
最初期のスタートアップでデータプロダクトを創る3つの戦略

先日、CTO LT 会という会でテッキーに今年1年を振り返る機会があったので、そこでの発表内容に加筆してココにまとめたいと思います。
今年一年を振り返ってみると一番のチャレンジは、創業期の 0 → 1 フェーズのスタートアップで如何にデータプロダクトを創るかってことかなと思うので、これについて書いていきます。
ちなみにこの記事は弊社のアドベントカレンダー用に書いていたのですが、全く間に合わなかったのでロスタイムで書き上げました(笑)
データプロダクトとは
そもそもデータプロダクトとは何なのかと言うと、簡単には
データから主要な価値を生み出すプロダクト
のことです。
データ活用というと既存のすでに価値を提供しているプロダクトをデータ施策によって改善することが多いかと思います。例えば、 Amazon などの EC サイトでは商品が Web 上で購入できるという価値が既にあり、それを効率化するためにレコメンドなどでデータが活用が行われています。
これに対して、データプロダクトでは、データ活用そのものが提供価値の中心にあるプロダクトです。例えば、上記と同じレコメンドでもニュースレコメンドサービスの場合は、ニュース記事自体は他メディアから持ってきたもので提供価値ではなく、レコメンド機能が提供価値の中心にあり、これが無いとサービスとして価値が無くなってしまうのでデータプロダクトだと言えます。
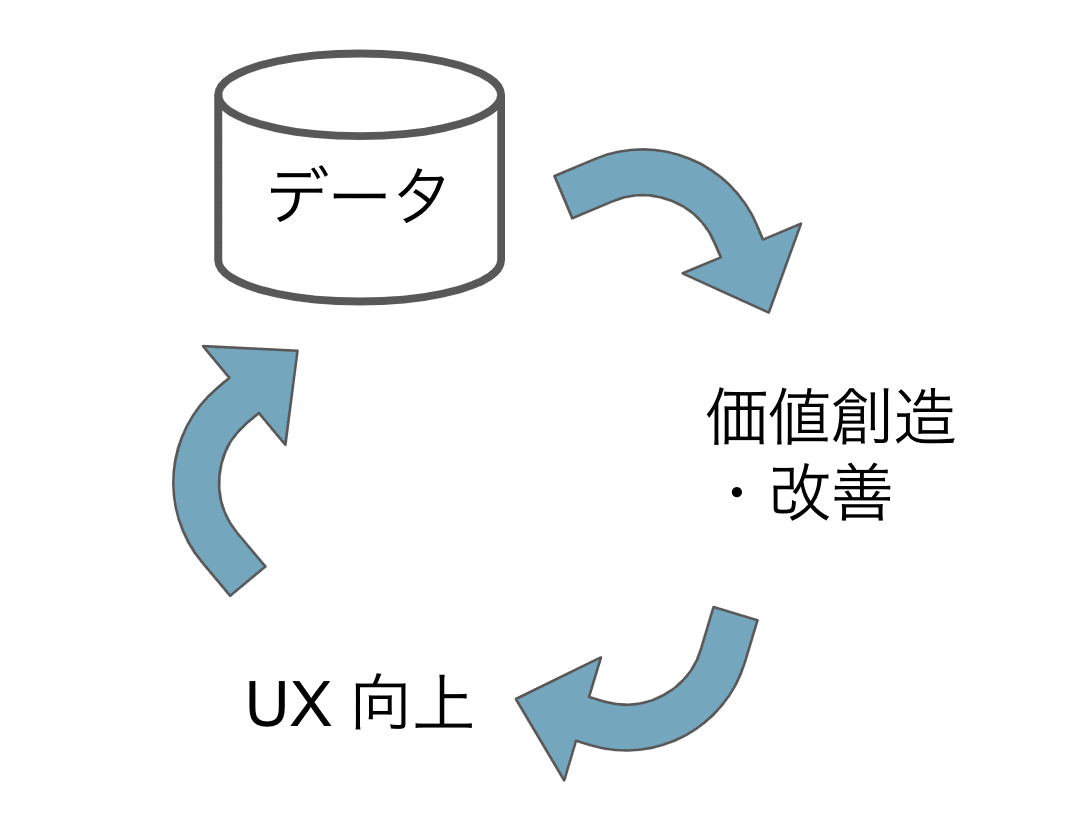
データプロダクトにおいては、
① データから価値創造をし、
② 提供した UX によりユーザーを獲得
③ ユーザーがプロダクトを使うことでよりデータが集まり、
①' 更に集めたデータによって価値を改善し、
②' その改善により UX が向上し更にユーザーを獲得
③' さらにデータが集まり、
︙
というポジティブな改善サイクルが回ることでプロダクトの価値がどんどん向上していきます。
兎にも角にも、まずデータが必要
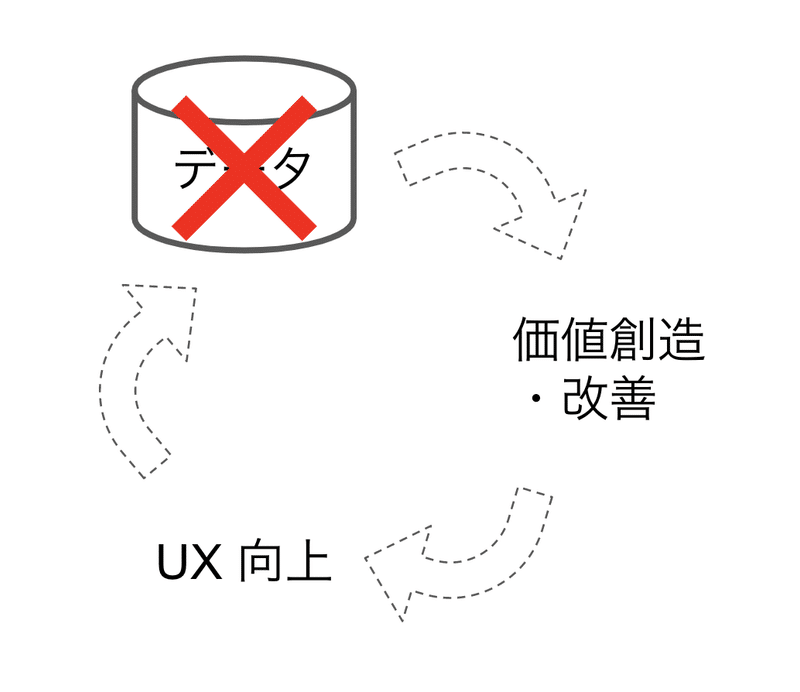
そして、最初期のスタートアップでデータプロダクトを創る上で問題になってくるのは、このポジティブな改善サイクルの一番最初で躓いてしまうということです。
データプロダクトはまずデータから価値を創造することが必要になってくるのですが、最初期のスタートアップではそもそもデータが無いので価値創造ができないのです。そのため、最低限の UX も提供できずユーザーに使われず、結果データも集められない、というネガティブサイクルに入ってしまいます。
「データプロダクトのニワタマ問題(鶏と卵問題)」とも言うべき問題が発生します。
初期データ収集戦略
