
シリーズPython② PyCaret事始め

はじめに
とあるオンライン講座で利用したデータを見ていて、ふと「そうだ、PyCaretしよう」と思い立ちました。
PyCaretは機械学習の作業を自動化するPythonのライブラリです。
この記事は「はじめてのPyCaret」を取り扱います。
PyCaretやAutoMLに興味をお持ちの方、学習中の方などの参考になれば幸いです。
1.PyCaretって?
PyCaretは、機械学習における前処理、モデルの比較、ハイパーパラメータのチューニング、評価、予測などの作業を「短いコードで実行できる」Pythonのライブラリです。
「Auto ML」と呼ばれる自動機械学習ツールのひとつです。
こちらはPyCaretのWebサイト。クールなダークパープルのデザインがカッコいいです!
ざっくり、PyCaretは「Pythonで機械学習を簡単に実行できる魔法」のようなツールなのです。

2.機械学習を始める前に
(1)PyCaretのインストール
私のPython使用環境は「Windows上でAnaconda」が管理しています。
PyCaretは裏で別のライブラリ(例えばscikit-learn)を使っています。
問題は「これらの別ライブラリのバージョンとPyCaretインストールバージョンの依存関係(つまり好き嫌い)が厄介なこと」なのです。
そこでPyCaret専用環境を作りました。
作り方はPyCaretのWebサイトに掲載されています。
①まず「Environment」の項に掲載のコードのうち、最初の3つを掲載通りに実行します。このコードにはPyCaretのインストールも含まれています。
コードの「yourenvname」の部分に「環境名」を指定する必要があります。
# create a conda environment
conda create --name yourenvname python=3.8
# activate conda environment
conda activate yourenvname
# install pycaret
pip install pycaret②次にJupyter Notebookで動かせるように設定します。
「Anaconda Navigator」を用いて、作成した環境にJupyter Notebookをインストールします。
こちらのサイトの「(5)新規作成した仮想環境にJupyter Notebookをインストール」に詳しく紹介されています。
参考にさせていただきました!ありがとうございます!
これでPyCaretのインストールが完了です。
第一段階クリアです。お疲れ様でした。

(2)PyCaret環境でJupyter Notebookを起動
正常にインストールできたか確認します。
Anaconda Promptで操作します。
スタートメニュー > すべてのアプリ > Anaconda3 > Anaconda Prompt
(他にスマートな方法があるかもしれません。。。)
①PyCaret環境を起動
conda active PyCaret環境名②Jupyter Notebookを起動
jupyter notebook(3)PyCaretを正常に動かすための追加作業
PyCaretの「evaluate_model」を正しく動かすために、「ipywidgets」をPyCaret環境にインストールします。
また、evaluate_modelの実行時に次のエラーが出る場合には、対処しましょう。
【エラー内容】
・真っ白なグラフが表示されたまま
・エラーメッセージ「draw() got an unexpected keyword argument 'ax'」
【対処】
・schemdrawのインストール
(とあるサイトでは「pip install "schemdraw<0.16"」との記載あり)
準備完了です!
さあ!PyCaretの機械学習の旅へ!

3.機械学習の実行
(1)使用データ
kaggleのデータセット「FitBit Fitness Tracker Data」を利用します。
①kaggleにアクセスして次のDatasetsサイトを開きます。
②Data Explorerから「dailyActivity_merged.csv」をローカルにダウンロードします。
(2)機械学習のタスク
今回取り組む機械学習タスクは「歩数・歩行距離・歩行時間で消費カロリーを予測する回帰」です。
データ「dailyActivity_merged.csv」の項目「Calories」を目的変数にします。
データに含まれる特徴量には、歩行時の運動の強さ(アクティブ、ライトなど)に応じた歩行距離、歩行時間が含まれています。
(3)機械学習の詳細ステップ
ではでは、短いコードで実行する機械学習のお披露目です!
