
【ざっくリサーチしき #33】 サンプリングに対するざっくり知識 4

リサーチの最重要ポイント「サンプリング」に関するざっくり知識 4
ビギナーの方々に、ざっくりとした知識をお届けするシリーズ の第33弾。
今回は、第32弾の続きです。
前回は、「母集団を正確に圧縮する」として、母集団と調査対象者を同質な集団として扱う時の条件や考え方について、ざっくり解説をおこないました。
今回は、きちんと拘って設計・設定しても必ず発生する「サンプリング誤差」について、解説していきます。
サンプリング誤差とは?
前回のおさらいですが、サンプリングで重要なことは、「母集団を正確に圧縮する」ということです。
しかしながら、いくら正確に圧縮しても、当然、母集団全員に対して調査・リサーチをしているわけではないので、サンプリングしてきた調査対象者さんから得られたデータと、母集団の本当のデータの間には、どうしても差が出てきてしまいます。
しかし、大丈夫です。
誤差の算出には、すでに計算式が確立されていますし、誤差の早見表というものもあります。
今回は、誤差の早見表の見方もお伝えします。
サンプリング誤差早見表
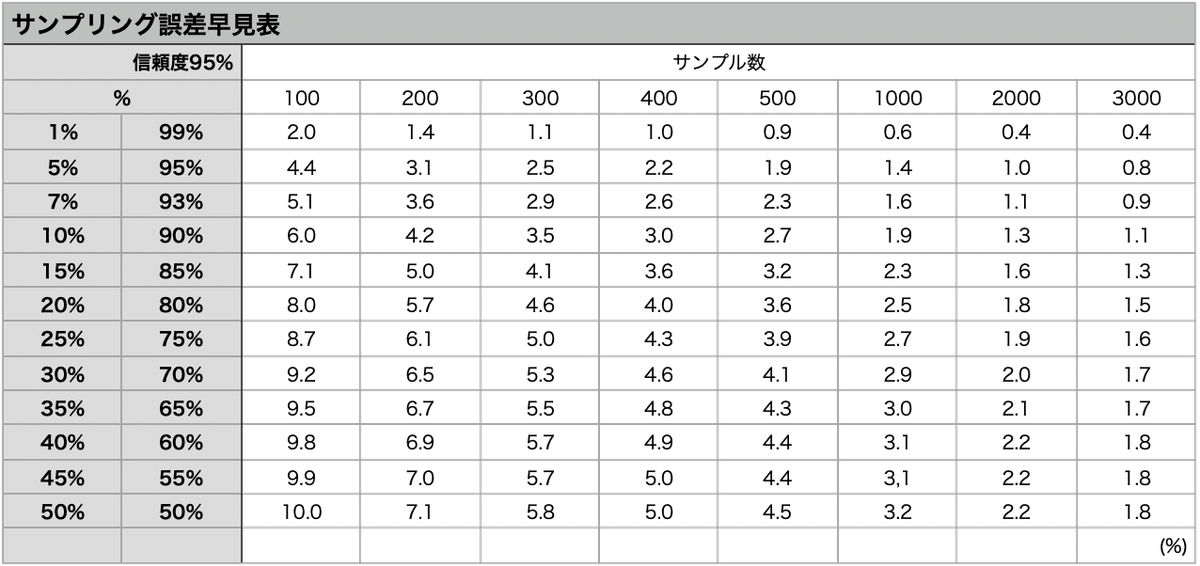
こちらが、その「サンプリング誤差」を早見するための表になります。
見方は、簡単です。
調査対象者の数(サンプル数)を表から探す
アンケートで得られた評価を表側から探す
そのクロスするところの数字をチェックする
その数字の±の幅が、信頼度にある%の確からしさで誤差となる
これだけですが、なんかややこしいですよね。
例を出して、見てみましょう。
調査会社さんのパネルから、「小学生以下の子持ちの女性」の条件に合った対象者をランダムに300名サンプリングしてきて、自社のこども向け玩具の認知率を取ってみると、20%という結果だったとします。
早見表で、「サンプル数 300」と「表側 20%」のクロスする部分を探してみると、「4.6」となっています。
この場合、アンケートでの認知率は、20%だったが、実際の母集団の認知率は、±4.6%の誤差を伴い、15.4%〜24.6%の間に本当の認知率があると、95%の確からしさで言えるということになります。
なので、「少なく見積もると7人に1人、大きく見積もると4〜5名に1人」は、自社の玩具を知ってくれている、ということになります。
このように、母集団を正確に圧縮しても、当然、全員に調査・リサーチができているわけではないので、どうしても誤差というものが出てしまいます。
この誤差について知っているかどうかで、リサーチの数字を見るときの見方が異なりますし、「嘘は言っていないけれど、正確ではない」報告などへの予防接種もできていることになります。
以前も書きましたが、残念ながら、不誠実な報告や対応をする人もいますので、報告を受ける側がリテラシーを身につけておくことも大事です。
4回にわたって、サンプリングについて解説をしてきました。
より詳細を知りたい方や、実際にリサーチを検討されている方で相談されたい方は、ぜひ、お気軽にお声かけください。
ご相談は、もちろん無料です!
本記事も読んでいただき、ありがとうございました。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?