立者や、プロジェクトベースの学習における研究アシスタントとしての役割を果たす可能性があります。しかし、これらの潜在能力は、高次の思考を引き起こすことを目的とした指導/学習設計プロセスを通じてのみ活用できるものであり、表6で例示されています。

5.3.5 特別なニーズを持つ学習者をサポートする生成AI
理論的には、生成AIモデルは聴覚や視覚の障害を持つ学習者を支援する潜在能力があります。新しい取り組みとして、生成AIを活用したろう者や難聴者向けの字幕やキャプション、視覚障害者向けの生成AIによる音声解説があります。また、生成AIモデルは、テキストを音声に変換し、音声をテキストに変換することで、視覚、聴覚、言語の障害を持つ人々がコンテンツにアクセスしたり、質問したり、同僚とコミュニケーションを取るのを可能にします。しかし、この機能はまだ大規模に活用されていません。先述のUNESCOの2023年の調査によれば、教育におけるAIの使用に関する政府の調査において、中国、ヨルダン、マレーシア、カタールの4カ国のみが、政府機関が障害を持つ学習者の包括的なアクセスを支援するためのAI支援ツールを検証し、推奨していると報告しています(UNESCO, 2023c)。
また、生成AIモデルの繰り返しのトレンドとして、学習者が自分たちの言語、特に少数民族や先住民の言語を使用して学習やコミュニケーションを行うためのサポートとしての訓練が進められています。例えば、Googleの次世代LLMであるPaLM 2は、ソースとターゲットのテキストペアの形式で数百の言語をカバーする並列データで訓練されています。並列の多言語データを含めることで、モデルの多言語テキストを理解し、生成する能力をさらに向上させることを目的としています(Google, 2023b)。
リアルタイムの翻訳、言い換え、自動訂正を提供することで、生成AIツールは、少数言語を使用する学習者がアイデアを伝え、異なる言語的背景を持つ同僚との協力を強化するのを助ける潜在能力があります。しかし、これは自然に大規模には発生しません。意図的な設計があって初めて、この潜在能力を活用して疎外されたグループの声を増幅させることができます。
最後に、生成AIシステムが、会話ベースの診断を行い、心理的または社会的感情的な問題や学習の困難を特定する潜在能力があるとも提案されています。しかし、このアプローチが効果的であるか、または安全であるかに関する証拠は少なく、いかなる診断も熟練した専門家による解釈が必要です。


6. 生成AIと教育・研究の未来
生成AI技術はまだ急速に進化しており、その影響は教育と研究に深刻なものとなり、まだ完全に理解されていない可能性があります。したがって、教育と研究に対するその長期的な影響は、即時の注意とさらなる詳細なレビューが必要です。
6.1 未知の倫理的問題
ますます洗練された生成AIツールは、詳細に検討する必要がある追加の倫理的懸念を引き起こすでしょう。セクション2および3にさらに追加し、以下の少なくとも5つの視点から未知の倫理的問題を明らかにし、対処するためのより深く、より先見的な分析が必要です:
アクセスと公平性:教育における生成AIシステムは、技術や教育リソースへのアクセスにおける既存の格差を悪化させる可能性があり、不平等をさらに深化させる可能性があります。
人間のつながり:教育における生成AIシステムは、人間と人間との相互作用や学習の重要な社会的感情的側面を減少させるかもしれません。
人間の知的発展:教育における生成AIシステムは、予め決められた解決策を提供することや、可能な学習体験の範囲を狭めることで、学習者の自律性や能動性を制限する可能性があります。若い学習者の知的発展への長期的な影響を調査する必要があります。
心理的影響:人間の相互作用を模倣する生成AIシステムは、学習者に未知の心理的影響をもたらす可能性があり、その認知的発展や感情的な健康、そして操縦の可能性に関する懸念を引き起こす可能性があります。
