
『プログラミング』コメント抽出・集計ツール。どのユーザーが多くコメントをくれたか。「Python、noteAPI」

以下記事で触れたツールの話。
誰でもすぐに実行できます。
プログラム記事ってコメントでの反応はあんまりなかったりするけど、マガジンのフォローは一番多いみたい。
興味ある人が多いのか少ないのかはわからないけど、まぁ記事は書いておきますか。
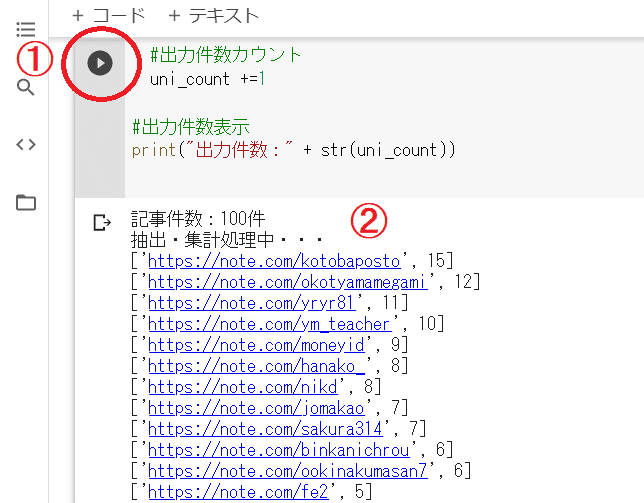
🌸実行イメージ
■実行すると以下結果が表示
・コメントをくれたユーザーURL
・そのユーザーのコメント合計数
・多い順(降順)
🌸実行環境準備
「Google Colaboratory」がある方はスルーしてください。準備がまだの人は以下記事の『実行環境』を準備。
🌸実行コード
以下のコードを全部コピーして「Google Colaboratory」に貼り付けてください。
# 使うやつインポート
import requests
import json
#id退避用配列初期化
id__array = []
######## 記事ID(数値)を全件取得 #######
#最終ページフラグ初期化
flg = "off"
#ループカウンタ初期化
j = 1
#記事数カウンター
total_count = 0
#最終ページフラグがonになるまでループ
while str(flg) == "off":
#API_URL
api_url = "https://note.com/api/v2/creators/あなたのアカウントID/contents?kind=note&page=" + str(j)
#API_URLを投げる
res = requests.get(api_url)
#jsonに変換
jsonData = res.json()
#data配列取り出し
data = jsonData["data"]
#contents配列取り出し
contents = data["contents"]
#idを取り出し
for i in contents:
id__array.append(i["id"])
total_count += 1
#最終ページ判断データ
bool = data["isLastPage"]
#カウントアップ
j += 1
#最終ページならフラグをon
if bool == True:
#最終ページフラグon
flg = "on"
print("記事件数:" + str(total_count) + "件")
print("抽出・集計処理中・・・")
######## 記事ID(数値)からコメントユーザー抽出 #######
#件数カウンター初期化
count = 0
#urlname配列初期化
urlname_array =[]
#重複削除用urlname配列初期化
urlname_dup_array =[]
#全件分のIDを実行するまでループ
for k in id__array:
#API_URL
api_url = "https://note.com/api/v1/note/" + str(k) + "/comments"
#API_URLを投げる
res = requests.get(api_url)
#jsonに変換
jsonData = res.json()
#data配列取り出し
data = jsonData["data"]
#集計しない記事を除外、コメントが50件以上のもの
if not data["rest_comment_count"] == 0:
continue
#comments配列取り出し
comments = data["comments"]
#コメントユーザ配列初期化
user_array =[]
#userを取り出し
for i in comments:
user_array.append(i["user"])
#urlnameを取り出し
for i in user_array:
#自分のIDは除外
if not i["urlname"] == "あなたのアカウントID":
urlname_array.append(i["urlname"])
count +=1
#重複を削除
urlname_dup_array =list(set(urlname_array))
######## 集計 #######
#集計結果用 配列初期化
sum_array=[]
#重複のないurlnameの数だけループ
for i in urlname_dup_array:
#件数カウンター初期化
comment_count = 0
#集計
for j in urlname_array:
#全件urlnameと一致したらカウント
if i == j :
comment_count +=1
#ユーザーページ と 件数 を配列に追加
sum_array.append(["https://note.com/" + str(i),comment_count])
#配列内をソート コメント回数 降順
sum_array = sorted(sum_array, reverse=True, key=lambda x: x[1])
#件数カウンター初期化
uni_count = 0
#結果を表示
for i in sum_array:
print(i)
#出力件数カウント
uni_count +=1
#出力件数表示
print("出力件数:" + str(uni_count))■以下を変更
・あなたのアカウントID2箇所
23行目、102行目。
ご自身のアカウントIDを設定してください
▼注意
コメント件数が50件以上ある記事は、取得方法がまだわからないため対象外にしております。 if not data["rest_comment_count"] == 0: の部分。
これで実行できると思います✨
🌸詳細
反応見て必要そうなら書きます。
勉強用で見ている方へ、今回のコードは「ロジック」を知るものだと思ってください。ふつう似たような処理はひとつにまとめて見やすくします。正直、紹介したコードは美しくないです。
もっとすっきりした書き方できると思う。抽出の部分とか初期化の部分。
この記事が気に入ったらサポートをしてみませんか?