
天才を殺すシステム~小説の新人賞システムを例に~

社会には”評価”を行うためのシステムが多数存在する。
例として就職面接、デザインのコンペ、小説の新人賞などがある。我々が親しんでいるものばかりだ。
私はこれらの審査システムが、「天才殺しのメカニズム」を内包しているのではないかと考えている。
その説明を、これからしていくつもりだ。
<小説の新人賞システム>
分かりやすい例として、今回は小説の新人賞を取り上げよう。
まずは軽く、新人賞について説明する。
小説の新人賞とは基本的に、一次審査→二次審査→三次審査→……のように、選考が段階を踏んで行われる。
各評価者(審査員)はランダムに配られた応募作品を読んでいき、その中から良いと感じたものだけを上の審査へと上げていく。
選考が進むにつれ作品の数は減る一方、一作に割り当てる評価者の人数は徐々に増えていく。そうやって徐々に作品を絞り込み、受賞を決めるというシステムである。
そして私はこの種の評価システムに、「天才殺し」の罠が潜んでいると主張するわけである。

それでは早速本題へと移る。応募者計400人の、仮の新人賞を考えてみよう。
この応募者の中には、まだまだ実力不足の人・既にプロ級の実力を持つ者など、様々な人がいるだろう。
話を分かりやすくするため、この400人を100人から成る4つのグループ(優等生、ダメダメ、天才、ワンチャンス)へと分類する。

①「優等生」は誰が見ても良い評価を得られる作品。どんな審査員に当たっても必ず80点の評価を得られる。
②「ダメダメ」はその名の通り誰が見ても微妙と分かる作品だ。点は一律40点。
③「天才」。非常に高い評価を得ることもあるが、一方でその独創性が故に評価者によって大きなムラがある。
相性が良い審査員と当たれば100点。悪い審査員と当たれば60点となる。なお、どちらの審査者に当たるかは半々の確率とする。
④「ワンチャンス」。粗が多く製品になるレベルとは言えないが、人によっては面白いと感じる部分もある作品だ。
こちらも③と同じく、審査員との相性が半々の確率で決まる。運が良ければ70点。悪ければボロクソの評価となり10点である。

点数の期待値は「優等生」と「天才」が80点、「ダメダメ」と「ワンチャンス」が40点。この中では「優等生」と「天才」が受賞候補と言えるだろう。
(優等生や天才が多すぎでは?という意見もあるだろうが、あくまで例なので気にしないでいただきたい)
さらに優等生・ダメダメは点数が安定している一方、天才・ワンチャンスは審査員によって好みが分かれるという特徴がある。
これらの4グループからなる応募者の集団に対し、これから審査を行っていく。またこの例で、「天才殺し」がどのように行われるか述べていきたい。
さて、最初に一次選考の開始だ。
今回、合格点は65点とする。また各作品に割り当てる評価者は一人のみとしよう。
この評価者が作品を採点し、65を上回れば一次通過、下回れば一次落ちである。
まず「点数が安定」の作品群では順当な評価がなされる。
全員80点の①「優等生」は全員問題なく選考を通過。逆に40点の②「ダメダメ」は全員があえなく落選だ。
一方、「好みが分かれる」作品群は異なる様相を呈す。
まず③「天才」であるが、半分の50人近くは運悪く相性の悪い審査者に当たってしまう。
その場合、評価点は60点。残念ながら落選だ。残り半分の、相性良い審査員に当たった応募者しか選考を通過できない。
だがこれだけで、直ちにこの種の「好みが分かれる作品」が不利とはいえない。その分、評価点の期待値では落第点の④「ワンチャンス」が上に上がるからだ。
今回の合格点は65点。「ワンチャンス」は相性の良い審査員と当たれば70点なので、半分近くが通過する。

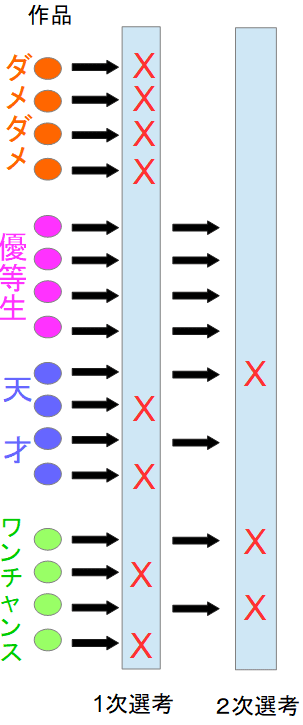
1次審査終了時、残ったのは「優等生」が100人、「天才」と「ワンチャンス」が50人。
「点数が安定」の作品群と「好みが分かれる」作品群が同数である。
一見公平な勝負に見えるだろう。……この時点では。
続いては二次選考だ。今回は当然一次よりも選考は厳しくなる。
合格点は72点へと上げよう。この点数以上取れれば二次選考突破だ。評価者は一次選考と同じように一人とする。
さて、結果がどうなるか見てみよう。
まず、「ワンチャンス」はここで全滅する。どうやっても70点より上にはならないからだ。
「優等生」は80点なので、全員が通過。一方で「天才」はまたもや、半数が相性悪い評価者と当たってしまい落選する。
残るのは「優等生」が100人、「天才」が25人、他2グループは0人である。

何か、おかしくないだろうか???
