
アマゾン 生成AI市場の戦い方:AWSの生成AIプラットフォーム戦略

今回は、アマゾンの生成AI関係の取組み、特にAWSにおける昨今のサービス展開にスコープをして、紹介をしたいと思います。
アマゾンの生成AIについては、業界で注目を集めるNVIDIAやOpenAI、マイクロソフト、Googleなどのプレイヤーに比べると、比較的控えめな存在と感じられるかもしれませんが、もちろん彼らが何もせずに手をこまねいているわけではありません。
ご存知の通り、AWS(Amazon Web Services)は、クラウドコンピューティングサービスを提供するアマゾンの子会社で、そのサービスは政府機関や企業に向けたもの、つまり、AWSの提供するほぼ全てのサービスは、政府機関や企業などが利用するシステムやアプリケーションを支える裏方のサービスが数百集まって構成されたサービスです。
今回は、アマゾンがAWSを通じて、企業向けの生成AIをどのようなサービスでどのように訴求しているのか、その一端を覗いてみたいと思います。
今回は特に、生成AIの使い手となる企業に対するAWSの成長戦略提案について触れてみたいと思います。
1. アマゾンの生成AIエコシステム
まず、AWSの生成AIサービスの話に入る前に、アマゾンがそのEC事業やビジネス共通基盤で進めている生成AI系のプロジェクトを3つ、簡単に紹介したいと思います。
ECショッピングアプリの「Rufus」、自社開発のAIアクセラレータチップ「Trainium/Inferentia」、そしてこれも自社開発となるマルチモーダルな基盤モデルとなる「Titan」です。
(1)Amazon Rufus
「Rufus」は、アマゾンのEC事業における消費者のショッピング体験を生成AIアシスタント機能で拡張するアプリです。
「Rufus」には、アマゾンの商品カタログやカスタマーレビュー、Q&Aやウェブ上のデータを学習した生成AIが組み込まれており、消費者のさまざまな買い物ニーズや商品に関する質問に答えることができます。消費者とチャットを繰り返しながら消費者の求める商品推奨する機能や同じカテゴリ製品の特徴や詳細な情報に基づいて商品選定の際の留意点を提示したりすることができます。
[利用例]
“寒冷地でゴルフをするときに持っていったら便利なものは?“であったり、”このジャケットは洗濯機で洗えるか?”の様な質問を行い、それに対してRufusがチャット形式で回答や提案を行うというイメージです。
米国では、2024年2月からベータ・リリースとして消費者が利用できるようになっており、今後、正式なリリースが期待されている状況にあります。

(2)自社開発AIアクセラレータ
アマゾンは、AIモデルの学習と推論を効率的に省電力で処理できるAIアクセラレータチップおよびその周辺システムを自社で開発しています。このAIアクセラレータチップが、深層学習の学習用に特化して設計された「AWS Trainium」と深層学習と生成AIの推論用に特化して開発された「AWS Inferentia」の2つです。これら2つのチップは、自社ビジネスのシステム基盤に組み込まれている他、AWSのコンピューティングインスタンスとしてサービスプロダクト化されて、企業顧客も利用できるようになっています。
また、アマゾンはAIタスク向けのアクセラレータチップ以外にも、ARMアーキテクチャを採用したCPU「AWS Graviton」を自社開発しています。

(出典:AWS re:Invent 2023)
尚、これら「AWS Trainium」と「AWS Inferentia」の概要については、以前投稿した以下の当方記事でご参照いただけます。
(3)Amazon Titan
「Amazon Titan」は、アマゾンが自社開発している生成AIの基盤モデル(Foundation Model)の総称です。OpenAI社のGPTモデルやGoogleのGemini、MetaのLlama 3などのメジャーな基盤モデルと比較すると、比較的地味な存在となっているのがこのAmazon Titanです。Titanは、複数のモデル群によって構成されており、「Titan Text」、「Titan Text Embeddings」、「Titan Multimodal Embeddings」、「Titan Image Generator」といった各々が異なるキャラクターを持つモデルが存在しています。
アマゾンは、これらのモデルを自社のサービス基盤で利用する他、後述するAWSの生成AI系サービスを通じて企業顧客がこれら基盤モデルを利用できる環境をサービス提供しています。

