
第2章「正直に回答しづらい違法行為の経験率の推定」のベイズモデリングをPyMC Ver.5 で

この記事は、テキスト「たのしいベイズモデリング2」の第2章「正直に回答しづらい違法行為の経験率の推定」のベイズモデルを用いて、PyMC Ver.5で「実験的」に実装する様子を描いた統計ドキュメンタリーです。
テキストは第2章から第4章まで「間接質問法」の各種手法で「違法行為等の経験」の調査データを用いたベイズモデリングに取り組んでいます。
この章では、「アイテムカウント法」を用いて違法行為の経験率を推論します。

テキストのモデル数式の解読は難しかったですが、なんとかPyMCモデルを構築できました。
そして「2」初の「無事の収束」と「結果の一致」を迎えることができました!
さあ、PyMCのベイズモデリングを楽しみましょう。
テキストの紹介、引用表記、シリーズまえがき、PyMC等のバージョン情報は、このリンクの記事をご参照ください。
テキストで使用するデータは、R・Stan等のサンプルスクリプトとともに、出版社サイトからダウンロードして取得できます。
サマリー
テキストの概要
執筆者 : 久保沙織 先生、豊田秀樹 先生、岡律子 先生、秋山隆 先生
モデル難易度: ★★・・・ (やさしめ)
自己評価
評点
$$
\begin{array}{c:c:c}
実装精度 & ★★★★★ & GoooD! \\
結果再現度 & ★★★★★ & 最高✨ \\
楽しさ & ★★★★★ & 楽しい! \\
\end{array}
$$

評価ポイント
テキストと同様の結果を得られました!
とてもうれしいです!
工夫・喜び・反省
PyMC実装時の苦手項目である「変数のスライスへの代入」をコード化することができました。
左辺にPyTensorの変数を持ち込まない点がポイントです。モデル数式をPyMCのモデルに当てはめることはできましたが、モデル数式の成り立ちを理解するには至りませんでした。
もう少し数式に悩んでみようと思います。

モデルの概要
テキストの調査・実験の概要
■ 間接質問法
間接質問法は、答えにくい質問の回答を得る場合に、回答者のプライバシーを守りつつ、分析に必要なデータを取得できる質問方法です。
テキストの定義をお借りします。
間接質問法とは、質問する方法を工夫し、調査者が回答結果を見ても各回答者の真の状態はわからないように配慮しつつ、集団の特性について目的とする推定値を得る方法である。
この章の調査では、大学生の違法行為の経験率を取り扱っています。
上記定義に当てはめると、「調査者が回答を見ても大学生個人の回答値が分からないように配慮しつつ、ある大学生グループ全体の推定経験率を得る方法」と言い換えられます。

■ アイテムカウント法
間接質問法の手法の1つです。
2つの質問リストをつくり、2グループの回答者を集め、1つのグループが一方の質問リスト、もう1つのグループが他方の質問リストについて、当てはまる項目数(アイテムカウント)を答えて、データを得ます。
テキストの質問リストの例示をお借りして、説明を続けます。
1.漢方薬を飲んだことがある
2.サプリメントを飲んだことがある
3.睡眠薬を飲んだことがある
4.違法ドラッグを吸引または摂取したことがある
5.タバコを吸ったことがある
例示の5つの質問項目のうち、答えにくい質問を「キー項目」と呼びます。
調査上、興味のある項目です。
上記の質問リストでは「4」がキー項目です。
一方、その他の質問項目を「マスク項目」と呼びます。
上記の質問リストでは「1、2、3、5」がマスク項目です。
ある1つのグループには、キー項目を含む5つの項目すべてを質問します。
キー項目を含む質問リストを「長リスト」と呼びます。
もう1つのグループには、キー項目を含まない4つのマスク項目だけを質問します。
キー項目を含まない質問リストを「短リスト」と呼びます。

回答者は質問リストの中から当てはまる項目の数を回答します。
例示の5項目の回答値には、1個も当てはまらないときの回答値「0個」から全ての項目が当てはまるときの回答値「5個」まで、6パターンの回答値があり得ます。
2つのグループから得た回答を次のように料理できます。
短リストの回答グループの回答値の平均値を$${\bar{y}_A}$$とします。
長リストの回答グループの回答値の平均値を$${\bar{y}_B}$$とします。
キー項目に当てはまると答える回答者の割合の推定値$${\hat{p}}$$は次のように計算できます。
$$
\hat{p}=\bar{y}_B - \bar{y}_A
$$
例示の項目で例えると、違法ドラッグ経験率を長リストの回答値の平均から短リストの回答値の平均を差し引いて推定できる、ということです。