これは直感に反する結果だ。
先述した通り、「優等生」と「天才」の点数の期待値は両方とも80点である。
そして両グループとも、当初の応募者は100人ずつ。だったら同じくらいの人数が残るというのが普通の感覚だ。
にもかかわらず、残っている作品数は4:1。「優等生」の方が「天才」よりもはるかに多い!
なぜ、こんなことになってしまったのか?
その最大の原因は、「好みが分かれるものの正確な評価が、極めて難しい」ことにある。
「優等生」「ダメダメ」グループの作品は評価ミスが起こりえない。
これらの作品は、誰が見ても同じような点数をつけるためである。評価者一人の評価点が、様々な評価者が行った評価の平均値と必ず一致するのだ。(このような性質を、エルゴード性と呼ぶ)
一方で「好みが分かれる」群は、評価者との相性によって点数が大きく変動する。(上の例では本来80点の「天才」に対し、評価者は20点ズレた評価を行ってしまう。これは無視できない誤差だ)
非エルゴード的な存在の「天才」が選考を通過できるか否かは、作品の出来だけに依らない。「審査員とのマッチング運」にも左右されてしまうのである。
そして今回、割り当てられる選考者はただ一人のみ。これではマッチング運の比重が高く、作品自体の出来のみの評価にはなっていない。合格レベルのものがマッチング次第で落選してしまう可能性がある。
その代わりに本来落第点の「ワンチャンス」が通過するかもしれないが、これは慰めにはならない。「安定評価」の群と「好みが分かれる」群の間には「質の偏り」が生じてしまうからだ。
試しにこれらの2群に対し、一次選考終了時点での点数期待値を計算してみよう。
「安定評価」群は全員「優等生」だから80点。一方、「好みが分かれる」群は「天才(80点)」、「ワンチャンス(40点)」が半々のため60点である。
この様に、残った作品の平均的な出来は前者が後者を凌駕するのだ。
そしてこの質が偏った集団に対し、二次選考が行われる。
「ワンチャンス」はただマッチング運により通過しただけの、合格レベルとはいえない作品だ。より高いレベルが要求される二次試験では相性の良い審査員とマッチングしても容赦なく落とされる。
また「天才」も、一次選考と同じく審査員とのマッチング運によって一定が落選する。一方で「優等生」は相変わらず落選しにくい。彼らの作品の評価にはエルゴード性が成り立ち、実力(点数の期待値)が高ければまず生き残るからだ。
こうして二次選考においても天才のみが淘汰され、その先に三次選考が待ちうける。
上記のように「天才」は、決して作品の出来が劣っていないにもかかわらず選考序盤から淘汰されてゆく。その一方で「優等生」は残り続ける!
この現象こそが、「天才殺しのメカニズム」である。下に分かりやすくまとめよう。
<天才殺しのメカニズム>
①評価対象の集団に「評価が安定している」群と「好みが分かれる」群が混在している。
②安定評価の集団は正当な評価を受けやすい一方、好みが分かれる集団の評価にはエラーが生じやすい。
少ない評価者による足切りを取り入れた選考を行う場合、その独創性ゆえに評価の分かれやすい「天才」はマッチング運により選考序盤で一定数が淘汰される。
一方、同じぐらいの実力でありながら評価に再現性のある「優等生」はひとまず生き残る。その結果、①の二つの集団間に「質の偏り」が生じる。
③「天才」の代わりに評価エラーで運よく生き残った者は、実力不足のため後の選考で確実に淘汰される。
④選考を繰り返すことで、上位選考に残るのは「優等生」が多数を占めるようになる。「天才」はマッチング運のよい一握りが残るだけ。
この「段階的評価システム」は一見公平で、全ての応募者に対し平等に作品の出来(すなわち、点数の期待値)を評価するように見える。だがそれは幻想にすぎない。
本システムは作品の出来だけではなく、「評価点のバラつきの小ささ」をも審査していることになるのだ!
