
AI を自分好みに調整できる、追加学習まとめ (その2 : Textual Inversion )

こんにちはこんばんは、teftef です。昨今のAI画像生成において、既存のモデル以外にも、独自の「絵柄」や「画風」を出力できるようにした『オリジナルモデル』を制作する方々が増えています。しかし個人が 0 からモデルを学習させるには膨大な時間と計算量を必要とするため、既存のモデルをベースに学習する「追加学習」と呼ばれる手法を使用することが一般的でしょう。追加学習の大雑把な解説は前回の記事をご覧ください。今回はその追加学習の中でも少量のデータセットで学習できる "Textual Inversion " について書いていきます。それでは行きます。
使用した論文
今回、使用した論文はこちら
モデル
まずは少し復習です。この先「モデル」という言葉を多用しますが。混乱が起きないために意味を正確にしておきます。この記事において「モデル」は関数のようなものを表します。世の中にあるすべての画像データ [ X1 , X2 , X3 … Xn ] を取り出すための関数 P(X) を考えます。P(X) に頼んで何か画像を出してもらいましょう。すると取り出される画像は毎回違ったものなのです。おそらくこれは確率的であるだろう、つまりこれを生み出す確率分布があるだろうというのが根本となる考え方です。そしてこの P(X) を作ることができれば、好きな画像を出力、生成してくれるはずです。しかし P(X) は世の中にあるすべての画像データが必要なので作成は不可能ですね。そこで、数百、数千万の大量のデータを持ってきたものを P(X) とみなし、それに最も近づくように P(X) ≈ q(X) となるように q(X) を最適化(学習)して創ります。このq(X) こそが私たちの扱っている「モデル」であり、その「モデル」を定義する数値が .ckpt なり .pkl といった拡張子のファイルの保管されているのです。
一言でまとめると、何か数値を入れると望んだ画像を出力してくれる一種の関数のようなものが「モデル」です。
問題提起
長くなりましたが、ここからいよいよ本編 "Textual Inversion" についてです。
自然言語を入力すると画像を出力してくれる Text-to-image モデルはとても自由度が高いモデルであり、私たちの思い描くものを自然言語から創ることができます。例えばトイ・ストーリー 3 に出てくる、あの受付でシンバルを持ったサルを出力させてみます (権利的にやばそうなので敢えて元画像は載せません) 。固このキャラの固有名詞を入れるとデ〇ズニーに消されそうなので今回の Prompt は「monkey, holding cymbal plush ,toy」とでもしておきましょう。

えーっと、シンバルじゃない!!そしてあの怖さがない。まあ Prompt を工夫すればもっといい感じになるんでしょうけれど、固有名詞を使ってはいけない以上、 Prompt が長すぎてしまします。midjourney や Stable Diffusion を使用している方は体感でわかるかと思いますが Prompt が長すぎると(75 Token 以上)最後のほうは切り取られてしまします(回避方法は普通にあるが…)。また、最初のほうに入れたものと最後のほうに入れたもので出力結果に及ぼす影響が異なります。そして何より、今回はトイストーリーを知っている方々なら知っているだろう共通認識の固有名詞が存在しますが、例えば個人所有のもののように、その人にしかわからないものもあります。そもそも画像を言葉で説明しても人によって思い浮かべるものは違うので、言語化困難と言えます。つまり
共通認識のある固有名詞が存在しない (個人の所有物など)
言語化することが難しい
ようなものを Text-to-image モデルに出力させることはいまだに困難なのです。
画像を新しい単語を"創る"
text 埋め込み( Embedding )空間
これを解決するために画像から text 埋め込み( Embedding )空間に新しい単語を見つけることを提案しています。私たちが入力した Prompt は Tokenizer というものを通じて数値(ベクトル)に変換されます。この自然言語が数値(ベクトル)として表されているものが text 埋め込み( Embedding ) というものです。もちろんテキトーな数値(ベクトル)ではなく、学習済み NLP (自然言語処理) モデルを通して、"意味のある" 数値(ベクトル)となっています。そしてこの数値(ベクトル)たちは text 埋め込み( Embedding ) として text 埋め込み( Embedding )空間に 存在してい (Mapping され) ます。
擬似単語 S*
ここで「うちの猫」の画像を3~5枚ほど用意します。こいつです。