この記事は、PyCaretの2つの方法のうち「Functional API」を使用して、コードを書いています(もうひとつの方法は「OOP API」です)。
①PyCaretのバージョン情報(オプション)
バージョン 3.0.0 をインストールしました。
import pycaret
pycaret.__version__
出力イメージ
'3.0.0'②前処理
ライブラリのインポート、データ読み込み、前処理を行います。
■インポート
回帰タスク用の pycaret.regression をインポートします。
from pycaret.regression import *
import pandas as pd■PandasでデータフレームにCSVデータを読み込み
# Pandasでload dailyActivity_merged.csvを読み込み
data_folder = './Fitabase Data 4.12.16-5.12.16/'
data = pd.read_csv(data_folder+'dailyActivity_merged.csv')
data.head()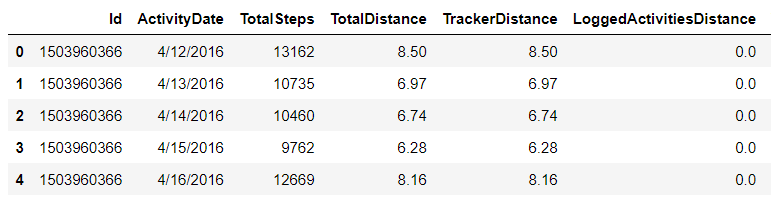
■前処理
PyCaretの「setup()」の一行でいわゆる前処理を行ってくれます。
欠損値補完、エンコーディング、訓練・テストデータの分割、K-Fold交差検証の設定などなどを実行しているみたいです。
なお特徴量エンジニアリングは実施していません。
# 前処理
# target: 目的変数、ignore_features: 特徴量から除外する変数リスト
setup(data=data, target='Calories', ignore_features=['Id'], session_id=123)
③複数モデルの比較
PyCaretの「compare_models()」の一行で複数モデルの評価を実施して、bestスコアのモデルを教えてくれます。
処理に少々時間がかかります。
best = compare_models()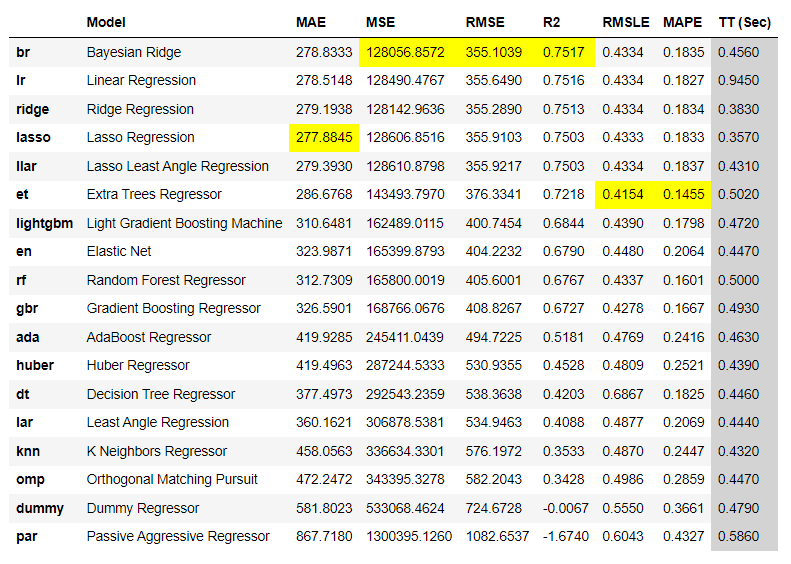
ベストは「Baysian Ridge」みたいです(なんか渋いな)。
ちなみに、前処理のsetupで除外した(ignore_features=['Id'])変数「Id」を除外しないで実行すると、ベストは「Gradient Boosting Regressor」になりました。
bestに選ばれたモデルのパラメータは次のコードで確認できます。
print(best)
出力イメージ
BayesianRidge()④ハイパーパラメータのチューニング
PyCaretの「tune_model()」の一行でハイパーパラメータのチューニングを実施してくれます。
10Fold交差検証ですね。
tuned_model = tune_model(best)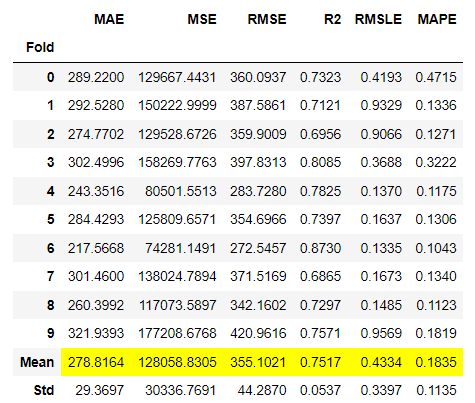
チューニング前の方がスコアが良かったようです。
Fitting 10 folds for each of 10 candidates, totalling 100 fits Original model was better than the tuned model, hence it will be returned. NOTE: The display metrics are for the tuned model (not the original one).
