
Pythonライブラリ(Webアプリ):gradio

1.概要
PythonのWebアプリ向けライブラリはFlask、Django、Streamlitなどがありますが、今回は機械学習向けWebアプリのgradioを紹介します。
なお個人的にはStreamlit推しでありこちらでも簡単に実装できると思いますので、状況に応じて使いやすい方を選択したらよいと思います。
1-1.gradioの強み(ポイント)
gradioの強みは下記です。特に1.はgradioが”機械学習に特化”と言われる所以になります。
機械学習に必要な最低限の項目※のみでwebアプリを作成できる(※関数、入力値、出力値の3つ)
Jupyter NotebookやGoogle Colab上でも動作する
作成したアプリを外部(同僚やチームメンバー)とシェアできる
Hugging Face Spacesを使用すれば、全世界へ公開できる
1-2.gradioの構成
gradioは最小限単位として入力値(Input)、出力値(Output)、関数(Function)があればWebアプリを動作させることが出来ます。
それらの間でgradioが自動で前処理(preprocessing steps)・後処理(postprocessing steps)を実施してくれます。
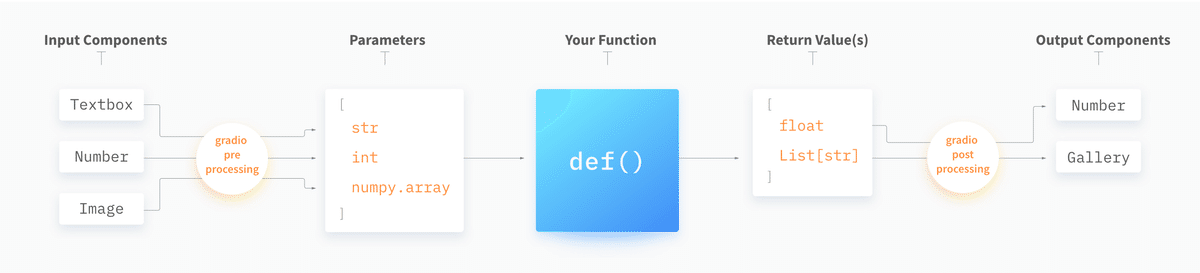
コンポーネント一覧及び実行できるイベント(処理内容)は下表の通りです。

1-3.公式Docsのガイド
公式ガイドよりどのような内容が学べるかがある程度理解できます。

1-4.環境構築:ライブラリのインストール
環境構築はgradioを下記でインストールするだけです。
[Terminal]
pip install gradio2.gradioの簡易実装(基礎編)
まずは公式DocsのQuickstartを参照に簡単な例を実施して理解を深めます。なお便利なのでJupyterを使用して実施してきます。
gradioでのWebアプリ作成の大きな流れは下記の通りです。
処理したい内容を考える
入出力に合わせて処理する関数を定義・実装する
gradio.Interface()でWebアプリを構成※
launch()メソッドでWebアプリを立ち上げる
※gradioでアプリを構成するには「gradio.Interface」と「gradio.Blocks」の2つがありますがレイアウトにこだわならければ”Interface()”のみで充分です。
2-1.入出力が1つ
本項では「入力したテキスト(入力値)の前後に文字を加えて(関数)文字列を出力(出力値)するWebアプリ」を作成します。実装は以下の通りであり下記が確認できました。
gradio.Interface()に関数、入力値、出力値を指定するだけでWebアプリが作成できた(入力・出力用のボックスも自動作成)。
入力値に合わせてgradioがバックエンドで関数処理して出力を出してくれている。
作成されたWebアプリはブラウザ上(http://localhost:7860/)でもJupyter Notebook上でも実行可能です。(※記載はしておりませんが連続で別アプリを作成するとURLのポート番号は自動で連番のものが作成されます)
[IN]
import gradio as gr
#Webアプリ内で実行する関数を定義
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, #Webアプリ内で実行する関数
inputs="text", #関数への入力値
outputs="text")#関数の出力値
demo.launch()
[OUT]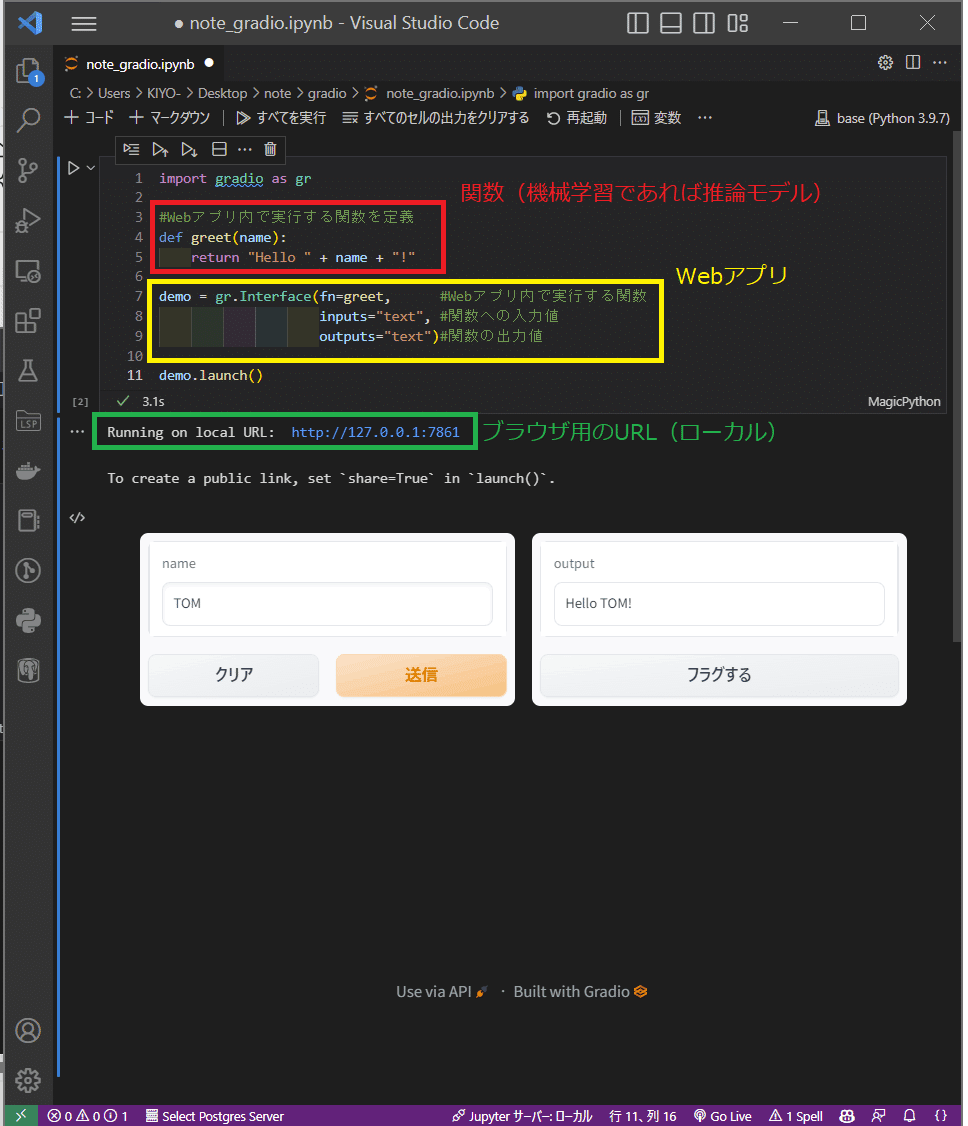

2-2.コンポーネントに画像を適用
