
集計作業のお悩みをAIで解決/第2話「単語自由回答データの集計をAIで自動化」

皆さんこんにちは、マクロミルの藤代です。連載第1話では集計作業のイントロダクションとして自由回答の概要をご紹介しました。今回はブランド名や企業名など、自由回答で集まったデータを効率的に集計するために「AI(機械学習)」の活用についてご紹介します。
1. 単語の自由回答データを集計する際のよくある悩み
アンケート調査において、例えば「おにぎりの具」のような名詞を記述してもらう場合や、「会社名・サービス」のようなブランド名・商品名・サービス名などを記述してもらう場合、その自由回答質問はアンケートの一番初めに配置することが一般的です。なぜなら、自由回答で記述する前に選択形式で回答するなどした場合、すでに目にした情報につられ自由回答内容に偏りや影響が出てしまう場合があるからです。

これらの回答をローデータから集計表の形にして定量化(数表やグラフ化)を行っていきます。

エクセルなどの表計算ソフトの場合、並び替えの機能を使うことによって似た回答をある程度まとめ、番号を入力することは出来ますが、カタカナやローマ字表記、スペースやコンマなどの記号の有無や誤字などはどうしても「表記ゆれ」の問題が出てきます。ここでの「表記ゆれ」とは、回答者の入力ミスや誤認、通称や略称を使っている、記号(カンマやスペース)など、同じ意味合いでも完全に書き方が一致しないことを指します。また、ひらがなとカタカナ・アルファベット、記号・言い回しなど様々な書かれ方をする場合はやはり人の目で見て集計をする必要があります。
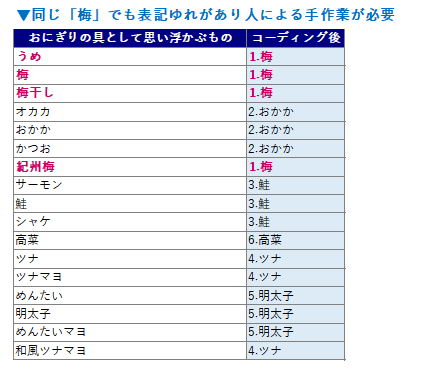
上図の「梅」を例に見ても分かるように、同じ「梅」でも様々な書かれ方があり、作業者が目で見て、番号を手入力する作業(アフターコーディング)が必要です。しかし、この作業にはどうしても時間、労力が必要となってしまいます。そうしたケースに適用できるAIを活用した「教師あり学習」を活用したマクロミルの集計技術をご紹介したいと思います。
2. AIを使ったアフターコーディング
先ほどの画像のように、人が手作業でアフターコーディングしたデータを「教師データ」としてAIに登録し、次回以降の集計に使用。コーディング済の作業データを下記のようにまとめ、AIへ登録し学習させます。AIの学習が終わった後、同じように集計する新しいデータを入手したら今度は「予測」を行います。得られた自由回答データ(集計前)を投入し、結果を予測させると以下のような結果が返ってきます。

文字の類似度を計算し、各項目(梅やおかか)に対しての類似度を求めて一番類似度のスコアの高かった内容を結果として予測させるという仕組みです。スコアで計算しているため、予測得点が低いような場合は「要注意」の印をつけここは人の目で確認した方が良い、という目星をつけておくことも可能です。
また、予測の精度を上げる取り組みも行っています。新商品の発売や会社の統廃合といった、市場や社会の動きに沿った更新を回を重ねるごとに行い、教師データを常に最新の状態に保ち、高い精度を維持しています。
3. AIを使ったアフターコーディングに適しているケース
第2話の最後に、AIを使ったアフターコーディングに適しているケースをご紹介します。
● 定点観測を行うケース
定点観測のために行う調査や事前・事後調査など、同じ質問を複数回聞くような場合などに適しています。初回は手動でアフターコーディング行い、「教師データ」を作っておく必要がありますので、1回で終わる作業ではなく、2回目、3回目…と同じ集計作業を定点的に行う際に適しています。
● 大量にデータがあるケース
大量にあるデータのブランド名など、毎回固定の選択肢にコーディングするような場合にも適しています。
例えば10万のデータがある場合、ランダムで1万のデータを抽出し手動でアフターコーディングして教師データを作り、その後残りの9万のデータをAIで予測させ効率的に集計することが可能となります。
4. 終わりに
今回ご紹介したような、AIを用いた学習・予測を、マクロミルでは自社開発するツールで行っていますので、自由回答を効率的に集計されたい場合はぜひ一度ご相談ください。
次回は文章の自由回答(感想や意見などが書かれた単語よりも記述が長い)データについて第3回、第4回に分けご紹介をしていく予定です。
【筆者紹介】

【連載 全5話】集計作業のお悩みをAIで解決