
AI を自分好みに調整できる、追加学習まとめ ( その3 : DreamBooth )

こんにちはこんばんは、teftef です。今回も追加学習手法についてです。今回は DreamBooth、前回の記事の Textual Inversion に似ていますが、これはこれでまた一味違った手法になっています。Textual Inversion との違いを比べつつ、書いていこうと思います。私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。
使用した論文
今回、使用した論文はこちら
問題提起
近年の画像生成モデル Midjourney , Novel AI や Stable Diffusion などは自然言語で構成された Prompt をベースに多彩な(高品質)画像を生成してくれます。しかし前回の Textual Inversion でも言いましたが、与えられた画像中の固有の被写体をほかの文脈で生成させる能力はありません。毎度おなじみ、うちの猫で説明すると

この猫のことを知らない人に "言葉のみ" で説明するのはとても難しいですよね。「丸太から顔だけをのぞかせている白黒の猫で、アニメ調の画風」とでも言いますか。これを nijijourney に入力してみましょう。

このように全く違ったものになってしまいます。
共通認識のある固有名詞が存在しない (個人の所有物など)
言語化することが難しい
ようなものを Text-to-image モデルに出力させることはいまだに困難なのです。(という話は Textual Inversion でしました)
従来手法
DALL-E 2
これを解決するために考えられた手法として、言語-視覚の共有潜在空間(shared language-vision space)を作るというものがあります。言語-視覚の共有潜在空間というのは、(Text-to-image) 潜在空間において、同じニュアンスを表す画像と言語間で、言語から Encode しても画像から Encode してもそれらの特徴ベクトルが近い場所に Mapping されるように設計した空間です。言葉で説明するより図を見たほうがわかりやすいと思います。
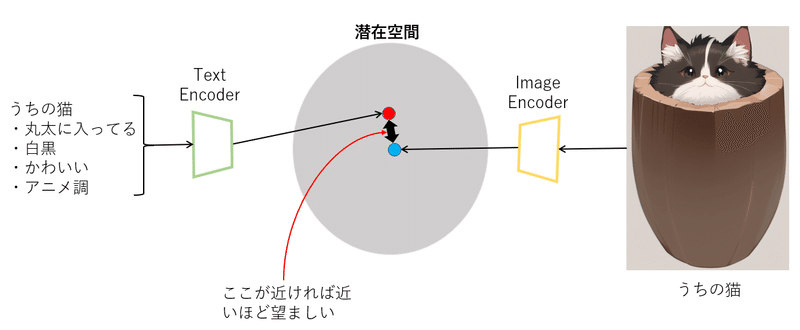
DALL-E 2 では CLIP 潜在空間がこのようにな言語-視覚の共有潜在空間 (shared language-vision space) になっていますが、 下図の Input Images の時計が忠実に再構成できていません。また背景も入力と同じになってしまっています。そもそも CLIP 潜在空間に存在していない (学習されていない) 表現を出力することが不可能です。
Imagen
また Imagen (DALL-E 2 とは異なりアップスケールを何回も行って、その都度 Prompt に沿った画像に指定していく手法) では背景が変わっていますが、 Input Images の時計を再現できていません。