先ほどは入出力ともにテキストでしたが、gradioのコンポーネントを使用すると様々な形に対応できます。コンポーネントの詳細は後述しますのでとりあえず入出力が画像の例を試してみました。
【画像用関数:ガウシアンノイズ】
な数はガウシアンノイズ(正規分布に従う乱数値を画像に追加)を作成しました。処理のイメージは下記の通りです。
$$
\mathcal{N}(\mu, \sigma)=\dfrac{1}{\sqrt{2\pi\sigma}}\exp(-\dfrac{(x-\mu)^ 2}{2\sigma^ 2})
$$
[IN]
from PIL import Image
import numpy as np
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols #画像の枚数がrows*colsと一致するか確認
w, h = imgs[0].size #画像のサイズを取得
grid = Image.new('RGB', size=(cols*w, rows*h)) #新しい画像を作成
grid_w, grid_h = grid.size #新しい画像のサイズを取得
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h)) #画像を貼り付ける
return grid
path_img = 'konan.jpg'
img = Image.open(path_img)
def gaussian_noise(img, mean=0, sigma=40):
img = np.array(img) #PIL形式をNumPy配列に変換
img = img + np.random.normal(mean, sigma, img.shape) #ガウシアンノイズを加える
img = np.clip(img, 0, 255) #画素値が0~255の範囲に収まるようにクリッピング
img = Image.fromarray(np.uint8(img)) #PIL形式に変換
return img
img_noise = gaussian_noise(img)
image_grid([img, img_noise], rows=1, cols=2)
[OUT]
【gradioの実装:gradio.Image】
gradioで画像コンポーネントは”gradio.Image()”を使用します。下記の通り「入力:画像->(関数処理)->出力:画像」も実装できました。
[IN]
import gradio as gr
from PIL import Image
import numpy as np
def gaussian_noise(img, mean=0, sigma=40):
img = np.array(img) #PIL形式をNumPy配列に変換
img = img + np.random.normal(mean, sigma, img.shape) #ガウシアンノイズを加える
img = np.clip(img, 0, 255) #画素値が0~255の範囲に収まるようにクリッピング
img = Image.fromarray(np.uint8(img)) #PIL形式に変換
return img
demo = gr.Interface(fn=gaussian_noise,
inputs=gr.Image(),
outputs=gr.Image())
demo.launch()
[OUT]
2-3.複数の入出力
先ほど作成したノイズ追加アプリにおいて「偏差(ノイズ)調整機能と出力の画像サイズ」を出力する機能を追加していきます。
入出力を複数にする場合は欲しいコンポーネントをリスト化して渡します。この時関数の引数およびreturnと順番を合わせておく必要があります。
[sample]
def <処理用の関数>(<Com_in1>, <Com_in2>,・・・, <Com_inN>):
<処理>
