
10-1-1 最小二乗法・傾きの検定 ~ コーヒーの生産量と小売価格の関係を線形単回帰モデルで分析

今回の統計トピック
回帰分析のテーマに入ります。
今回は単回帰モデルです。
相関係数と回帰分析の違い、回帰係数(傾き)の推定値の検定に取り組みます。
いよいよ統計ソフトウェア R にチャレンジします!
公式問題集の準備
「公式問題集」の問題を利用します。お手元に公式問題集をご用意ください。
公式問題集が無い場合もご安心ください!
「知る」「実践する」の章で、のんびり統計をお楽しみください!
問題を解く
📘公式問題集のカテゴリ
線形モデルの分野 ~回帰分析の分野
問1 最小二乗法・傾きの検定(コーヒーの生産量と小売価格)
試験実施年月
調査中
問題
公式問題集をご参照ください。
利用データ
この記事は、問題集が用いる以下の「コーヒーデータ」を利用しています。
【出典記載】
「Total production - Crop Year : 1990- Present」
「Retail Prices - Annual Averages : 1990- Present」
(両データともに、国際コーヒー機関 International Coffee Organization)
(http://www.ico.org/new_historical.asp)
【コンテンツ編集・加工の記載】
記事の記載にあたっては、出典記載の資料を加工して作成しています。

解き方
題意
最小二乗法で推定した単回帰モデルについて、次の3問を解答します。
①散布図から相関係数を読み取り
②散布図に回帰直線を描画
③単回帰モデルの傾きの検定統計量とこの統計量が従うt分布の自由度
【条件】
・散布図のイメージは下のグラフを参照
・目的変数は「価格」、説明変数は「生産量」
・最小二乗法による傾きの推定値は$${-0.14510}$$、傾きの推定値の標準誤差は$${0.02316}$$
・誤差項は互いに独立で同一の正規分布に従うと仮定
・統計的仮説検定の帰無仮説は「傾きが0である」
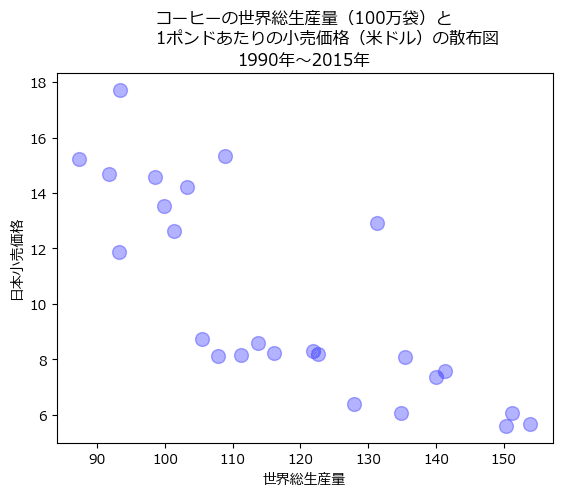
【散布図】


【注意事項】
出典から得たコーヒーデータには問題集のデータと相違する点があります。
例えば、散布図に赤い矢印で示した2点です。
従いまして、この記事のデータ・数値は問題集と完全に一致するものではありません。
① 散布図から相関係数を読み取る
ひとまず散布図を眺める
散布図を眺めて分かったことを列挙します。
右肩下がりの傾向が見られます。
「世界総生産量が増加すると日本小売価格が減少する」
→これは「負の相関係数」の特徴です。
つまり、相関係数の値は「負」です。データ点はぴっちり1直線に並んでいるわけでなく、かと言って、散らばり過ぎている感じも無いです。
→これは「中程度」の相関関係の特徴です。
解答選択肢から選別します。
対象外1:①~③は正の値なので対象外です。
対象外2:⑤の $${-0.994}$$ は「強い」相関関係なので対象外です。
解答は ④ $${-0.794}$$ です。
コーヒーデータで確認しましょう。
Python・pandas の相関行列を計算する関数 corr で計算しました。