本論文の目標
Subject-driven generation : 入力する被写体の視覚的特徴を維持しつつ (つまり固有性は崩さず)、異なる文脈で被写体の表現を合成すること。つまり、被写体を異なるシチュエーションでも崩さずに生成できるようにすること
しかし入力する被写体の意味 (Semantic knowledge) を維持しながら数枚の画像のみで U-net をファインチューニングする。例えば、「うちの猫」の画像を入力したときに、猫というクラスからは外れないようにする。
DreamBooth (大まかに)
DreamBooth の学習法はこのようになっています。
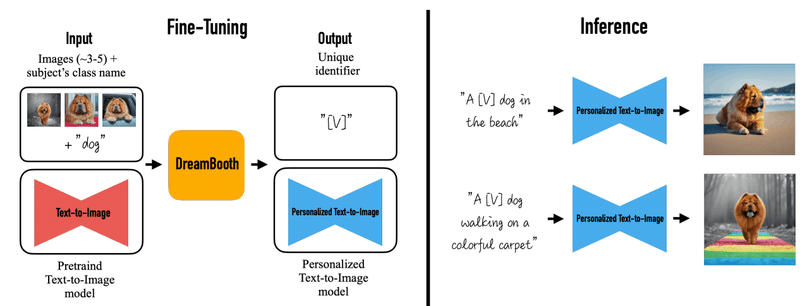
まず左の部分で学習済み Text-to-Image モデルと数枚の画像(左上)を用意してその Class (大まかな分類)を出しておきます。今回だと犬の画像なので "dog" Class となっています。これを DreamBooth することで画像はあるその固有の特徴とidentity,personality (固有性)をされた含む識別子 [V] (のちに説明する [Identifier] と同じ)として、これを使って学習済みモデルをファインチューニングします。するとこの識別子 [V] によって Personalize された (特定の個性が付与した) Text-to-Image モデルができます。この記事ではこれを Personalized モデルと呼びましょう。この Personalized モデルを使って "A [V] dog in the beach" のような Prompt を入れると右上の画像のように元の画像の犬が維持されたままの画像が生成されます。
DreamBooth (詳しく)
レアトークン
用意した画像を "a [Identifier] [class noun]" のような表現にします。一つ前に説明していた 識別子 [V] は [Identifier] のことです。ここで [Identifier] はその被写体の特徴を表す部分で、[class noun] は被写体の大まかな Class を Classifier (分類機) を用いて得ることができます。例えばこの写真だと "a [ V ] [犬]" のような感じになるんでしょうか。

ちなみに Textual Inversion の時のように被写体の特徴を表す [Identifier] のみを使って進めていくと学習時間が増え、性能低下するらしいです。

また [Identifier] では私たちが知っている有名な形容詞で表現すると単語が混ざってしまい性能低下してしまいます。単語を本来持つ意味から切り離すため、私たちの知らない単語を用意する必要があります。かといって "xxy5syt00" のように謎の文字列を使ってしまうと Tokenizer がこの1単語を複数のトークンに分けてしまう可能性があるため、よくないです。

そのためどちらにも当てはまらないような「レアトークン」を探す必要があり、T5-XXL トークナイザーの {5000 ~ 10000} の範囲のトークンを使用するといいと書いてあります。(上図)
要するにいい感じの単語を探しましょうということです。
オーバーフィッティング

DreamBooth では用意する被写体の量が少ないためオーバーフィッティングが起こりやすくなってしまいます。上の図のように、どの出力画像を見ても犬の外観とポーズが元画像と同じになってしまっています。この現象をオーバーフィッティングといい、ファインチューニングの時に Unet, Text Transformer の層を凍結せず、全層にわたって再学習することで解決することが経験的にわかっています。
言語ドリフト

しかしオーバーフィッティング防止のためにText 埋め込み(Embedding) による conditioning を受け取る Unet の層も再学習するので、言語ドリフトという問題が発生します。言語ドリフトはそのモデルを学習するにつれて、学習させる対象のクラス (今回で言うと犬)に関する知識を忘れていきます。拡散モデルに与える影響で、入力写真の被写体以外が出力されなくなってしまうということが起こります。
上の画像では、 Prompt から [Identifier] を抜いた "a [class noun]" ("A Dog") のみを入力した結果で、入力画像の犬を生成することしかできなくなってしまっています。このように DreamBooth したモデルを普通の通常の用途で使用したい場合、 Unet を学習するにつれて "犬" という概念を忘れてしまい、”犬” = "入力画像の犬" として認識してしまっています。
Prior-Preservation Loss
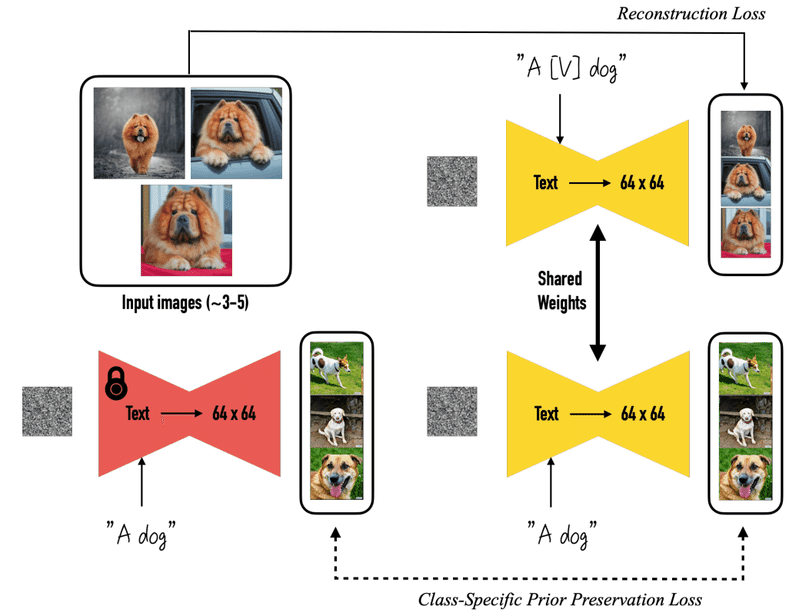