■ 調査の概要
「違法ドラッグの使用経験」(以下、Dと略します)と「売春の経験」(以下、Pと略します)を調査項目としています。
1つのグループには「Dの短リスト」と「Pの長リスト」(キー項目含む)を組み合わせた質問リストを質問します。
もう1つのグループには「Dの長リスト」(キー項目含む)と「Pの短リスト」を組み合わせた質問リストを質問します。
大学生204名がランダムに2グループに分けられて、各グループ用の質問リストURLが配布され、Google フォームで回答する方式を取られたようです。
また分析に利用するデータは回答値ごとの回答者数です。
例えば、上記のDの長リストの場合は次のような集計表になります。
$$
\begin{array}{c|cccccc}
回答値 & 0個 & 1個 & 2個 & 3個 & 4個 & 5個 \\
\hline
回答者数 & 〇人 & 〇人 & 〇人 & 〇人 & 〇人 & 〇人 &
\end{array}
$$
ここまでの説明を図示します。

テキストのモデリング
■目的変数と関心のあるパラメータ
目的変数は短リストの回答値ごとの回答者数$${y_A}$$と長リストの回答値ごとの回答者数$${y_B}$$です。
関心のあるパラメータは経験率$${p}$$です。
■ テキストのベイズモデル
テキストおよびStanコードを基にして、私が理解できる形式に書き換えました。
数式の具体的な内容はぜひ、テキストでお確かめください。
$$
\begin{align*}
y_A &\sim \text{Multinomial}\ (n_A,\ \boldsymbol{\theta}) \\
y_B &\sim \text{Multinomial}\ (n_B,\ \boldsymbol{\theta^*}) \\
\boldsymbol{\theta} &= (\theta_0, \cdots, \theta_K)\\
\boldsymbol{\theta^*} &= (\theta^*_0, \cdots, \theta^*_{K+1})\\
\theta^*_0 &= \theta_0 - \pi_{01} \\
\theta^*_k &= \theta_k - \pi_{k1} + \pi_{(k-1)1},\ (k = 1, \cdots, K)\\
\theta^*_{K+1} &= \pi_{K1} \\
\pi_{k1} &= \pi_{k} \times p \\
p &\sim \text{Uniform}\ (0,\ 1) \\
K &= マスク項目の数 \\
\end{align*}
$$
最初の2行の尤度関数について、長リストを例に説明します。
長リストの回答値ごとの回答者数$${y_B}$$は、長リストの全回答者数$${n_B}$$を試行回数パラメータに、長リストに対する各回答値(0~K+1)の確率$${\theta_k^*}$$をベクトル化した$${\boldsymbol{\theta^*}=(\theta^*_0, \cdots, \theta^*_{K+1})}$$を確率パラメータにもつ多項分布に従います。
$${\theta_k}$$は短リストに対する各回答値(0~K+1)の確率です。
$${\theta_k}$$の合計は1になります。
$${\pi_{k1}}$$は、マスク項目に$${k}$$個当てはまってキー項目にも当てはまる同時確率であり、$${p}$$との関係で次のように表されます。
$$
p = \displaystyle \sum^K_{k=0} \pi_{k1}
$$
$${\theta^*_k}$$は$${\theta_k}$$と$${\pi_{k1}}$$を加減算して求めることができます。
$${\pi_k}$$はキー項目に当てはまるという条件付きの短リストの確率ベクトル$${\pi_{k1} / p}$$であり、合計は1になります。
■分析・分析結果
分析の仕方や分析数値はテキストの記述が正確だと思いますので、テキストの読み込みをおすすめします。
PyMCの自己流モデルの推論値を利用した分析は「PyMC実装」章の「分析」をご覧ください。