手元のコーヒーデータの場合、日本小売価格と世界総生産量の相関係数は $${-0.797}$$ です。
なお、相関係数と回帰分析の関係は次のようなものになります。
相関係数と回帰式の傾きは異なる数値です。
混同しないようにしましょう。最小二乗法&線形単回帰の場合、相関係数の二乗は決定係数$${\boldsymbol{R^2}}$$と一致します。
「Rで作成してみよう!」の章に計算例があります。
② 散布図に回帰直線を描画する
散布図を縮小して再掲します。
突然ですが「回帰の主な性質」の降臨です。
「最小二乗法による回帰係数を用いる場合の回帰式の性質 c」をご存知でしょうか?
『c.回帰直線は$${\boldsymbol{x, y}}$$の平均点を通る』です。
散布図から平均点のだいたいの位置を推測してみましょう。
概算目算皮算用で、$${\bar{x}\fallingdotseq 120}$$、$${\bar{y}\fallingdotseq 11}$$としましょう。
解答選択肢に並んだ5つのグラフの中で、$${(120, 11)}$$付近を通る回帰直線は、ずばり、② です。
解答は ② です。
それでは、手元のコーヒーデータを用いたグラフで、ぼほ正解を確認しましょう。
まずは目算した平均点から。
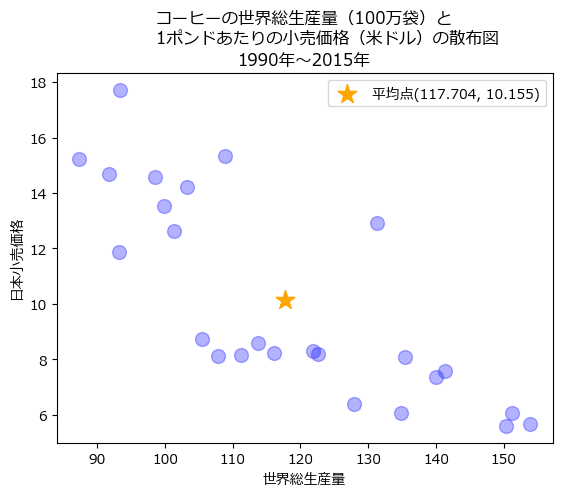
★印が平均点です。凡例に座標を表示しました。
平均点は$${(117.7, 10.2)}$$でした。
推測はだいたい合っていました。
続いて回帰直線です。

確かに回帰直線は平均点を通っています!
③ 単回帰モデルの傾きの検定統計量とこの統計量が従うt分布の自由度
傾きの検定とは?
回帰式の傾きの統計的仮説検定は「説明変数が目的変数の変化に影響を与えるか」に関心をもって行います。
影響を与えるとは「傾きが0ではない」ことです。
従いまして、帰無仮説は「傾き$${\boldsymbol{\beta}}$$は0である」になります。
傾きの検定統計量
傾きの検定には「$${t}$$検定統計量」を用います。
この統計量は自由度$${(n-p-1)}$$の$${t}$$分布に従います。
■ $${t}$$検定統計量の公式
$${t = \cfrac{\hat{\beta}}{\sqrt{\hat{\sigma}^2/ T_{xx}}} \sim t(n-p-1)}$$
$${\hat{\beta}}$$:傾きの推定値
$${\sqrt{\hat{\sigma}^2/ T_{xx}}=\text{se}(\hat{\beta})}$$:傾きの推定値の標準誤差
$${n}$$:観測データの数(標本サイズ)
$${p}$$:説明変数の数
さて、問題の条件を思い出しつつ、公式に当てはめてみましょう。
最小二乗法による傾きの推定値は$${-0.14510}$$、傾きの推定値の標準誤差は$${0.02316}$$
$${t}$$検定統計量を計算します。
$$
\begin{align*}
t&=\cfrac{傾きの推定値}{傾きの推定値の標準誤差} \\
\\
&=\cfrac{-0.14510}{0.02316} \\
\\
&= -6.265 \cdots \\
&\fallingdotseq -6.27
\end{align*}
$$
$${t}$$検定統計量の値は$${-6.27}$$です。
続いて自由度を計算します。
コーヒーデータは1991から2015年の25年間の毎年のデータなので、標本サイズ$${n}$$は$${25}$$です。
また、説明変数の数$${p}$$は$${1}$$です。
$$
\begin{align*}
p-n-1&=25-1-1 \\
&=23
\end{align*}
$$
自由度は$${23}$$です。
まとめると、$${t}$$検定統計量の値は$${-6.27}$$、検定統計量の分布は自由度$${23}$$の$${t}$$分布、です。
解答は ⑤ です。
解答
〔1〕④、〔2〕②、〔3〕⑤ です。
難易度 ふつう
・知識:相関係数の読み取り、回帰直線の性質、回帰係数の検定
・計算力:数式組み立て(中)、電卓(低)
・時間目安:3問合計 5分
知る
おしながき
公式問題集の問題に接近してみましょう!
今回は、公式問題集で計算した「傾きの検定」の覚え方を学びましょう。
単回帰モデル
📕公式テキスト:1.6.4 回帰直線(32ページ~)、5.1.1 線形単回帰モデル(163ページ~)など
特集記事のお知らせ
単回帰モデルの詳しい学習ポイントを「特集記事」にまとめました。
ぜひご覧くださいませ。
統計ソフトウェアの出力結果
統計検定2級の回帰分析の問題には「統計ソフトウェアの出力結果」が出題されることが多いです。
こんなイメージです。

