

#LLM


生成AI活用の試行錯誤〜Ubie社での取り組み〜
生成AIChatGPTをはじめとするGenerativeAI(生成AI)は、テレビや新聞で見ない日はないくらいに話題になっています。YouTubeでも芸人さんがChatGPTを紹介する動画が多数出ています。(個人的に、芸人かまいたちの「ChatGPTに漫才を作ってもらう」という動画が好きです。)
企業でも、ソフトバンクやNTTなどの大企業が、会社を上げて生成AIの開発・活用をしていくと発表してい


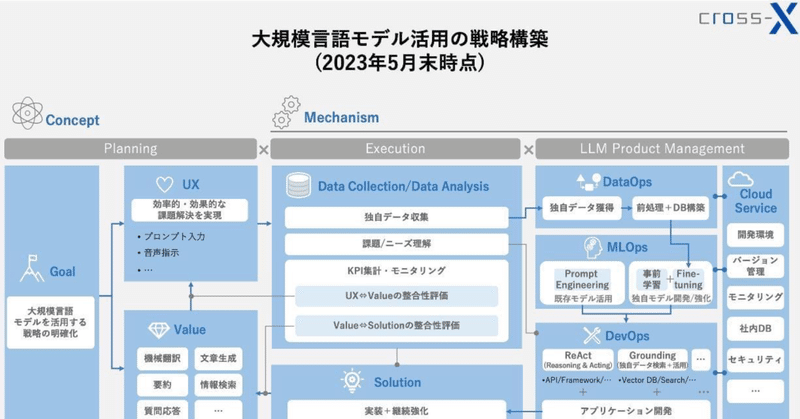
大規模言語モデル(LLM)を活用するための戦略・実務フレームワーク
はじめに株式会社cross-Xの古嶋です。DX戦略の立案やデータ・AI活用の支援をしています。
今回は、本記事の表紙にも掲載している「大規模言語モデル(LLM)活用の戦略・実務フレームワーク」について弊社の見解を簡単に解説したいと思います。
そもそもですが、このフレームワークの前身は、拙著『DXの実務』でDX戦略の全体像を示した以下のフレームワークです。
このフレームワークの狙いは「戦略と技

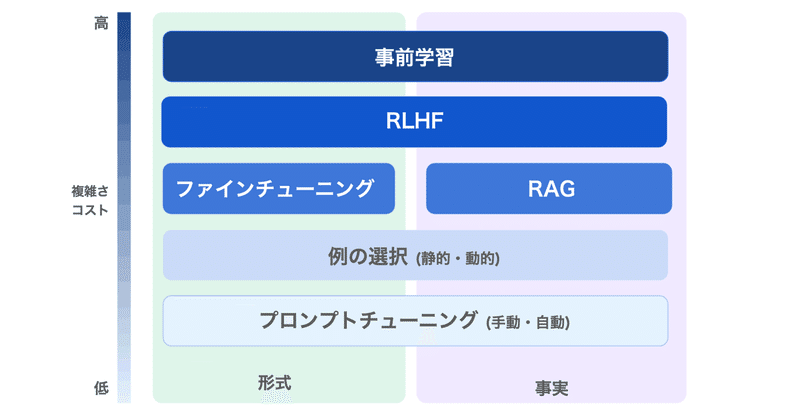
LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動


無料でGPT4越え!?ついに来たXwin-LM
今日のウィークリーAIニュースではnpaka大先生と一週間のニュースを振り返った。今週もいろいろあったが、なんといってもダークフォース、GPT-4越えと言われるXwin-LMである。中国製。
大先生もまだ試してないというので番組内で一緒に試してみた。
もちろんドスパラ製Memeplexマシン(A6000x2)を使用。
>>> from transformers import AutoToken


生成AI/LLM時代のエンジニアリングとの向き合い方とは? Ubie×ログラス×Gaudiyが語る【イベントレポート】
2023年5月23日(火)に開催された、特別イベント「生成AI/LLM時代のエンジニアリングとの向き合い方」。
生成AI/LLMにいち早く取り組んできたUbie社、ログラス社、Gaudiyの3社で、プロダクトや業務へのAI活用から、生成AI/LLM時代にエンジニアとして必要なスキルやマインドセット、今後の挑戦に至るまでをお話ししました。そのイベント内容を、長編レポートでお届けします!
第一線で


ローカルPCでLLMとLangChainで遊ぶ
今回は、お手軽にローカルPCでLLMモデルとLangChainで遊んでみました。モデルはStable-Vicuna-13Bを4bit量子化した重みファイルを使いました。
ここ一発はgpt-4を使うとしても、普段使いでOpenAIに課金せずに色々試せるのは、気持ち的にラクになりますね。
なお、llama-cpp-python ラッパーからGPUを呼び出す方法がよくわからなかったので、ひとまずCPU

Rinna 3.6B の量子化とメモリ消費量
「Google Colabでの「Rinna 3.6B」の量子化とメモリ消費量を調べてみました。
1. 量子化とメモリ消費量「量子化」は、LLMのメモリ消費量を削減するための手法の1つです。通常、メモリ使用量が削減のトレードオフとして、LLMの精度が低下します。
AutoTokenizer.from_pretrained()の以下のパラメータを調整します。
2. Colabでの確認Colabで