Retail AIのスマートショッピングカートを使ったリアル店舗でのレコメンデーション

Retail AI の塩田です。
今回は前回のエントリに書いたスマートショッピングカートから得られるデータの利活用方法の一つである、スマートショッピングカートを使った商品レコメンデーションについて書いていこうと思います。
この記事では、レコメンドで使用しているアルゴリズムに触れつつ、レコメンデーションに関する概要、効果について書いています。
リアル店舗での レコメンデーション

「レコメンデーション」
この note を読んでいる人(ITの分野に近い方。もっというと、エンジニアを想定しています)であれば、みなさん一度は聞いたことがあると思います。
レコメンデーションとは Wikipedia には以下のように書かれています。
レコメンダシステム(英: recommender system)は、情報フィルタリング (IF) 技法の一種で、特定ユーザーが興味を持つと思われる情報(映画、音楽、本、ニュース、画像、ウェブページなど)、すなわち「おすすめ」を提示するものである。
レコメンデーションはECや広告事業など、多くの分野で顧客満足度や売上の増加のために使用されています。
代表的な例では
- ある商品と一緒に買われやすい商品を一緒に提示する
- ユーザーが閲覧したページ, 検索したクエリと関連のある広告を提示する
などが挙げられます。

みなさんもインターネットで物を買う時など、知らず知らずのうちにレコメンデーション機能を使ってその便利さに慣れ親しんでいると思います。
大手ECサイトなどで お客様が閲覧した商品に関連する商品 や この商品を購入した人はこちらの商品も購入しています などのオススメに見入ってしまうことはしばしばありますよね。
動画配信サービスなどでも、自分が今まで知らなかった映画やドラマを見つけ、思わずテンションが上がる気分を味わったことがある人は少なくないと思います。
しかし、膨大な商品がある中で、自分に合った欲しいと思える商品を見つけることは骨の折れる作業です。
これは私の経験談ですが、店舗に行って DVD を借りていた頃の話です。
もちろん実店舗に借りに行ってますので、「この作品をみた人にはコチラの作品もオススメ」などというレコメンデーションはありません。
今日はどんな映画を見ようかと膨大な数の DVD が陳列されている棚を一つ一つ見て歩き、見たいと思った映画があれば DVDが入っている半透明のケースを外箱から引き抜いて周ります。
しかし、陳列されている DVD の数が多すぎて延々と見てしまい、気づいたら数時間店内にいた…なんてことが結構ありました。
選択肢が多すぎて選べない、、という人の手助けをしてあげようと言うのが レコメンデーション の役割と言えます。

インターネットを通じてサービスを受け取ることが普通になった近年では、多くのサービスでレコメンデーションの機能が導入されています。
では、ネットを通さないで受けるサービスでのレコメンデーションはなんでしょうか。
弊社に関連のあるところですと 実店舗でのお買い物 ですね。
スーパーマーケットの実店舗で扱う商品数は、かの有名大手ECサイトに掲載されている商品数ほど多くはないですが絶対数で見るとかなり多いです。
だいたい都心にあるようなスーパーで 10,000 SKU くらい、地方の大型スーパーで 100,000 SKU くらいあります。
単品管理
SKUは最小管理単位 (Stock Keeping Unit) の略。
例えば、「ある店舗で扱っているシャツはデザイン・色はすべて共通だが、サイズがS、M、L、XLの4種類ある」、もしくは「サイズはMのみだが、色は赤、青、白、緑の4種類ある」場合にはどちらの場合も「1アイテム4SKUある」と数える。

そして特に地方に行くほど、店舗面積は広くなる傾向があります。
お買い物を完了させるには、 広大な店舗から目的の商品を自分の足で探さないといけません。
PC の前に座っているだけでお買い物が完結するネット通販とは条件が違い過ぎますよね。
これらのことを踏まえ、リアル店舗で商品のレコメンデーションが出来ればお客様の買い物体験を大幅に向上させることができます。
スーパーのお買い物の途中にレコメンドを見ることによって
- その日買おうと思っていたけど、うっかり忘れてしまっていたものを思い出した!
