
【開発】筋肉AIは学習後に電気プロテインを飲むか①

みっつです。
時間がかかるかもしれませんし、頓挫してしまうかもしれませんが、筋肉AIを作ってみようと思います。
経緯
バーチャルSNS Cluster にて開催された「大筋肉祭」というイベントにて、かわしぃさんという方が下記のようなLTを行っていたことを、Twitterのタイムラインで知りました。
発明 https://t.co/AiM6hJePbj pic.twitter.com/rdESoor7Eq
— かわしぃ@ローカル電脳VRアート🎨戦士 (@s_kawasy) August 29, 2021
「あ、これ、ちょっと頑張ればたぶん作れるな。」と思ったので、挑戦してみます。
「たぶん作れるな」についての詳細は、このツイートをたどってみてください。
また、「やってみようと思います!大丈夫ですか?」という点については、かわしぃさんに確認してみたところ、ご了承いただくことができました。
「最高ですね、やりましょう!」と。
この返答が、最高に最高ですね。
第一目標はプロトの作成
上記ツイートのツリーでも触れていますが、ゆくゆくは1000枚程度の写真を使ったデータセットを作りたく、そのラベル付けにおいても複数人の意見をスコア化するような方法を取りたいと思っています。
が、まずは一人で簡単なプロトを作ってみる、というのがいいと思っています。他者の力を借りる前に、自分である程度検証して、うまくいく算段をつけておきたいという、よくあるやつです。
いいプロトにはいい仲間が集まるものだと信じて。
第一弾としては、
・掛け声の種類は2種類
・データセットのサイズは、写真100枚程度
の物を考えています。
事前にA,Bという掛け声を用意しておいて、写真を読み込んだら「Aだよ!!!」あるいは「Bだよ!!!」と、写真に対する"もっともらしい"掛け声を返してくれるという、AIです。
データへのラベル付けやモデルの学習がうまくいけば、AIの回答への納得感が得られそうです。
これを目指します。
今回の報告
今回は、まずデータとなる写真を集めることを行いました。有料プランに加入しているPhoto ACで探せばある程度集まるかな、という考えがあったのですが、甘かったです。
どんな検索の仕方をしても30枚が関の山。
努力の塊、筋肉は、そうそう安売りされていないということでしょうか。
悩みあぐねたみっつ青年、「筋肉 フリー素材」という何とも脳筋な検索をかけてみたところ、まさかの光明がさしました。
トップに表示されたのは
「マッチョフリー素材サイト『マッスルプラス』」さん。
ほんとうにありがとうございます!!!!
1ページあたり20枚。計87ページ分、すべてのマッチョに目を通し、使えそうな写真を選別しました。
マッスルプラスさんにて集まった画像は計113枚。Photo ACから集めた31枚も足して、144枚。これならひとまずのモデル構築もできそうです。
ほんとうにありがとうございます!!!!
選定においては、
・被写体が一人であるものを選ぶこと
・写真の主題が筋肉を表現している人である写真を選ぶこと(写真の中央部に人が一人写っている構図になっていること)