PyMC実装
Let's enjoy PyMC & Python !
準備・データ確認
1.インポート
### インポート
# ユーティリティ
import pickle
# 数値・確率計算
import pandas as pd
import numpy as np
# PyMC
import pymc as pm
import pytensor.tensor as pt
import arviz as az
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')2.データの読み込みと前処理
テキストの R スクリプト内に記述されたデータを設定します。
回答者個人別では無く、回答値ごとの回答人数(集計値)になっています。
### データの作成 Rスクリプトより
data = pd.DataFrame({'回答値': list(range(6)),
'D短リスト': (21, 33, 33, 13, 2, 0),
'D長リスト': (19, 25, 40, 18, 0, 0),
'P短リスト': (32, 60, 9, 1, 0, 0),
'P長リスト': (33, 56, 10, 1, 1, 0)})
display(data)【実行結果】
全14行です。1行が1つ標本のデータです。
データ項目は次のとおりです。
・回答値:質問項目のうち当てはまる個数
・D短リスト:Dの短リストで該当回答値を答えた回答者の数
・D長リスト:Dの長リストで該当回答値を答えた回答者の数
・P短リスト:Pの短リストで該当回答値を答えた回答者の数
・P長リスト:Pの長リストで該当回答値を答えた回答者の数

2.データの外観の確認
データの分布、ヒストグラム(横並び棒グラフ)でデータの外観を確認します。
まずはデータの分布です。
テキストの表2.1、表2.3に相当します。
### Dの回答値、Pの回答値の分布 ※表2.1、2.2に相当
# 合計(列)の追加
table = pd.concat([data, pd.DataFrame(data.sum()).T], axis=0)
# 合計(列)の文字を変更
table.iloc[6, 0] = '計'
# 行列を入れ替えてデータフレームの完成
table = table.set_index('回答値', drop=True).T
# Drugの表示
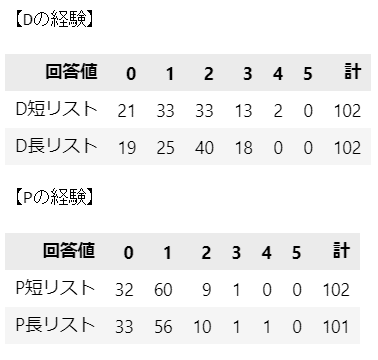
print('【Dの経験】')
display(table.iloc[:2])
# Prost.の表示
print('【Pの経験】')
display(table.iloc[2:])【実行結果】
何となく、長リストの方が回答値が大きめな感じがしたりしなかったりです。
ヒストグラム(横並び棒グラフ)で短リストと長リストの回答値の相違点を可視化しましょう。
### 横並び棒グラフの描画
## 描画域の設定
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4), sharey=True)
## Dの横並び棒グラフの描画
# 短リストの描画
ax1.bar(data['回答値']-0.2, data['D短リスト'], width=0.4, alpha=0.6,
label='短リスト')
# 長リストの描画
ax1.bar(data['回答値']+0.2, data['D長リスト'], width=0.4, color='tomato',
alpha=0.7, label='長リスト')
# 修飾
ax1.set(xlabel='回答値', ylabel='人数', title='Dのデータ収集結果')
ax1.legend()
## Pの横並び棒グラフの描画
# 短リストの描画
ax2.bar(data['回答値']-0.2, data['P短リスト'], width=0.4, alpha=0.6,
label='短リスト')
# 長リストの描画
ax2.bar(data['回答値']+0.2, data['P長リスト'], width=0.4, color='tomato',
alpha=0.7, label='長リスト')
# 修飾
ax2.set(xlabel='回答値', title='Pのデータ収集結果')
ax2.legend()
plt.tight_layout();【実行結果】
Dは長リストの方が大きな回答値の人数が多く、違法行為Dの経験ありと答えた人の存在を予感します。
一方で、Pは長リストと短リストの回答値の分布に大きな違いはない印象です。

キー項目に当てはまると答える回答者の割合の推定値$${\hat{p}}$$を計算してみましょう。
テキストの式2.1 $${\hat{p}=\hat{y}_B-\hat{y}_A}$$を用いて計算します。
### キー項目に当てはまると答える割合の推定値p_hatの算出
# 各リストの平均値を算出する関数の定義
def calc_mean(col):
return data['回答値'] @ data[col] / data[col].sum()
# 推定値の算出
print(f'Dの経験率の推定値: {calc_mean("D長リスト") - calc_mean("D短リスト"):.3f}')
print(f'Pの経験率の推定値: {calc_mean("P長リスト") - calc_mean("P短リスト"):.3f}')【実行結果】
この計算結果では、Dの経験率はかなり高いことになります。
さて、ベイズモデルはどのような経験率を推論するのでしょう!