return <Com_out1>, <Com_out2>,・・・, <Com_outN>
gr.Interface(fn=<処理用の関数>,
inputs=[<Com_in1>, <Com_in2>,・・・, <Com_inN>],
outputs=[<Com_out1>, <Com_out2>,・・・, <Com_outN>])今回はtextとは異なる物として数値の入力ボックスとスライダーを追加しました。複数のコンポーネントを追加できることを確認しました。
[IN]
import gradio as gr
from PIL import Image
import numpy as np
def gaussian_noise(img, mean=0, sigma=40):
img = np.array(img) #PIL形式をNumPy配列に変換
img = img + np.random.normal(mean, sigma, img.shape) #ガウシアンノイズを加える
img = np.clip(img, 0, 255) #画素値が0~255の範囲に収まるようにクリッピング
img = Image.fromarray(np.uint8(img)) #PIL形式に変換
return img, img.size
demo = gr.Interface(fn=gaussian_noise,
inputs=[gr.Image(), "number", gr.Slider(0, 100)],
outputs=[gr.Image(), "text"])
demo.launch()
[OUT]
3.Interface:WebアプリのUI作成
3-1.Interfaceのパラメータ
Webアプリの基本画面を作成するにはgradio.Interfaceを使用します。
[gradio.Interface]
gr.Interface(fn,
inputs,
outputs,
examples,
cache_examples,
examples_per_page,
live,
interpretation,
num_shap,
title,
description,
article,
thumbnail,
theme,
css,
allow_flagging,
flagging_options,
flagging_dir,
flagging_callback,
analytics_enabled,
batch,
max_batch_size)パラメータは上記の通り複数ありますが基本的には必須項目の3つにデータを渡せば十分です。
【必須パラメータ】
●fn:Webアプリ内で実行する関数
●inputs:Webアプリ内で使用するコンポーネントを指定(e.g. "text", "image" or "audio")
●outputs:出力するコンポーネント指定(e.g. "text", "image" or "audio")
より細かい部分を調整する場合は下記パラメータ(特にexamples)は便利です。
【任意パラメータ】
●examples:Webアプリの下にデータ表を表示し、クリックすると値がアプリ側へ(インタラクティブに)入力されます。
ー>ファイル名"log.csv"としてデータをテーブル型で保存している場合、"examples=<log.csvの保存dirのpath>"でもデータを渡せます。
●title:Webアプリの上にタイトルを表示
●description:titleの下にコメントなど※表示
●article:Webアプリの左下にコメントなど※表示
(※text, markdown or HTMLなどに対応)
[IN]
import gradio as gr
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
if num2 == 0:
raise gr.Error("Cannot divide by zero!")