【DeepL翻訳】
10個の候補に対してそれぞれ10個のフォールドをフィットさせ、合計100個のフィットを行う。
オリジナルモデルの方がチューニングモデルより優れていたため、返却します。
注:表示指標はチューニングモデルのものです(オリジナルモデルではありません)。
チューニング後のモデルのパラメータは次のコードで確認できます。
print(tuned_model)
出力イメージ
BayesianRidge()⑤モデルの評価
これもPyCaretの「evaluate_model()」の一行。
さまざまなグラフィックでモデルの評価を支援してくれます。
処理に少々時間がかかります。
evaluate_model(tuned_model)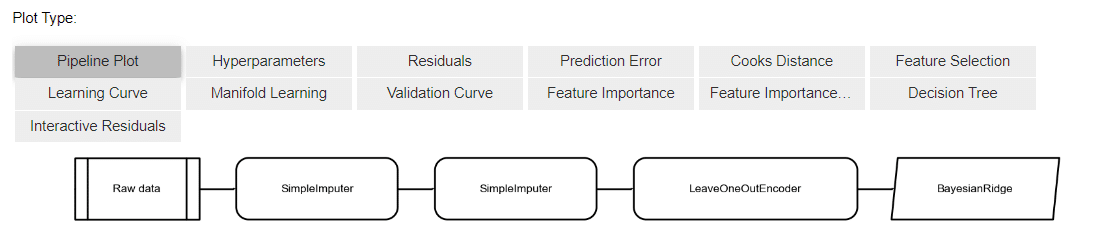
実行後に表示されるグラフィックはパイプライン。処理過程をフロー図で表示しています。