Dのモデル構築
DとPのモデルを別個に構築します。
まずはDのモデリングです。
続いて、Dと同じモデルをP用にアレンジします。
モデルの数式表現
目指したいPyMCのモデルの雰囲気を混ぜた「なんちゃって数式」表記です。
$${K}$$はマスク項目数(短リストの項目数)です。
$${n_{short}}$$は短リストの回答者数、$${n_{long}}$$は長リストの回答者数です。
$$
\begin{align*}
p &\sim \text{Uniform}\ (\text{lower}=0,\ \text{upper}=1) \\
\\
\pi &\sim \text{Dirichlet}\ (\text{a}=\text{np.ones}(K+1)) \\
\pi_1 &= \pi \times p \\
\\
\theta &\sim \text{Dirichlet}\ (\text{a}=\text{np.ones}(K+1)) \\
\\
\theta^*_{tmp}[0] &= \theta[0] - \pi_1[0]\\
\theta^*_{tmp}[i] &= \theta[i] - \pi_1[i] + \pi_1[i-1]\ \text{for}\ i\ \text{in range(1, K+1)}\\
\theta^*_{tmp}[K+1] &= 1 - \text{sum}(\theta^*[0, K+1]) \\
\theta^* &= \text{pt.stack}[\theta^*_{tmp}]\\
\\
likelihood_{short} &\sim \text{Multinomial}\ (\text{n}=n_{short},\ \text{p}=\theta)\\
likelihood_{long} &\sim \text{Multinomial}\ (\text{n}=n_{long},\ \text{p}=\theta^*)\\
\end{align*}
$$

1.モデルの定義
数式表現を実直にモデル記述します。
### モデルの定義
## 初期値設定
# マスク項目数 K
K = data['回答値'].max() - 1
# 回答値ごとの人数
short = data.iloc[0:K+1, 1].values
long = data['D長リスト'].values
# 回答者数
n_short = short.sum()
n_long = long.sum()
## モデルの定義
with pm.Model() as model1:
### coordの定義
model1.add_coord('dataShort', values=list(range(K+1)), mutable=True)
model1.add_coord('dataLong', values=list(range(K+2)), mutable=True)
### dataの定義
# 回答値ごとの人数
yShort = pm.ConstantData('yShort', value=short, dims='dataShort')
yLong = pm.ConstantData('yLong', value=long, dims='dataLong')
### 事前分布
# p:キー項目に当てはまる確率
p = pm.Uniform('p', lower=0, upper=1)
# θ:短リストに当てはまる項目がk個である確率(k=1,2,…,K)
theta = pm.Dirichlet('theta', a=np.ones(K+1), dims='dataShort')
# π:キー項目に当てはまるという条件付きの短リストの確率ベクトル
pi = pm.Dirichlet('pi0', a=np.ones(K+1), dims='dataShort')
# π_k1:マスク項目にk個当てはまりキー項目にも当てはまる同時確率
pi1 = pm.Deterministic('pi1', pi * p, dims='dataShort')
## θ*:長リストに当てはまる項目がk個である確率(k=1,2,…,K,K+1)
# 長リストの項目数K+1
num_long = K + 1
# 一時変数(リスト)の初期化
thetaAsterTmp = [0] * (num_long + 1)
# 要素0番目の算出
thetaAsterTmp[0] = theta[0] - pi1[0]
# 要素1~K番目の算出
for i in range(1, num_long):
thetaAsterTmp[i] = theta[i] - pi1[i] + pi1[i-1]
# 要素K+1番目の算出
thetaAsterTmp[num_long] = 1 - sum(thetaAsterTmp[0:num_long])
# 一時変数をθ*へ代入
thetaAster = pm.Deterministic('thetaAster', pt.stack(thetaAsterTmp),
dims='dataLong')
### 尤度:多項分布
likeliShort = pm.Multinomial('likeliShort', n=n_short, p=theta,
observed=yShort, dims='dataShort')
likeliLong = pm.Multinomial('likeliLong', n=n_long, p=thetaAster,
observed=yLong, dims='dataLong')【モデル注釈】
coordの定義
座標に名前を付けたり、その座標が取りうる値を設定できます。
今回は次の2つを設定しました。短リストの行の座標:名前「dataShort」、値「行インデックス」
長リストの行の座標:名前「dataLong」、値「行インデックス」
dataの定義
目的変数である短リストの回答値ごとの回答者数$${yShort}$$と長リストの回答値ごとの回答者数$${yLong}$$を設定しました。パラメータの事前分布
キー項目に当てはまる確率$${p}$$はテキストどおり、区間$${[0,1]}$$の一様分布
合計が1の確率ベクトルに該当する次の2つの変数はディリクレ分布に従います。
短リストに当てはまる項目が$${k}$$個である確率$${\theta}$$
キー項目に当てはまるという条件付きの短リストの確率ベクトル$${\pi}$$
尤度
リストの回答者数を試行回数パラメータ、当てはまる項目が$${k}$$個である確率を確率パラメータとする多項分布です。
2.モデルの外観の確認
# モデルの表示
model1【実行結果】
割とすっきりしたモデルですね。