テキスト生成やテキストから画像生成するモデルなどを提供 (出典:AWS)
2. AWSの位置づけ
アマゾンが急速に強化を進めているAWSの生成AI関連サービスについて話をする前にまず、アマゾンのビジネスモデル、特にAWSのビジネスモデルについて簡単に振り返りたいと思います。
というのも、生成AIが盛り上がる中、実際に売上が増大している企業や将来期待から株価が上昇している企業が生まれている一方で、とっかかりのマネタイズモデルも不在のまま、技術の開発競争のみが激しく繰り広げられている状況も見え隠れしています。
個人投資家としては、成長戦略として技術開発に投資することは歓迎すべきことですが、その投資成果をどのように将来ビジネスで活用して事業を伸ばしていくかは、高い関心事の一つになります。そのため、アマゾンが生成AIでどのように収益を上げるのかイメージするには、彼らのビジネスモデルを振り返るのが良いと思います。
(1)収益構造上のAWSの存在
【図表1】に示すアマゾンの2023年12月度の通期の収支構造を示すダイアグラムから、アマゾンの全体ビジネスにおけるAWSの位置付けについて振り返ってみます。図の左下を見ると、AWSという文字と908億ドルという数字が見えると思います。この908億ドルというのが昨年度のアマゾンの全体の売上5,749億ドルに占めるAWSの売上金額となります。すなわち、全体の売上に対して15.8%がAWSの売上計上額ということです。

次に注目すべきは【図表2】です。
これは、過去3年間の営業利益をセグメント別に抽出したものです。アマゾンの財務諸表に示される事業セグメントは、北米ビジネス、インターナショナルビジネス、そしてAWSの3つです。黒いバーで示されるのがAWSによって生み出された営業利益で、過去3年間のデータが示されています。具体的には、2021年度では営業利益の74%をAWSが占め、2022年度は他の2つの事業の営業赤字をカバーしながら185%の利益貢献を達成。そして2023年度は369億ドルの営業利益のうち246億ドル、すなわち67%をAWSが叩き出すという結果になっています。これらの数字から、AWSがアマゾンのビジネスにおいてどれほど中心的な存在であり、戦略的な役割を担っているかが明らかになるかと思います。
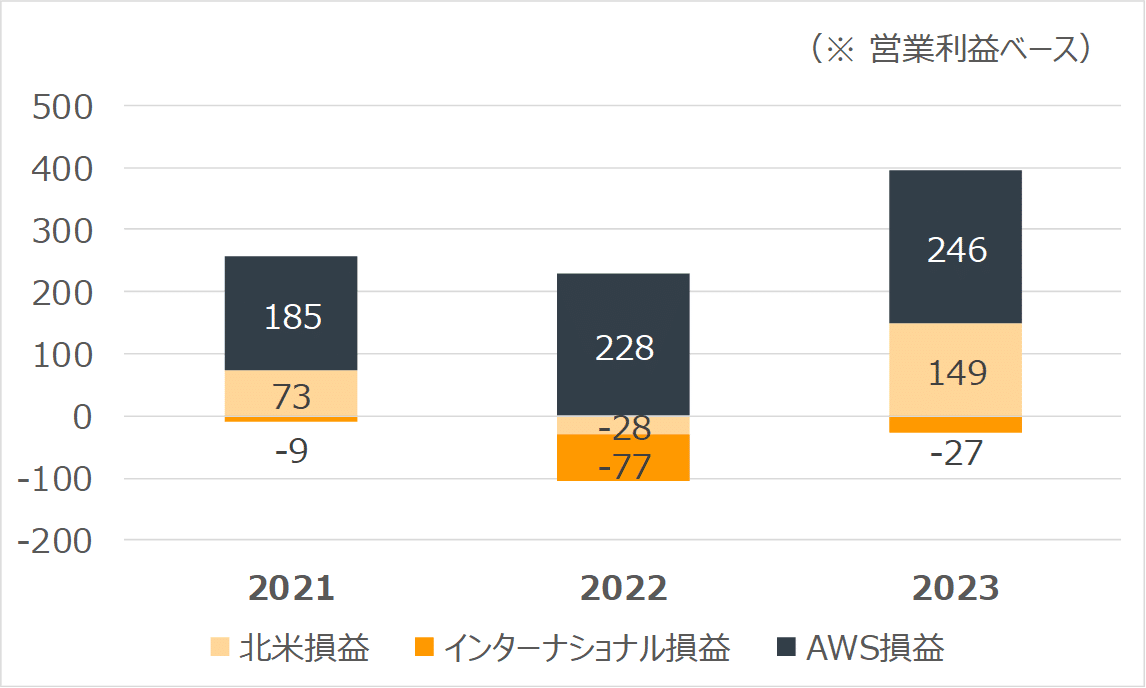
(単位:億ドル)(クリックして拡大)
(2)アマゾンの重要な評価指標
アマゾンといえば、かつて2017年くらいまでは、成長投資を優先して利益を出さない企業として有名でした。故にPER:株価収益率も100を超えるようなことは日常茶飯事でした。しかしながら最近は、直近のPERが52、フォワードPERが32と大分落ち着いてきています。
そして、昨今のアマゾンの重要な評価指標となっているのがキャッシュフローです。直近の2024年度第1四半期決算では、純利益が104億ドルであった一方で、営業キャッシュフローは、前年同期比82%増の991億ドルと爆発的な伸びを示しています。そして、設備投資後のフリーキャッシュフローは、昨年度第1四半期のマイナスから直近12ヶ月で約500億ドルと、急速かつ大幅に改善されており、ビジネス全体として非常に優秀な状況にあると考えられます。【図表3】