- いつも醤油はこのメーカーのものを買ってたけど、こっちも美味しそう…🤔
- 今まで知らなかったけど、こんな商品も取り扱っているのか!ちょっと試しに買ってみよう!
などなど、数多くの場面で役に立ちます。
スマートショッピングカートの レコメンデーション UI
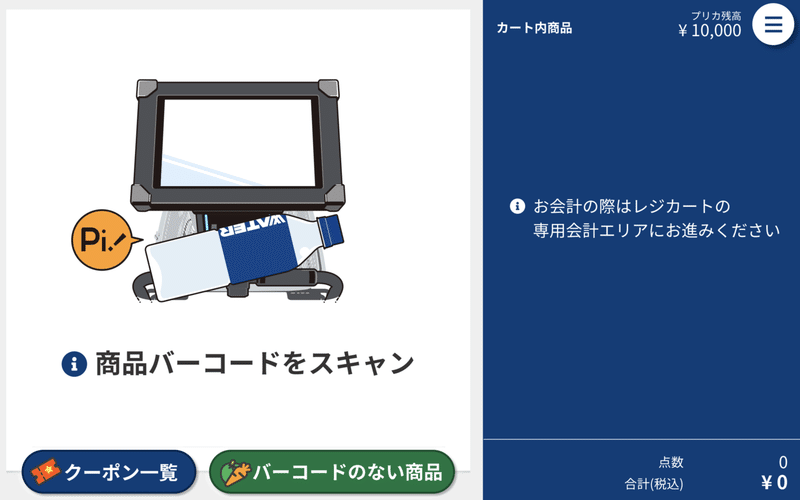
スマートショッピングカートにログインすると、商品バーコードをスキャンする画面に遷移します。
商品をスキャンすると右側にスキャンされた商品と合計金額などの情報が並び、左側にその商品に関連した商品一覧が出てきます。

これがスマートショッピングカートで行っている商品のレコメンデーションです。
お客様が カートの中に入れた商品 (スキャンした商品)に対して、オススメの商品を リアルタイムで提示 しています。
レコメンデーション に使用するデータ
データは以下のものを使います
ID-POS: user_Id, JAN, 数量, 日付, 金額
ユーザー情報: user_Id, 年代, 性別
商品情報: JAN, 商品カテゴリ大, 商品カテゴリ中, 商品カテゴリ小, ...
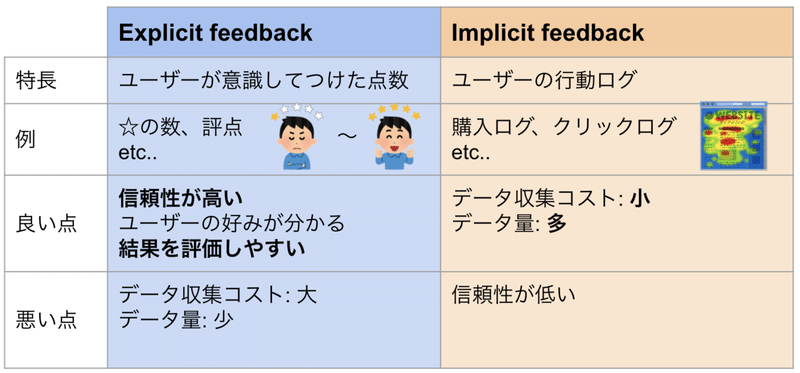
基本的にスマートショッピングカートから得られるデータは、ユーザーからの暗黙的なフィードバック(Implicit feedback)です。
(ECみたいに商品の口コミがあったら最高ですが、 現在のスーパーマーケットには商品のレビューをユーザーからもらえるシステムはない ので現時点では不可能)
Implicit feedback という言葉が出ましたが、レコメンドエンジンを学習させる時に使用するデータは大きく分けると Explicit feedback(明示的なフィードバック) と Implicit feedback の2種類に分かれます。
簡単に説明すると以下の通りです。
ID-POS データについて
ここで、ID-POS データ(ユーザーの購入履歴)を見ていきましょう。
ID-POS は以下のようなデータから構成されています。
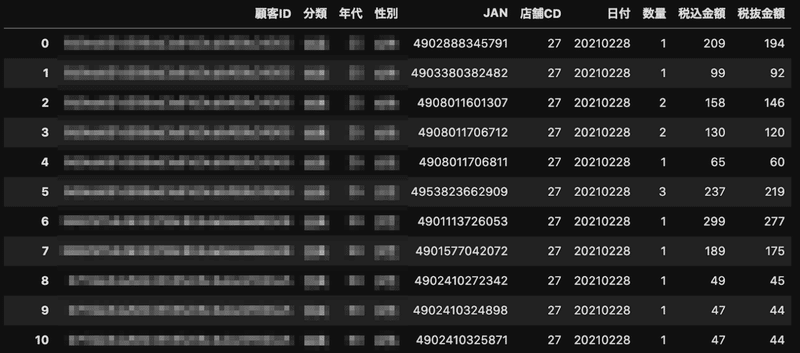
ここからお客様が一連のお買い物において、どのような商品を購入したかという情報がわかります。
この情報をもとにしてレコメンドシステムを作っていきます。
Recommend algorithms
今回は Personalized Recommender として、以下の2つについて書いていきます。
