
【コラボ企画】PDFの読み取り・加工・判定ツール!(1)『Python・プログラミング』

記事を一緒に書きながら「とあるフォロワーさん」が希望するツールを作っていくことにしました! こちらの方です!
「せっかくなので、コラボ企画という形で記事にしながら楽しく進めていければと思っています」とご提案いただいたことが始まりです!
このご提案をいただいた時、「楽しそう!」と最初に思いました。「ツール作り」というただの単純作業が創作に変わるような気がしました。
こちらの記事では、実際に要望を受けてからどのような手順で考えて、どういった失敗を繰り返して作っていくかを記載していきます!
![]()
※最後にまとめとして
コード公開と
手順を記載いたします
![]()
🌸要望内容
最初の会話で以下の要望をいただきました。
PDFに記載されている内容が、ルールに則っているか合否判定するツールを作りたい。Pythonの勉強をしているので、できればPythonで作りたいです。
はなこ☆さんの記事で具体的な条件が記載されておりますが、まずはひとつずつ考えていきます。
![]()
ーーー作業開始ーーー
基本的にプログラムは覚えてませんし、覚えるつもりもありません。重要なのはわからないときにどうするかだと個人的には思います。「不明点の言語化」や「目的の情報にたどり着く検索力」などが重要な気がします。
プログラミングだけではなく、通常のお仕事においても、自分で問題発見から解決までを行えるのは重要だと思います。
この記事では、私の思考手順をそのまま記載していきます。
![]()
🌸実行環境
環境準備が簡単な「Google Colaboratory」を使います。使いたい人は以下記事の『実行環境』を参照。
![]()
🌸PDFの内容を取得
まずは「PDFの内容を判断したい」ということなので、とりあえず内容の読み取りについて考える。
『google colaboratory PDF 読み取り』で検索
なぜこのような検索をしたかというと、Pythonを使っていても別環境だと準備等が違ってくるから「Python PDF 読み取り」ではなく「google colaboratory PDF 読み取り」としました。
![]()
▼こちらのサイトを見た
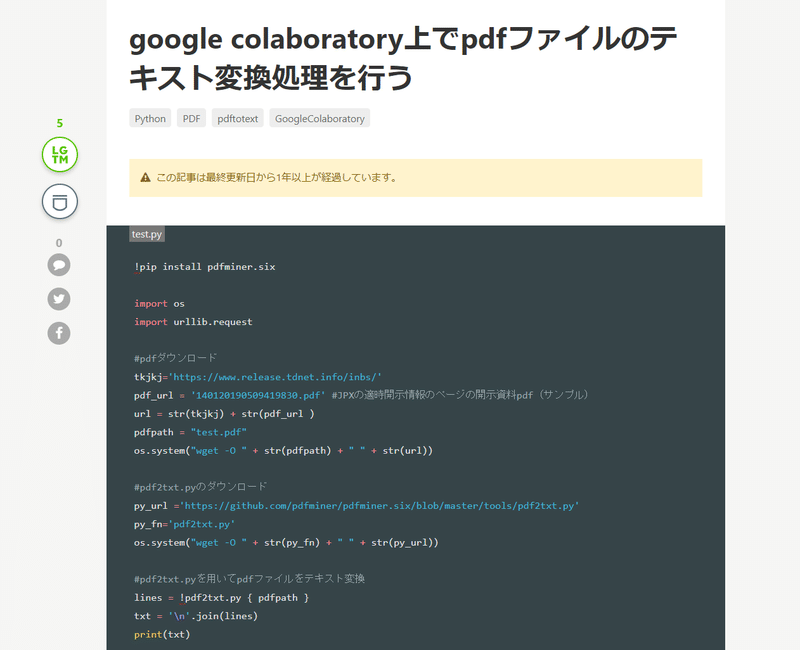
それっぽいけど、もっと簡単なのありそうだから探す。
![]()
▼こちらのサイトを見た

おっと、PDFに変換する方法か……この情報は違う。
![]()
▼こちらのサイトを見た

好みだとは思いますが、私はパッと見て見にくいと感じたページはすぐ閉じます。
![]()
▼こちらのサイトを見た

おっ! それっぽい気がする。
PyPDF2というのを使えばいけるのかな?
pip install PyPDF2import PyPDF2
with open("sample.pdf", "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0)
print(page.extractText())open("sample.pdf", "rb") ・・・まずファイルを参照できる状態にしないといけないですね。
![]()
🌸読み込み準備
簡単なテキストファイルから試してみよう。
「google colaboratory テキストファイル読み込み」で検索
![]()
▼こちらのサイトを見た

いきなりそれっぽい記事!
一発で当たりを引くとやる気UP!
▼見ていこうか……


めちゃ良記事✨✨✨
通常時とColabのときが両方書かれているし、パッと見でわかりやすくなっている。そして、不要な情報がない最小限の目的に沿った内容!! ありがとう記事執筆者さん!
![]()
🌸マウント
どうやら「マウント」という作業が必要になるみたい。
「google colaboratory マウント」検索
「google colaboratory」で以下作業を行えばいいようだ。

フォルダの読み込み許可のようなものだと思う。
![]()
🌸ファイルをアップ
試しにテキストファイルを格納した

![]()
🌸読み取り実行
通常Pythonを使うときと同様の読み取りコードで、参照先を「先程格納したマイドライブのテキスト」に設定したものです。

これで、Colabから読み取りが確認できました!
![]()
🌸PDFの内容を取得2
先程のコードを試してみよう。取得テスト用に「Ammonia_Gas_J-1.pdf」をマイドライブに入れておく。
pip install PyPDF2上記でPyPDF2をインストール
import PyPDF2
with open("sample.pdf", "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0)
print(page.extractText())このコードは、たぶんsample.pdfが参照の場所なのかな? 書き換えてみる
import PyPDF2
with open("/content/drive/My Drive/Ammonia_Gas_J-1.pdf", "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0)
print(page.extractText())こうかな? 実行しよ。

はいエラー……まぁ感覚でやってるからよくあること……簡単なところでつまづくと胃がきりきりしてくる……
![]()
私は感覚でやって、エラーが出たら初めて理解しようとします。いい方法かどうかわからないけど、それが私には理解が早いと感じる。
もちろん、ひとつの操作が重大な問題を起こすような仕事や、実務ではテキトーなことはしませんよ(笑)。あくまでもエラーを出しても問題がない場合のお話。さて、エラーは
file has not been decrypted
らしい。ここから長い。
記載できないので流れだけ。
エラー調べる
→ 暗号化PDFの話
→ 関係ないと判断
→ pdfminer.six試す
→ エラー
→ エラー調べる
→ わからん
→ 別の方法探す
というのをやっていきます。
そして方法がようやくわかりました。
読み取りはわかりましたが、
その先でもつまづきます……
![]()
ここからは有料になります!
「条件と結果」だけを知りたい方は、
ぜひ「はなこ☆さん」の記事をご購入ください!
![]()
私の記事は「結果に至るまでの思考」です。いつもは依頼されてさらっと結果を渡すし、PCにも詳しいと思われているから「すぐできるんでしょ?」という印象を持たれます。
でも、実際は地道でちょいストレスな作業なんですよ(笑)。
「大変なんだな!」「頑張ってるな!」「思考をもう少しみたい」「応援したい!」そういった方はぜひ私の記事をご購入お願いいたします!
![]()
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?