ということで、最初期のスタートアップでデータプロダクトを創るためには、最初のデータを如何に集めるかということを考える必要があります。私が考えるに、他のスタートアップなどを見るとこの戦略は3つぐらいあるかなと思うので、弊社で実践していることも含めて紹介したいと思います。
1. 代替データを使う
まず、考えつくのは、実際のデータに類似したデータを何かしらの方法で集めて活用することです。
例えば、ニュースレコメンドサービスの Gunosy は最初期では Twitter のデータを用いてレコメンドエンジンを作っています。このデータは API を使えば誰でも手に入るデータでしたが、ツイートと共有されているニュース記事から、どのようなユーザーがどのような記事に興味があるかが分かるので最初のレコメンドエンジンを創るには十分なデータだったと思われます。
他にも自動運転サービスの場合だと車載に搭載したカメラやセンサーのデータが必要になりますが、実際にユーザーの車からは集められないため、開発者が運転して集めたセンサーデータを用いて AI を構築しています。
しかし、この戦略の場合、集めたデータが実際のプロダクトで上手く働かない場合も多くあります。これは AI の学習に用いた代替データと実際のデータに差異があることが原因です。例えば、上記の自動運転の場合だと、学習データとして集められるのは開発者が想定して再現できるドライビング状況だけで、実際に交通事故を起こすような状況のデータなどは含めることができません。
この問題を回避するためにも、代替データの使用は最初だけにして、それ以降は上記の改善サイクルに則り、プロダクトで実際のユーザーから集められるデータを使うべきだと考えられます。また、このような学習データとテストデータの違いによる問題は、共変量シフト (Covariate Shift) など非定常分布の学習に関する領域で研究されていますし、違うドメインの学習データを別ドメインに適用するという意味では転移学習 (Transfer Learning) という分野でも研究されているので参考にしてみると良いかもしれません。
2. データホルダーと組む
次に考えられる方法として、データを保有している既存企業(データホルダー)と組む方法が考えられます。既にある程度ユーザーがいるプロダクトを所有している企業はそこから大量のデータを生み出すことが可能です。
例えば、Prefered Networks や ABEJA などの業務提携や委託開発を主にする企業がこれにあたります。これらの企業は提携先の保持しているデータを用いて、提携先に特化したデータソリューションを提供します。既存プロダクトの改善などデータ案件的なものが多いかと思われますが、 BtoBtoC として新しくプロダクトを創る場合などもありえます。