上に並ぶタイルをクリックすると該当するグラフを表示できます。
■Hyperparameters(ハイパーパラメータの値一覧)

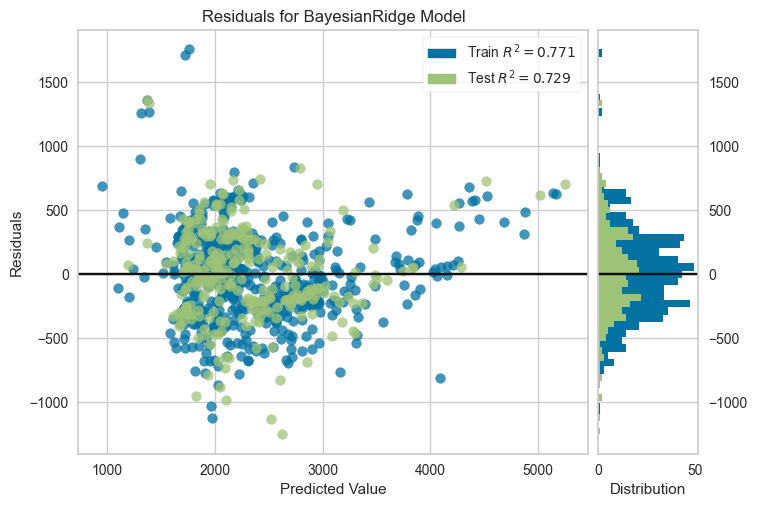
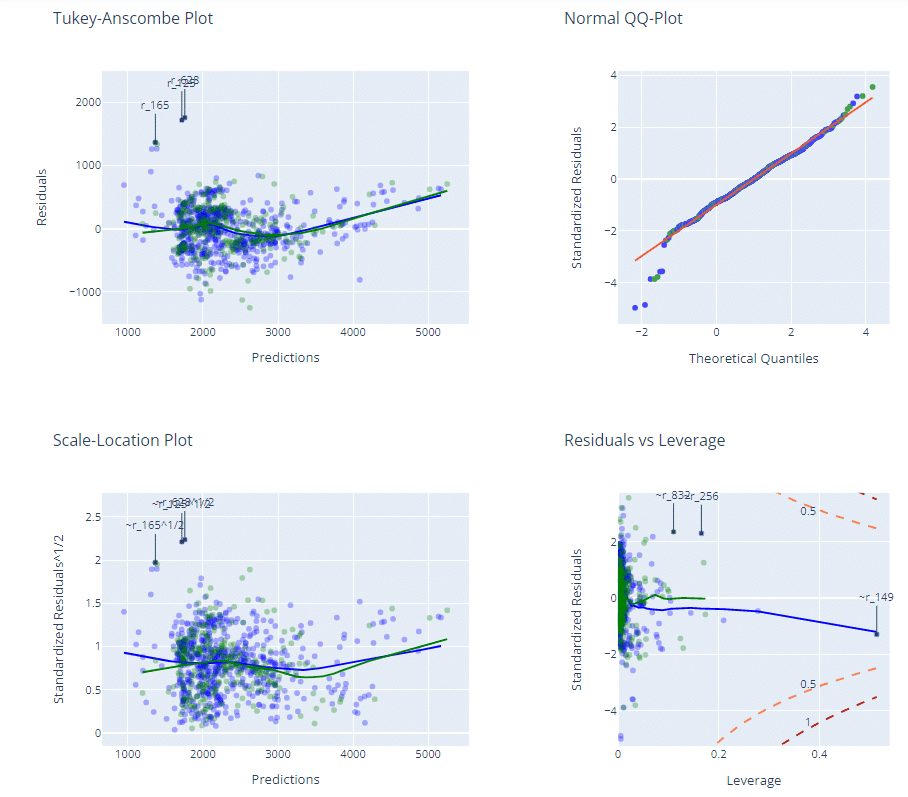
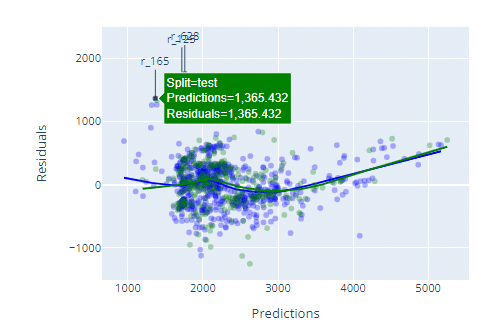
■Resifduals(残差プロット)
横軸:予測値、縦軸:残差(予測値と実際値の差)
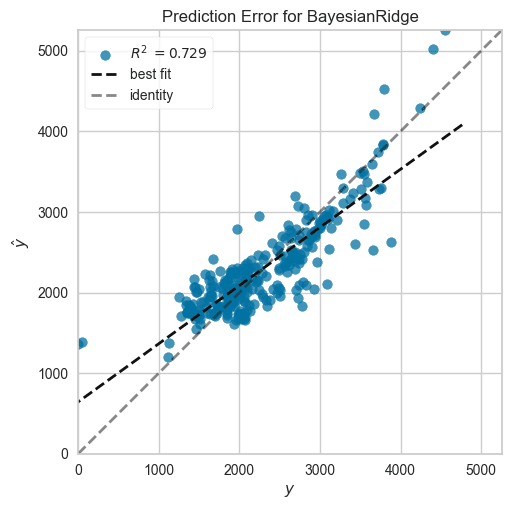
■Prediction Error
横軸:実際値、縦軸:予測値
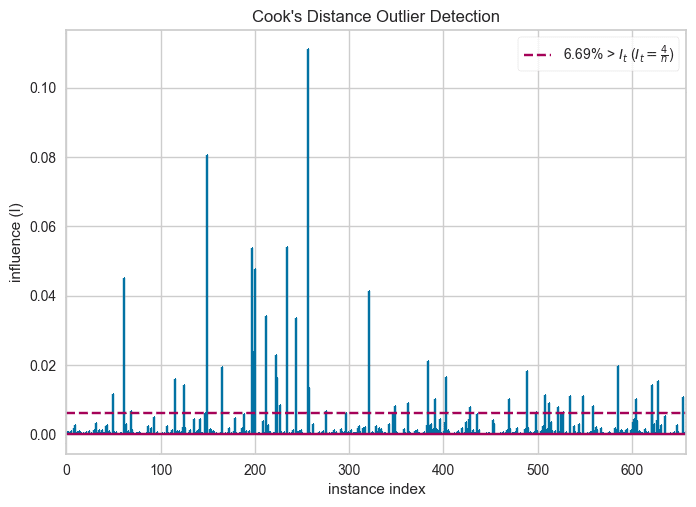
■Cooks Distance
横軸:データID、縦軸:外れ値の確認に用いる指標「クックの距離」かな?
