
アセンドにおけるサービス障害との向き合い方〜組織一体で向き合うための仕組みづくり

はじめに
こんにちは。アセンドのプロダクトエンジニア、増谷(https://x.com/yuichi_masutani)です。今回は、サービスを提供するうえで避けては通れない「障害」との向き合い方についてお話ししたいと思います。
サービスを運営している以上、障害の発生は不可避であると考えています。これはスタートアップに限らず、Amazon Web Service(通称AWS)を提供するAmazonや、Gmail、Google Spreadsheet などのオンラインアプリケーションを提供するGoogleのような、名だたるテックジャイアント企業でも同様です。現実に、彼らもしばしばサービス障害を発生させています。
このように、障害を完全になくすことは困難である、というのが現実の一側面ではないでしょうか。SaaSにおいてサービス障害の発生は一つの宿命かもしれません。しかし、「障害は避けられないものだ」という安易な開き直りは、思考停止に過ぎません。
以前計測したところによると、アセンドにおける障害からの平均復旧時間は42分で、これは、Googleによる State of DevOps(2023)の報告に照らすと、Eliteレベルに分類されるものでした。しかしながら、私たちが提供する運送管理システム「ロジックス」は、運送事業者の「配車」や「請求」といった業務の中核に関わる重要な役割を果たしています。私たちの提供するプロダクトの背後には、お客様の事業活動があり、障害の発生はその活動を阻害するものです。これらの業務が滞ることで、単なる不便さを超えてお客様の事業そのものに深刻な影響を及ぼしかねません。
ですから、私たちには障害の発生を可能な限り抑え、お客様が安心して業務を遂行できる環境を提供する責任があります。そのため、障害を完全に防ぐことはできなくとも、それを限りなくゼロに近づけるため、不断の努力を続けることが求められるでしょう。
本Noteでは、障害を単なるプロダクトの不具合と捉えず、組織全体で真摯にサービス障害へ向き合うための仕組みをご紹介します。
取り組みのご紹介
障害対応時の適切なコミュニケーションを実現する仕組み
〜ビジネスサイドのチームやお客様まで考慮したコミュニケーション設計
アセンドでは、Slack上に障害対応チャンネルとSlack Workflowを用意しており、「何かおかしいかもしれない」と感じた際に迅速に障害対応の体制を整え、コミュニケーションを開始できる仕組みを作っています。この仕組みにより、「気になることがある場合に即座に共有できる」環境と、それを受け入れる文化の醸成を図り、障害発生から検知・初動対応までのリードタイムを短縮しています。

ビジネスサイドのメンバーはお客様へ現在の状況や解消の見通しを伝えつつ、我々プロダクトチームのエンジニアは原因特定や暫定対応を行い、一刻も早く障害を解消するために動きます。このスレッドでは、現在の解消状況や影響範囲、お客様への報告・案内の状況を一元的に集約しています。やりとりが一元化され、状況がスレッドに残るため、後述の「ポストモーテム(障害振り返り)」でも活用しやすくなっています。
なお、リモートで働いているメンバーがいる場合でも、先日導入したオフィス配信環境を活用し、障害発生時のオフィスの空気感を共有しながら対応に当たれるようになっています。
ArgoCDを中心としたデプロイシステムと監視の仕組み
〜障害に素早く気づき、迅速に復旧する
SRE(Site Reliability Engineering)においては、信頼性の一要素として、障害からの復旧時間が重要視されます。アセンドでは、創業初期から速やかな復旧を実現する仕組みが必要と考え、KubernetesのCD(Continuous Delivery)ツールとしてArgoCDを導入しています。
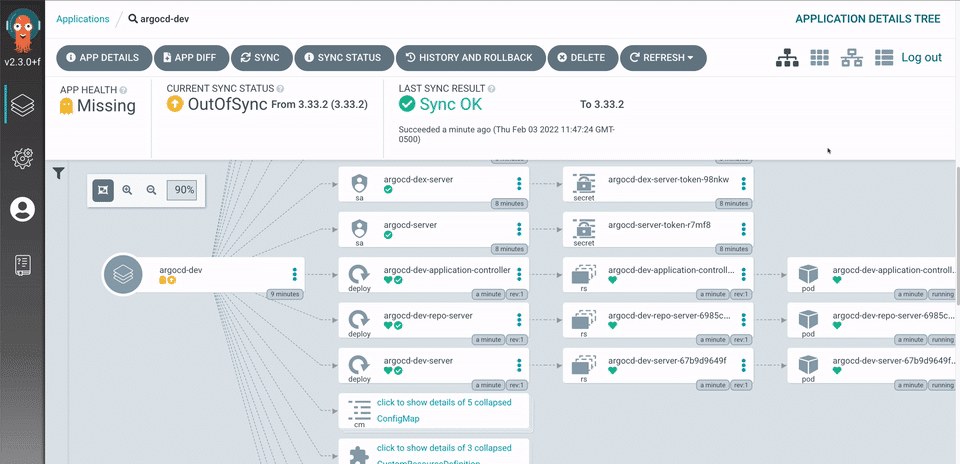
発生した障害によっては、ソースコードのロジックを戻すことで復旧できる場合も多くあります。このため、即座にイメージを差し替えることができる仕組みは、障害発生時に大きな効果を発揮します。改善コミットを本番環境にデプロイした後、不具合を検知した場合、ArgoCDのGUIを操作してアプリケーションのコンテナイメージを速やかに(1分未満の作業時間で)変更できます。まずはサービスを回復させ、その後、不具合を修正する恒久的な対応に集中できます。
この対応は、Sentryによる監視との連携で実現されています。アセンドではSentryを導入しており、フロントエンド・バックエンドの両方で発生したエラーをSlackチャンネルに通知する仕組みを構築しており、障害原因の調査や迅速な検知に役立てています。