return num1 / num2
demo = gr.Interface(fn=calculator,
inputs=["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
outputs="number",
examples=[[1, "add", 2], [1, "subtract", 2], [1, "multiply", 2], [1, "divide", 2]],
title='title:ここにタイトルを表示',
description='descriptions:ここに説明を表示')
demo.launch()
[OUT]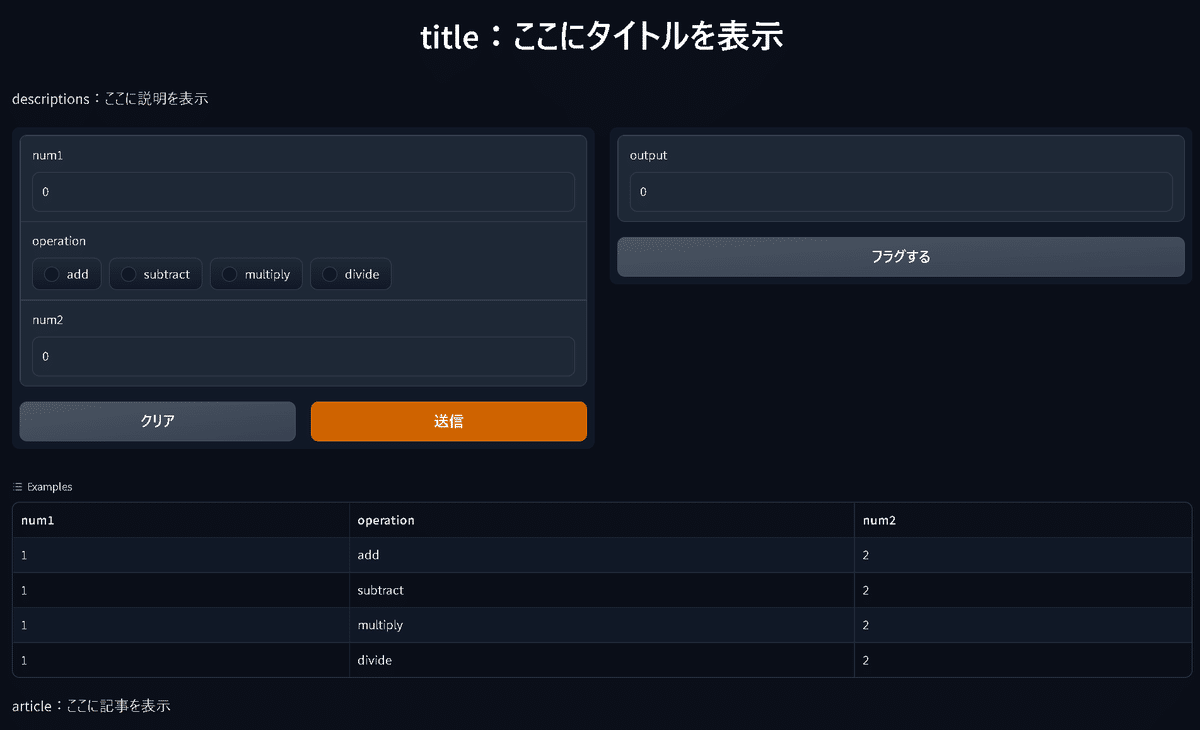
3-2.複数の入出力
入出力を複数にする場合は欲しいコンポーネントをリスト化して渡します。この時関数の引数およびreturnと順番を合わせておく必要があります。
[sample]
def <処理用の関数>(<Com_in1>, <Com_in2>,・・・, <Com_inN>):
<処理>
return <Com_out1>, <Com_out2>,・・・, <Com_outN>
gr.Interface(fn=<処理用の関数>,
inputs=[<Com_in1>, <Com_in2>,・・・, <Com_inN>],
outputs=[<Com_out1>, <Com_out2>,・・・, <Com_outN>])例として線形モデルを数式と合わせて出力するアプリを作成しました。
[IN]