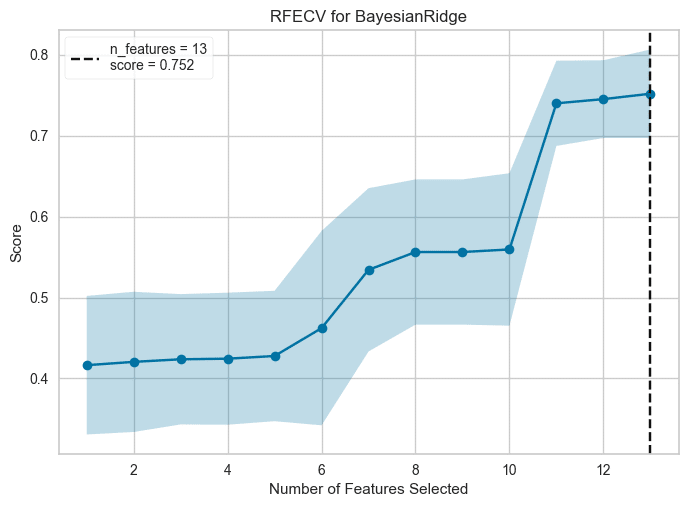
■Feature Selection
横軸:特徴量(説明変数)の選択数、縦軸:スコア
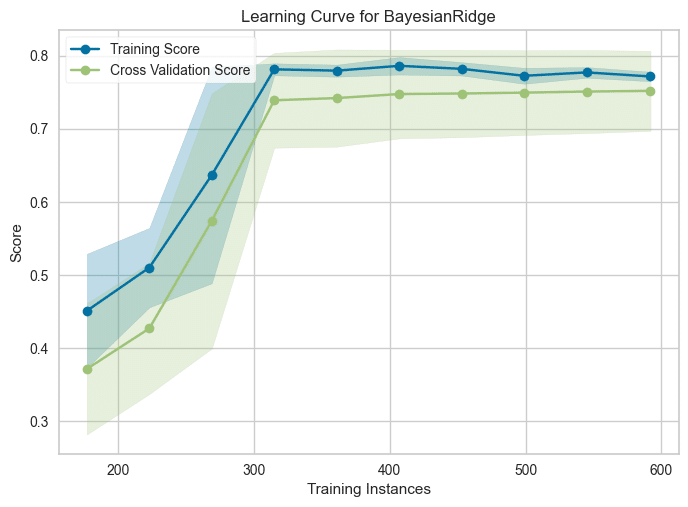
■Learning Curve(学習曲線)
横軸:学習データ数、縦軸:スコア
■Manifold Learning(多様体学習)
(よく分かっていません)
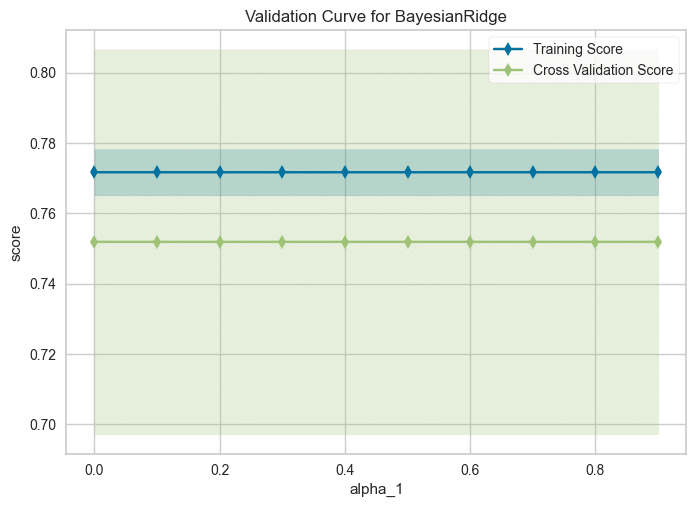
■Validation Curve(検証曲線)
横軸:パラメータ($${\alpha_1}$$)の値、縦軸:スコア
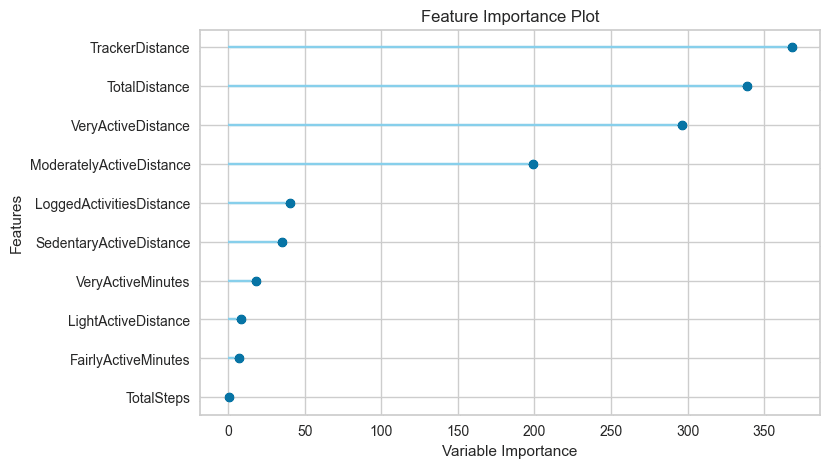
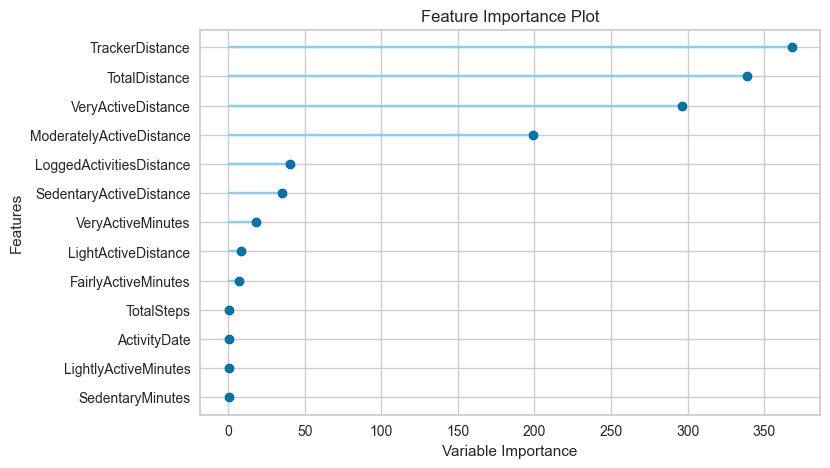
■Feature Importance(特徴量重要度のトップ10)
縦:特徴量(重要度の高い順)、横:重要度指標
■Feature Importance…(全特徴量の重要度?)
■Interactive Residuals
回帰診断(外れ値、誤差項の独立性・等分散性・正規性の仮定)に使うグラフを集めているように見えます。
グラフの点にマウスカーソルを当てると、点の各値を表示します。
なお「Decision Tree」は決定木系統のモデルのみ表示されるとのこと。
たくさんの評価用グラフィックをお楽しみいただけたでしょうか?
⑥テストデータによる予測・評価
PyCaretの「predict_model()」の一行です。
predict_df = predict_model(…model)のようにすると、predict_dfデータフレームに格納され、Pandasでcsvファイル等に出力できます。
predict_model(tuned_model)
⑦モデルの最終化
PyCaretの「finalize_model()」の一行です。
(最終化の目的・結果はよく分かっていません)
