
9-2-1 期待度数・自由度 ~ 独立性の検定と適合度の検定はソックリさん

統計的仮説検定のトピック「独立性の検定」の初回です。
クロス集計表を用いた独立性の検定にチャレンジします。
適合度の検定にとても似た手法です。
公式問題集の準備
「公式問題集」の問題を利用します。お手元に公式問題集をご用意ください。
公式問題集が無い場合もご安心ください!
「知る」「実践する」の章で、のんびり統計をお楽しみください!
問題を解く
今回の記事の構成
この記事は、通常の記事構成と違う章立てにいたします。
「知る」「実践する」を1つの章にまとめます。
最初に「問題を解く」の章で、出題箇所にピンポイントで解答を検討します。
続く「知る・実践する」の章で、適合度の検定の一連の流れを手作業・EXCEL・Pythonで実践いたします。
📘公式問題集のカテゴリ
カイ二乗検定の分野 ~独立性検定の分野
問1 期待度数・自由度(性別・お菓子のアンケート)
試験実施年月
調査中
問題
公式問題集をご参照ください。
解き方
題意
与えられた条件に基づき、独立性の検定に関する「期待度数の一部分」と「カイ二乗分布の自由度」を解答します。
【条件】
・「性別」2行・「嗜好」2列の2元クロス集計表に基づいて独立性の検定を行う
・帰無仮説は「性別によって好き/嫌いに違いはない」
この問題の統計的仮説検定の概要を図示します。

作戦会議
ひとまず、出題箇所にフォーカスを当てて、ピンポイントで解答します。
「男性・好き」の期待度数
観測度数を確認します。

「好き」縦計は27、「男」横計は49、合計は100。
クロスする縦計と横計を掛けて合計で割ると期待度数が求まります。

「男性・好き」の期待度数は$${13.23}$$です。
次のように考えることもできます。

解答選択肢(ア)の期待度数は 13.23 です。
$${\boldsymbol{\chi^2}}$$分布の自由度
2元クロス集計表を用いて、独立性の検定を行う場合、自由度の計算式は次のようになります。
■自由度の公式
(行のカテゴリの数-1)×(列のカテゴリの数-1)
もしくは
$${(r-1)(c-1)}$$
ただし、$${r}$$:行のカテゴリの数、$${c}$$:列のカテゴリの数
クロス集計表を再掲します。

行は横、列は縦です。
行のカテゴリ$${r}$$は「男」と「女」の2つです。
列のカテゴリ$${c}$$は「好き」と「嫌い」の2つです。
従いまして、自由度は$${(r-1)(c-1)=(2-1)(2-1)=1 \times 1=1}$$です。
解答選択肢(イ)の自由度は 1 です。
解答
① です。
難易度 やさしい
・知識:独立性の検定
・計算力:数式組み立て(低)、電卓(低)
・時間目安:1分
知る・実践する
おしながき
公式問題集の問題について、適合度の検定の一連の流れを手作業・EXCEL・Pythonで実践していきましょう。
📕公式テキスト:6.3 独立性の検定(205ページ~)
読み解き
条件から統計的仮説検定の主題を読み解きます。
条件より「独立性の検定」を行います。
独立性の検定は「片側検定(上側)」です。有意水準は問題で与えられていないので、ここでは$${5\%}$$とします。
クロス集計表の観測度数は下の表を参照。
クロス集計表の2つの「変数は独立である」との帰無仮説の下で、期待度数を計算します。
観測度数と期待度数を用いて、検定統計量$${\chi^2}$$を計算します。
検定統計量$${\chi^2}$$が従う$${\chi^2}$$分布の自由度を計算します。
$${\chi^2}$$分布のパーセント点表より、有意水準$${5\%}$$のパーセント点を取得して、帰無仮説を棄却できるかどうか結論づけます。

この問題の統計的仮説検定の概要を図示します(再掲)。

手計算で検定
ステップ1:期待度数を計算する
期待度数は、帰無仮説が正しいと仮定してカウントする度数です。
独立性の検定の場合、クロス集計表の2変数は独立である、と仮定して期待度数を計算します。
帰無仮説を独立な2つの事象の確率の数式を用いて表します。
帰無仮説 $${H_0 : P(A_i \cap B_j)=P(A_i)P(B_j)}$$
ただし、$${i,j}$$:クロス集計表の行と列、$${A_i}$$:性別のカテゴリ、$${B_i}$$:嗜好のカテゴリ、$${P(A_i \cap B_j)}$$:性別と嗜好の積事象の確率(同時確率)、$${P(A_i), P(B_i)}$$:性別の確率と嗜好の確率(周辺確率)
この数式をクロス集計表にマッピングしてみます。
期待度数の確率が見えてきました。