これを Inversion 処理によって text 埋め込み( Embedding )空間で探します。探し方は少し後に書きます。とりあえず「うちの猫」の text 埋め込み( Embedding ) を見つけることができたとします。これを v* と置きます。この v* になった元の単語を擬似単語 S* とします。これまでの操作で擬似単語 S* を使って、この絵を画像のまま言語で表現できているというわけです。そしてこの擬似単語 S* を使用して”A S* in the beach" や "A photo of S* "といったように Prompt として使えば「うちの猫」を生成された絵に登場させることができます。
画像生成の流れ
論文ではこのような図で説明されています。ユーザーが用意した画像、右上の時計、 Input Image をベースに作成した擬似単語 S* を "A photo of S*" として Tokenizer を通じて text Embedding v* に変換します。ここで "A photo of S*" の「A photo of」の部分は自然言語と同じ扱いであることに注意です。あくまでも擬似単語 S* の部分が少し特殊なのです。続いてこれを text Transformer を通して condition として Generator (Unet 部分)に渡します。画像生成の際、 Generator はこの text Transformer を通った後の情報を元に Denoise し画像を生成します。
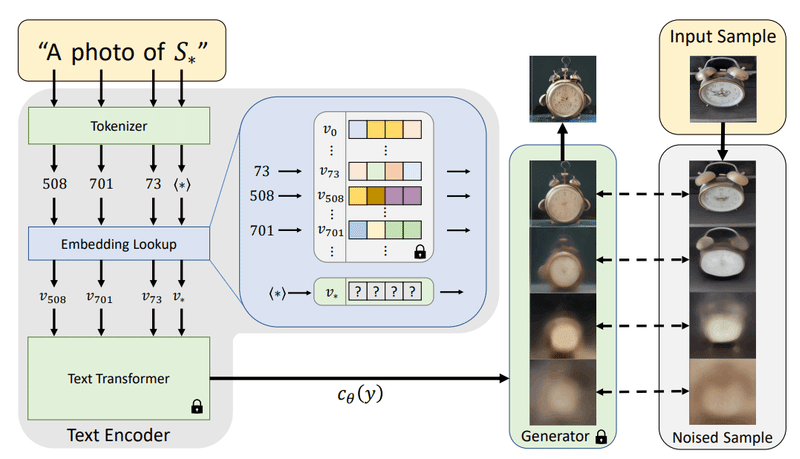
やっていることを直感的に、簡潔に、まとめると
ユーザーが用意した画像をとても忠実に再現できる何らかの擬似単語 S* を探して、それに変換します。
Tokenizer を使って text Embedding に変換します。
Text Transformer を使って Generator (Unet 部分) に渡して画像生成します。 (Text Transformer と Unet の再学習をしてないことに注意)
このようなことをやっています。
擬似単語 S* を探す
Latent Diffusion Models (LDM) の損失関数
まずは Latent Diffusion Models (LDM) を使ったオートエンコーダーを考えます。観点に説明すると入力画像 x をエンコーダーを通じて潜在空間に落とし込み、それを拡散過程を使用して (潜在変数に拡散モデルを適応する) デノイズするというプロセスです。デノイズの時の損失関数を書いてみます。

これはデノイズの t ステップ目で画像のノイズを正しく(元の画像 x になるように)除去することを目的にしています。正しい潜在表現 z であれば正しくデノイズされ、最終的に元の画像 x になるはずです。
擬似単語 S* を最適化する
いよいよ擬似単語 S* を探索します。まずはこの時の損失関数の式を見てみましょう。