- Matrix Factorization
- Factorization Machines
ある程度まとまった量のデータがある時、ACM RecSys や AAAI で発表されているような、複雑でネットワーク図がキラキラ輝いているアルゴリズムを試したくなります。
しかし、その気持ちをグッと抑え、まずは古典的な手法で試すべきだと考えます。
なぜなら、リアル店舗でのレコメンデーションがお客様へどのような影響を及ぼし、また、お客様からどのような反応が得られるのかを確認し、データを取ることの方がまずは重要だからです。
■ Matrix Factorization
まず一つ目は Matrix Factorization と呼ばれる手法です。
これは、協調フィルタリングにおける行列演算に次元削減を行うことで、計算コストを下げつつより良い推薦を出しましょうといった手法です。
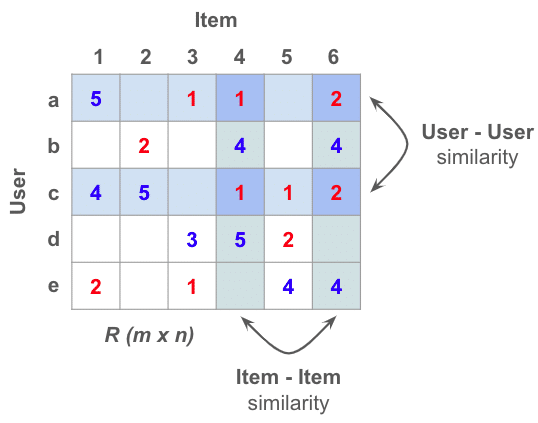
▶︎ 協調フィルタリング (Collaborative Filtering)
Amazon など EC サイトでよく見る “この商品を買った人はこちらの商品も買ってます” の手法
レコメンドアルゴリズムの基本で王道の手法として有名です。
シンプルで複雑なパラメーターチューニング等の必要がなく精度も申し分ないため、“ベースライン” としてよく使われます。
レコメンドの流れとしては User x Item 行列を作り、各ペアに対して類似度を計算して入力に対する予測値を計算するといった流れです。
▶︎ Matrix Factorization (行列分解)
上記の協調フィルタリングの説明では完璧かのように聞こえますが、もちろん不都合なところもあります。
現実のデータに当て嵌めるとユーザー数は数十万、アイテム数は数万のオーダーになることはザラにありますよね。機械学習では次元が増えれば増えるほど、次元の呪い (Wikipedia) と呼ばれる現象が付き纏ってきます。
一言でいうと、予測器がまともに使える精度を出すために必要な Training data の量が爆発的に増える といったところでしょうか。これを防ぐために、頑張って次元を減らそうという訳です。

次元を減らすといっても、常連客 top 100 人の情報だけ使おう 🥳 という短絡的な考えではなく、
「高次元である元のデータの情報量を可能な限り保ちながら、データを低次元に変換したい」