(出典:2024年度Q1 決算発表時配布スライドより抜粋)
(3)生成AIのマネタイズモデル
AWSは、政府公共機関や企業を顧客に持ち、それら顧客のシステムやアプリケーションを支える裏方となる様々なITサービスをクラウドモデルで提供するテクノロジー企業です。
その高度な技術力によってクラウドコンピューティング市場という新たな市場を開拓して来たAWSは、企業が求めるサービスを単に提供だけはでなく、従来には存在しなかった需要を自らが創出して長年にわたって市場に普及させてきました。既に巨大な組織ですが、オープンソースコミュニティやスタートアップとも積極的に協力し、機動的かつ次々に新たなサービスを創出して、顧客が利用しやすいクラウド環境の実現と発展に大きく貢献している企業といえます。
そして、AWSのビジネスモデルは、顧客が利用するクラウドサービスの従量課金制となります。それは例えば、使用したCPUの時間あたりの課金であったり、場所Aから場所Bに動かしたデータ量に基づく課金だったりしますが、このモデルでは、企業が初期投資を抑えることができ、必要に応じてリソースをスケールアップまたはダウンできることから、ビジネスの成長や需要の変動に柔軟に対応が可能なサービスの仕組みとなっています。尚、AWSのクラウドサービスは、コンピューティングやストレージ、データ分析やIoT、セキュリティやアプリケーションサービスまで、200を超える個別のサービスから構成されており、顧客企業は、これらのサービスを組み合わせて、自社のシステム基盤やアプリケーションを構築・運用することになります。
3. 生成AI市場におけるAWSの戦い方
(1)AIエコシステムの傾向
AWSの提供するAI・機械学習に関するクラウドサービスの数は、ゆうに数十サービスを越えて多岐に及び、様々な顧客ニーズに応えるための幅広いサービスを提供しています。これには、GPUインスタンスのサービスから始まり、APIを通じて簡単に利用できるRekognitionやComprehendのようなAIがプリビルドされたSaaS型サービスも含まれます。
そして、ここにきて注力するのが、生成AIの基盤モデル(Foundation Model)を中心としたサービスエコシステムの強化策です。
「Amazon Sagemaker」という従来より提供されるAI・機械学習向けのサービスを基幹的位置づけに据えて、生成AIモデルに特化したサービスである「Amazon Bedrock」を正式リリースし、さらに今年の4月末に生成AIのアシスタントサービスとなる「Amazon Q」を正式リリース。この様に企業が生成AIモデルを活用可能な環境づくりを強力に推進しています。
(2)アマゾンの重要投資領域
アマゾンのアンディ・ジャシーCEOに対し、2024年4月に米CNBCが行ったインタビューで、同CEOから、3つの重要なAI投資領域の言及がありました。この3つの領域は、“モデルを訓練し推論を行うためのチップ“、“第三者が開発したモデルを活用して自身のデータでカスタマイズするためのサービス“、そして、“自社もしくは第三者が開発するアプリケーション“です。また加えて、これまでの生成AI市場を観察し、顧客が用途やユースケース、サイズや遅延許容度などによってモデルの選択肢を求めていることが見えてきたとも述べており、企業に複数の基盤モデルの選択肢を提供することが重要であると言及しています。
これらに対して、具体的なアマゾンの取組みは何でしょうか。
最初に言及された“チップ“については、前述のAIアクセラレータチップの投資を指すことは明らかです。
その他の言及についてはどうでしょうか。
残りの言及内容に応えるサービスと言えるのが、AWSが生成AIフルスタックサービス化の中で生まれた「Amazon Sagemaker Jumpstart」と「Amazon Bedrock」、そして、「Amazon Q」という3つのサービスとなります。
(3)生成AI:推しのサービス
アンディ・ジャシーCEOが言及していたAI投資領域である以下の2つに呼応する3つのサービスを紹介します。
・第三者が開発したモデルを自身のデータでカスタマイズできるサービス
・自社もしくは第三者が開発するアプリケーション
① Amazon SageMaker
Amazon SageMaker Jumpstartは、生成AIモデルに限定されない機械学習のモデル開発と運用に幅広くフォーカスする、より柔軟で拡張性の高いAmazon SageMakerの機能として提供されています。このサービスは、技術的スキルが高く、自社の生成AI環境をフレキシブルに構成したい企業に適しています。