この式、上で見た LDM の損失関数と同じですね。初めは何らかの擬似単語 S* を用意し Embedding v* に変換し、これをベースに LDM で画像を生成します。で、この時に臨んだ画像 にデノイズされればok , うまくデノイズできなければ逆伝搬によって v* を調整していき、最適化します。意外と強引ですね。というかこれは再構成損失と近いもので、直感的には「入力画像を表す擬似単語 S* を作り、新しくデノイズされて生成された擬似単語 S* の要素を含んでいる画像は入力画像と近いEmbedding になるはず」と考えれば確かに再構成に近いとわかります。
生成結果
再構成
それでは実際に生成結果を見てみましょう

縦に見ていきましょう。一番上の行が入力画像で、目的としてはこれらの画像を作ってほしいことです。まず左の列は何とも独特なコップですね。左の列の最上段の画像を作りたいのですが、これを言葉で頑張って説明したのが
"A mug having many skulls at the bottom and sculpture of a man at the top of it."
「下部にたくさんの骸骨があり、上部に男性の像が掘られたマグカップ」
"Mug or vase featuring grouchy faced native standing on skulls"
「どくろの上に立つ不機嫌な顔の原住民をモチーフにしたマグカップや花瓶」
と、この文章だけみても絶対に想像できません。そしてこれらの Prompt を用いて作った出力画像はもう原型をとどめてないですね。それに対してこの 2 行目 (Ours の行) には Textual Inversion で生成した結果です。原型を保っていることがわかります。

同様に他の列を見てみても、一番右下のアラジンのランプではもはや別のランプになっています。真ん中のティーポットはフルーツが出てきてしまったりしています。に対して 2 行目はしっかりと 1 行目の画像の中の被写体を再現できています。

Text-Guided synthesis
入力の画像の Style を保ちつつ、他のものにその Style を反映させます。

横に見ていきます。1行目、左の Input samples 風の画像が右の車、Lego人形、服、スケッチに反映されています。2行目のティーポットも同様に見事にペルシャ風の絵柄が反映されています。
2 つ以上の要素を掛け合わせる
擬似単語 S* を2つ使って生成することも可能です。このように4種類の画像群を用意しそれらを擬似単語 S* に変換し、2つ選んで混ぜ合わせます。この交ぜ方によってそれぞれの特徴を保ったまま、画像生成することができています(2行目)。

Style transfer
入力画像 "風" の画像を作ることができます。横に見ていきます。ます1行目一番左の入力画像のを擬似単語 S* にして、 好きなPrompt に " ~ in style of S* " とつけて画像生成します。するとこのように入力画像 "風" の画像が生成されました。2行目も同様です。

Textual Inversion を "試す"
Textual Inversion は Stable Diffusion WebUI で実行することができます。3~5枚ほどの画像で試すことができるので、とても簡単にできます。今回はそのマニュアルを載せておきますが、後で「Textual Inversion 始め方ガイド」を書く予定です。また npaka さんのGoogle Colab で試せる記事も載せておきます。
Textual Inversion in SD WebUI
Google Colab で Textual Inversion を使う
参考文献
次回予告と宣伝
今回は追加学習の1手法、 Textual Inversion を論文ベースにまとめました。それぞれの実装方法に関してはまた後々記事を書こうと思っています。また実際に試した記事も書きたいと思います。次回は追加学習 DreamBooth についてです。
近頃の追加学習ブームを鑑みて、個人が追加学習したモデルを Google Colab で使えるようにまとめたノートブックを配布予定です。その前にそ Cool Japan Diffusion , acertainthing , Waifu diffusion など様々なモデルを切り替え一つで変更できる Google Colab ノートブックも配布しています。
https://t.co/XjBcKXPmvZ
— teftef (@hanyingcl) December 13, 2022
Colabで動かすStableDiffusion (改)
追加要素
・モデルを選択 (cjd,sd1.5,ACertain,any)
・サンプラーを選択
・Seed及びRandom Seed (-1)を選択できるようになりました@ArtengMimi
(kizamimiさん)協力#StableDiffusionWaifu #CoolJapanDiffusion #StableDiffusion https://t.co/Up8I8r7FGt
追加学習をやってみたい方はこちらの記事より
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
この記事が気に入ったらサポートをしてみませんか?