隠れた偏見と差別:より洗練された生成AIシステムが開発・適用されるにつれて、モデルが使用するトレーニングデータや方法に基づいて、新しい偏見や差別の形態が生じる可能性があります。これにより、未知で潜在的に有害な出力が生じる可能性があります。
6.2 著作権と知的財産
生成AIの出現は、科学的、芸術的、文学的な作品がどのように作成、配布、消費されるかの方法を急速に変えています。著作権を持つ者からの許可なしに著作権のある作品を無断で複製、配布、または使用することは、彼らの排他的権利を侵害し、法的結果を招く可能性があります。例えば、生成AIモデルのトレーニングは、著作権を侵害していると非難されています。最近の事例の一つとして、AIが生成した「Drake」と「The Weeknd」(Abel Tesfaye)をフィーチャーした曲は、著作権の紛争のためにオフラインになる前に何百万人ものリスナーに届けられました(Coscarelli, 2023)。新たに出現している規制の枠組みが、モデルが使用するコンテンツの所有者の知的財産を認識し保護することを生成AI提供者に要求することを目指している一方で、生成される作品の圧倒的な量の所有権と独自性を判断することはますます困難になっています。このような追跡不能性は、創作者の権利を保護し、その知的貢献に対して公正な報酬を確保することに関する懸念を引き起こすだけでなく、生成AIツールの出力がどのように責任を持って使用されるかについての教育的文脈に課題をもたらします。これは、研究システムに深刻な影響を及ぼす可能性があります。
6.3 コンテンツと学びの情報源
生成AIツールは、教育と学習のコンテンツがどのように生成され、提供されるかの方法を変えています。将来的には、人間とAIの対話を通じて生成されるコンテンツが知識生産の主要な情報源の一つとなる可能性があります。これにより、人間が作成・検証したリソース、教科書、カリキュラムに基づく教育コンテンツへの生徒の直接的な関与がさらに低下する可能性があります。生成AIのテキストが権威的に見えることが、十分な事前知識を持たない若い学習者を誤解させ、不正確さを認識したり、効果的に疑問を持つことができない可能性があります。検証されていないコンテンツとの学習者の関与を「学習」として認識すべきかどうかも、議論の余地があります。
その結果、集約された間接情報に焦点を当てることで、実際の世界を直接知覚し、経験すること、試行錯誤から学ぶこと、経験的実験を行うこと、常識を発展させることなど、実証的な方法を通じて知識を構築する機会が減少する可能性があります。また、協力的な授業の実践を通じた知識の社会的構築と社会的価値の育成も脅かされるかもしれません。
6.4 均一化された反応と多様性・創造的な出力について
生成AIは、生成される出力が主流の視点を表現し、強化する傾向があるため、多様な物語を狭めてしまいます。このような知識の均一化は、多様性と創造的な思考を制限します。教師や生徒が生成AIツールに頼って提案を求める依存度が増すことで、反応の標準化と一致が促進され、独立した考えや自己指向の問い合わせの価値が弱まる可能性があります。書かれた文章や芸術作品の表現の均一化は、学習者の想像力、創造性、表現の代替的な視点を制限する可能性があります。
生成AIの提供者や教育者は、EdGPTがどの程度創造力、協力、批判的思考、その他の高次思考スキルを育成するために開発・利用されるかを考慮する必要があります。
6.5 評価と学習の成果を再考する
生成AIの評価への影響は、学習者が書かれた課題で不正行為をするという即座の懸念をはるかに超えています。生成AIが比較的整然とした論文やエッセイ、印象的な芸術作品を生み出し、特定の科目で知識ベースの試験に合格できるという事実を直面する必要があります。したがって、具体的に何を学び、どのような結果を目指して、学習をどのように評価し、確認するのかを再考する必要があります。
教育者、政策立案者、学習者、その他の利害関係者による批判的な議論では、以下の4つのカテゴリの学習成果を考慮する必要があります:
価値観:
