
機械学習(ニューラルネットワーク)を用いた株価予測

皆さん
こんにちわ。高橋勇気です。
本日は先週に引き続き、AIを用いた株価予測について記事を書きたいと思います。
前回はK-最近傍法でしたが、今回はニューラルネットワークを用いたMLPモデル(多層パーセプトロン)になります。
前回の記事:機械学習(K-最近傍法)を用いた株価予測
また以下の書籍を参考にプログラムを構築しております。
機械学習の初心者にとっても非常に分かりやすく書かれており、”まず動くものを作る”と言う意味では大変参考になりました。
MLPモデル(多層パーセプトロン)とは
さて、今回は非常に簡単なニューラルネットワークを使った分析になります。ディープラーニングを用いた分析には、CNN、RNN、QRNNモデルなど、多くのモデルがありますが、今回はMLPモデル(多層パーセプトロンモデル)という初歩的なニューラルネットワークを用いたモデルになります。
MLPモデル:Multi-Layer Perceptronモデル
まずは簡単な説明からです。
まずは下記の表をご覧ください。
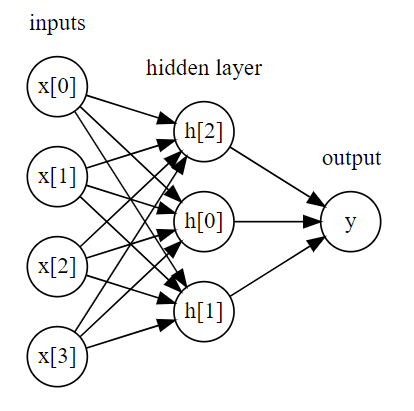
インプットデータ(x[0]からy[3])からまずは隠れ層(hidden layer)のユニットの値を計算し、その後、アウトプット(y)を求めることになる。
基本的には各インプットの重みを機械学習で学習した後、線形和でアウトプットを求めることになるが、インプットから隠れ層への変換は非線形関数を用いることになる。
具体的によく使用される非線形関数はreluとtanhがある。
relu→rectified linear unit:正規化線形関数
tanh→hyperbolic tangent:双曲正接関数
数式で表現すると以下のようになる。(非線形関数でtanh使用した場合)
h[0]=tanh(w[0]×x[0]+w[1]×x[1]+w[2]×x[2])
同様にh[1]とh[2]を計算。その後、出力されたh[0],h[1],h[2]と重みv[0],v[1],v[2]を用いて以下のように線形モデルで計算する。
y=v[0]×h[0]+v[1]×h[1]+v[2]×h[2]
さてreluとtanhのグラフを見てみよう。
このようになる。

tanhの場合は、どのような数字でも-1から+1の間の数字に変換されることになる。
一方でreluの場合は、負の値は全てゼロとなり、正の値はそのまま同じ値が出力される。
線形関数だけではなく、このような非線形関数も用いることでニューラルネットワークはより複雑な分析が可能となっているのである。
さていよいよ本題に入ろう。
日経平均株価の予測である。
使用したデータ
2020年10月から2021年9月までの日次データ(約200営業日)
予測対象:日経平均株価
予測に使用した変数は3パターン。
① 米国国債10年、ドル円
② 米国国債10年、ドル円、原油、SP500
③ 米国国債10年、ドル円、ユーロドル、SP500、DAX、ゴールド、原油、VIX
①から③のデータを用いて、翌日の日経平均株価が上昇するか、下落するかをMLPモデルを用いて分析していきます。
分析手法
約200営業日のデータを学習データと検証データに分割する必要があります。
機械学習では全データの75%で学習し、残りの25%で性能を検証するケースが多いため、本分析でも同じようにしております。つまり2020年10月から2021年6月までのデータを学習データとし、2021年7月から2021年9月までのデータを検証データとして性能を分析しました。
また、この分析では隠れ層の数を1個から100個までの変数としております。
つまり、まずは隠れ層1個の場合で学習データを用いて学習し、検証データを用いて予測精度を測ります。これを隠れ層1個から100個までの100パターン実施し、予測精度が最大となる隠れ層の数を探していきます。
尚、使用する説明変数は桁数等が異なっていることから平均ゼロ、分散1になるよう前処理を施しております。
分析ツール
Scikit-learnをJuputer Note Book上で分析を実施しました。
使用言語はもちろんPythonです。
分析結果①(2つの説明変数を使用した場合)
まずは米10年金利とドル円を用いて翌日の株価が上昇するか、下落するかと分析します。
非線形関数としてtanhとreluの2パターンで実施いたしました。