import gradio as gr
def linear_regression(x, m, b):
output_num = m * x + b
output_str = f"y = {m}x + {b}"
return output_num, output_str
demo = gr.Interface(fn=linear_regression,
inputs=["number", gr.Slider(0, 10), gr.Slider(0, 10)],
outputs=["number", "text"])
demo.launch()
[OUT]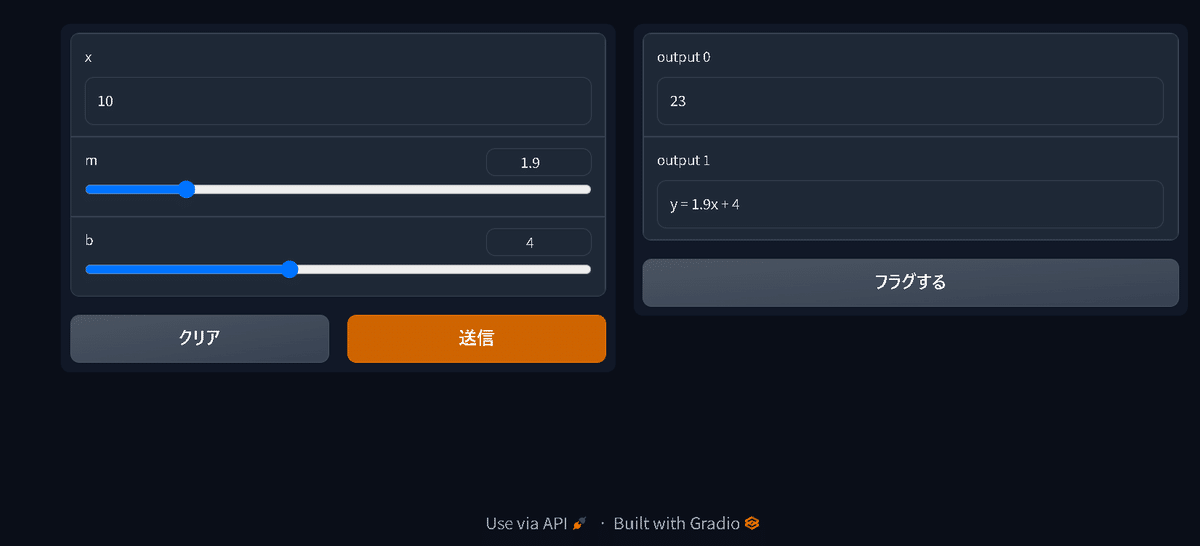
3-3.Webアプリの立ち上げ:Interface().launch()
Webアプリの立ち上げを実施するメソッドです。重要なメソッドのみ記載しておきます。
【launch()メソッドのパラメータ】
●share(default: None):TrueにするとSSHチャネルを通じて作成したWebアプリにアクセスできるようになる(puclicのリンクは72hで切れる)。
4.Components:入出力の要素作成
入出力で使用できるコンポーネントは下表の通り複数あり、それぞれで使用できるパラメータやメソッドも異なります。
使えるコンポーネントを事前に理解しておき、必要なタイミングで調べていく方が良いと思います。

適当に選択したコンポーネントを表示させてみましたのでご参考までに。
[IN]
import gradio as gr