横計$${P(A_i)}$$と縦計$${P(B_i)}$$を計算しましょう。
これらの比率は周辺確率と呼ばれるものです。
$$
P(A_1)=49/100=0.49 \\
P(A_2)=51/100=0.51 \\
P(B_1)=27/100=0.27 \\
P(B_2)=73/100=0.73
$$
計算結果を表にします。

期待度数の確率は、縦計の比率(周辺確率)と横計の比率(周辺確率)を掛け算した値です。
期待度数の確率を計算しましょう。

期待度数の確率と標本サイズ(合計)$${100}$$を掛け算して、期待度数を算出します。

【時短計算法】
次の表のように観測度数の「縦計」「横計」「総合計」から期待度数を計算できます。

次の計算で観測度数と期待度数を用いるので、両方の度数をまとめて掲載しましょう。

棒グラフで観測度数と期待度数の違いを可視化しましょう。
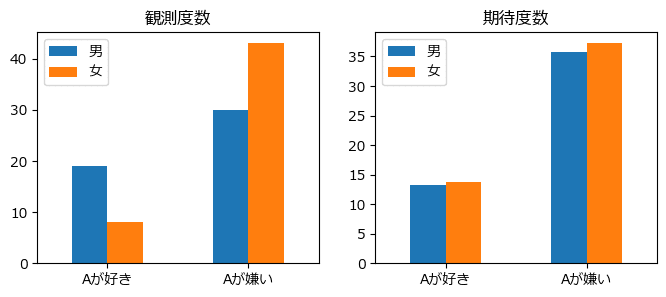
観測度数では男性と女性と間に嗜好の偏りのようなものが見られます。
はたして、適合度検定の結果はいかに・・・。
ステップ2:検定統計量$${\boldsymbol{\chi^2}}$$を計算する
カテゴリ(分類)ごとに「観測度数と期待度数の差の2乗」を「期待度数で割り」、全カテゴリを合計します。

本問のカテゴリは行2×列2で合計4のカテゴリがあります。
・行:「男」と「女」の2つ
・列:「好き」と「嫌い」の2つ
検定統計量$${\chi^2}$$は次の計算式を用いて計算します。

先程まとめた観測度数と期待度数の値を当てはめて、検定統計量$${\chi^2}$$を計算しましょう。

検定統計量の計算で得られた$${\chi^2}$$値は$${6.76}$$です。
【時短計算法】
2×2クロス集計表から期待度数を計算する場合、各カテゴリの分子の値は同じになります。
上の計算式の2行目をご確認ください。
また、分子の値は次の計算式で求めることができます。
$${ \left(\cfrac{ad-bc}{a+b+c+d} \right)^2}$$
計算式中の$${a,b,c,d}$$は下の観測度数のクロス集計表を参照してください。

ステップ3:検定統計量$${\boldsymbol{\chi^2}}$$が従う$${\boldsymbol{\chi^2}}$$分布の自由度
2元クロス集計表を用いて、独立性の検定を行う場合、自由度の計算式は次のようになります。
■自由度の公式
(行のカテゴリの数-1)×(列のカテゴリの数-1)
もしくは
$${(r-1)(c-1)}$$
ただし、$${r}$$:行のカテゴリの数、$${c}$$:列のカテゴリの数
本問で取り扱う観測度数のカテゴリ数は「行$${r}$$:男・女の2つ」「列$${c}$$:好き・嫌いの2つ」です。
自由度は、$${(r-1)(c-1)=(2-1)\times(2-1)=1\times1=1}$$で、$${1}$$です。
ステップ4:検定統計量$${\boldsymbol{\chi^2}}$$が従う$${\boldsymbol{\chi^2}}$$分布の上側パーセント点
続いて上側パーセント点を取得して棄却域を確認します。
ここで重要なお知らせ。
【重要ポイント】
・独立性の検定は片側・上側検定です。
独立性の検定は片側・上側検定ですので、有意水準$${5\%}$$の棄却域を求める際には、自由度$${1}$$の$${\chi^2}$$分布のパーセント点表より上側確率$${5\%}$$点を取得します。

自由度$${1}$$の上側確率$${5\%}$$点は$${3.84}$$です。
$${\chi^2}$$分布の確率密度関数をグラフで確認しましょう。
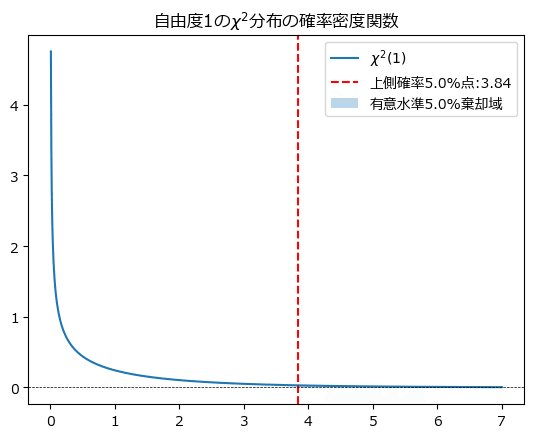
垂直の滑り台のような形状です。
ステップ5:結論を出す
$${\chi^2}$$値$${=6.76}$$と上側確率$${5\%}$$点$${=3.84}$$を比べます。
$${\chi^2}$$値は上側確率$${5\%}$$点より大きいため、棄却域の区間内です。
よって、帰無仮説は棄却されます。
具体的には、有意水準$${5\%}$$で帰無仮説「性別によって好き/嫌いに違いはない」(独立である)は棄却され、対立仮説「性別によって好き/嫌いに違いがある」(独立ではない)と言えます。
最後にグラフで棄却域と$${\chi^2}$$値の関係を確認しましょう。