これがベストですよね。
これを踏まえて、Matrix Factorization ではどうなんでしょうか、というと
m 人のユーザと n 個のアイテムを考えた時、協調フィルタリングだとユーザは n 次元のベクトルで表現されることになります。これを評価値を表す `m × n` の行列 R に対し、ユーザ要素を表す `m × k` の行列 U とアイテム要素を表す `k × n` の行列 IT を考え近似しましょう。
つまりこの時、`m > k > 0` である k 次元に次元削減できました。
という方法です。
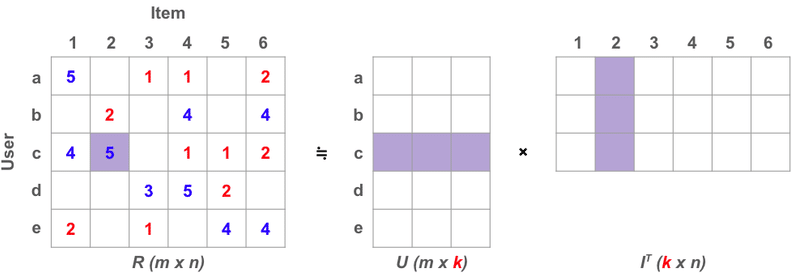
図を見ると Matrix (行列) Factorization (因数分解)。
名前そのまんまの方法ですね!
学習に使用する ID-POS データは数百万行とかなり大きいデータとなっているので、今回はパラメータの学習方法には Alternating Least Square (ALS) を使っています。
■ Factorization Machines
レコメンドアルゴリズム、その 2 が Factorization Machines。
( `Matrix Factorization` と `Factorization Machines` 、名前は似ていますが全くの別物です。)
Matrix Factorization ではユーザーの購入履歴しか考慮出来ていません。
スマートショッピングカートから得られる情報は購入履歴以外にたくさんありますが活用しきれていないので、コンテキスト情報を扱えるアルゴリズムはないか?といった流れが Factorization Machines を使うに至ったモチベーションです。
どのようにコンテキスト情報を扱うかというと、以下の図で Matrix Factorization と Factorization Machines を比較した際のデータの持ち方について説明します。
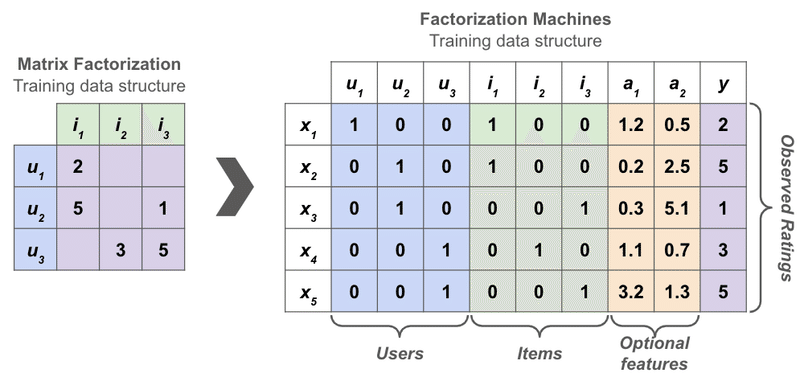
Matrix Factorization は (ユーザー x アイテム) 行列として考えていましたが、Factorization Machines は 1 行 1 アイテムを表すベクトルとして情報を持っています。
ユーザーとアイテムに関しては one-hot で、追加するコンテキスト情報には
- 商品のカテゴリ
- ユーザーの属性情報
- 購入された時間