ただ、上記のような業務提携系だとスケールさせることができないという問題があります。基本的には労働集約型のビジネスですし、特定の企業に特化させるため他の企業で適用できる場合も少なくなってしまいます。
また、データを保有していないため主導権がデータホルダーにあり、Moat としても技術力のみになり、企業の生存戦略としては構造的に弱くなってしまいます。
これらの問題を解決するには、様々な企業で一般的に活用できそうなソリューションを見つけサービスとして提供することが考えられます。そうすることで様々なデータホルダーからデータを提供してもらえるようになります。例えば、 PKSHA Technology はチャットボットで使える対話エンジンなどの自然言語処理技術をプロダクトとして様々な企業に提供しています。
3. 段階的にデータとプロダクトの質を進化させる
上記の2つの戦略は対象ドメインがある程度成熟していれば実行できます。しかし、スタートアップでは新しいドメインを創っていくことも多く、その場合これらの戦略が取れません。弊社でも同じ状況であったため、なかなか苦労しました。振り返ってみて、弊社ではどのようなアプローチを取ってきたのかというと、段階的にデータとプロダクトの質を進化さる戦略です。
最初にニワタマ問題(鶏と卵問題)と言いましたが、実際、鶏と卵はどちらが先に存在していたのでしょうか?答えは「どちらでもない」です。鶏はセキショクヤケイという鳥から進化したと言われており、更に遡るなら原鳥類や恐竜が祖先になります。つまり、はじめから今のような鶏の姿だったわけではなく徐々に別の生物から変化してきて今に至っているのです。
データプロダクトでも同じで、最初から目指しているプロダクトを創るのが難しい場合は、それを創るのに必要なデータを集められるようなプロダクトを創り、段階的に目指しているプロダクトに近づけていく進化的戦略を取ることができると思います。
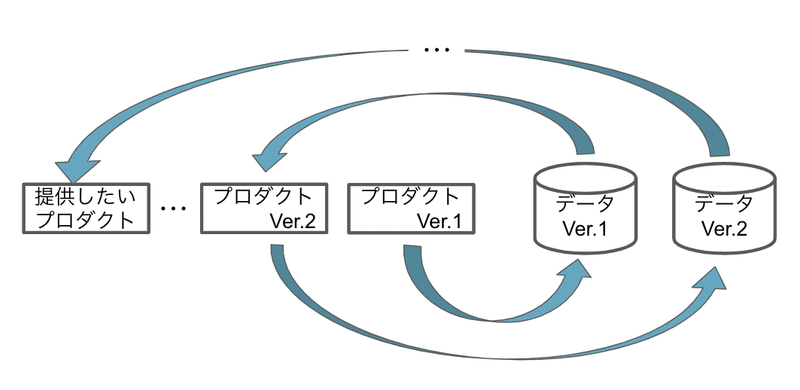
プロダクトの Ver. 1 を創り、それをユーザーに提供することでデータの Ver.1 を収集します。このプロダクト Ver.1 はデータプロダクトである必要はありません。このプロダクトの目的は種となるデータを集めることなので、ソレさえ満たしていれば、別種のプロダクトでも構いません。次はプロダクト Ver. 1 で集めたデータ Ver.1 を用いてプロダクトの Ver.2 を創り、データの Ver.2 を集めます。このサイクルを繰り返すことで段階的にデータの質を進化させていき、プロダクトも目指しているプロダクトに進化していくことができます。