ポストモーテム(障害振り返り)による学びと資産化
〜二度と同じ障害を引き起こさないための仕組みづくり
障害を解消した後は、その事実を正面から受け止め、二度と同じ事象を起こさないための仕組みを構築することが重要です。アセンドでは、障害発生後に関係者が集まってポストモーテムを開催し、チーム一丸となって再発防止のアクションを明確にしています。
ポストモーテムの基本的な哲学・考え方に関しては、Googleの以下の資料をご参照いただけますと幸いです。
さて、アセンドのポストモーテムはNotionのDB機能を用いてテンプレート化されており、障害からの学びを資産化しやすい仕組みが整っています。また、このテンプレートの肝は振り返り観点が網羅的に作られていることであり、これにより、対策を抜け漏れなく考えられるようにしている点が特徴的です。今回は、アセンドにおけるポストモーテムのテンプレートについてご紹介します。

まず、障害についてチーム全員が向き合えるよう、基本的な情報をまとめます。これは障害当事者がポストモーテム開催前に記載しますが、障害対応スレッドに記録が残っているため、記載のコストはそれほど高くありません。
・障害サマリ(障害事象と原因を記載)
・原因と対処内容(根本原因、暫定対応内容、恒久対応内容)
・影響状況(障害発生期間、影響テナント数、影響レベル・内容)
・タイムライン(障害原因発生、検知、対応開始、暫定対応、恒久対応)
・補足情報・背景情報
続いて、障害の概要が共有され、チーム全員が共通認識を持ったところで、KPT形式で障害を振り返ります。KPT実施前に、振り返りの観点や軸を簡単に確認し、各個人がKPTを記載します。以下のカテゴリーに沿って、継続すべきこと(Keep)、問題だったこと(Problem)、試してみるべきこと(Try)を記載します。

・要求・仕様整理
・バグの起きづらいコーディング
・コードレビュー
・ルールの型化
・作業のコード化
・動作確認・テスト
・リリース作業
・監視
・通知
・障害影響の低減
・原因特定
・障害対応作業
・障害時のコミュニケーション
KPTの記載が終わったら、チームで全体を見渡し、深掘りすべきトピックについて議論し、次のアクションを決定します。アセンドのポストモーテムは、障害対応を個人の責任とせず、チーム全体で向き合うことで、高品質で妥当かつ現実的な対策・改善策を導き出す仕組みとして活用されています。
また、「ポストモーテム自体の振り返り」も行い、会全体の改善の余地やテンプレートの改善点を検討しています。取り組みを始めて数年が経ち、今までの取り組みと改善を経て現在のテンプレートに至っていることを補足しておきます。
まとめ
今回は、アセンドにおける障害への取り組みをご紹介しました。障害を完全になくす「銀の弾丸」は存在しないと理解しています。だからこそ、日々やるべきことを愚直に、真摯に取り組むことが大切だと私は考えています。
最後に、今回ご紹介した内容に共感していただけた方、ぜひ一緒に働きませんか?カジュアル面談からお気軽に、こちらからお問い合わせください。
この記事が気に入ったらサポートをしてみませんか?