確かに$${\chi^2}$$値は棄却域に含まれています。
手計算は以上となります。
EXCELで検定
計算シートを用いて独立性の検定を行います。
計算シートの全体像
左側の表には、観測度数を登録します。
観測度数に基づいて期待度数を計算しています。
また、カテゴリごとに$${(観測度数-期待度数)^2/期待度数}$$の計算を行って合計を取り、$${\chi^2}$$値にしています。
右側の入力パラメータは「有意水準」です。
観測度数・期待度数・有意水準より、$${\chi^2}$$値、上側確率%点、$${p}$$値を求めて、判定します。

適合度検定の実行
上記の計算シートには既に必要なデータ、パラメータを設定済みです。
計算値によると、自由度は$${1}$$、$${\chi^2}$$値は$${6.759}$$、上側確率$${5\%}$$点は$${3.841}$$です。
$${\chi^2}$$値が上側確率$${5\%}$$点よりも大きいので、帰無仮説は棄却されます。
$${p}$$値は$${0.009}$$と小さな値になりました。
まとめ
$${\chi^2}$$値は$${6.759}$$、$${p}$$値は$${0.009}$$です。
有意水準$${5\%}$$で帰無仮説は棄却され、対立仮説「性別によって好き/嫌いに違いがある」(独立ではない)と言えます。
EXCELの関数
EXCELの CHISQ.TEST 関数を用いて、適合度検定の$${p}$$値を算出できます。
引数は、CHISQ.TEST ( 観測度数のデータ範囲, 期待度数のデータ範囲 ) です。
2元クロス集計表の場合も、観測度数の期待度数の行と列を揃えておくことで、データ範囲の指定を容易に行なえます。
シンプルなのでぜひ使ってみてください!

EXCELは以上となります。
EXCELサンプルファイルのダウンロード
こちらのリンクからEXCELサンプルファイルをダウンロードできます。
Pythonで検定
scipy.stats の chi2_contingency を用いて、クロス集計表に基づく独立性の検定を実行します。
最後にスピンオフ企画を設けました。お楽しみに!
①インポート
### インポート
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'②データとパラメータの設定
問題で与えられたクロス集計表(観測度数)を登録して、pandasのデータフレーム observed_tab を作成します。
### データとパラメータの設定
## データ、パラメータの登録
# 観測度数 行:性別、列:回答
observed_array = np.array([[19, 30], [8, 43]])
# 有意水準
alpha = 0.05
## データフレーム化
observed_tab = pd.DataFrame(observed_array,
columns=['Aが好き', 'Aが嫌い'],
index=['男', '女'])
observed_tab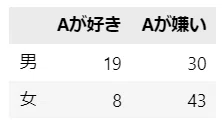
③独立性の検定の実施
scipy.stats の chi2_contingency を用いて独立性の検定を行います。
最初の1行だけで独立性の検定を処理できています。すごい。
引数は、chi2_contingency ( 観測データのクロス集計表, correction ) です。
期待度数を用意する必要が無いので、とても手軽に検定を実行できます。
correction=False はイエーツの補正を実施しない、というオマジナイです。
戻り値は、$${\chi^2}$$値、$${p}$$値、自由度、期待度数です。
### 独立性の検定の実施 クロス集計表をインプット
chi2_value, p_value, df, expected = stats.chi2_contingency(observed_tab,
correction=False)
# 期待度数のデータフレーム化
expected_tab = pd.DataFrame(expected, columns=observed_tab.columns,
index=observed_tab.index)
# 期待度数の表示
print('期待度数:')
display(expected_tab)
# カイ二乗統計量、p値、自由度の表示
print(f'χ^2値:{chi2_value:.3f}, p値:{p_value:.3f}, 自由度:{df}')
④結論の表示
有意水準と$${p}$$値を比較して、帰無仮説を棄却できるかどうかを判定します。
### 結論の表示
# 有意水準のカイ二乗分布の上側パーセント点の取得
critical_value = stats.chi2.isf(alpha, df)
if p_value < alpha: # p値が有意水準より小さい場合:棄却できる
result = ('棄却される', '言える')
else: # p値が有意水準以上の場合:棄却できない
result = ('棄却されない', '言えない')
print(f'結論\n有意水準{alpha:.1%}で帰無仮説は{result[0]}\n'
f'対立仮説「各変数は独立でない(関連がある)」と{result[1]}')
### 統計量の表示
print('\n統計量')
print(f'自由度{df}のカイ二乗分布の上側{alpha:.1%}点:{critical_value:.3f}, '
f'カイ二乗値:{chi2_value:.3f}')
print(f'有意水準{alpha:.3f}, p値:{p_value:.3f}')
帰無仮説を棄却できました。
まとめ
観測度数のクロス集計表データを整えて、scipy.stats の chi2_contingency を実行するだけで、$${p}$$値を取得して独立性の検定の結論を出せることが分かりました。
$${p}$$値が有意水準$${5\%}$$より小さいので、有意水準$${5\%}$$で帰無仮説は棄却され、対立仮説「性別によって好き/嫌いに違いがある」(独立ではない)と言えます。
★★★ スピンオフ 企画★★★
「クロス集計する前のローデータで独立性の検定を実施してみよう!」