弊社の場合だと、最初はコミュニケーションツールのデータを解析して得られたインサイトをレポートとして提供することで、コミュニケーションツールのデータを集めました。次に、そのデータを用いて従業員負荷の大きかったパルスサーベイをターゲティングにより効率化し、これを提供することでサーベイデータを収集しました。そして、コミュニケーションデータとサーベイデータから AI を構築しサーベイレスで従業員の状態を推定できる機能を提供するようになりました。
この進化的戦略はデータプロダクトだけではなく他のドメインでも取りえる戦略です。例えば、フリルやメルカリなどの CtoC マーケットプレイスでは、最初から売り手も買い手も集めることは困難なので、運営元が売り手のふりをして他で仕入れてきた商品を売るところから始めていたらしく、これは CtoC マーケットプレイスではなく所謂 EC サイトです。ここから徐々に買い手を増やし、売り手にとってメリットのあるプロダクトにすることで売り手を増やし CtoC マーケットプレイスにするという戦略を取っていたようです。このように構造的にニワタマ問題をはらんでいるドメインだと進化的戦略が有効だと考えられます。
データプロダクトでこの進化的戦略を実施する上で重要なのは、プロダクト開発と集められるデータの全体を俯瞰した戦略が立てれるかだと思います。最終的に目指しているプロダクトを創るにはどのようなデータが必要で、それを集めるにはどのような機能を持ったプロダクトを作る必要があるのか、この進化の過程を逆算的に設計することが必要になってきます。なので、データ活用とビジネスについて知見のあるデータサイエンティストやアナリティクスディレクターを創業期からメンバーにすべきです。
ただ、最初から完全に設計するのは難しいですし、進化途中のプロダクトでも使ってもらえないとデータ収集すらままならなくなってしまうので、 Lean な開発サイクルの中で随時設計を見直していくのが良いと思います。開発したプロダクトを検証する中でデータを集め、集まったデータの質と量を鑑みることで進化の方向性を修正することができます。
以上、弊社でどのようにデータプロダクトを創っているのかと共に、初期のスタートアップで取り得る戦略をまとめてみました。
3つの戦略の中でも進化的戦略は難易度が高いな、と今年1年振り返ってみて思います。ただ、時代の流れとしては、 AI など技術が一般化しデータ活用は既存ドメインに技術を適用するだけでなく、新しいドメインを開拓していく必要があると思っているので、その先頭を切るスタートアップではこのアプローチが必要になってくる場合が多くなってくると考えています。
これらの知見がこれからスタートアップを起ち上げてデータプロダクトを創ろうとしている方々の参考となれば幸いです!
この記事が気に入ったらサポートをしてみませんか?