# モデルの可視化
pm.model_to_graphviz(model2)【実行結果】
短リストの要素数(回答値の種類)は5です。
多くのパラメータは5つの要素で構成されていることがこの図からわかります。


3.事後分布からのサンプリング
乱数生成数はテキストよりも少なくしています。
nuts_sampler='numpyro'とすることで、numpyroをNUTSサンプラーに利用できます。
処理時間はおよそ2分45秒でした。
### 事後分布からのサンプリング ※NUTSサンプラーにnumpyroを使用 2分45秒
# テキスト:iter=21000, warmup=1000, chains=10
with model1:
idata1 = pm.sample(draws=20000, tune=1000, chains=4, target_accept=0.8,
nuts_sampler='numpyro', random_seed=1234)【実行結果】
4.サンプリングデータの確認
$${\hat{R}}$$、事後分布の要約統計量、トレースプロットを確認します。
事後分布の収束確認はテキストにならって$${\hat{R} \leq 1.1}$$としています。
### r_hat>1.1の確認
# 設定
idata_in = idata1 # idata名
threshold = 1.01 # しきい値
# しきい値を超えるR_hatの個数を表示
print((az.rhat(idata_in) > threshold).sum())【実行結果】
ひとまず、しきい値を$${\hat{R} > 1.01}$$で確認しました。
$${\hat{R} > 1.01}$$のパラメータは「0」件です。
全てのパラメータが$${\hat{R} \leq 1.01}$$であることを確認できました。

ざっくり事後分布サンプリングデータの要約統計量とトレースプロットを確認します。
### 推論データの要約統計情報の表示
pm.summary(idata1, hdi_prob=0.95, round_to=3)【実行結果】
経験率$${p}$$の平均値(テキストのEAP)は0.067です。