② Amazon Bedrock
Amazon Bedrockは、生成AIの開発に特化したプラットフォームです。このプラットフォームは、生成AI系の異なる複数の基盤モデルや言語モデル、拡散モデルを提供し、セキュリティやプライバシーを強化するとともに、企業のデータやデータパイプラインの構築を支援します。また、エンタープライズ品質の企業独自の生成AIアプリケーションを開発・構築するために必要な幅広い機能を提供しています。

尚、Amazon SageMaker Jumpstartでは、AI21 Labs、Cohere、Meta Llama 3、StableDiffusion、HuggingFaceなどの基盤モデルを利用可能。Amazon Bedrockでは、Titan、AI21 Labs、Anthropic、Cohere、Meta Llama 3、Stability AIなどの基盤モデルが利用可能です。(2024年5月現在)

③ Amazon Q
Amazon Qは、生成AIを活用した企業向けAIアシスタントサービスとして、生成AIアプリケーションをより身近に実現可能とする画期的なコンセプトを持つサービスです。Amazon Qには、目的別に複数サービスが用意されており、コーディング不要でクリック&セレクトの操作だけで、ビジネスユーザーでさえ、自社にカスタマイズされた生成AIアシスタントをつくることのできる環境を提供しています。尚、実現できるアプリケーションのスコープは限定されると言えますが、社内の企業システムとセキュアにデータ連携して業務支援する生成AIアシスタントを難しいコーディングや設定なしに実現できるサービスとしては、非常に貴重なサービスとなっています。
尚、企業向けAIアシスタントサービスというと、Microsoft Copilotがありますが、Copilotのそれは、WordやExcelなどの含まれるMicrosoft 365に付随して日常のオフィスワークを支援するサービスの位置付けで、Amazon Qとは、テキスト生成、翻訳、Q&A検索、コンテンツ要約、画像生成などのコンテンツ生成機能で被る領域もありますが、だいぶ毛色が異なるサービスになっています。