等の好きなものを追加することができます。
また、Factorization Machines を使うメリットの一つにカテゴリカルデータを扱える点があります。カテゴリカルデータは多くの場合スパースなデータになりがちなので、スパースデータのパラメータ推定できることは非常に助かります。
今回は user と item の特徴量として以下を使用しました。
- user features: 年齢、性別、平均商品単価、等
- item features: 価格、アイテムのカテゴリ情報、等
■ Learning to Rank (LTR) algorithms
機械学習では、予測器が出す予測と Training data の正解ラベルとの誤差を最小化して学習していきます。(これが損失関数と呼ばれるものですね)
一方、予測誤差を最小化する代わりにランク順を直接学習する最適化手法は Learning-to-Rank(LTR)と呼ばれます。LTR はそれぞれ個々の観測値ではなく、トレーニングサンプルに存在するデータのペアまたはリストでトレーニングをしています。
つまり、観測されたスコアではなく、アイテムの相対的な順序に基づいて学習をしています。(あくまで相対的なので値自体には意味はない)
今回、Factorization Machines に LTR アルゴリズムを適用して implicit feedback によるランキング学習をする手法を取りました。
使用した LTR アルゴリズムはこの2つです。
- Bayesian Personalized Ranking (BPR)
- Weighted Approximate-Rank Pairwise (WARP)
▶︎ Bayesian Personalized Ranking (BPR)
Implicit feedback に適用するための代表的な手法
商品が購入される といった正例のみが観測され、負例が観測されない Implicit feedback の取り扱いで難しい所は「購入しなかった」(つまり Training データの中にレコードがない) という情報の取り扱いです。
「購入しなかった」という情報には
- 「興味がない(negative)から購入しなかった」
- 「興味はある(positive)が、数ある棚の中から見つけられなかったため購入まで至らなかった」
の2つが混在している点です。商品数の多い店舗ではスーパーは広いので、2つ目の理由は大いにあり得るかと思います。
BPRでは