技術の人間中心の設計と使用を確実にするための価値観は、デジタル時代の学習成果とその評価の再考において中心的な役割を果たしています。教育の目的を再評価する際、技術が教育と関連する方法を形成する価値観を明示的にする必要があります。この規範的な視点を通じて、学習成果及びその評価と検証が技術、特にAIの社会における急増する使用に反応して反復的に更新される必要があります。
基礎的な知識とスキル:
生成AIツールが人間よりも優れている能力の領域でも、学習者はしっかりとした基礎的な知識とスキルが必要です。基本的なリテラシー、数学的リテラシー、基本的な科学的リテラシーのスキルは、未来の教育にとって鍵となるでしょう。これらの基礎的スキルの範囲と性質は、私たちが生活するますますAIが豊富な環境を反映して定期的に再評価される必要があります。
高次の思考スキル:
学習成果には、人間とAIの協力に基づく高次の思考と問題解決をサポートするためのスキルを含める必要があります。これには、事実や概念の知識の役割を高次の思考に基づいて理解すること、AIが生成するコンテンツの批判的な評価が含まれるかもしれません。
AIと共に働くための職業的スキル:
AIが人間よりも優れている領域で、タスクユニットを自動化している場所では、人間の学習者は生成AIツールを開発、運用、作業するための新しいスキルを育む必要があります。学習成果と教育評価の再設計は、AIによって作成される新しい職業に必要な職業的スキルを反映する必要があります。
6.6 思考過程
教育と研究における生成AIの長期的な影響に関する最も基本的な視点は、まだ人間のエージェンシーと機械との補完的な関係に関するものです。主要な疑問の1つは、人間がAIに基本的な思考やスキル取得の過程を譲渡して、AIによって提供される出力に基づく高次の思考スキルに集中することが可能かどうかです。
例えば、書き込みは、思考の構造化と密接に関連していることが多いです。生成AIを使用すると、アイデアの目的、範囲、アウトラインをゼロから計画するのではなく、人間は生成AIによって提供されるよく構造化されたアウトラインから開始できるようになります。いくつかの専門家は、この方法でテキストを生成する生成AIの使用を「考えることなく書く」として特徴づけています(Chayka, 2023)。これらの新しい生成AIを使用した練習が広く採用されるようになると、書き込みのスキルの取得と評価のための確立された方法は適応する必要があります。将来の選択肢の1つは、書き込みの学習が、プロンプトの計画と構成、生成AIの出力の批判的評価、高次の思考、および生成AIのアウトラインに基づく共同執筆のスキルの構築に焦点を当てることです。
結びの言葉
人間中心のアプローチの視点からすれば、AIツールは、人間の知的能力や社会的スキルを拡張または増強するために設計されるべきであり、それらを損なう、それらと対立する、またはそれらを取って代わるものではありません。AIツールが、より包括的で持続可能な未来のための分析と行動を支援するツールとして、人間が利用可能なツールの一部としてさらに統合されることが、長い間期待されてきました。
AIが個人、機関、システムレベルでの人間と機械の協力の信頼できる一部となるためには、2021年のユネスコのAIの倫理に関する勧告に基づく人間中心のアプローチが、生成AIのような新しい技術の特定の特性に従ってさらに明確にされ、実装される必要があります。この方法だけで、生成AIが研究者、教師、学習者のための信頼できるツールとなることを保証することができます。
生成AIは教育と研究に役立つように使用されるべきですが、生成AIがこれらの領域の確立されたシステムとその基盤を変える可能性もあることを認識する必要があります。生成AIによって引き起こされる可能性のある教育と研究の変革は、人間中心のアプローチによって厳格に見直され、指導されるべきです。これによってのみ、特にAIの潜在力、および広く教育に使用される他のすべての技術のカテゴリーが、すべての人々のための包括的なデジタル未来を築くために、人間の能力を向上させることを保証することができます。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?