第三者が開発したモデルを利用し、自社データを活用する生成AIアプリケーションを開発するのは、前述のAmazon SageMaker JumpstartでもAmazon Bedrockでもできるのですが、これら2つのプラットフォームは、中級以上のスキルを持ったエンジニアやデータサイエンティスト向けのプラットフォームになります。
社内向けの生成AIアプリケーションをビジネスユーザーでも作れるAmazon Qの少し踏み込んだ説明と、何がどう簡単になっているかについての説明は、次の章で紹介したいと思います。
4. Amazon Qの概要
Amazon Qは、原則有償サービスとして提供されます。機能と課金プランの違いによって、大きく「Amazon Q Business」と「Amazon Q Developer」の2つのプランがあります。
(1)Amazon Q Business
Amazon Q Businessは、ビジネスユーザー向けのプランで、ChatGPTと同様のチャットイメージで利用できる生成AIアシスタントサービスです。サービスの特徴は、社内のデータを簡単に活用して社内業務に合わせてカスタマイズできる点にあります。コーディングが不要なため、プログラミング経験のないビジネスユーザーでもクリック&セレクトの操作だけで簡単にカスタマイズされた生成AIアシスタントを作ることができます。
社内の企業システムのデータとの連携は、あらかじめ提供されるコネクタを使って自動同期することができ、最新のデータを反映しながら、質問応答形式でAmazon Qのアドバイスを受けて業務上の意思決定やアクションを迅速化することができます。(勿論、社内データへのアクセス権が必要)
以下は、Amazon Q Businessが提供する主な機能です。

(2)Amazon Q Developer
Amazon Q Developerは、Amazon Q Businessの全ての機能に加え、AWS上でのシステム開発やソフトウェア開発を支援するIT部門やエンジニア向けのナレッジサービスが追加提供されています。
このサービスには、AWSの17年以上に渡るAWSのサービス提供経験に基づいた豊富なナレッジを学習したエキスパートモデルが搭載されており、システム構築やソフトウェア開発に関するコーディングやシステムテスト、セキュリティスキャンやAWSリソースの最適化、システム設計のベストプラクティスやトラブル発生時の原因分析や対処法など、生成AIアシスタントとしてエンジニアの多様な課題に対応します。
以下は、Amazon Q Developerが含む主な機能です(抜粋)。

(3)その他ユースケース向け
Amazon Q BusinessやAmazon Q Developerとは異なり、AWSが別途提供するサービスにバンドルされて提供されるAmazon Qのラインナップがあります。
① Amazon Q in Amazon Connect
Amazon Q in Amazon Connect は、AWSのコンタクトセンター向けサービス「Amazon Connect」に組み込まれたAmazon Qで、コンタクトセンターのエージェントが顧客との通話中もしくはチャット中に、Amazon Qに顧客対応のための情報や推奨アクションの要求の自動化が可能となります。
② Amazon Q in Supply Chain
Amazon Q in Supply Chainは、AWSのサプライチェーンマネジメントソリューションである「AWS Supply Chain」に組み込まれたAmazon Qで、サプライチェーン上の情報を参照し、在庫管理者や取引企業の在庫切れや過剰在庫のリスクについての問い合わせに対応したり、発生した課題解決のためのアクションを推奨する等の機能を提供します。
5. Amazon Qが簡単にしたこと
(1)Amazon Qが振り切ったこと
自社データを活用して生成AIアプリケーションを容易に開発できる環境をAmazon Qは提供していますが、そこには「割り切り」というものが存在しており、従来の丁寧なやり方では、自動化しないであろうプロセスをブラックボックス化しているような傾向があり、これによって良し悪しは発生しますので留意は必要です。アマゾンとしては、「Amazon Qの仕組みで思ったようなことができないようであれば、Amazon SageMaker JumpstartかAmazon Bedrockを使ってくださいね」ということかと思います。
(2)生成AIモデルの選択肢
OpenAIのGPTモデル、GoogleのGemini、MetaのLlama 3など、膨大なデータと莫大なコンピューティングリソースを必要とする基盤モデルを、一般の企業が自社で開発するのは困難であり、現実的な手段ではないと言われています。そうなると、企業の選択肢としては、第三者の開発したモデルを自社用に動かして利用するのか、または、ChatGPTやマイクロソフトのCopilotのような第三者が提供する生成AIサービスを利用するのか、大雑把にはこれらのどちらかになります。(注:その他、様々に異なる細かいバリエーションも存在しますが・・・)
前述の通り、AWSが提供するAmazon SageMaker JumpstartやAmazon Bedrockは前者の第三者の開発したモデルを自社用に動かして利用する、ということになります。
では、Amazon Qはどちらかというと、「生成AIサービス」に近いイメージです。まず、Amazon Qには、基盤モデルの選択肢はなく、AWSが提供するモデルの択一となります(モデルは非公開ですが、Titanが利用されている可能性が高い)。そしてAmazon Qでは、モデルそのものを直接ファインチューニングすることもできません。よって、決められたモデルのサービスを利用するモデルといえますが、ChatGPTやCopilotと毛色の違う点は、自社データで生成AIアシスタントの知識ベースを簡単に拡張できる点にあります。
(3)企業システムのデータ取り込み
Amazon Qでは、あらかじめ提供されるコネクタを使って、社内システムのデータと自動同期することができるため、、最新のデータを反映しながら、Amazon Qのアドバイスを受けることができます。40を超えるコネクタが提供されており、簡単な設定でデータソースに接続することが可能です。 以下があらかじめ用意されているコネクタの対象システムのリストです。
尚、これらコネクタを利用してのデータソース連携については、AWSマネジメントコンソールからの設定やData Source APIなどの設定が必要となるため、IT部門の支援が一般的に必要になると思われます。