def test(text, num, slider, checkbox, checkboxg,
radio, dropdown, image, video, audio,
file, df, timeseries, button,
Upbtn, colorp, label, hightext, json):
return "Success!"
inputs = [gr.Textbox(), gr.Number(), gr.Slider(), gr.Checkbox(), gr.CheckboxGroup(),
gr.Radio(), gr.Dropdown(), gr.Image(), gr.Video(), gr.Audio(),
gr.File(), gr.DataFrame(), gr.TimeSeries(), gr.Button(),
gr.UploadButton(), gr.ColorPicker(), gr.Label(), gr.HighlightedText(), gr.JSON()]
demo = gr.Interface(fn=test,
inputs=inputs,
outputs="text")
demo.launch()
[OUT]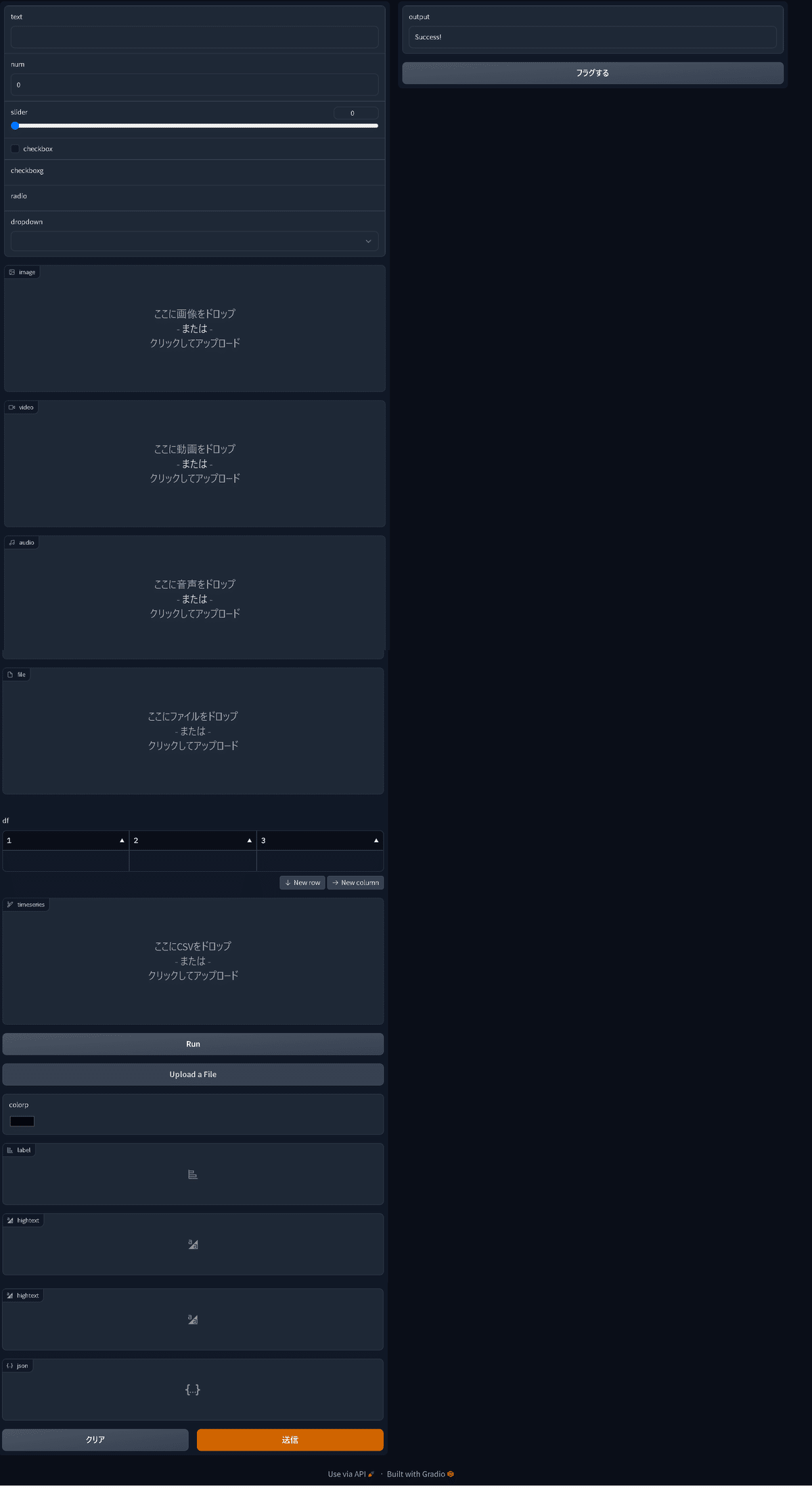
5.Blocks:より柔軟なレイアウト
”簡単にWebアプリ作成”とは離れますが、"gradio.Blocks()"を使用してレイアウトを自分の好きな形に変更も可能です。
5-1.Blocksの簡易サンプル
2-1節で紹介したアプリをBlockでレイアウトしたものを紹介します。
