

#ChatGPT

LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
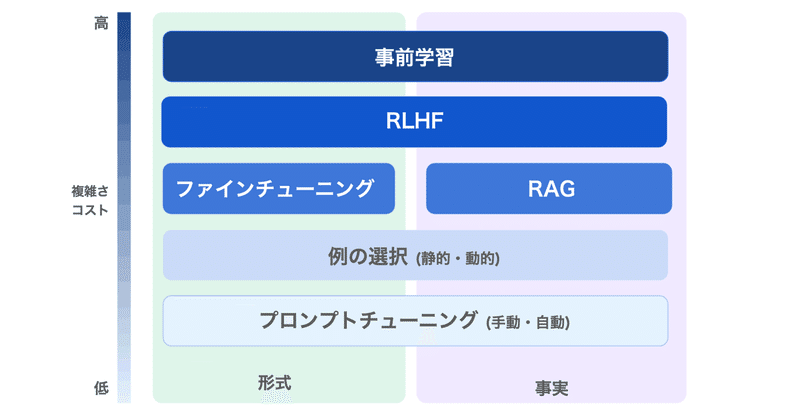
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動


airoboros: GPT-4で作成した学習データで微調整した大規模言語モデル(ほぼgpt-3.5-turbo)
Self-Instructの手法でGPT-4を使用して生成された学習データを使って、ファインチューニングされたLlaMA-13b/7bモデルが公表されていました。
モデルの概要Self-Instructの手法でgpt-4、またはgpt-3.5-turboを用いて、人間が生成したシードを含まず学習データセットを作成(OpenAIライセンスの対象)
airoboros-gpt4
airoboro





Google Colab で Cerebras-GPT を試す
「Google Colab」で「Cerebras-GPT」を試したので、まとめました。
1. Cerebras-GPT「Cerebras-GPT」は、OpenAIのGPT-3をベースにChinchilla方式で学習したモデルになります。学習時間が短く、学習コストが低く、消費電力が少ないのが特徴とのことです。
2. Colabでの実行Google Colabでの実行手順は、次のとおりです。
(






手元で動く軽量の大規模言語モデルを日本語でファインチューニングしてみました(Alpaca-LoRA)
イントロ最近、ChatGPTやGPT-4などの大規模言語モデル(LLM)が急速に注目を集めています。要約タスクや質疑応答タスクなど様々なタスクで高い性能を発揮しています。これらのモデルはビジネス分野での応用が非常に期待されており、GoogleやMicrosoftが自社サービスとの連携を進めているという報道も相次いでいます。
今回は、手元で動作する軽量な大規模言語モデル「Alpaca-LoRA」を