この出力結果の「Coefficients」の箇所に「傾き(回帰係数)」の分析結果が掲載されます。

回帰係数欄の各項目の記載順を利用して、「回帰係数、標準誤差、$${t}$$値の関係」を覚えましょう!

回帰係数の推定値、標準誤差、$${t}$$値の順で並んでいます。
この並び順に合わせて「回帰係数の推定値÷標準誤差=$${t}$$値」と覚えます。
統計検定2級の学習の際、「統計ソフトウェアの出力結果」を見つけたら、「Coefficients」のブロックの数値を電卓に打ち込んで、「$${t}$$値」を計算したり、「回帰係数の推定値」を逆算したりして、慣れ親しんでくださいね。
実践する
コーヒーデータの単回帰分析を実践する
コーヒーデータを用いて単回帰分析を実践しましょう!
EXCEL、R、Pythonの3つの手段でトライします。
特集記事のお知らせ
EXCEL、R、Pythonなどのツールを利用した単回帰分析の実践を「特集記事」にまとめました。
ぜひご覧くださいませ。
CSVファイルのダウンロード
こちらのリンクから「コーヒーデータ」のCSVファイルをダウンロードできます。

EXCELで作成してみよう!
データ分析アドインを利用する
EXCELの「データ分析」アドインを用いて回帰分析を実践します。
「データ」メニューに「データ分析」が無い場合は、データ分析のアドインを有効にしましょう。
メニューより、「ファイル」>「オプション」を選びます。
「Excelのオプション」画面の左メニュー「アドイン」を指定します。
「Excelのオプション」画面の下部の「管理」で「Excelアドイン」を選び、「設定」ボタンをクリックします。
「アドイン」画面で「分析ツール」をチェックして、OKボタンをクリックします。
回帰分析の出力結果
概要、分散分析表、回帰係数の分析結果が網羅的に表示されます。

回帰分析の結果を分析する
1ブロックづつ見ていきましょう。

決定係数$${R^2}$$の値は$${0.6353}$$。
この単回帰モデルの当てはまり具合はまずまずと言えるでしょう。
標準誤差は残差の標準誤差です。

分散分析表には$${F}$$値(観測された分散比)と$${p}$$値(有意F)が表示されます。
$${p}$$値は極小です。有意水準$${5\%}$$で、このモデルに含まれる説明変数の中に目的変数の説明に役立つ変数がある、と言えます。

回帰係数の切片と傾き(世界総生産量の回帰係数)の推定値から、単回帰式は次のようになります。
$${y=27.2195-0.1450x}$$
世界総生産量が1単位増加すると日本小売価格が$${0.1450}$$単位減少することとなります。
回帰係数の推定値の$${p}$$値は切片・傾きともに極小です。
有意水準$${5\%}$$で切片・傾きは0では無い(目的変数に影響を与える)と言えます。
コーヒーの生産量(供給量)が増えると価格は下がる、という関係がデータから見えました。
操作概要
■ メニューで「データ分析」を指定します。

■ 「データ分析」画面で「回帰分析」を選びます。

■ 「回帰分析」画面でx、yデータの指定等を行います。
この操作を終えると、分析結果が表示されます。

少ない操作ステップで回帰分析を実行できます。
お手元のデータでガンガン回帰分析をしてみましょう!!!
EXCELサンプルファイルのダウンロード
こちらのリンクからEXCELサンプルファイルをダウンロードできます。
サンプルファイルには「コーヒーデータ」が含まれています。