[IN]
import gradio as gr
# ラップする関数
def greet(name):
return "Hello " + name + "!"
# シンプルなUIを作成
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output Box")
greet_btn = gr.Button("Greet")
greet_btn.click(fn=greet,
inputs=name,
outputs=output)
# 起動
demo.launch()
[OUT]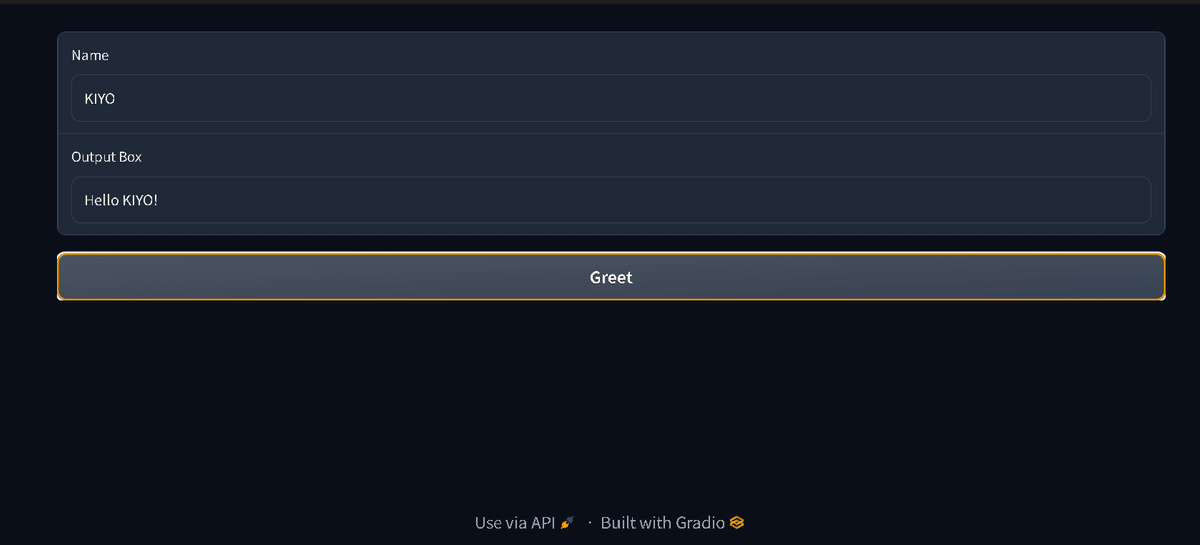
5-2.Auto-Reloadingによる高速化
追って
6.アプリのシェア
追って
[IN]
[OUT]7.Hugging Faceとの統合
Hugging Faceで公開済みモデルを使用してWebアプリの作成も可能です。
サンプルとして「Helsinki-NLP/opus-mt-ja-en」モデルを使用して日本語を英語に翻訳するモデルを作成します。
7-1.学習済みモデルを取得して使用:pipeline()
初回は必要な学習済みモデルのダウンロードが発生します。
[IN]
import gradio as gr
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-ja-en")
def predict(text):
return pipe(text)[0]["translation_text"]