そして上に挙げた「質の偏り」の様な問題は、バラつきの大きい対象の評価をごく少数の評価者が行うことでもたらされる。
残念ながら、「天才」を一人の評価者だけで正確に評価するのはどうあがいても不可能なのである。
ところでこのような問題が起きるのは、「天才」を評価しない審査員が悪いからだろうか?
少なくとも私はそうは思わない。これはある意味、仕方がないことだ。
我々人間には一人一人、個性というものがある。各審査員には評価軸の違いがあって当然だし、個性があるから我々は別人が創り出した作品を楽しむことができるのだ。
だがこの個性は多数の評価エラーを生み出す元凶にも成り得る。自分が面白いと評価しても周囲はそうでもなかったり、またその逆といったことがあるからだ。
そんな中、客観的に優れた作品を選び出すというのは極めて難しいタスクである。評価者がやれることにはおのずと限界があるのだ。
一方で、審査会の成功(すなわち、より良い作品を選び出せるかどうか)を決める要因は、評価者の有能さだけではない。
「選考のシステム」も、大きくかかわってくるのである。これは上で述べた通りだ。
しかしながら評価者の有能/無能さに言及されることは多々あれど、「システム」の構造に目を向けられることは少ない。
そのシステムの形態によって、応募者の運命が大きく変わる場合があるにもかかわらず……。
以上が、一定ラインで足切りを行いながら選考を進める評価システムに潜む問題の一例だ。
そして問題を認識した今、考えるべきことがある。どうやって上のような”不合理的な評価エラー”を無くすかだ。
安直な解決案の一つは、単純に評価者の数を増やすことである。
例えば一次選考の時点から、五人ほどが作品を読むようにする。こうすれば評価点が平均化されることで評価エラーは減るだろう。
しかし当然ながら、これは費用がかさむため現実的ではない場合が多い。
評価者を増やす時のコストは、特に選考する対象が多い序盤ほど大きくなる。(だからこそ、この種の評価システムは選考を段階的に行うのだ)
採算が合わなくなり賞の存続ができなくなるのは、選考に関わる人全員にとって本意ではないだろう。極力コストは増やさぬまま公平な審査を実現したいはずだ。
残念ながら評価エラーの根絶は、上記のようなコスト的な制約からまず不可能。
しかしながらエラーを減らす工夫を行うことは可能だ。以下ではその一例を紹介しよう。
選考で問題となるのは、「作品の質」以外の不合理的なファクターによって選考判断が乱されてしまうことだ。
すなわち、評価者とのマッチング運のような”ノイズ(ランダム性の高いバラつき)”に結果が左右される状況を極力作り出したくないわけである。
今回、ノイズを引き起こす一つとして「ジャンルの好み」を取り上げよう。
本来、ジャンルによる優劣なぞ存在しないはず。ファンタジーとラブコメでは、ファンタジーの方が優れているなんてことがあるだろうか? 無論、そんなことはないだろう。
だが一方で、人により「ジャンル」の好みに大きな差があることを我々は知っている。
このようなファクターは、公正な選考の支障になる危険性が高い。なぜならこのファクターによる評価の格差は、評価者側の都合だけで生じるものだからだ。
そしてこの種のノイズの一部をうまく取り除く方法がある。不合理的な判断を引き起こしやすいファクターによって作品の「分類」を行った後で、評価者に作品を配分するのだ。
通常各評価者には応募作がランダムに配られていたが、これを変更するのである。
例えばある評価者がファンタジー好き・ラブコメ嫌いだったとする。
するとこの評価者に配分された作品の内、ファンタジーは選考を通過しやすく、逆にラブコメは通過しにくくなるかもしれない。
だがこれは不合理的な判断と言える。評価者のジャンルの好みによる有利不利はマッチング運に起因するものであって、作品の質の評価によるものとはいえないからだ。
そこでまずは、応募作を「ジャンル」で分類する。
そしてそのジャンルごとに作品を一まとめとし、評価者へと分配を行う。ある評価者にはファンタジーのみを配り、別の評価者にはラブコメのみを配るのだ。
このように同ジャンルの作品のみが配られれば当然、評価者はその中から通過作を判断せざるを得ない。ファンタジーはファンタジー同士で、ラブコメはラブコメ同士での選考となるわけである。
当然、ジャンルの違いによる評価のバラつきは起きにくくなるだろう。「分類」を事前に行うことで
①作品の質とは関係のないファクターによる評価のバラつきを抑えることができる。
②距離の近い作品同士で比較を行うことで、審査を相対的にしやすくなる。
上の二つが実現可能となる。
このように、評価エラーの発生をアルゴリズムによって解決しようというのが、私の考えである。


上の説明が直感的に分かりにくいようなら、食べ物の審査で考えてみても良い。
例えば複数の牛肉とワインについて、順序付けを行いたいとしよう。
