
京都のホテル販売価格の予測モデルをExploratoryで試作してみた

先日、WEBスクレイピングでBooking.comから京都のホテルの販売価格データを取得する方法について書きました。
Octoparseを使って3ヶ月先までの京都のホテル販売価格を調査してみた
さらに、データを分析するための便利なツールとして、Exploratoryという無料サービスがあることも紹介しました。
SQLもRもいらない?これからはExploratoryの時代。
今回は、この2つを組み合わせて、京都のホテル販売価格の予測モデルを簡単に作ってみたいと思います。
先日の記事では、4月第4週(4/21頃)時点で1週間おきの週末(4/25, 5/2, 5/9, ...)の販売価格を調べました。今回は、これを1週間ずつずらし、4月第5週以降の3ヶ月間と、5月第1週以降の3ヶ月間についても同様のデータ取得を行い、これらを1つのデータセットとして結合しました。サンプルデータはコチラからご自由にダウンロードしてください。
データの取込と整形
まずはこのファイルをExploratoryにインポートします。画面左側の「データフレーム」をクリックし、「ファイルデータ」「ローカル」「エクセルファイル」と選択していくと、インポートすることができます。なお、インポートする時点で不要と思われる列はチェックを外しておくことで省くことができるので、URLデータなどは省いておきましょう。

この取り込み作業をRのスクリプトで出力するには、画面右側に出てくるステップの右肩にあるハンバーガーメニュー(3本の横棒)から「Rスクリプトを作成」を選択します。

すると、作業対象となるファイルの置き場所の指定や、分析に必要となるライブラリのインストールを行うための文章が記述された後、最後に該当する文章が以下のとおり出てきます。(1行目は横に長いのでスクロールしてください)
exploratory::select_columns(exploratory::clean_data_frame(exploratory::read_excel_file( "../committed_data/booking_stat.xlsm", sheet = "data", na = c('','NA'), skip=0, col_names=TRUE, trim_ws=TRUE, tzone='Asia/Tokyo')),"検索日","宿泊日","名前","builink","場所","点数","クチコミ","room_link","cbedsconfiguration","価格2","価格3","内容") %>%
readr::type_convert()
データがインポートされると列ごとのデータ型が自動的に判定されますが、大抵の場合修正が必要です。今回の場合、データの検索日と宿泊日のデータ型が「POSIXct」という秒単位の時系列データとして認識されますが、日単位で十分なので、DATE型に変換します。