「user が購入した item は、購入しなかった item に比べて興味がある」…①
という仮定のもと学習を行います。
図で説明すると、商品は全部で 5 個 [item_1, item_2, item_3, item_4, item_5] あるとします。
そこで、 user_1が item_1, item_2 を購入し、item_3, item_4, item_5 を購入しませんでした。
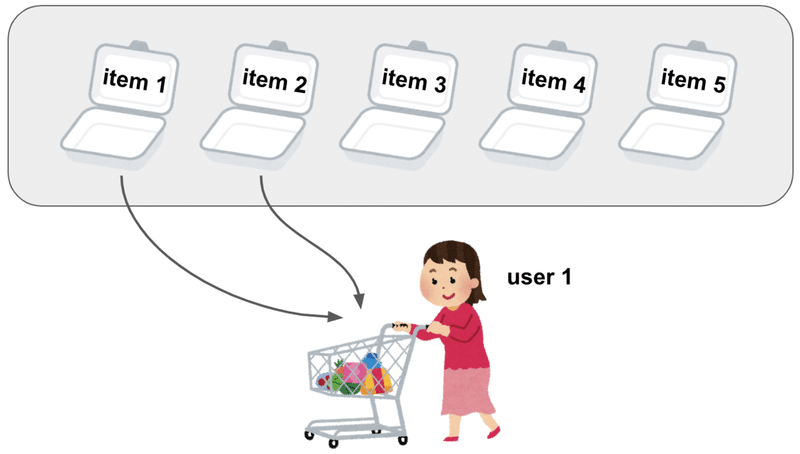
この場合、user 1 の興味は以下のような順序になっていると言えます。

あくまで ① の仮説に則っているので、 購入したもの同士、購入しなかったもの同士の興味関心の度合いは分かりません。
(つまり、item 1 と item 2 のどちらがより興味あるか。 item 3 と item 4 どちらがより興味ないか)
▷ 学習プロセス
1. (ユーザー(u), 買われた商品(i), 買われなかった商品(j)) のタプルで構成されるトレーニングサンプルを作成
2. SGD(確率的勾配降下法)を用いて学習
▷ 数式について
以下の対数尤度関数を最大化するように学習を行う
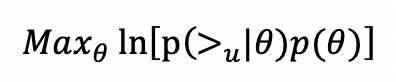
- (>u | θ) は、ユーザー (u) に対するモデルの予測アイテムランキング
→ さっきの例で言うと、>1 = { i1 > i3, i1 > i4, i1 > i5, i2 > i3, i2 > i4, i2 > i5 }
- >u を生成するモデルのパラメータは θ
これは ユーザーが購入したアイテム (i) が購入していないアイテム (j) よりも優先される同時確率 を最大化しています
この確率は、シグモイド関数を使用して、[0, 1] にマッピングされた ユーザーの観測されたアイテム (i) と 観測されていないアイテム (j) の予測スコアの差として定義されます
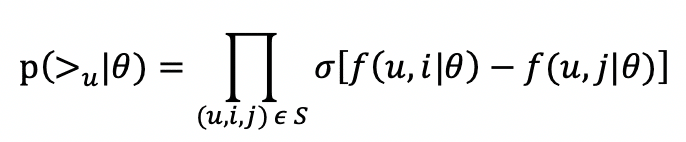
▶︎ Weighted Approximate-Rank Pairwise (WARP)
ランク学習をするための損失関数です。
WARPは誤ってラベル付けされているペアが見つかるまで、モデルの出力ラベルをランダムにサンプリングし、これら2つの誤ってラベル付けされた例にのみ更新を適用します。
具体例で Loss を導出するまでの解説をしていきます。