R で作成してみよう!
R スクリプトで回帰分析を実践します。
① データの読み込み
### データの読み込み
data <- read.csv("sampledata.csv")
# データの要約表示
str(data)
summary(data)【出力結果】
コーヒーデータの概要を表示しました。
> str(data)
'data.frame': 25 obs. of 3 variables:
$ 年 : int 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 ...
$ 日本小売価格: num 11.9 12.6 14.6 14.7 17.7 ...
$ 世界総生産量: num 93.2 101.3 98.5 91.8 93.3 ...
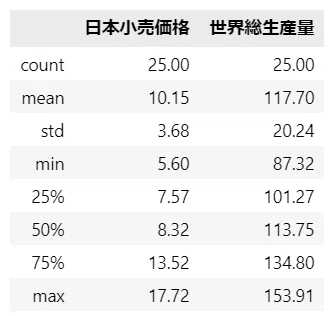
> summary(data)
年 日本小売価格 世界総生産量
Min. :1991 Min. : 5.60 Min. : 87.32
1st Qu.:1997 1st Qu.: 7.57 1st Qu.:101.27
Median :2003 Median : 8.32 Median :113.75
Mean :2003 Mean :10.15 Mean :117.70
3rd Qu.:2009 3rd Qu.:13.52 3rd Qu.:134.80
Max. :2015 Max. :17.72 Max. :153.91 ② 相関係数の表示
### 相関係数の計算
cor(data$世界総生産量, data$日本小売価格)【出力結果】
[1] -0.7970828相関係数は -0.7970828 です。
中程度(もしくはやや強め)の負の相関関係があります。
ちなみに、最小二乗法による単回帰モデルの場合、相関係数の二乗は決定係数の値と一致します。
$${-0.7970828^2=0.6353410}$$を覚えておきましょう。
③ 回帰分析の実行
lm 関数を用いて、回帰モデルのformula(式)を組み立てて、回帰分析を実行します。
formula(式)は「目的変数 ~ 説明変数」の形式で記述します。
### 回帰分析の実施と結果表示
data.lm <- lm(日本小売価格 ~ 世界総生産量, data=data)
summary(data.lm)【実行結果】
出ました!「統計ソフトウェアの出力結果」です。
Call:
lm(formula = 日本小売価格 ~ 世界総生産量, data = data)
Residuals:
Min 1Q Median 3Q Max
-3.4459 -1.8230 0.4390 0.7821 4.7484
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 27.2195 2.7337 9.957 8.29e-10 ***
世界総生産量 -0.1450 0.0229 -6.330 1.85e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.27 on 23 degrees of freedom
Multiple R-squared: 0.6353, Adjusted R-squared: 0.6195
F-statistic: 40.07 on 1 and 23 DF, p-value: 1.85e-06回帰係数:Coefficients を見ます。
Intercept が切片、世界総生産量が傾きです。
回帰式が$${y=27.2195-0.1450x}$$となりました。
回帰係数の推定値の検定では、$${p}$$値が極小な値となり、切片・傾きは0では無い(目的変数に影響を与える)と言えます。
下段を見ます。
残差の標準誤差は$${2.27}$$、自由度は$${23}$$です。
決定係数$${R^2}$$は$${0.6353}$$、自由度調整済み決定係数$${R^{*2}}$$は$${0.6195}$$。回帰モデルの当てはまり具合はまずまずと言えるでしょう。
決定係数は相関係数の二乗($${-0.7970828^2=0.6353410\fallingdotseq 0.6353}$$)となりました。
回帰の有意性の検定では、$${F}$$値が$${40.07}$$。$${p}$$値は極小な値となり、有意水準$${5\%}$$で、このモデルに含まれる説明変数の中に目的変数の説明に役立つ変数がある、と言えます。
④ 散布図と回帰直線の描画
### 散布図と回帰直線の描画
plot(日本小売価格 ~ 世界総生産量, data=data)
abline(data.lm, lwd=1, col='red')【実行結果】

回帰直線(赤い直線)は右肩下がりとなりました。
⑤ 分散分析の実行
### 分散分析の実施と結果表示
anova(data.lm)【出力結果】
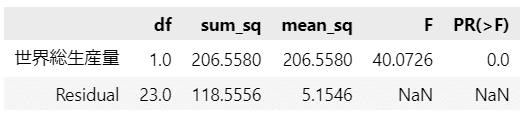
Analysis of Variance Table
Response: 日本小売価格
Df Sum Sq Mean Sq F value Pr(>F)
世界総生産量 1 206.56 206.558 40.073 1.85e-06 ***
Residuals 23 118.56 5.155
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1回帰(世界総生産量)と残差(Residuals)の分析が表示されます。
平方和(Sum Sq)は回帰による平方和は$${206.56}$$、残差平方和は$${118.56}$$。
残差の平均平方(Mean Sq)の平方根を取った値は、回帰分析で表示された残差の標準誤差(Residual standard error)になります。
$${\sqrt{5.155} \fallingdotseq 2.270}$$
分散分析表でも回帰の有意性の検定の$${F}$$値、$${p}$$値を確認できます。
Rサンプルファイルのダウンロード
こちらのリンクからRスクリプト形式のサンプルファイルをダウンロードできます。