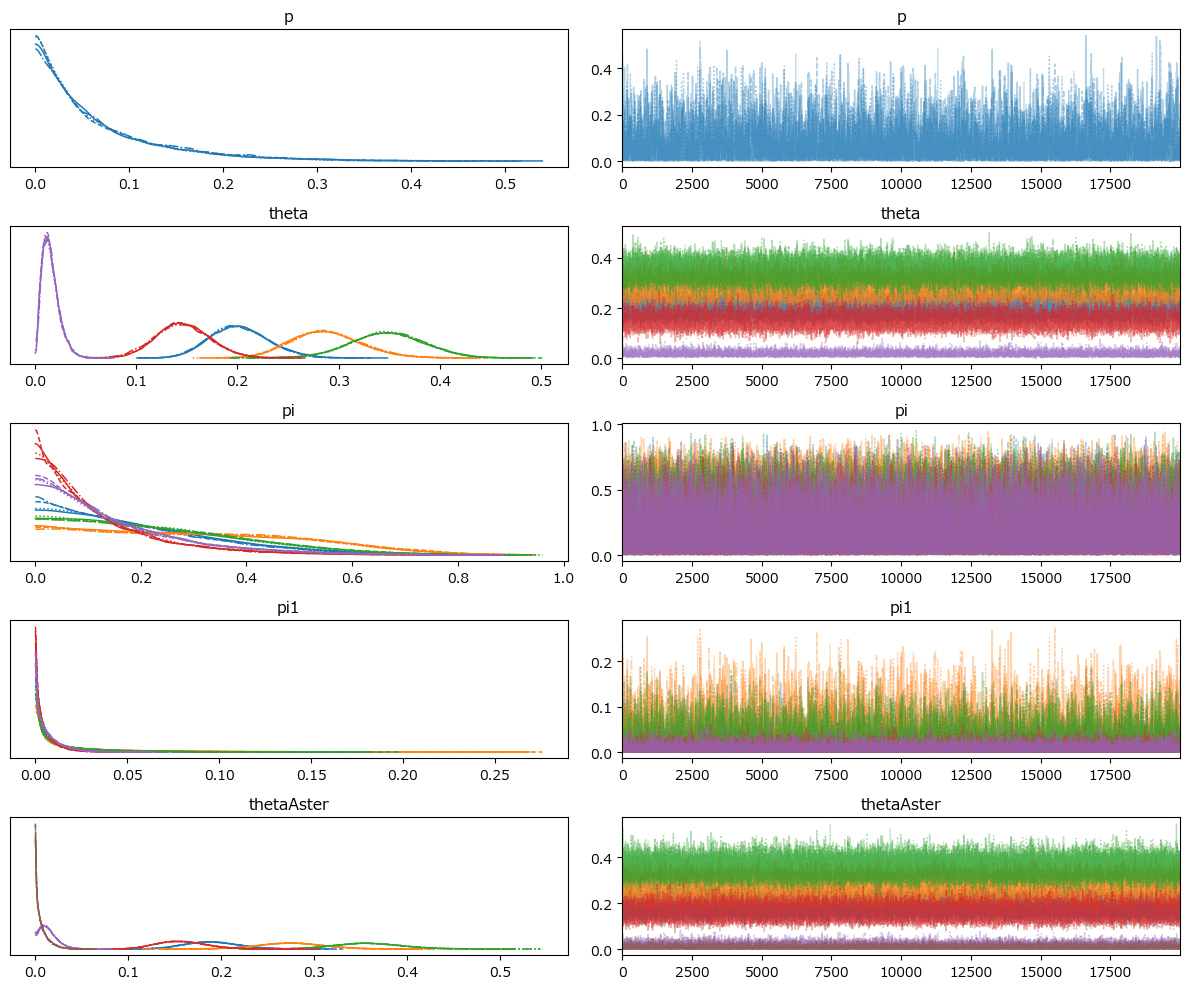
### トレースプロットの表示 ※発散している
pm.plot_trace(idata1, divergences=None)
plt.tight_layout();【実行結果】
右のグラフはまんべんなく描画されていて、収束している感じがします。
なお、引数 divergences=None を指定したので見えていないのですが、実は、発散(divergences)を示すバーコードが大量に発生しています(汗)
5.推論データ(idata)の保存
推論データを再利用する場合に備えてファイルに保存しましょう。
idataをpickleで保存します。
### idataの保存 pickle
file = r'idata1_ch02.pkl'
with open(file, 'wb') as f:
pickle.dump(idata1, f)読み込みコードは次のとおりです。
### idataの読み込み pickle
file = r'idata1_ch02.pkl'
with open(file, 'rb') as f:
idata1_load = pickle.load(f)
Pのモデル構築
続いて、Dのモデルを転用してP用にアレンジします。
Dと異なるのは「初期値設定」の「回答値ごとの人数」の設定のみです。
モデルの数式表現
Dと同様ですので、記載を省略します。
1.モデルの定義
### モデルの定義
## 初期値設定
# マスク項目数 K
K = data['回答値'].max() - 1
# 回答値ごとの人数
short = data.iloc[0:K+1, 3].values
long = data['P長リスト'].values
# 回答者数
n_short = short.sum()
n_long = long.sum()
## モデルの定義
with pm.Model() as model2:
### coordの定義
model2.add_coord('dataShort', values=list(range(K+1)), mutable=True)
model2.add_coord('dataLong', values=list(range(K+2)), mutable=True)
### dataの定義
# 回答値ごとの人数
yShort = pm.ConstantData('yShort', value=short, dims='dataShort')
yLong = pm.ConstantData('yLong', value=long, dims='dataLong')
### 事前分布
# p:キー項目に当てはまる確率
p = pm.Uniform('p', lower=0, upper=1)
# θ:短リストに当てはまる項目がk個である確率(k=1,2,…,K)
theta = pm.Dirichlet('theta', a=np.ones(K+1), dims='dataShort')
# π:キー項目に当てはまるという条件付きの短リストの確率ベクトル
pi = pm.Dirichlet('pi', a=np.ones(K+1), dims='dataShort')
# π_k1:マスク項目にk個当てはまりキー項目にも当てはまる同時確率
pi1 = pm.Deterministic('pi1', pi * p, dims='dataShort')
## θ*:長リストに当てはまる項目がk個である確率(k=1,2,…,K,K+1)
# 長リストの項目数K+1
num_long = K + 1
# 一時変数(リスト)の初期化
thetaAsterTmp = [0] * (num_long + 1)
# 要素0番目の算出
thetaAsterTmp[0] = theta[0] - pi1[0]
# 要素1~K番目の算出
for i in range(1, num_long):
thetaAsterTmp[i] = theta[i] - pi1[i] + pi1[i-1]
# 要素K+1番目の算出
thetaAsterTmp[num_long] = 1 - sum(thetaAsterTmp[0:num_long])
# 一時変数をθ*へ代入
thetaAster = pm.Deterministic('thetaAster', pt.stack(thetaAsterTmp),
dims='dataLong')
### 尤度:多項分布
likeliShort = pm.Multinomial('likeliShort', n=n_short, p=theta,
observed=yShort, dims='dataShort')
likeliLong = pm.Multinomial('likeliLong', n=n_long, p=thetaAster,
observed=yLong, dims='dataLong')【モデル注釈】省略
2.モデルの外観の確認
# モデルの表示
model2【実行結果】
Dと同じです。

