
- 運営しているクリエイター

#データサイエンス


AIで橋下徹さんのメルマガを解析してみた
技術書店で『はじめての自然言語解析』という本を出版しました。
自然言語解析とは、この僕らが普段使っている言語を数値に落として解析をすることです!なんだそれ?と思うかもしれませんが、様々なサービスで活用されています。
例えば、Googleの検索システムだったり、Gunosyのユーザーへのウェブ記事個別化配信であったり、スマートニュースのウェブ記事の芸能やビジネスなどのタブ分類であったり。
そん

新しいパブリックリレーションの形
前回の大統領選でFacebookのビッグデータを不正入手して、トランプ大統領を生むことに貢献したケンブリッジアナリティカ社(以下CA社)の内部告発についてまとめた記事です。
CA社は、ビッグデータを活用して人種差別主義を基盤としたムーブメントを起こそうとした事が明らかになりました。
もともと、民衆を動かす上でのPR(パブリックリレーション)は、新聞・テレビなどのマスメディアをいかに動かすか、が

あと5〜10年で弁護士の仕事は自動化されるよ
弁護士事務所の秘密保持契約書や業務委託契約書の自動化の仕事をしております。
弁護士さんが条文ごとにリスク判定をして、それをAIに学習させて同じような判定を出来るように調整する仕事です。
この仕事をしているから分かりますが、あと5〜10年で弁護士の仕事は自動化されることは間違いないと思います。
ただ自動化されることと、弁護士さんの仕事がなくなることはイコールではないと思います。
AIの精度が
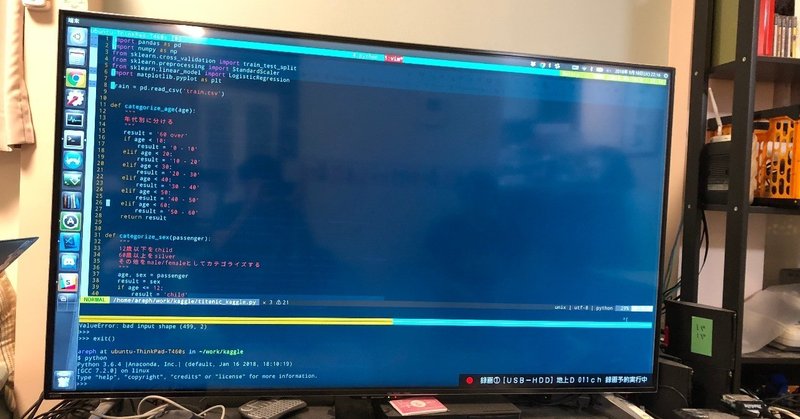
機械学習勉強会を開催しました!PART3
前回に引き続き勉強会を開催しました。
引き続き、KaggleのTitanicの問題を解いていきました。
前回データの可視化までを行ったので、可視化から分かる目的変数に影響を与えているであろう要素を選択して、その要素だけのデータセットを作成しました。
ブラックボックス・ホワイトボックス性と精度の関係をマトリックスにした下記のグラフから考えて使用するアルゴリズムを選択してもらいました。(PART
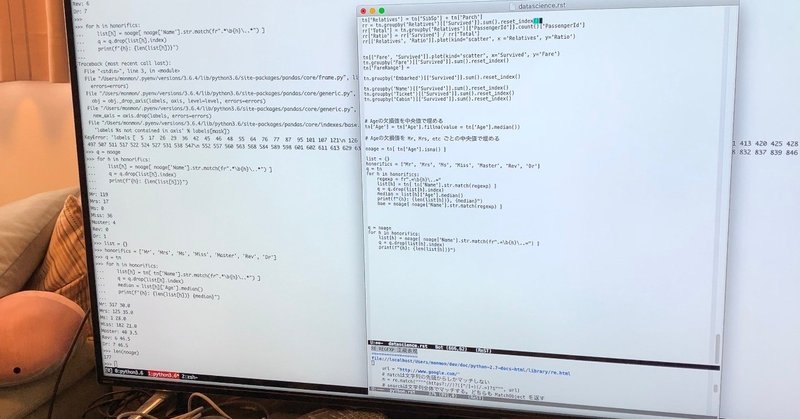
機械学習勉強会を開催しました!PART2
前回の勉強会に引き続き、機械学習勉強会を開催しました〜。
Kaggle(カグル)というデータサイエンスのコンペティションサイトがありまして、このサイトで出題される問題を実際に解いていきました。
Kaggleでは常にデータサイエンスのコンペティションが開かれており、優れた予測モデルを開発出来たら、賞金もあります。このコンペティション界隈に生息している人はKaggler(カグラー)と呼ばれ、データ

機械学習勉強会を開催しました
機械学習の勉強会を開催しました。
まず業務フォローと機械学習のモデル選択の基準について説明をしました!
それぞれのモデルについてざっくりと解説する際は下記のようなサイトURLを展開して、説明していきました。今はわかりやすいサイトがいっぱいあるので、これらを送ってして説明する方が、理解しやすいと思います。
その後は、ディープラーニングの理論を解説しました。理論を数式で理解すると時間がかかるので
数学は気合でなんとかなる
この言葉が好きです。
この言葉は、この記事で紹介した「数学を使わない数学の講義」の本の中で
出てくる言葉です。
僕みたいに文系の人間は数学アレルギーを持っている人が多いと
思うのですが、数学は気合いでなんとかなるはずなんです。
というのは、
江戸時代では、割り算は高等数学で、割り算ができるような女子は生意気で嫁の貰い手がないと言われたりしたらしいです。
ところが、明治時代に入ると割り算な