

#機械学習初心者


お絵描きAIに使われるGANと拡散モデルについて初学者向けに解説してみた(その1 : オートエンコーダー編)
こんにちは、こんばんは teftef です。今回はいよいよ Diffusion Model についての記事です。Diffusion Model は NovelAI や Stable Diffudsion , Midjyouney にも使われている生成モデルの一つです。これまでは生成モデルの覇権をとっていた GAN について 3 記事ほど書いてきて、「 GAN ってすごいよ!」というのをさんざん言
もっとみる
AI を自分好みに調整できる、追加学習まとめ ( その3 : DreamBooth )
こんにちはこんばんは、teftef です。今回も追加学習手法についてです。今回は DreamBooth、前回の記事の Textual Inversion に似ていますが、これはこれでまた一味違った手法になっています。Textual Inversion との違いを比べつつ、書いていこうと思います。私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください
もっとみる
AI を自分好みに調整できる、追加学習まとめ ( その5: LoRA)
こんにちはこんばんは、teftef です。今回も追加学習手法についてです。これまで説明してきた Diffusion Model のファインチューニングでは一般的に Unet , Text Transformer の再学習を行いました。しかし、全てのパラメーターを再学習するには時間がかかってしまいます。今回はファインチューニング後のモデルの品質を下げず、省時間、省メモリの手法を実現した軽量化手法、
もっとみる
ComfyUI で動かす Stable Diffsion XL
こんにちはこんばんは、teftef です。今回は話題の Stable Diffusion XL についてです。と、言っても使い方の記事は調べればいくらでも出てくると思うので、主は依然として論文解説をします。使い方を見に来たという方々にとってはその目的にに沿わないと思うので、主が特に分かりやすいと思った記事を下に張っておきます。今回は SDXL が条件付けとして画像のサイズを使用していることについ
もっとみる
CLIP は赤い丸の意味を理解できるのか?新たな Prompt engineering の話
こんにちはこんばんは、teftef です。私たち人間は、画像に赤い丸がついていると、無意識にその丸の中身が重要なものであると判断すると思います。果たしてそれは大規模視覚言語モデル (LLM) の CLIP も同じような挙動をするのでしょうか?
今回は言語情報 (Prompt) の代わりに特定の視覚的情報を与えることでCLIPがその領域に注目できるかどうか、また視覚的情報が言語情報の代わりになる

CyberAgent より、画像生成タスクにおける新たな評価指標の提案
こんにちはこんばんは、teftef です。今回は CyberAgent より、生成モデルから生成された画像の品質評価に関する論文です。近年の画像生 AI の発展によって、『高品質』な画像が生成できるようになりました。しかしよくよく考えてみると『高品質』というのは何でしょうか?人間の好みが違いをどのように評価するのでしょうか?今回はそこについて軽く書いていきます。
私もまだ初学者であり、説明が間
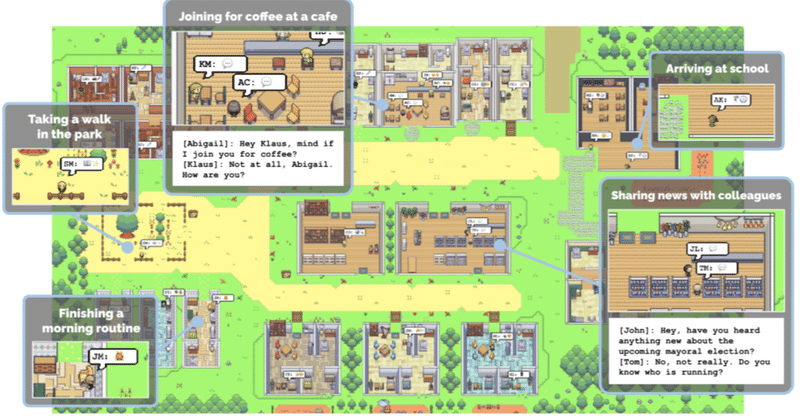
エージェント論文:Chat GPTによる人間社会のシミュラクラ
こんにちはこんばんは、teftef です。今回はシミュレーションゲーム「ザ・シムズ」にインスパイアされた、スタンフォード大学と Google の共同研究である「エージェント論文」です。ChatGPT を用いた 25 人の AI エージェントを実際に 2 日間動かし、どのようになったかを調べました。町の様子や家具の動作、人間関係など設定がかなり凝っていて、実世界にかなり近い結果となっています。
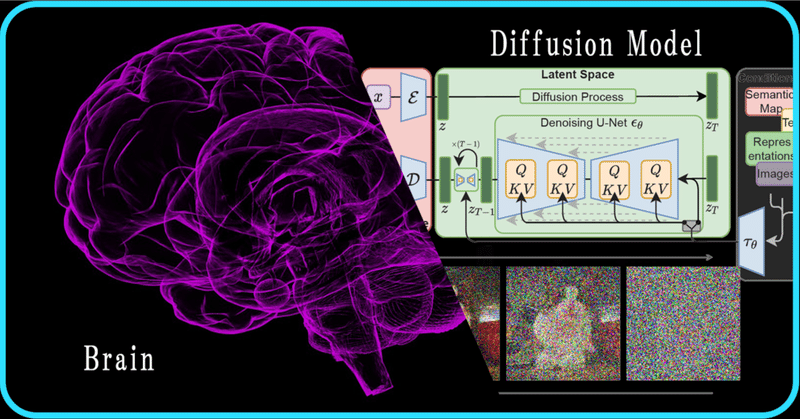
fMRI から画像を生成する話
こんにちはこんばんは、teftef です。今回は大阪大学から出た fMRI 画像から Stable Diffusion を用いて画像生成する論文をベースに Brain 2 Image について書いていこうと思います。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、

AI を自分好みに調整できる、追加学習まとめ ( その6: Instruct Pix2Pix )
こんにちはこんばんは、teftef です。今回は画像に対して text を用いて操作内容を指示し、元画像と大きく離れることなく指定した内容を編集する手法、Instruct Pix2Pix です。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。
使用した論文 今回、使用した論文

AI を自分好みに調整できる、追加学習まとめ ( その4: Imagic )
こんにちはこんばんは、teftef です。今回も追加学習手法についてです。今回はTextual Inversion , DreamBooth に引き続きファインチューニングの変わり種である Imagic についてです。Imagic はファインチューニングに用いる画像が入力画像の 1 枚の 1 shot の手法で、その入力画像の固有性を維持しながら、画像編集ができるという手法です。
私もまだ初学

馬をシマウマに、シマウマを馬にするCycle GAN のおはなし(論文解説)
こんにちは、こんばんは、teftefです。NovelAI が登場したのでここ最近の記事は作品、Prompt 紹介をでいっぱいになっていました。少し前に敵対的生成ネットワーク、通称 GAN について基本的なところについて書きました。記事を載せておきます。今回はいくつかある GAN うちの中でもCycle-GANについて書いていきたいと思います。前半では高校生レベルの数学の知識があれば理解できる内容
もっとみる