私はこの二種の比較に困難さを感じる。なぜなら私はワインの味が苦手だからだ。
出された牛肉とワインのどちらが良いかと問われたら、私は基本牛肉の方を選んでしまうかもしれない。例えワインが厳選された素材を使った超高級品であったとしても。
では、牛肉とパフェだったらどうか? 私はどちらもそこそこ好きだから、正確な評価ができるだろうか。
残念ながら、答えはNO。なぜならこの二つの”評価”は全く別物であるからだ。
牛肉の時は「焼き加減が肉と合っているか? 生臭い臭いがしないか? 脂は適度な量でジューシーか?」
一方でパフェの場合、「温度はちょうどいいか? 甘ったるすぎないか? 材料同士がマッチしているか?」
などといった視点で評価が行われる。
評価軸に違いが有りすぎて、この二種を精密に順序付けるのは困難だ。これではまともに審査を行っているとはいえない。
一方で多数の牛肉の中から、良いものを選ぶだけでいいならどうなるか?
審査員は元々好みのものとワインのような嫌いなものを無理やり比べるという拷問から解放される。
また審査員は、それぞれの牛肉に対し共通の評価軸を適用できる。結果、正規化の手間が抑えられより精密な判断ができるようになるだろう。
少なくとも消費期限の近い外国産の解凍肉ではなく、新鮮な高ランクの和牛を選べるはずだ。
このように、評価軸が異なるもの同士の比較を行う必要がなくなることで、判断の質が上がることが期待できるのである。
(余談だが、逆に数あるワインの中から1つを選べと言われたら……私は審査員を降りる。良さが全く理解できないジャンルの審査員になってはいけない。評価を受ける側に失礼だ)
この「ジャンル分類方式」の選考を行う場合、異なるジャンルの作品の比較は高次でのみ行われる。ひょっとすると、難しい判断をただ後に遅らせているだけだと感じるかもしれない。
だが思い出してほしい。新人賞システムは選考が進むほど、1作品の評価に多くの人数をかけられる。すなわち数の力によって、後の選考における判断ほど正確に行えることが期待できるのだ。
(もっともこれには条件があるのだが、話が複雑化するためここでは言及しない)
誤判定は各作品に人数を割けない序盤で起きやすいだろう。ここで注力すべきは「良い作品をいかに落とさずに、コスト削減するか」だ。
合格点が低いこともあり、1次選考というのはそこまで重要視されていないプロセスかもしれない。だが実は、1次こそがシステム設計者の腕の見せ所である。
高次の選考では多くの評価者が作品を見るため上記のような工夫の入り込む余地がない。一方で少人数での判断をせざるを得ない選考序盤では、適切な審査アルゴリズムが力を持つのだ。
このように評価システムを工夫することで、良い作品が選ばれる確率を上げられる。”ノイズ”が減ることで、評価者がより良い判断を行えるようになるからだ。
もちろん選考対象となる集団の質・特性などによって、適正なシステム設計は変わってくる。
例えば上で示した「ジャンル分類」案は、多様なジャンルが存在するライトノベルの賞では比較的高い効果を見込めるだろう。
一方ジャンル限定の賞(例えばミステリーの新人賞)では限定的な効果しか望めない。送られてくる作品のジャンルの多様性がライトノベルよりもはるかに小さいからだ。
開催者は「応募者の集団にどんな特徴があるのか?」を考えながらシステム設計を行う必要があるだろう。
このような工夫は、ほんのちょっとの労力を要求するかもしれない。しかし正確な選考判断により一番利益を得られるのは当の開催者(+真に実力がある応募者)なのだ。
以上、小説の新人賞を例に説明してきたが、本記事の議論は新人賞に限らず同種のシステムに適用できる。
一定ラインで「足切り」を繰り返す選考システムは、常に「天才殺し」のような問題がつきまとう。
より公平かつ優れた審査を望むのであれば、コンテスト・審査会の開催者はこの種の数理的な原理にも気を配った方がいいだろう。
応募者の多くは、選考のため何か月も必死に作品を作り上げて来たはず。また評価者・審査員も、より良い作品・人を受賞させられるよう懸命に頑張っている。
だがそんな人たちの想いが、本記事にあるような「システム」の些細な不具合の見落としにより無為になってしまう。
そして応募者や審査員はもちろん、身銭を切っている開催者でさえも、「天才」が殺されてしまっていることに気づかない――。もしそうだとすれば、こんな悲しいことはない。
まずは用いる評価システムによって、もたらす結果が大きく変わり得ることを認識すること。
そして評価エラーが極力起こらないよう、様々な工夫を施しつつ注意深くシステムを設計することが重要なのだ。
より良い評価システムの構築により審査員の能力が最大限に活かされ、一人でも多くの「天才」を救うとともに、その天才の成果物が巡り巡って多くの者に幸福をもたらすことを願いながら、本記事を終える。
<参考文献>
NOISE: 組織はなぜ判断を誤るのか?