(4)自社データの生成AI活用
コネクタを介して取り込まれたデータは、Amazon Q Indexによってインデックス化され、組み込みモデルによってナレッジベースに取り込まれ、ユーザーの問い合わせを受けた際に生成AIモデルの知識を拡張する拡張検索生成(RAG:Retrieval Augmented Generation)相当の仕組みを提供しています。
検索拡張生成(RAG)とは、ユーザーの質問や要請に対する応える回答を生成するために大規模なデータセットから関連情報を動的に検索した結果を利用して、《生成AIモデルそのものに手を加えずにモデルを賢くし》コンテンツを生成するAI手法です。既存情報から検索した情報と生成AIのコンテンツ生成の技術を組み合わせることで、生成AIモデルの推論のみに頼るのではなく、事実情報を組み合わせて、より精度の高いコンテンツ生成と質問応答を可能とする仕組みです。
拡張検索生成(RAG)の一般的な仕組みは、下図にあるようにナレッジベース構築のための前準備の部分(下段)と実際の質問と回答を行う際にリアルタイムで処理される様々なプロセス(上・中段)が連動して行われることになりますが、Amazon Qでは、これらの多くの処理を自動化し、開発者やユーザーから隠蔽し、内部の複雑なメカニズムを理解することなく、自社のデータを有効活用できる拡張検索生成を劇的かつお手軽にできてしまうという、言ってみれば、かなり振り切ったサービスソリューションに仕立てています。
尚、隠蔽されている内部処理についても幾分カスタマイズができる模様で、インデックス作成時にAWS Lamdaの関数でデータのエンリッチメントなどの前処理を行えますが、フレキシブルになんでもカスタマイズできるというようなものではありません。