final_model = finalize_model(tuned_model)⑧モデルの保存
PyCaretの「save_model()」の一行です。pickle形式で保存されます、
save_model(final_model, 'begin_pycaret') # pickle形式で保存(拡張子pklを自動設定)⑨モデルの読み込み
PyCaretの「load_model()」の一行です。
final_model = load_model('begin_pycaret')PyCaretによる機械学習の一連の処理をざっと眺めました。
短い旅でしたが、お楽しみいただけたでしょうか?

結び
PyCaretを動かしてみて感じたことを書きます。
機械学習の初学者が一連の作業の流れを簡単に体感できると思います。
ハードルの高いコードにいきなりトライする前に、PyCaretで流れや型を知ることで、機械学習作業を感覚的にイメージできるでしょう。
機械学習のハードルを下げることは、機械学習アレルギーや挫折の防止につながります。
機械学習の普及にとても有効なツールだと思いました。
また、PyCaretの実行パラメータを熟知することで、機械学習の自動化を実現できそうなので、データ分析作業の効率化に寄与する感じもします。
PyCaretの簡単な利用方法はPyCaretのWebサイト「Quick Start🚀」で紹介されています。
ぜひ、PyCaretをインストールしたら、Webサイトのコードを試してみましょう。
個人的には複数モデルのアンサンブルに挑戦してみたいです。
おわり
ブログの紹介
noteで2つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
もくじのリンクから各記事にたどってくださいね。
2.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
リンクから記事を開いてくださいね。