
CLIP は赤い丸の意味を理解できるのか?新たな Prompt engineering の話

こんにちはこんばんは、teftef です。私たち人間は、画像に赤い丸がついていると、無意識にその丸の中身が重要なものであると判断すると思います。果たしてそれは大規模視覚言語モデル (LLM) の CLIP も同じような挙動をするのでしょうか?
今回は言語情報 (Prompt) の代わりに特定の視覚的情報を与えることでCLIPがその領域に注目できるかどうか、また視覚的情報が言語情報の代わりになるのかについて考えます。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。

それでは行きます。(今回これを選んだ理由 : タイトルが面白かったから)
論文
今回参考にさせていただいた論文はこちら
VLMs と LLM
近年 GPT-3などの大規模自然言語モデル (LLM) の驚くべき進化によって、自然言語間の翻訳や要約を行うことができます。特に近年の chatGPT のようなモデルは膨大な量のコーパスを学習させることによることで、事前に学習されたデータをもとに学習していない新しい概念のタスク (ゼロショット) をこなすことができます。
CLIP
CLIP は Vision-Language Models (VLMs) という、画像とテキストを同時に扱うモデルの一種であり、マルチモーダルなタスクに対応するモデルです。自然言語による指示 「Prompt」を入力とし、画像の生成、分類、検索を行ったり、逆に画像を入力とし、その画像を自然言語を用いて説明をするというタスクも行います。CLIP は OpenAI がインターネットに大量に落ちている 画像-text のペアを学習させることで、ペア間の関係を理解することを目的としています。特に学習データに存在しないようなデータやカテゴリに対して、新しく学習をすることがなく高い性能を発揮します(ゼロショット)。
マルチモーダル性
マルチモーダル性というのは、複数のデータ形式(例:テキスト、画像、音声)を組み合わせて情報を処理する能力のことです。マルチモーダルなモデルは、異なるデータタイプを同時に扱い、相互の関連性を学習し、それらの結果を得ることができます。より複雑で高度なタスクに対応することが可能となります。簡単に言うと異なる領域 (分野) のマルチタスクができるAIです。
CLIP のマルチモーダル性
今回のテーマである CLIP は Prompt として 「Xの画像」と入力することで,与えられた画像との適合性をチェックし、ゼロショットで画像を分類するタスクに使用することができます。このように LLM と同様、Prompt を工夫することで CLIP は様々なタスク(分類、検索など) をこなすことができます。しかし、重要なのは CLIP を含む VLMs というのはマルチモーダル性を持ち、自然言語 以外にも画像というモダリティを操作することができるということです。
今回の論文の目的は、VLMs である CLIP が自然言語と画像の2つのモダリティを持つマルチモーダルなモデルであることを利用し、自然言語である Prompt だけでなく、画像を操作することを通じて自然言語のみでは表現できないような新たな表現を得ることです。
今回の目標
以上をまとめると
ゼロショットで VLMs から有用な情報を抽出するための、より実用的なツールを提供すること。
VLMs とその学習データの興味深い特性を明らかにし、倫理的な懸念を引き起こす可能性のあるいくつかの動作を特定すること
簡潔に言うと CLIP が自然言語と画像の両方を操作できるという特性 (マルチモーダル性) を利用して、画像分類や質疑応答などの性能向上を目指します。
手法
Prompt engineering
VLMs は 画像 と Prompt のペアを比較することによってさまざまな能力を持っています。今回は適切な Prompt を作成して画像の中の特定の要素の場所を探すタスクに特化します。
例えば以下のような画像を用意して、探索タスクを与えます。この画像にはキャプションとして、「犬、公園、猫、様々な動物が遊んでいる」がついています。

