
Google Colab ではじめる DreamBooth

「Google Colab」で「DreamBooth」を試す方法をまとめました。
1. DreamBooth
「DreamBooth」は、数枚の被写体画像 (例 : 特定の犬) と対応するクラス名 (例 : 犬) を与えてファインチューニングすることで、Text-to-Imageモデルに新たな被写体を学習させる手法です。愛犬の合成画像を生成できる画像生成AIとして話題になりました。

GPU 16GBで動くDreamBooth実装を作ってくれた方がいたので、「Google Colab」でも試せるようになりました。
・diffusers/examples/dreambooth at main · ShivamShrirao/diffusers
2. ライセンスの確認
HuggingFaceからStable Diffusionをはじめてダウンロードする人は、以下のサイトにアクセスして、ライセンスを確認し、「Access Repository」を押し、「Hugging Face」にログインして(アカウントがない場合は作成)、同意します。
3. 入力画像の準備
今回はうちの猫を学習させるため、写真を5枚ほど用意しました。

4. 学習の実行
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」に「GPU」を選択。
(2) GPUの確認。
16GB以上であることを確認します。
# GPUの確認
!nvidia-smi+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:04.0 Off | 0 |
| N/A 34C P0 24W / 300W | 0MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
(3) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/ShivamShrirao/diffusers
%cd diffusers/examples/dreambooth/
!pip install -r requirements.txt
!pip install diffusers
!pip install bitsandbytes(4) 入力画像を配置するフォルダを作成。
# 入力画像フォルダ 作成
!mkdir inputs(7) 入力画像をアップロード
左端のフォルダアイコンでファイル一覧を表示し、「/content/diffusers/examples/dreambooth/inputs」の「︙」でアップロードを選択し、入力画像をアップロード。
(8) HuggingFaceにログイン。
# Hugging faceにログイン
from huggingface_hub import notebook_login
notebook_login()(9) 学習の実行。
「instance_prompt」には、"a photo of sks <クラス名>"を指定します。クラス名は写真のオブジェクトが属する種別で、今回は猫(cat)になります。
# 学習の実行
!accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path="CompVis/stable-diffusion-v1-4" --use_auth_token \
--instance_data_dir=./inputs \
--output_dir=./model/data \
--instance_prompt="a photo of sks cat" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400 \
--use_8bit_adam「/content/diffusers/examples/dreambooth/model/data」にモデルが出力されます。(diffusersの形式?)
5. 推論の実行
(1) Stable Diffusionパイプラインの準備
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# StableDiffusionパイプラインの準備
pipe = StableDiffusionPipeline.from_pretrained(
"./model/data",
torch_dtype=torch.float16
).to("cuda")(2) 推論の実行。
from torch import autocast
# テキストからの画像生成
prompt = "photo of sks cat"
with autocast("cuda"):
images = pipe(prompt, guidance_scale=7.5).images
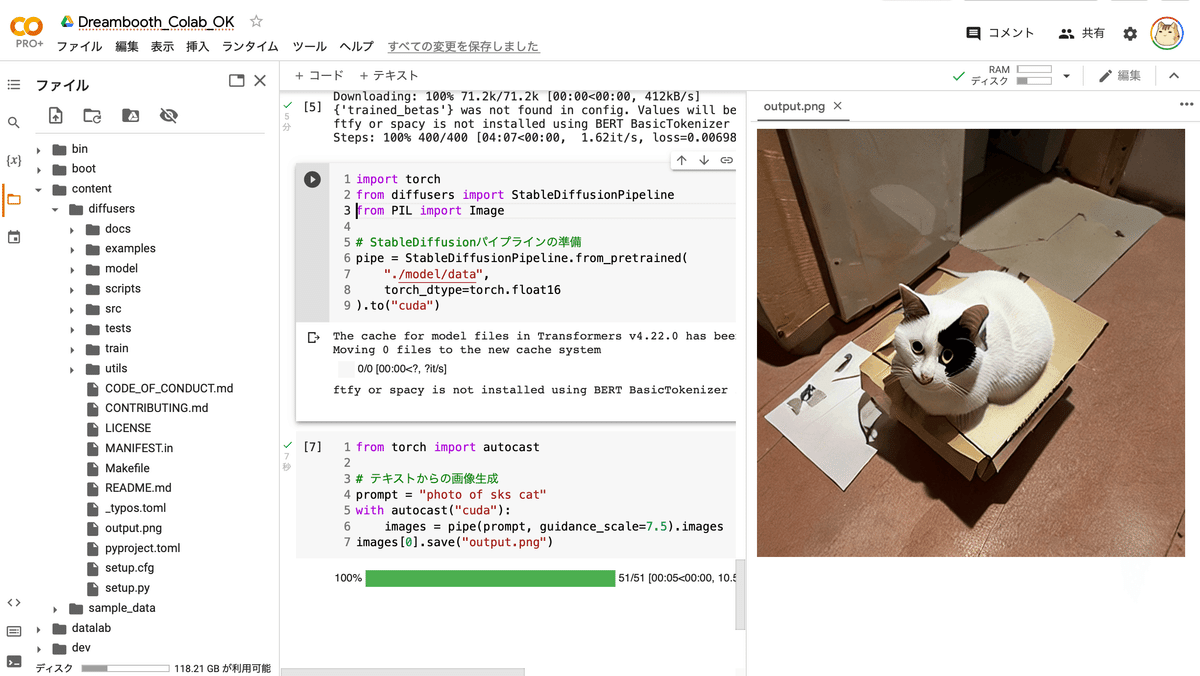
images[0].save("output.png")(3) 生成した画像の確認。
左端のフォルダアイコンでファイル一覧を表示し、output.pngをダブルクリックします。
・写真 (a photo of sks cat)
・油絵 (sks cat of oil painting)
・ぬいぐるみ (sks cat plush toy)
・ドット絵 (sks cat of pixel art)
・ロボット (robot of sks cat)
・スーパーヒーロー (super hero of sks cat)
・本物

6. 参考
公式のColabノートブックが動かなかったので、以下のColabノートブックを参考にさせてもらいつつ、公式のメモリ減らすオプションを追加してみました。
Colabで実行可能なDreamBooth & Stable Diffusionを作ったので公開https://t.co/YvzTTtI9wB#Dreambooth #stablediffusion #aiartcommunity #AiArtworks
— 2f6i (@2feet6inches) September 27, 2022
7. 関連
この記事が気に入ったらサポートをしてみませんか?