Pythonで作成してみよう!
statsmodels を用いて回帰分析を実践します。
① インポート
### インポート
# 数値計算
import numpy as np
import pandas as pd
# 統計処理
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 可視化
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'② データの読み込み
コーヒーデータをpandasのデータフレームに読み込み、データの形状と先頭5行を表示します。
### データの読み込み
# 日本小売価格(単位:米ドル)、世界総生産量(単位:100万袋)
# 【注意点】2007年の生産量の値が問題集よりも大きい
# 2012年の生産量の値が問題集よりも小さい
data = pd.read_csv(r'sampledata.csv', index_col=0)
print('data.shape', data.shape)
display(data.head())【実行結果】

「年」はインデックスです。
③ 要約統計量の表示
pandas の describe で最小値・最大値・平均値・四分位数等を表示します。
なお、数値の小数点以下の丸めは「.round()」で指定します。
### 要約統計量の表示
data.describe().round(2)【実行結果】
④ 相関係数の表示
pandas の corr で日本小売価格と世界総生産量の相関係数を計算します。
### 相関行列の表示
data.corr().round(3)【出力結果】

日本小売価格と世界総生産量の相関係数は$${-0.797}$$です。
⑤ 回帰分析の実行
smf.ols でモデル model を定義します。
R スクリプトと同様に、formula(数式)形式で「目的変数 ~ 説明変数」を定義します(クォーテーションでくくる点が R と異なります)。
model に対して fit を実行することで回帰分析が行なえます。
### 回帰モデルの定義と実行
# モデルの定義
model = smf.ols('日本小売価格 ~ 世界総生産量', data=data)
# 回帰分析の実行
result = model.fit()
# 回帰分析の結果を表示
result.summary()【実行結果】

R と表示形式は異なりますが、ほぼ同じ項目を表示しています。
上段がモデル全体の分析結果、中段の「coef」の部分が回帰係数の分析結果、Omnibusから始まる下段は残差の各種統計量(正規性、自己相関など)です。
上段の決定係数(R-squared)、$${F}$$値の$${p}$$値(Prob(F-statistic))などから、R の出力結果と同様に、モデルの当てはまり具合、モデルの説明力を判断します。
中段の係数の推定値(coef)、$${t}$$値の$${p}$$値(P>|t|)などから、R の出力結果と同様に、回帰式、回帰係数の説明力を判断します。
⑥ 散布図と回帰直線の描画
目的変数の予測値は、回帰分析の結果 result の中の fittedvalues に格納されています。
回帰直線の描画時には、この fittedvalues を利用します。
### 散布図の描画 回帰直線付き
# グラフタイトルの設定
title = 'コーヒーの世界総生産量(100万袋)と\n\
1ポンドあたりの小売価格(米ドル)の散布図\n1990年~2015年'
# 散布図の描画
data.plot.scatter(x='世界総生産量', y='日本小売価格', s=100, color='b', alpha=0.3,
title=title)
# 回帰直線の描画
plt.plot(data['世界総生産量'], result.fittedvalues, color='red');【実行結果】

⑦ 分散分析の実行
分散分析の関数 sm.stats.anova_lm を用いて回帰分析結果の分散分析を行います。
anova_lm に与えるデータは、回帰分析の結果 result です。
### 分散分析表の表示
sm.stats.anova_lm(result).round(4)【実行結果】
Pythonサンプルファイルのダウンロード
こちらのリンクからJupyter Notebook形式のサンプルファイルをダウンロードできます。
おわりに
回帰分析のテーマに入りました。全4記事の予定です。
最小二乗法による線形回帰モデルを「統計ソフトウェア R の出力結果」から読み取ることが理解の近道かな、って思います。
いくつかの公式を利用した計算問題もあります。
Excel、R、Python、統計専用ツールなどを活用して、サクッと回帰分析ができるようになると、データサイエンスっぽい雰囲気を味わえるのではないでようか。
最後までお読みいただきまして、ありがとうございました。
のんびり統計シリーズの記事
次の記事
前の記事
目次
この記事が気に入ったらサポートをしてみませんか?