今回のタスクは画像から「赤いスカーフをまいた猫」を探します。これに対して、質問 q :「赤いスカーフをまいた猫はどこにいますか?」と CLIP に投げかけるだけでは回答を得ることができません。
VLMs は、画像とテキストの互換性スコアを計算することができますが、質問 q と回答 a を直接関連付けることはできません。ここで適切な回答を得るために、プロンプトエンジニアリングを行います。これは VLMs が質問 q と回答 a の関連性を評価できるように、キャプションテキストを変更(エンジニアリング)する方法です。適切に Promopt engineering をすることでこれを解決することができます。例えば
質問 q :「様々な動物が公園で遊んでいます。赤いスカーフをまいた猫の位置は(x座標, y座標)にあります。」と入力することで、座標 (x,y) を求めるように誘導することができます。このように自然言語の Promopt engineering を行うことで、最初の質問 q に比べて高い確率でタスクを成功させることができるようになります。
情報損失
しかし、自然言語の Promopt engineering だけでは表現ができないことがあります。これは主の記事で何度もネタにしたのですが、画像と言語というのは大きく情報量の差があります。頭の中で思い浮かんだ画像を他の人に伝えてみたくても、完全に伝わる可能性は限りなく低いです。そのため、画像の情報を一度、自然言語に変換することなく画像生成するという手法があります。Textual Inversion や GAN inversion などがこれにあたります。
マルチモーダルな Prompt engineering
この論文では CLIP は自然言語と画像の2つのモダリティを持つマルチモーダルなモデルであることに注目します。つまり、 Prompt engineering として入力する画像も変更を加えることができます。
質問 q :「様々な動物が公園で遊んでいます。赤いスカーフをまいた猫の位置を表している画像はどれですか?」
と以下のような Prompt engineering を施した複数枚の画像を入力します。

このように、Prompt engineering とマルチモーダルなアプローチを組み合わせることで、VLMの能力を最大限に引き出すことができます。
画像の Prompt engineering
それでは、画像に対してどのような操作をするのでしょうか。様々な条件を用意して比較して、最も有効であった方法を探します。
手法
まずは以下の条件を用いて、画像の Prompt engineering として最適な方法を探します。
何もしない
画像の一部を切り抜く(クロップ)
画像に目印となるようなものを付与する (赤丸)
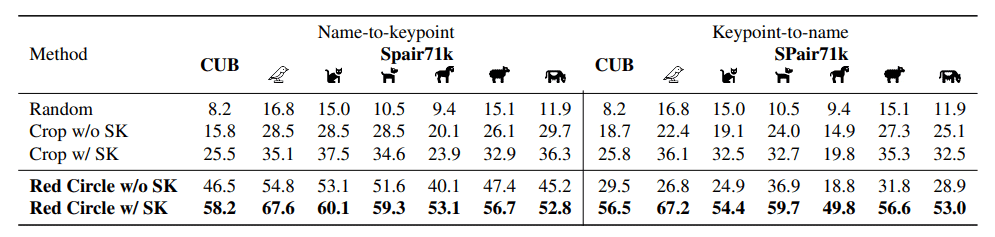
結果として、 3 番の「画像に目印となるようなものを付与する」の結果が最も高い精度であるとわかりました。
付加する画像
続いて「画像に目印となるようなものを付与する」中でもどのような図を付加するべきなのかを調べます。条件として、円、矢印、四角、バツ印の 4 種類を用意します。

結果として上のように円を画像に付与することが最も高い精度であるとわかりました。
色
円が最も精度が良いということがわかった上で、色による変化も調べます。赤、緑、紫、青、黄の 5色の円を用意しそれそれについて精度を調べました。