ちなみに、これをRスクリプト化すると、こうなります。
mutate(検索日 = as_date(検索日), 宿泊日 = as_date(宿泊日))その他、以下のような処理を行って、データを整形していきます。
①食事付きのプランを排除
②エリアデータをカンマで区切って、行政区のみを抽出
③ベッド数データから、ベッド数のみを抽出
④中心部からの距離から距離の数値のみを抽出し、kmをmに換算
⑤必要な列のみに絞り込む
ここまでの処理のスクリプトは、画面右側に表示されるステップのうち、一番最後のステップのメニューからスクリプト化することで、下記のように取得することができます。
exploratory::select_columns(exploratory::clean_data_frame(exploratory::read_excel_file( "../committed_data/booking_stat.xlsm", sheet = "data", na = c('','NA'), skip=0, col_names=TRUE, trim_ws=TRUE, tzone='Asia/Tokyo')),"検索日","宿泊日","名前","builink","場所","点数","クチコミ","room_link","cbedsconfiguration","価格2","価格3","内容") %>%
readr::type_convert() %>%
mutate(検索日 = as_date(検索日), 宿泊日 = as_date(宿泊日)) %>%
separate(builink, into = c("area", "builink"), sep = "\\s*\\,\\s*", convert = TRUE) %>%
separate(場所, into = c("場所_1", "場所_2"), sep = "中心部から", convert = TRUE) %>%
select(cbedsconfiguration, 検索日, 宿泊日, 名前, area, 場所_2, 点数, クチコミ, room_link, 価格2, 価格3, 内容) %>%
separate(cbedsconfiguration, into = c("cbedsconfiguration_1", "cbedsconfiguration_2"), sep = "ベッド", convert = TRUE) %>%
separate(cbedsconfiguration_2, into = c("cbedsconfiguration_2_1", "cbedsconfiguration_2_2"), sep = "台", convert = TRUE) %>%
filter(内容 %nin% c("1泊2食付き", "ディナー込", "朝食込")) %>%
select(cbedsconfiguration_2_1, 検索日, 宿泊日, 名前, area, 場所_2, 点数, クチコミ, room_link, 価格2, 価格3, 内容) %>%
reorder_cols(検索日, 宿泊日, 名前, area, 場所_2, 点数, クチコミ, 価格2, 価格3, cbedsconfiguration_2_1, room_link, 内容) %>%
mutate(area = recode(area, `下京区` = "下京区", `南区` = "南区", `中京区` = "中京区", `東山区` = "東山区", `嵐山・高雄` = "右京区", `河原町・烏丸・大宮` = "中京区", `上京区` = "上京区", `京都駅周辺` = "南区", `伏見区` = "伏見区", `左京区` = "左京区", `北区` = "北区", `山科区` = "山科区", `西京区` = "西京区", `京都市中心部` = "中京区", `西陣` = "上京区", `京都市
地図に表示` = "不明", `三条` = "中京区", `京都市東山区
地図に表示` = "東山区")) %>%
filter(cbedsconfiguration_2_1 %in% c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")) %>%
mutate(cbedsconfiguration_2_1 = parse_number(cbedsconfiguration_2_1)) %>%
rename(`ベッド数` = cbedsconfiguration_2_1) %>%
rename(`中心市街地からの距離` = 場所_2) %>%
mutate(中心市街地からの距離 = parse_number(中心市街地からの距離), `中心市街地からの距離_replaced` = case_when(
中心市街地からの距離 < 10 ~ 1000*中心市街地からの距離,
TRUE ~ 中心市街地からの距離)) %>%
reorder_cols(検索日, 宿泊日, 名前, area, 中心市街地からの距離, 中心市街地からの距離_replaced, 点数, クチコミ, 価格2, 価格3, ベッド数, room_link, 内容)データの分析
できあがったデータを集計して、概要を把握してみましょう。画面上部のメニュータブから「チャート」を選択し、左側メニューのタイプで「ピボットテーブル」を選択します。あとは、Excelのピボットテーブルと同様、集計したい項目を「列」「行」「値」欄にそれぞれはめ込んでいくだけです。細かい設定は、いろいろ試してみれば分かると思うので、説明は省略します。

検索を行ったタイミングと、宿泊予定日ごとでの販売価格の平均値を集計してみると、先日の記事でもお伝えしたとおり、夏場になるほど価格が上昇していることがわかります。一方、検索日と宿泊日が近づくと、販売価格はやや下がる傾向にあるように見えます。
Exploratoryでは、こうした数値間の関係性を、他の要素も加えて複雑に分析することができます。画面上部メニュータブから「アナリティクス」を選択し、行いたい分析の種類を選びます。今回は、販売価格の予測モデルを作りたいので、「一般化線形モデル」のうち「ガンマ分布」を選びます。ガンマ分布は、予測する対象が連続性のある正の数である場合によく用いられる確率分布で、所得データなどにもよく利用されることから採用しています。(なお、歯車マークからリンク関数を「逆数」「恒等」「対数」のなかから選ぶことになりますが、ここでは対数を選んでいます)

つぎに、モデルに組み込む変数をしていきましょう。目的変数は販売価格(このデータ上では価格2というカラム)を指定し、予測変数(いわゆる説明変数)は下記のように関係しそうなデータを指定していきます。

