
Uber徹底研究 -因果推論によるマーケティング最適化編-

「Uber徹底研究」シリーズを久し振りに更新します。
[過去のUber徹底研究シリーズ]
・Uber徹底研究 -ビジネス概要編-
・Uber徹底研究 -UX改善編-
・Uber徹底研究 -ゲーミフィケーション・行動科学編-
・Uber徹底研究 -MaaSを支えるデータサイエンス編-
・Uber徹底研究 -「続き」MaaSを支えるデータサイエンス編 レコメンド-
今回はUberがマーケティング領域で使用する因果推論を、最新の論文を基に紹介していきます。
内容としては因果推論の領域なので、前々回と前回の内容からの発展編となります。
・前々回:ノーベル経済学賞でも注目の因果推論を俯瞰する
・前回:AIで原因と結果を把握する ~機械学習と因果推論の融合 Meta-Learner~
最もコスパの良いマーケティング方法を探る
前々回の投稿で紹介した"Uplift Modeling for Multiple Treatments with Cost Optimization"を具体的に紹介します。
・前々回の抜粋
Uberは複数の施策を顧客に行ったときに、どの施策が最もコストパフォーマンスが良いかをX-Learner,R-Learnerを改良した方法を用いて検証しています。
Uplift Modelingの手法を用いて、どの顧客にどんなチャネルでどのようなキャンペーンを打てばコストパフォーマンスが良いかを検証します。また、キャンペーン以外にも、アプリ内のデザイン・コンテンツ、その他変更可能な部分を戦略的にパーソナライズでき、誰に何をどのように提供すべきかが明確になります。
Uplift Modelingとは、介入による効果の最大化を目的としたモデル化の手法です。
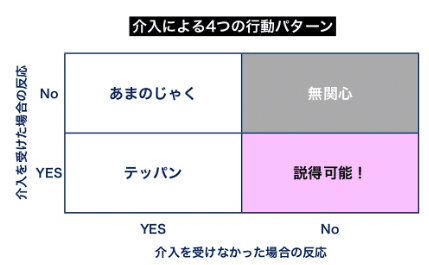
・左下:施策をしようがしまいが、反応してくれる鉄板ユーザ群
・右上:施策をしようがしまいが、反応しないため、無関心ユーザ群
・左上:施策をしないと、反応してくれるが、施策をすると反応しない あまのじゃく群
・左下:施策をしないと、反応してくれないが、施策をすると反応する説得可能群
(参考 : 2012-03-04 Uplift Modelling 入門(1))
X-Learner, R-Learnerを改善した提案手法
本論文で提案されているのが、X-Learner, R-Learnerを改善した手法です。
X-Learnerについては前回説明した通りで、R-LearnerについてはCATEの算出方法が以下の式になっています。

このそれぞれのMeta-Learnerモデルを複数介入モデルとして改良しています。
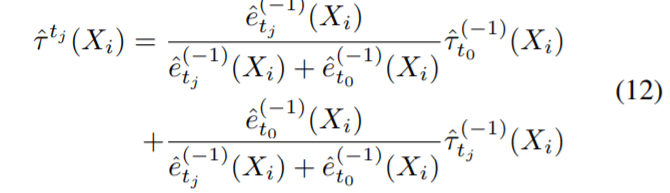
(詳細については論文をご参照ください。)
高パフォーマンスな提案モデル
X-Learner, R-Learnerを改善したモデルをAUUC(Area Under the Uplift
Curve)を指標として他の従来モデルと精度比較を実施しました。
その結果X-Learner, R-Learnerの改良モデルが最も効果が出ることがわかりました。
AUUCとは、ベースラインと比較して、介入がどの割合に対してどれほど効果があるのかを示したものです。AUUCの算出は"Lift"を用いて行います。"Lift"とは、今回の事例では、ある顧客にのみ介入した場合と全く介入をしなかった場合とを比較して、CV数がどれ程増えるかを表す値です。
横軸を介入効果が高い順(z-score-rankが高い順)に並べたときの順位とすると、upliftは下図で示すような曲線となり、この曲線と、全く介入をしなかった場合(ベースライン)の差分がCV上昇分になります。つまり、ベースラインと比較して該当するモデルの線が左上にあるほどCVを向上させる効果があることを示しています。
下図の結果を見ると、X-Learner, R-Learnerの改良モデルの線が他のモデルと比較して左上にあることがわかります。

さらに、UberはX-LearnerとR-Learnerに施策実施時のコストも考慮した、Net Value X-Leaner, Net Value R-learnerを開発しました。
これらのモデルも他の従来モデルと比較して、高パフォーマンスであることが分かります(下図)。

結果として、他のモデルと比べて約2倍のパフォーマンスを発揮しています。
因果推論を活用した離反防止策
Uberは離反防止のために、ユーザー一人ひとりの因果効果を把握し、HTE(個別の因果効果)を最適化する方法としてDirect Ranking Model(DRM)を提案しています。
このモデルでは、予測と最適化を1つにまとめ、線形 & 多層パーセプトロンを用いた構造を設定しています(具体的な式は論文をご参照ください)。
通常、介入効果の予測は非常にノイズが多く、さらに指標として"比率"を用いるとノイズが増幅するなど様々な問題がありますが、今回の手法では、そのようなノイズを低減しており、離反抑止のコストパフォーマンスの最大化を実現しました。
このDRMを評価するために、Causal Forest, R-Learnerと比較した検証を行っています。
比較の際にはAUCC(Area Under Cost Curve)を用いています(下図参照)。

・百万人以上のユーザーデータ
・約70個の特徴量
を用いて3つのモデルを比較した結果、DRMが最もコスパの良いモデルであることがわかりました。
DRMを使用した場合はランダムにターゲティングした場合より、4倍もリテンション効果がありました(一部のデータの結果ではありますが)。

また、3つの都市で実際に精度検証をしたところ、一部DRMのパフォーマンスが高くなかった所があったものの、トータルして考慮するとDRMが最もパフォーマンスが高い結果となりました。
今後の展望 -強化学習からのアプローチ-
今後の因果推論の展開として、強化学習を加えた高度なアプローチが増えていきそうです。DeepMind,UCL,ハーバード大学の共同研究の論文(Causal Reasoning from Meta-reinforcement Learning)中では、因果構造を含んだ様々な問題を解決するために、モデルフリーの強化学習を用いてメタモデル(RNN)を構築する方法が提案されています。ここでは、ある交絡因子を含む因果関係について、
①情報収集をして
②その関係性を答え、
③当たっていれば報酬がもらえる
というタスクを繰り返して学習をします。
この方法は因果推論の従来の方法を踏襲する必要はなく、ただ因果構造に依存するタスクを実行するようエージェントを最適化しています。具体的には、エージェントは観察や介入、反実仮想の予測をするなどして因果(推論)データを引き出し、因果推論に使える様々な種類のデータの生成やそのデータを活用する戦略を学んでいるのです。
この学習済みのエージェントは、報酬を得るために新しい状況でも因果推論を実行できることがわかっています。
今後も強化学習を用いた最適化のユースケースが広がりそうです。
■(参考)Uberの公開ライブラリ
CausalML
1.Tree-based algorithms
・Uplift tree/random forests on KL divergence, Euclidean Distance, and Chi-Square
・Uplift tree/random forests on Contextual Treatment Selection
2.Meta-learner algorithms
・S-learner
・T-learner
・X-learner
・R-learner
この記事が気に入ったらサポートをしてみませんか?