結果として赤が最も高い精度であるとわかりました。
モデルの手法とパラメータ数
最後にモデルの大きさによる違いも調べます。

パラメーター数が上がると精度が上がっていることがわかります。また CLIP は他の手法に比べて群を抜いて精度が高くなっていることがあります。その中でも赤枠で囲んだ部分が高精度を保っていることがわかります。
考察
図形と色
まずは画像に対して図形を付与したことについて。画像の一部を切り抜く(クロップ)する手法では、クロップした部分以外の情報が失われてしまいます。画像の情報が失われてしまうと精度が下がってしまうことは直感的にも自明です。それに対し、画像に赤丸を付与すること画像の情報をほとんど失わないと考えられます。
続いて赤丸が最も適した図形と色であることについて。これは学習データセットに赤丸を含んだデータがあると考えられます。実際にYFCC15Mの中にマーカーを含む画像を見つけ、ViT-B/16とRN50x16 CLIPビジョンエンコーダのアンサンブルを使用してバイナリ分類器をトレーニングしました。その後、この分類器を使用して、YFCC15Mの6Mのサブセットをフィルタリングし、最もスコアの高い上位10,000の画像を取得しました。最後に、10,000の画像を手動で調べ、注釈が上に描かれた70の画像を見つけました。しかし含有量は非常に稀であり(約0.001%)これだけではまだ、データセットの影響が大きいという結論、考察にたどり着くまでが弱いので、手法とデータセットの違いについて考察をします。
データセットとパラメーター数
先ほどと同じ図を以下に示します。

これは使用したモデルの手法、パラメーター数及びデータセット数とそれらを用いて画像に赤丸を付加した時に分類タスクを行った際の精度です。
これを見ると学習データセット数が多い CLIP は群を抜いて精度が高くなっている傾向があります(青枠)。そしてどの手法においてもパラメーター数が上がるにつれて精度向上の傾向が見られます(緑枠)。

以上の結果をグラフにまとめるとこのように、パラメーター数が大きければ大きいほど、精度が上がっていることがわかります。またこのグラフを見るとパラメーター数と精度は比例関係ではなく、パラメーター数が一定以上を超えると大幅な精度向上となっていることが考えられます。
そして以上を踏まえて、データセットの中身に赤丸の含有率が低くても高精度のパフォーマンスを出せるような考察として、高パラメーター数のモデルを非常に大規模なデータセットから学習することで、このように未知のタスクに対する高い性能を引き立出し、優れた結果を生み出す可能性が高くなり、ことが考えられます。
偏りによる倫理的問題
データセットの偏りというのは非常に大きな問題となります。例えば Google では黒人の画像に対して「ゴリラ」とラベル付けしたことが問題となっています。この問題には画像データセットの中で特定の人種や肌色、性別の属性が少ないことに原因があることがあります。これは今回の論文でも問題になることがあります。
例えば、COCOデータセットから無作為に選ばれた男性と女性が写っている画像を取り上げ、その画像と、各個人に円を描いた画像を、「男性」、「女性」、「行方不明者」、「容疑者」の4つのカテゴリにゼロショットで分類するタスクを実行します。注釈された人物の性別を正しく識別できる一方で、注釈された画像は行方不明者や殺人犯を含む画像として分類される可能性が高くなります。
これは、CLIPモデルの学習データに、行方不明者の報告や警察の映像など、人物にマークが付けられたデータが含まれているためだと考えられます。

このような問題は非常にセンシティブな結果を出力することがあり、今後の倫理問題を左右する可能性を含んでいます。これを解決するためにデータセットの偏りをなくすことやモデルの学習時に偏りをなくす工夫もされています。しかし私は、偏りを 0 にすることは不可能なので、何かしらの倫理的基準を設ける必要があると思っています。
結論
今回は VLMs である CLIP にタスクを与える際に、画像に赤い丸を付けるくふうをすることで精度上昇がみられるという論文でした。一般的に自然言語と画像間では、意味論的な表現にはテキストモダリティが適していますが、位置などの幾何学的な表現にはビジュアルモダリティが適してることから、自然言語のみではなく、画像を編集することも効果的な Prompt engineering になっていることがわかりました。また、これはすべてのモデルに共通したことではなく、モデルのパラメーター数や学習に使用したデータセット数に大きく依存することがわかりました。
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(5500字、teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?