# モデルの可視化
pm.model_to_graphviz(model2)【実行結果】
Dと同じです。


3.事後分布からのサンプリング
乱数生成数はテキストよりも少なくしています。
nuts_sampler='numpyro'とすることで、numpyroをNUTSサンプラーに利用できます。
処理時間はおよそ40秒でした。
### 事後分布からのサンプリング ※NUTSサンプラーにnumpyroを使用 40秒
# テキスト:iter=21000, warmup=1000, chains=10
with model2:
idata2 = pm.sample(draws=20000, tune=1000, chains=4, target_accept=0.8,
nuts_sampler='numpyro', random_seed=1234)【実行結果】

4.サンプリングデータの確認
$${\hat{R}}$$、事後分布の要約統計量、トレースプロットを確認します。
事後分布の収束確認はテキストにならって$${\hat{R} \leq 1.1}$$としています。
### r_hat>1.1の確認
# 設定
idata_in = idata2 # idata名
threshold = 1.01 # しきい値
# しきい値を超えるR_hatの個数を表示
print((az.rhat(idata_in) > threshold).sum())【実行結果】
ひとまず、しきい値を$${\hat{R} > 1.01}$$で確認しました。
$${\hat{R} > 1.01}$$のパラメータは「0」件です。
全てのパラメータが$${\hat{R} \leq 1.01}$$であることを確認できました。

ざっくり事後分布サンプリングデータの要約統計量とトレースプロットを確認します。
### 推論データの要約統計情報の表示
pm.summary(idata2, hdi_prob=0.95, round_to=3)【実行結果】
経験率$${p}$$の平均値(テキストのEAP)は0.037です。

### トレースプロットの表示 ※発散している
pm.plot_trace(idata2, divergences=None)
plt.tight_layout();【実行結果】
右のグラフはまんべんなく描画されていて、収束している感じがします。
なお、引数 divergences=None を指定したので見えていないのですが、こちらも、発散(divergences)を示すバーコードが大量に発生しています(汗)

5.推論データ(idata)の保存
推論データを再利用する場合に備えてファイルに保存しましょう。
idataをpickleで保存します。
### idataの保存 pickle
file = r'idata2_ch02.pkl'
with open(file, 'wb') as f:
pickle.dump(idata2, f)読み込みコードは次のとおりです。
### idataの読み込み pickle
file = r'idata2_ch02.pkl'
with open(file, 'rb') as f:
idata2_load = pickle.load(f)
分析
分析~テキストにならって
経験率$${p}$$の事後分布をヒストグラムで描画します。
テキストの図2.2、図2.3に相当します。
### 経験率pの事後分布のヒストグラム描画 ※図2.2、2.3に相当
# 描画域の設定
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 3), sharey=True)
# Dの経験率の描画
pm.plot_dist(idata1.posterior.p, kind='hist', figsize=(6, 4),
hist_kwargs={'bins': 30}, ax=ax1)
ax1.set(xticks=(np.linspace(0, 0.5, 6)), xlabel='p', ylabel='Density',
title='Dの経験率pの事後分布')
# Pの経験率の描画
pm.plot_dist(idata2.posterior.p, kind='hist', figsize=(6, 4),
hist_kwargs={'bins': 30}, ax=ax2)
ax2.set(xticks=(np.linspace(0, 0.5, 6)), xlabel='p', ylabel='Density',
title='Pの経験率pの事後分布')
plt.tight_layout()
plt.show()【実行結果】
MCMCサンプリング数がテキストと異なる(少ない)ので、密度(Density)を表示しました。
Dの経験率もPの経験率も0に偏っていて、裾が右側にずれた(正に歪んだ)分布になっています。