ダニエル・カーネマン, オリヴィエ・シボニー, キャス・R・サンスティーン 著
早川書房
天才を殺す凡人 職場の人間関係に悩む、すべての人へ
北野 唯我 著
日本経済新聞出版
<参考動画>
一次選考で落ちてもあきらめないで!【新人賞・小説大賞】
わかつきひかるの小説道場
https://www.youtube.com/watch?v=NOQHwwyEESw
補足1:
本記事で述べたようなノイズが引き起こす問題は可視化されづらいため、あまり多くの人には認識されていないのが現状だ。
だがこのような問題を積極的に解決しようとしている団体も既にある。
例えばGoogle社は採用プロセスにおいて、構造化面接というものを採用している。
https://rework.withgoogle.com/jp/guides/hiring-use-structured-interviewing#read-googles-internal-research
我々の直感が時に間違いをおかすことを受け入れ、システムの工夫とアルゴリズムの力によって解決を試みている良い事例である。
選考システムを運用している者にとっても、参考にできる部分があるだろう。
Google社の選考システムについては、下記のページでも分かりやすく説明されている。
https://matter-hajime.com/2022/02/06/グーグルの面接改革/
補足2:
お上手な評価システムを作る事の困難性については、アローの不可能性定理なども参照。https://ja.wikipedia.org/wiki/アローの不可能性定理
これは投票理論の話となるが、集団に対して上手く順序づけを行うことの難しさを垣間見れるだろう。
補足3:
最近流行りの機械学習には、この種の評価システムに似た構造を持つ「バギング」と呼ばれる概念がある。
より審査の精度を向上させたければ一度調べてみるのも手だ。システム改善のヒントになるかもしれない。
例えば下記ページでは決定木(選考システムで言う評価者)同士の相関を下げることのメリットが紹介されている。
https://nigimitama.github.io/note/20200429_why_bagging_works.html
これはすなわち、2人以上の審査員の判断を統合して選考を行う場合には、好みが異なる審査員を組み合わせるのが有効であるということだ。
(この原理を直感的に理解するには、全く同じ判断をする審査員2人を考えてみると良いだろう。そのような評価者達の判断を統合した所で、審査結果は1人の時と変わらない。ただコストを無駄に多く払っているだけだ)
補足4:
人間は基本的に非エルゴード的な存在のため、「一般に天才の数は少ない→あなたが天才である確率も小さい」という論理を軽率に持ち出すのは危険である。
だが一方でこれを拡大解釈し、「天才が少なくても関係ない。私がその天才」という論理展開を繰り広げる者もいる。
残念ながら、天才かどうかを判断するのは著しく困難なタスクである。ゆえにあなた自身が天才である確率については「判断できない」辺りが落とし所の言葉だ。
心理上のバイアスなどが原因で、恐らく「自称天才」の数は実際の天才よりも多いだろう。だがその自己評価はあまり当てにならないのだ。
私はあなたが天才である可能性を否定しない。だが実際には天才じゃない可能性もあることを心の片隅に留めておいた方がいいだろう。
(自分に自信を持つこと自体は決して悪いことではないが)
余談だが、私は大した根拠も持たずに自らが天才だと周囲に喧伝することを「非エルゴード性の私的利用」と呼んでいる。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?