・連写や、手元、表情のみが変わっているような写真はできるだけ省くこと
を重視しました。
学習用データを作る際に画像をトリミングする可能性があること、人の身体以外の部分の特徴量化を防ぐ必要があること、回転や反転などでデータの水増しを行う予定なので似たような写真は後で自動的に増やせること、などを意識して選別しました。
データが少ないうちは仕方ないですが、つまり出来上がったAI君は、ここで選別された写真に近いものについてしか予測できないというディスアドバンテージが、この操作で決定してしまったということでもあります。まあ仕方ないんですけど。
というわけで、いま僕のデスクトップにあるフォルダはこんな感じです。ワクワクしますね。
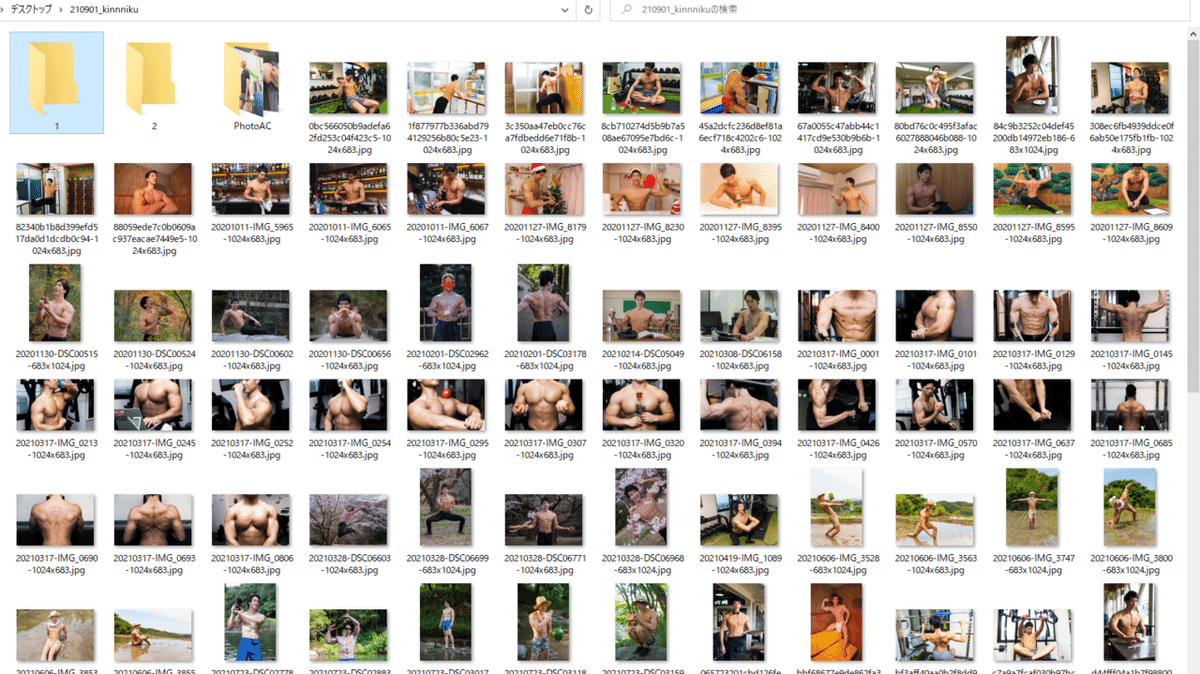
100以上の筋肉、圧が凄い。
(実はこの時点で、展望として考えている1000枚の筋肉学習用データセット;"筋肉AIくん用の教科書" をつくるハードルが高いという問題もじわじわ明るくなってきているのですが、これについてはプロト君の出来次第で何とかなるとも思っています。いいプロトには、いい仲間が、、、。)
次やること
次は、この集まった写真を仕分けしていきます。

この「1」「2」というフォルダに分けて入れていこうと思います。
ということは、何をもって写真を分けるのか、という判断軸が必要となります。
ここが実はAIづくりの肝であったり、開発者の腕の見せ所だったりします。
当初は、下記のように「筋肉本舗」と「プロポーションおばけ」のラベルで割り振っていこうと考えていました。
こちらの本を買いました。
— みっつ@vket6ラグーナ・フィオーレ9 (@Mittsujp) August 31, 2021
Chapter4 超上級編 より
「筋肉本舗」と「プロポーションおばけ」の二択で画像を仕分けしてみようと思います。 pic.twitter.com/zCQzPdGBUT
今回データを集めていて少し考えが変わったので、次回のためにメモしておきます。
まず初めに気づいたのは、『マッスルプラス』さんに掲載されている画像は、どちらかというとネタ画像が多く、ボディビルのコンテストのような筋肉を見せるようなものではないことです。
ラベルを考え直す必要があるな、、、と思いながら収集作業を続けました。
そしてもう一つ、ラベル付けについて気づいたこと。
感覚的ですが、作品として写真を眺めていると、
「その写真がとらえた一瞬に重きを置いたもの。筋肉のきらめき。」
みたいなものと
「その写真に写された筋肉が出来上がるまでの過程、積み重ねを感じさせるもの。研鑽の日々。」
みたいなもの、の二種類があるのでは?ということです。
この2つのラベルは互いに相関しない意味を持っていそうので、よさそうな気がします。
もう少しうまく言葉にして、それらしい掛け声に変換してラベル化しようかなと思います。
もしかしたらもっと別のラベルがあるかもしれないので、引き続き考えていきます。ご意見ございましたらコメントやTwitterのDMなどでいただけたらと思います。
ということで、次は画像の仕分けが終わったら報告します。
この記事が気に入ったらサポートをしてみませんか?