ご覧いただきたい線はオレンジの線になります。
2つとも予測精度は約55%となっており、なんとも言えません。またtanhを用いて行った分析では検証データの予測精度が学習データを予測精度を上回っております。通常では起こりえないことです。この結果をそのまま鵜呑みすることは避けた方が良いでしょう。
また隠れ層の数による予測精度の向上については、tanhは特に変化なし、reluは20個以上であれば変化なしとなりました。
reluの場合は隠れ層を1個から20個に増やす過程で少しだけ学習効果があるかもしれません。
分析結果②(4つの説明変数を使用した場合)
米10年金利とドル円に加えて、原油とSP500も追加しました。
コモディティの代表指数である原油と米株の代表指数であるSP500を追加しております。
非線形関数としてtanhとreluの2パターンで実施いたしました。


この結果からの気付きは2つあります。
まず、予測精度についてです。
reluを用いた予測精度は65%となっており、tanhよりも良い結果となりました。
冒頭に記載した通り、reluの場合、負の数字は全てゼロに変換されるため、どちらかと言うとtanhの方が高い予測精度になると予想していたのですが、意外な結果です。
また2つ目の気付きはreluの予測精度は隠れ層を20個まで増やす過程で予測精度の向上が見られております。まさに機械学習の賜物でしょう。
分析結果③(8つの説明変数を使用した場合)
さらにユーロドル、DAX(ドイツ株)、ゴールド、VIXも加えて8つの指数を説明変数として日経平均株価を予測していきます。学習させる変数を増やしていることから予測精度の向上に期待です。
非線形関数としてtanhとreluの2パターンで実施いたしました。


残念ながら説明変数を増やしても予測精度の向上は見られませんでした。これは追加した4つの変数(ユーロドル、DAX(ドイツ株)、ゴールド、VIX)が日経平均株価の予測には影響が少ないと言うことなのかもしれません。
個人的にはDAX(ドイツ株)やVIXは大きな影響を与えそうですが、既にSP500(米株)が入っていることから、追加的な予測精度向上とはならなかった可能性もあります。
分析結果③(特徴量分析)
次に8個の説明変数の中でどの変数が日経平均株価の予測において重要であるかを見ておきます。
ニューラルネットワークを用いた分析ではかなり分かりにくいのですが、以下をご覧ください。
簡易のため、隠れ層は10個にしております。

まず表の見方ですが、縦軸は説明変数、横軸は何個目の隠れ層であるかを示します。
また明るい色の方が重要であることを示します。
この場合、3個目の隠れ層のSP500とDAXが明るい黄色になっております。これらは米株とドイツ株であるため、日経平均株価に大きな影響を与えるとしても違和感ありません。
最後に
さて今回はニューラルネットワークを用いた株価分析を実施いたしました。
説明変数が高々8個程度であったことから隠れ層は20個で学習がストップしたことは興味深かったです。おそらくもっと大量のデータをインプットした場合は隠れ層のユニット数を増やしたり、さらにはそもそも層の数を増やすことえ予測精度の向上に繋がるかもしれません。
もしこの記事を読んで、少しでも面白かったと感じて頂けた方はスキを押していただけると嬉しいです。また何か質問やご意見などありましたらコメント欄にお願いいたします。
リクエストもお待ちしております
高橋勇気
この記事が気に入ったらサポートをしてみませんか?