
Google Colabで衛星データを扱う(2)

具体的なコードを書いてみましたので、備忘録的にノートの記事にしてみます。
やること
夜間光データの指定
日本の領域の夜間光各年データのクリップ、データ("mean")取得
上記データのデータフレームへの変換とグラフ化
準備
準備としてまず、必要なライブラリを読み込みます
import ee
import geemap
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import geopandas as gpd
import rasterio
import glob
import jsonGoogle Earth Engineの利用については、少し学習が必要かもしれませんので、以下のような情報を参考にしてみてください。
アカウント登録ができたら、以下のようなコードでデータが使えるようになります。
ee.Authenticate()
ee.Initialize(project='hogehoge')
#'hogehoge'の部分はGEEのアカウント登録で指定したプロジェクト名
夜間光データの指定
衛星のデータは色々とあるのですが、今回は、
"Li X, Zhou Y. A Stepwise Calibration of Global DMSP/OLS Stable Nighttime Light Data (1992–2013). Remote Sensing. 2017; 9(6):637. https://doi.org/10.3390/rs9060637"
というデータを使います。
これを読み込むのが以下のコードです。
dmsp_hrm = ee.ImageCollection("projects/sat-io/open-datasets/Harmonized_NTL/dmsp")
viirs_hrm = ee.ImageCollection("projects/sat-io/open-datasets/Harmonized_NTL/viirs")日本の地図データの読み込み
以下のサイトから、"Japan"のデータを指定して、ダウンロードします。
gadm41_JPN_1は都道府県境界データ gadm41_JPN_2は基礎自治体境界データです。ファイルはシェープファイルとGeoJSONの2形式提供されています。1ファイルに全ての情報が入っているgeojsonの方がローカルのフォルダ内での整理が簡単なので、GeoJSON形式を使います。どんなデータになっているかというと、都道府県のデータの中身を以下のコードで見てみます
# Define the path to the GeoJSON file(自分の環境のパスを指定してください)
file_path = '/content/drive/MyDrive/Colab Notebooks/gadm41_JPN_1.json'
# Read the GeoJSON file
japan1 = gpd.read_file(file_path)
# Display the first few rows of the dataframe
japan1.head()
こんな感じで自治体名と'geometry'にポリゴンデータが入っています。
このポリゴンデータを使うことで、線の表示、面積の計算、ある地点がそのエリアに含まれているかどうかの判別やカウント、他のデータとの重ね合わせなどが
可能となります。
夜間光データを日本地図の領域で切り取る
ここからが結構苦労したのですが、先に読み込んである夜間光のデータ"dmsp_hrm", "viirs_hrm"は、ほぼ地球全体の1990年代後半から2021年くらいまでのデータです。
二つに分かれているのは、観測衛星そのものが違うためで、含まれているデータ(bandといいます)や、数値なども衛星によって異なります。DMSP衛星は
さらに複数の衛星で運用されていたために、同年に複数の衛星データがある、同じようなデータでも微妙に衛星間での違いもあるということで、そのような違いを調整したデータが研究者によって'harmonized nighttime light data'として公開、提供されています。
とりあえず日本地図の表示
先に読み込んだ日本地図のデータを使って、表示してみます。
ax = japan1.plot(figsize=(10, 10))
japan1.plot(ax=ax)
plt.show();
ここからはGemini AIやchatGPTなどに聞きまくって、2日がかりでなんとか変化のグラフ描画まで行きつきました。
今の日本地図のデータをコンバートします
# Convert the GeoDataFrame to a GeoJSON dictionary
geojson_dict = json.loads(japan1.to_json())
# Convert the GeoJSON dictionary to an Earth Engine Geometry
japan1_ee = ee.Geometry(geojson_dict['features'][0]['geometry'])DMSPのデータを可視化
dmsp_hrmのデータを使用(band = "b1")
日本のMean of Lightを算出する関数を定義
引数で受け取ったimage(引数ではimgと記載)に対して、ee.Reducer.mean()を適用し、imgに日付と平均値をsetして返す。
という流れで、
reduceRegion()に、reducer、geometry、scaleを与えることで、image内の値を操作します。操作の種類はsum()、max()、min()、meam()、median()などがあり、今回は光の平均値を取得したいのでmean()を適用。
# 関数の定義
def get_japan_mean(img):
mean = img.reduceRegion(reducer=ee.Reducer.mean(), geometry=japan1_ee, scale=500, maxPixels=1e9).get('b1')
return img.set('date', img.date().format()).set('mean',mean)
# ImageCollectionはImageの集まりで、その一つ一つのImageにmap関数を用いてget_japan_mean関数を適用
japan_mean = dmsp_hrm.map(get_japan_mean)
# この方法を適用したImageCollectionからdate(日付)とmeanを取り出してリスト化
nested_list = japan_mean.reduceColumns(ee.Reducer.toList(2), ['date','mean']).values().get(0)
df = pd.DataFrame(nested_list.getInfo(), columns=['date','mean'])
# ImageCollectionから、指定した列のみを抽出したい場合、reduceColumnsを利用
# reduceColumnsでは出力は辞書型になるので、ee.Reducer.toListを用いてリスト型に変換し、最後にgetInfo()で値のみを抽出
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
df実行結果は以下の通りになりました。
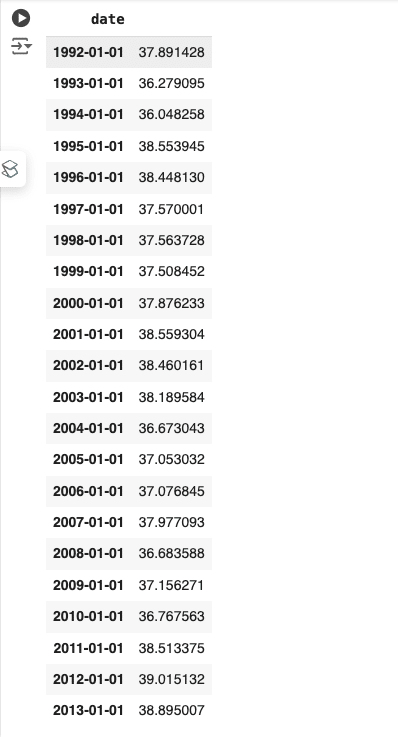
以下のコードで上記の表を折れ線グラフにします。
ちなみにこのコードもサジェスチョンのボタン押しただけで書いてくれました。
df['mean'].plot(kind='line', figsize=(8, 4), title='Japan mean light')
plt.gca().spines[['top', 'right']].set_visible(False)
なんとなくですが、バブル崩壊、その後のITバブル、リーマンショックなんかは感じとして捉えられてるような気もします。東日本震災のような短期のショックはエリアをさらに国内で区切ったり、年データではなく、月データを使うなどするとはっきり出てくるかと思います。
ただ、このDMSPデータは2012年までの運用で、その後はVIIRS衛星に変わっています。(各年データが1月1日と日付が入っていますが、実際にはその年1年間の平均値実績のデータです)
このようなデータそのものの違いも、分析対象との兼ね合いで十分に考慮して使う必要があります。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?