予測結果は以下のとおりです。iframeでも出力できるのですが、noteとは相性が良くないみたいなので、画像の下にURLリンクを載せておきます。

左側の青い項目が販売価格に対して正の関係を持っていることを表します。逆に、右側の赤い項目は負の関係を持っています。点の上下に伸びている線は誤差の範囲を表しています。誤差が0をまたいでしまっている項目は、正の関係を持っているのか負の関係を持っているのか判断できない、つまり統計的には有意ではない項目ということになります。
ちなみに、これらのデータは標準化という処理を行っていませんので、点が上にあるほど寄与度が大きいというわけではないのでご注意ください。たとえば、クチコミの係数はほぼ0なのであまり価格に対する影響が無いように見えますが、クチコミ件数は施設によって数千件に昇るので、これをモデルへ反映すると予測金額は大きく上昇することになります。逆に、一番左の点数の係数は大きくなっていますが、点数は0.0~10.0点までしか動かないので、モデルへ反映しても予測金額への影響は少ない場合があります。
こうなってくると、各パラメータが変わったときに、販売価格の予測結果にどれくらい影響があるかを知りたくなると思います。そこで、画面上部のメニュータブから「予測影響度」を選んでみましょう。すると、以下のように、各パラメータが変化したときに算出される販売価格が可視化されます。
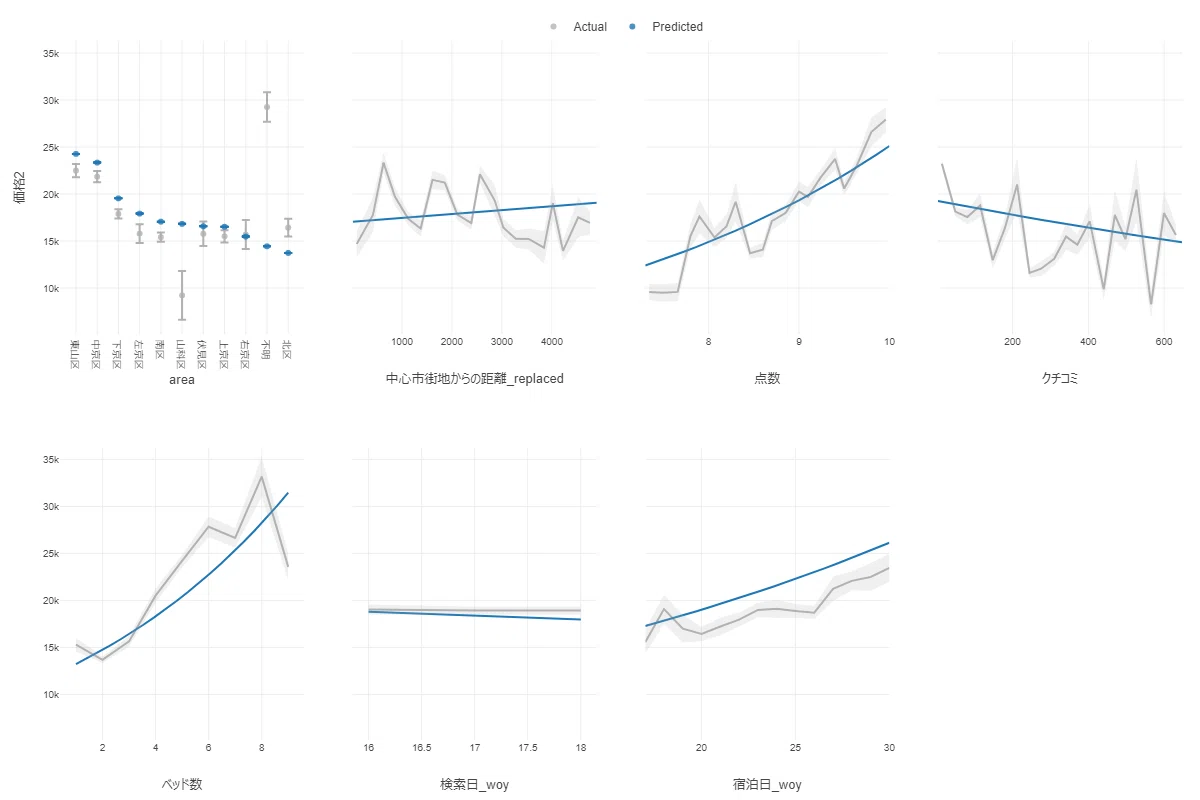
たとえば、宿泊施設のエリアでは、東山区だと平均25,000円弱のところ、北区では平均14,000円弱となります。施設の評価点数は、8.0点程度の場合は15,000円、10.0点の場合は25,000円となります。
意外にも、クチコミは多いほうが価格が低くなるようです。検索日は、わずかではありますが最近に近づくほど安くなる傾向があるので、ピボットテーブルで集計したとおり、宿泊日が近づくにつれて価格は安くなるようです。そして宿泊日は、やはり先になるほど販売価格を上げる関係にあるようです。
3ヶ月先までの情報を3回取得しただけのデータなので、モデルの精度はかなり低いですが、こうした情報を貯めて精度を高めていくことで、パラメータを指定して妥当な販売価格を予測することが可能になります。
また、データが溜まってきたら、続報をお伝えできればと思います。
続きに興味を持っていただけましたら、サポートをお願いします。一定の金額が貯まったら、独自の調査活動資金に充てたいと考えています。