ビールからテキーラまでの 5 種類のアルコールをユーザーにオススメする場合を考えます。
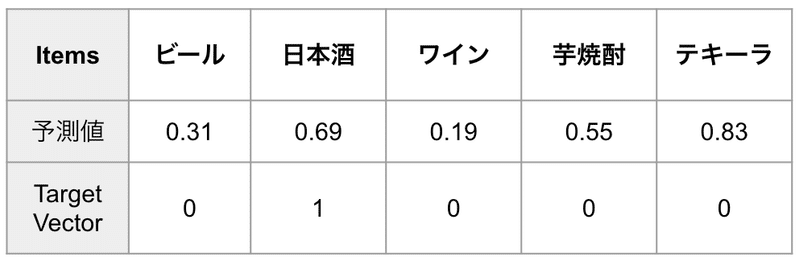
それぞれに対してモデルが予測値を出力して予測ベクトルがあります。
Training data には正解ラベルも含まれているので、 `Target Vector` として表に付け加えました。
`1` は購入された、 `0` は未購入の item になります。
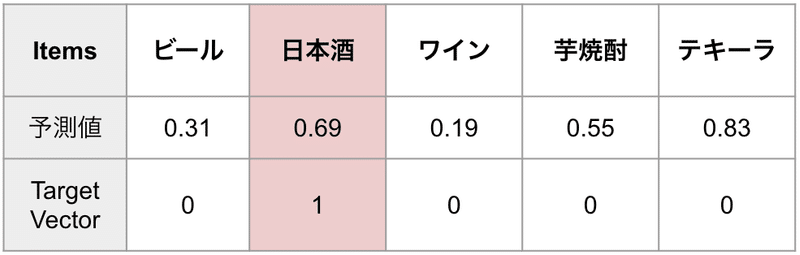
ここで、赤くメッシュが掛かっている 日本酒 は `1` となっているので、実際に購入された商品です。
日本酒 を基準に考えた時、他の商品をサンプリングしていきます。
ビール をサンプリングしてみます。( 青くメッシュをかけました )
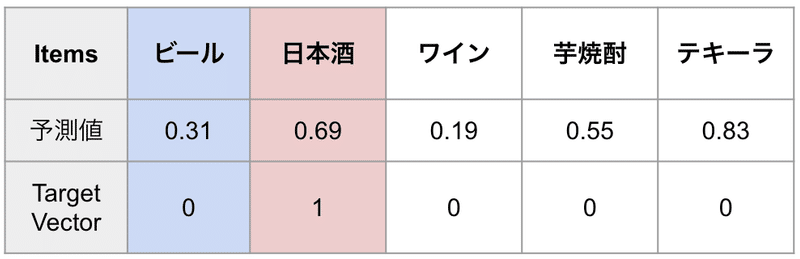
この場合、 モデルは 日本酒 の方が購入確率が高いと予測 しており、かつ実際に購入されているのでその予測は正しいですね。
この場合は、さらに別の Item をサンプリングします。これはモデルが間違った予測値を見つけるまでサンプリングし続けます(もし間違ったラベルがない場合は更新終了)
次のケースはテキーラをサンプリングしました。
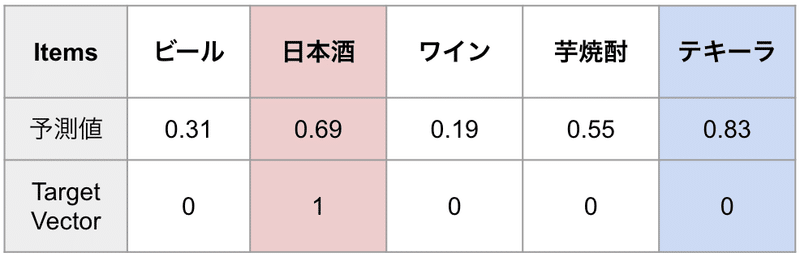
日本酒: 0.69 < テキーラ: 0.83 となっています。
この場合、 モデルは日本酒よりもテキーラの方が購入可能性が高いと予測 しているので、その予測は間違っています。
ここで _loss = 0.83 - 0.69 こうなりますね。
ただ、単純に予測誤差だけ使って更新するだけでは現状モデルがどの程度うまく学習出来ているのかが分かりません。 WARP では 正例の予測値を超える負例がランダムサンプリングで出現するまでの回数 も考慮に入れています。
したがって更新式に使われる Loss は以下のように定義されます。
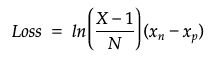
- X: ラベル総数 ( 上の例だと 5 種類のアルコールなので 5 )
- N: サンプリング回数 ( 上の例だと 2 回 なので 2)
- xn: 負例の予測値
- xp: 正例の予測値
WARPを使用すると、BPRに比べてエポックごとのトレーニング時間が長くなりますが、一般的に多くの場合に収束が速くなり、モデルのパフォーマンスが向上すると言われています