(クリックして拡大)
この様に、お手軽に生成AIアシスタントを作れるAmazon Qですが、ぱっと思いつく懸念点として幾つかあります。まず多言語対応でしょうか。特に日本語は様々な面でハードルが高いため、多言語対応でどう精度を上げられるかは、大いに懸念されるところです。利用されるモデルの日本語対応やナレッジベースのベクトル処理など、企業ユースを想定したものですので、ハルシネーションやバイアスなどの懸念もあり、日本語への適用については、しばらくは様子見というところでしょうか。
また、セキュアな仮想プライベートクラウドという環境で、この検索拡張生成(RAG)を実現する際の他社の提案としては、マイクロソフトからはAzure AI Studio、GoogleからはVertex AIの選択肢が提供されていますが、これらはAWSでいうところのAmazon SageMaker Jumpstart(または、Amazon Bedrock)と同等の中級以上のエンジニアリングスキルが必要なソリューションになり、現状においてAmazon Qに匹敵するようなソリューションは提供されていません。
6. 足元のデータにお宝が潜んでいる
企業にとっていかに生成AIを活用するかは重要な関心事です。特に競合他社を意識しつつ、生成AIのようなテクノロジーを使ってどう差別化を図るかは競争戦略上の大きな課題となります。
しかしながら、誰もが利用可能な生成AIサービスを使っても、もしくは、誰もがアクセス可能なデータで学習したオープンソースモデルで他社と競争しても、それだけで優位に立つことは困難かもしれません。
ご承知の通り、生成AIのポテンシャルに大きな影響を及ぼすのが学習するデータです。であれば、自社にしかない独自のデータを使ってモデルを強化し続ければ、他社に対する競争力の源泉となるその企業の秘伝のタレを持つ生成AIモデルを生み出せる可能性があります。
企業は歴史的に様々なデータを自社ビジネスに活用してきました。販売データや顧客データ、財務データ他、様々なデータで様々な意思決定を日々行っています。しかしながら、これらの意思決定を促すデータの殆どが“構造化されたデータ“で、企業内データの80%以上を占めるといわれる”非構造化データ“の活用については、実は相当に遅れているのが現状です。
そしてこの非構造化データのAI処理を得意とするのが生成AIの基盤モデルです。そして企業には、企業の外には出せないデータも膨大に存在しています。顧客データや取引データ、また、営業秘密や個人情報を含んだコミュニケーションデータなど、ChatGPTに問い合わせるには不適切な情報が企業内には沢山存在します。
これら自社独自のデータ、そして、外部に開示できないデータについては、自社の管理の及ぶセキュアな環境で独自にモデルに学習させる必要があります。実際にそのようなプロジェクトは既に数多く存在しており、例えば初期の事例としては、過去40年に渡る自社のデータを学習させた米ブルームバーグ社の金融業界向けの「Bloomberg GPT」などは、自社データを使った差別化戦略の1つのロールモデルであると言えます。
尚、データを使ったモデルが持つ知識を強化する一般的な手法としては、プロンプトを工夫する”プロンプトエンジニアリング”、モデル自体を新たなデータでトレーニングする“ファインチューニング”、そして、 “モデル自身には手を加えず、外部の知識ベースを利用してモデルの知識を拡張する前述した”検索拡張生成(RAG)”です。
プロンプトエンジニアリングについては、既に誰もが気軽に行っている状況かと思いますが、ファインチューニングに至っては、データ、知識、技術力、時間、労力、コストが必要で、相応の投資が必要となる手法です。そして、Amazon Qによって、ぐっと身近な存在になったのが検索拡張生成(RAG)です。
このように徐々に企業が自社のデータを生成AIで活用するための環境を構築するハードルが徐々に下がってきているのですが、これもそれも、AWSの生成AI戦略シナリオの一環です。
AWSは、顧客のシステムを支えるクラウドサービスで収益を上げています。つまり、AIや生成AIを使って自社データを活用したいと考える顧客をAWSに取り込み定着させる手立てを考えています。
そこで、取っ掛かりとなる企業の参入障壁をなくすために、ここ1年間をかけて整備してきたのが、AI・機械学習のためのフルスタックサービスとなるAmazon Sagemaker、生成AIのカスタマイズモデル向けのAmazon Bedrock、そしてお手軽に外部データベースで生成AIモデルの知識を拡張するAmazon Qという3つによる品揃えです。
これらは、今後の顧客企業の競争戦略を見据え、興隆の期待できる企業需要を取り込むための打ち手となります。特に、Amazon Qは、企業データを活用し、簡単に生成AIアプリケーションを開発できるというAWSの新たな提案ですが、これによって生成AIでの企業データの活用促進がどう進展して行くかは、生成AI市場、特に生成AI市場のB2Bセグメントでの重要な焦点になる可能性があるのでこれからも注目していきたいと思います。
以上です。
御礼
最後までお読み頂きまして誠に有難うございます。
役に立ちましたら、スキ、フォロー頂けると大変喜び、モチベーションにもつながりますので、是非よろしくお願いいたします。
だうじょん
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。