第 1 項目は Reconstruction Loss でPrompt "a [Identifier] [class noun]" を使用して生成した画像と入力画像を正確に再現できるように(再構成)する損失関数です。(画像上部)
第 2 項目は Class-Specific Prior Preservation Loss でこれも再構成です。今度は "a [class noun]" を使って生成し、その画像をファインチューニング前のモデルを使った生成画像と比較します。(画像下部)
そして λ はこの二つの項の重みを決めるパラメーターになっていてます。
これで 64×64 の画像を生成し、Imagin を使って1024×1024 にアップスケールもできます。
結果


このようにリュックの画像はワッペンの部分も再現されています。下のティーポットでは形を維持したまま透明にできたりしています。

このようにスタイル変換をしたり、

色を変えたり、犬と動物の中間をとったりすることもできます。
Textual Inversion と DreamBooth の違い
Textual Inversion では画像からそれに対応する text 埋め込み( Embedding ) v* を作り、この v* になった元の単語を擬似単語S* としました。しかしこの擬似単語S* によって表現できる幅はせいぜい「 a photo of S* 」,「 S* style」、「 S* on the tropical beach」のように自然言語を伴った拡張です。これでもある程度は表現できる幅が広がります。しかしこれは途中の埋め込み (Embedding) 空間で入力画像に近い表現を探しているだけで、結局は Text Transformer , Unet の再学習を行わない(簡単に言うとモデルを少しもいじらない) ので、モデルが学習した(データセットに依存した)表現しか出力されません。その点では DreamBooth は Textual Inversion より正確に被写体の再構成ができます。そして Prior-Preservation Loss のおかげで過学習が起こりにくくなります。しかし U-net を再学習するためその分の時間とGPUリソースを消費します。
以上それぞれの違いをまとめると (太字が利点)
Textual Inversion
Text Transformer , Unet の再学習を行わない
モデルが学習された表現しか出力されない
再学習しないので VRAM 消費が少ない , 1~2 時間かかる
DreamBooth
Text Transformer , Unet の再学習を行なう
モデルが学習していない表現も入力画像を学習するので忠実に再現できる
再学習するので VRAM 消費が少し多く , 4~5 時間かかる
DreamBooth を "試す"
DreamBooth は 3~5 枚の画像で高い再現性を持った画像を出力してくれます。しかし Textual Inversion に比べると要求スペックが高いので、ローカル環境の VRAM が足りない方は Google Colab をお勧めします。
参考文献
次回予告と宣伝
今回は Dream Booth を論文をもとににまとめました。実装方法に関してはまた後々記事を書こうと思っています。また実際に試した記事も書きたいと思います。次回は Imagic もしくは Tune a Video について書くと思います。
皆様がファインチューニングした様々なモデルを切り替え一つで変更できる Google Colab ノートブックも配布しています。
https://t.co/CJqXAJoa7E
— teftef (@hanyingcl) December 22, 2022
↑Colab で動かすStable Diffusion (Fintuning Model Ver 1.0)
個人がファインチューニングしたその方々独自のモデルが試せます
モデル提供いただいた方@8co28
様@nikaidomasaki
様@p1atdev_art
様
ありがとうございます#stablediffusion #WaifuDiffusion #AIart pic.twitter.com/g2UYJueC1c
追加学習をやってみたい方はこちらの記事より
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
この記事が気に入ったらサポートをしてみませんか?