注* WARP で negative sample 回数が 1 の時、BPR の処理と一致しますね。
(つまり、WARP の特殊なケースが BPR と見なすことができます)
レコメンデーションの出力結果
今まで紹介したアルゴリズムを使ってスマートショッピングカートでレコメンド機能を実装しました。
適当にサンプリングした3種類の商品で Factorization Machines (BRP) を用いたレコメンドの結果はこのようになりました。
個人的にはどれもそれっぽい出力になっているのかなと思います。
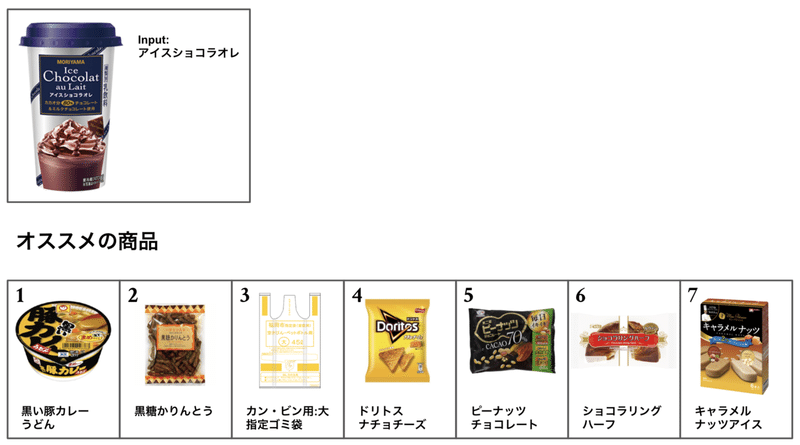
■ その 1
コーヒー系の飲み物 を入力として入れました
これを見るとカップ麺やお菓子、アイスなど、似ているジャンルが出てきました。
■ その 2
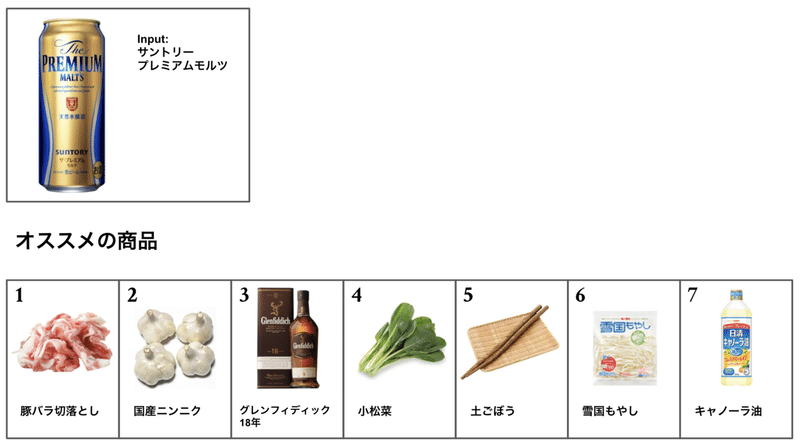
缶ビール を入力にしてみました。
ビールのいい感じのお供になりそうな食材達が出てきましたね。
■ その 3
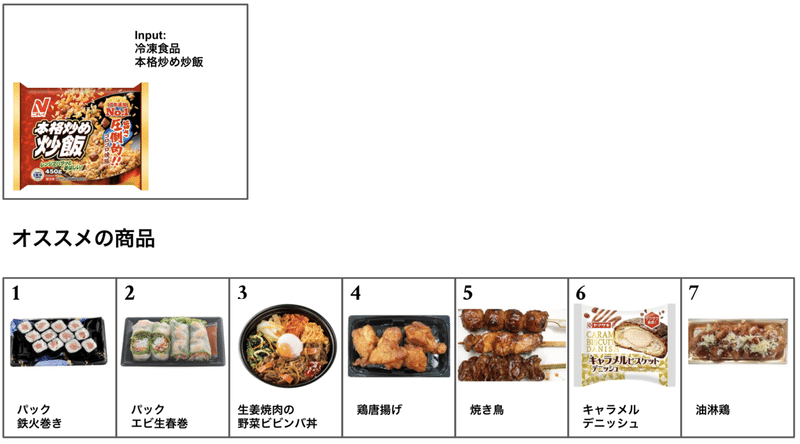
冷凍食品の炒飯 を入力にしてみました
基本的に似ているお惣菜がオススメされました。
和食・中華系のお惣菜が並んでるのが目立ちますね。
今後の課題
今後、本番環境でこれら3つ (Matrix Factorization, Factorization Machines (BPR), Factorization Machines (WARP)) のレコメンドアルゴリズムを導入して、それぞれのパフォーマンスを比較したいと考えています。
結果が出たらまた note を更新しようと思いますので、その時はまた見ていただけたらと思います。
かなり長めの note になってしまいましたが、最後まで読んで頂きありがとうございました。
======================================================
Retail AI では ID-POS データに加え、お客様の属性情報などを始めとしたリアル店舗での購買行動に関わるデータを分析し、分析から得られた価値をお客様に還元しています。
今回はスマートショッピングカートで行っているレコメンデーションについての紹介を書かせていただきました。
引き続き、データ分析周りについて発信していきますので、興味を持っていただけましたらスキやフォローお願いします 👏👏