事後分布の統計量を確認します。
テキストの表2.2に相当します。なおMAPは省略しました。
### 経験率pの点推定と区間推定の表示 ※表2.2に相当 MAPの算出は省略
## 統計量計算関数の定義
def calc_stats(x):
ci = np.quantile(x, q=[0.025, 0.975]) # 95%CI
hdi = az.hdi(x, hdi_prob=0.95) # 95%HDI
return np.array([np.median(x), np.mean(x), np.std(x), ci[0], ci[1],
hdi[0], hdi[1]])
## 点推定値の算出
# 各リストの回答平均値の算出
means = [np.average(data.回答値, weights=data[col]) for col in data.columns[1:]]
# p_hatの算出
phat = np.array([means[1]-means[0], means[3]-means[2]]).reshape(-1, 1)
## DとPに関するpの事後統計値の算出
d_stats = calc_stats(idata1.posterior.p.data.flatten())
p_stats = calc_stats(idata2.posterior.p.data.flatten())
## 表示用のデータフレームの作成
# 点推定、事後統計量の各データを結合
stats_array = np.vstack([d_stats, p_stats]) # 2つの事後統計量を行方向に結合
stats_array = np.hstack([phat, stats_array]) # 点推定と事後統計量を列方向に結合
# データフレーム化
stats_df = pd.DataFrame(stats_array,
index=['D経験', 'P経験'],
columns=['p_hat', 'MED', 'EAP', 'post.sd',
'CI下限', 'CI上限', 'HDI下限', 'HDI上限'])
# データフレームの表示
display(stats_df.round(3))【実行結果】
テキストとほぼ同じ結果を得られました。
95%CI区間や95%HDI区間がテキストよりも広いのはMCMCサンプリングデータの個数が少ないからかもしれません。


【分析】
ベイズモデルによる2つの経験率の推定値は次のようになりました。
Dの経験率は平均値$${6.7\%}$$、95%信用区間は$${[0.1\%, 25.5\%]}$$、95%HDIは$${[0.0\%, 21.0\%]}$$です。
Pの経験率は平均値$${3.7\%}$$、95%信用区間は$${[0.1\%, 13.9\%]}$$、95%HDIは$${[0.0\%, 11.2\%]}$$です。
$${\hat{p}}$$は、従来のアイテムカウント法で経験率として解釈されていた値です。テキストの式2.1で算出される値です。
$${\hat{p}}$$とベイズによる推定値の違いを確認します。
Dの場合、$${\hat{p}=12.7\%}$$に対して、ベイズ推論による経験率は、平均値$${=6.7\%}$$、中央値$${=4.4\%}$$であり、かなり小さな値・経験率が低い結果となっています。
もしかすると、$${\hat{p}}$$に基づく経験率は過大評価されているのかもしれません。
一方、Pの場合、$${\hat{p}=2.8\%}$$に対して、ベイズ推論による経験率は、平均値$${=3.7\%}$$、中央値$${=2.6\%}$$であり、両者は近い結果となっています。
なお、DおよびPの$${\hat{p}}$$は、DまたはPの95%信用区間・95%HDIに収まっています。
以上で第2章は終了です。
おわりに
数式とプログラミング
モデリング面に関するこの章の特徴は、テキストの「数式モデル」とStanの「実装モデル」が直感的に紐づけにくかったことです。
私には、数式モデルと実装モデルの関係性をなかなか掴むことができず、とても混乱しました。
例えば次の点です。
尤度関数について、実装モデルは単リストと長リストの2つの関数を別々に定義していますが、テキストでは1つの数式(式2.14)でまとめられています。
$${\pi_1}$$について、数式モデルから実装モデルに転換する際、「言葉によるモデル説明」の理解が難しかったです。
特に、確率ベクトル$${\pi}$$について、数式モデルでは明示されておらず(同時確率$${\pi_{k0}}$$と混同しました)、テキストの文章にて「キー項目に当てはまるという条件付きの短リストの確率ベクトル$$\pi_1/p$$」が数式なしに突然出現します。一方、実装モデルでは「pi」がひょっこり定義されています。
この章は(おそらく)学術的な視点で数式モデルをメインに取り扱われており、実装モデルは別次元の位置づけに感じられました。
テキスト全体における数式モデルと実装モデルの関係性記述は、たぶん、各章の個性である「プログラミングへの意識の向け方」によって、弱くなったり強くなったりするものなのだ、と読み取りました。
個人的には数式モデル(業務要件)と実装モデル(プログラミング)を整然と結びつけてくれるプログラミング寄りの章が好みです(甘い)

シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?