クロス集計もPythonにやってもらおう!という企画です。
お手元の「2つのカテゴリ変数データ」に関連があるかないかをサクッと検定しましょう。
pingouin パッケージを利用します。
インストール例はこちら。
# pipの場合
pip install pingouin
# condaの場合
conda install -c conda-forge pingouin①インポート
### インポート
import pingouin as pg②ローデータの作成(オプション処理)
問題のクロス集計表をバラして100件のローデータを生成した後に、pandasのデータフレーム data_df にします。
お手元のローデータを活用する場合には、クロス集計表をローデータにバラす処理は不要です。
なお、データフレーム化しておくと、後工程が楽になります。
### ローデータの作成
# クロス集計表をバラしてnumpy配列を作成(repeat関数で度数分の同値を設定)
for i, row in enumerate(observed_tab.index):
for j, col in enumerate(observed_tab.columns):
tmp = np.repeat([[row, col]], observed_tab.iloc[i, j], axis=0)
if (i==0) & (j==0):
data = tmp
else:
data = np.vstack([data, tmp])
# データフレーム化
data_df = pd.DataFrame(data, columns=['性別', '回答'])
# データフレームの表示
display(data_df)
③独立性の検定の実行
pingouin の chi2_independence 関数を記述するだけです!
引数は、chi2_independence ( データフレーム名, 変数1, 変数2, correction ) です。
correction=False はイエーツの補正を実施しない、というオマジナイです。
戻り値は、期待度数、観測度数、統計量です。
### 独立性の検定の実行 集計前データをインプット
# 引数は、データフレーム、変数名x,y、イエーツの補正の要否
# 戻り値は、期待度数、観測度数、統計量
excepted_freq, observed_freq, test_result \
= pg.chi2_independence(data=data_df, x='性別', y='回答', correction=False)④検定結果の表示
chi2_independence から得た戻り値を表示します。
■ 観測度数
# 観測度数の表示
observed_freq
■ 期待度数
# 期待度数の表示
excepted_freq
■ 統計量
# 統計量の表示 .loc[;1] を外すと全6個のテスト結果を表示する
# 検定の種類、λ、カイ二乗統計量、自由度、p値、クラメールのV、検出力
test_result.iloc[:1].round(3)
自由度 dof$${=1}$$、$${\chi^2}$$値 chi2$${=6.579}$$、$${p}$$値 pval$${=0.009}$$です。
$${p}$$値が有意水準$${5\%}$$より小さいので、有意水準$${5\%}$$で帰無仮説は棄却され、対立仮説「性別によって好き/嫌いに違いがある」(独立ではない)と言えます。
おまけ:ローデータからクロス集計表を作成する方法
pandas の crosstab を利用して、ローデータ data_df の2項目からクロス集計表を作成します。
### データフレームからクロス集計表を作成
crossed_tab = pd.crosstab(data_df['性別'], data_df['回答'])
crossed_tab
Pythonサンプルファイルのダウンロード
こちらのリンクからJupyter Notebook形式のサンプルファイルをダウンロードできます。
以上で終了です。
お疲れ様でした。
おわりに
独立性の検定が始まりました。
適合度の検定と同様の計算手法です。
帰無仮説が「クロス集計表の2変数は独立である・関連がない・違いがない」と来ましたら、独立性の検定の登場です。
観測度数の埋め方を会得して、あるいは、EXCEL・Pythonを利用して、サクッと検定しましょう!
最後までお読みいただきまして、ありがとうございました。
のんびり統計シリーズの記事
次の記事
前の記事
目次
この記事が気に入ったらサポートをしてみませんか?