iface = gr.Interface(
fn=predict,
inputs='text',
outputs='text',
examples=[["こんにちは、私の名前はKIYOです"]]
)
iface.launch()
[OUT]
Running on local URL: http://127.0.0.1:7886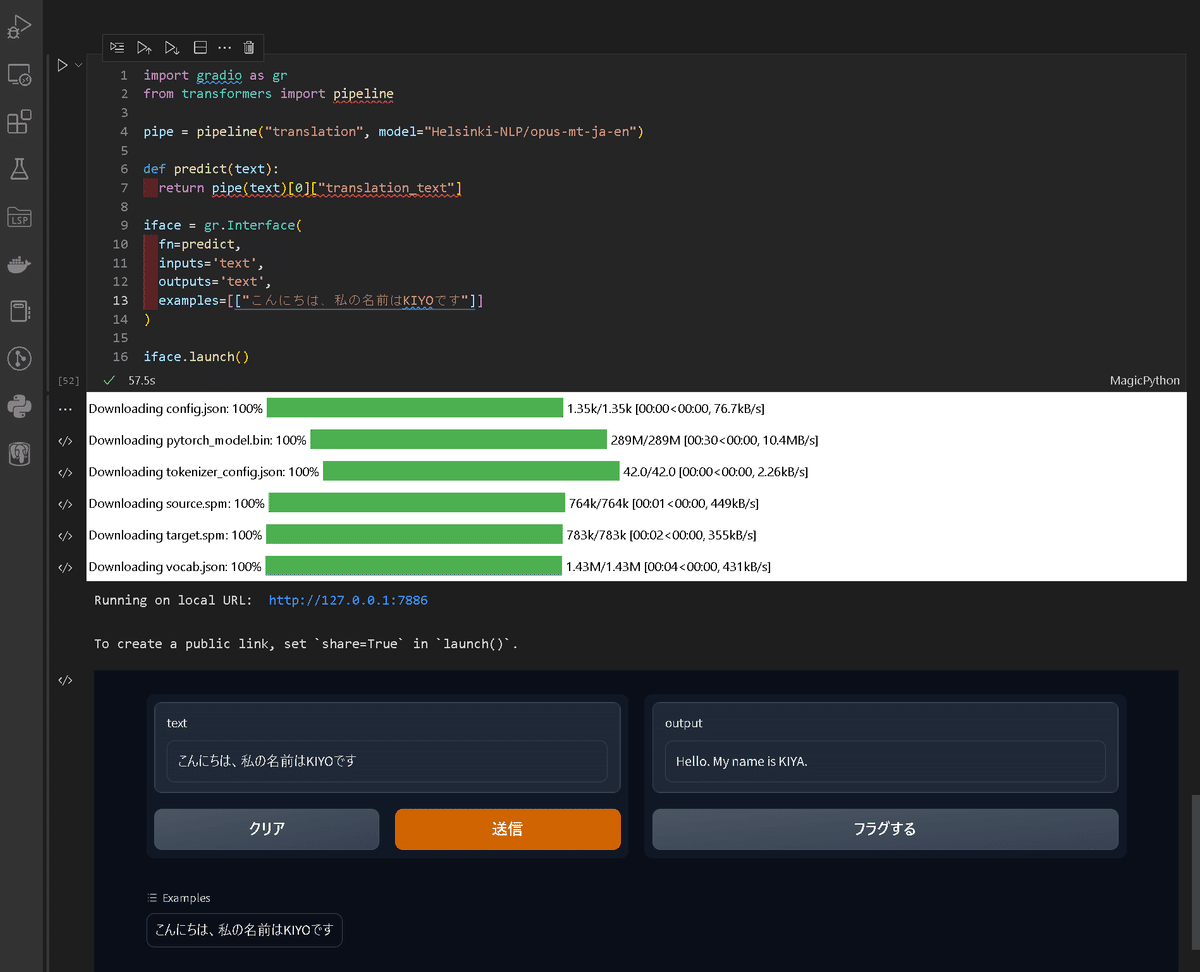
7-2.APIでHugging Faceから直接使用:load()
"Hugging Face Inference API"を使用することで直接モデルを使用することが出来ます。
[IN]
import gradio as gr
iface = gr.Interface.load("huggingface/Helsinki-NLP/opus-mt-ja-en",
examples=[["こんにちは、私の名前はKIYOです"]]
)
iface.launch()
[OUT]
Fetching model from: https://huggingface.co/Helsinki-NLP/opus-mt-ja-en
Running on local URL: http://127.0.0.1:7889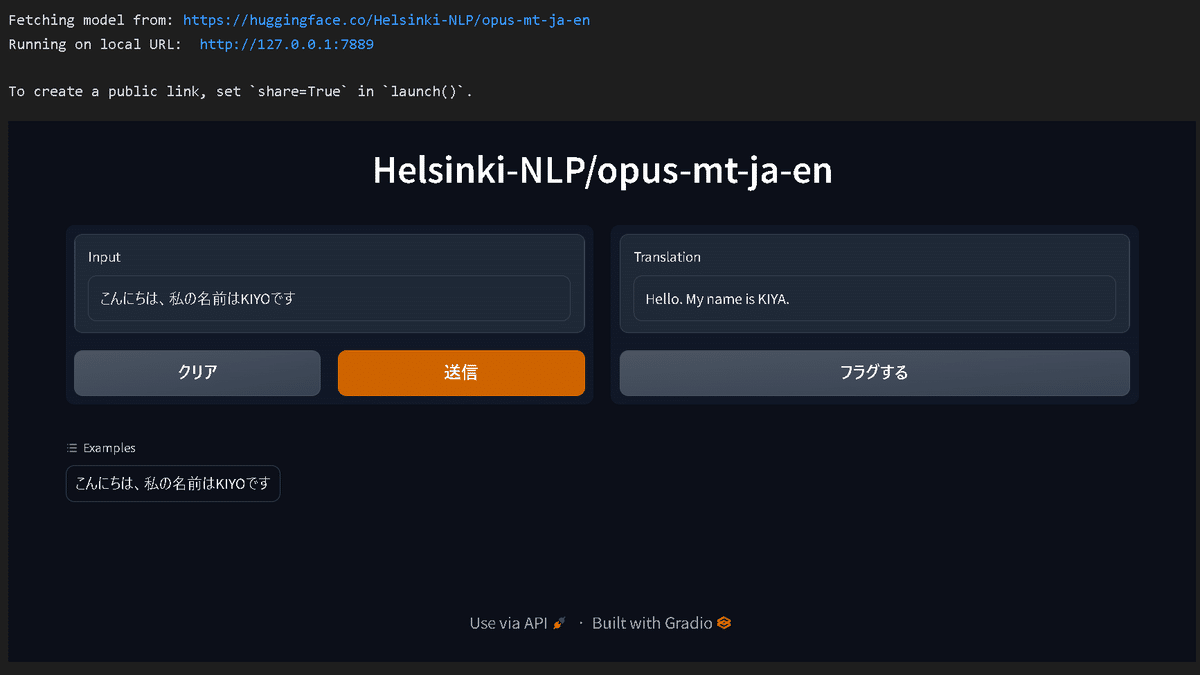
8.Databaseへの接続
追って
[IN]
[OUT]9.gradioの実装(実践編)
それでは簡易で動物の認識Webアプリを作成します。今回はPytorchHubを使用して下記手順で作成しました。
動物認識の学習モデルとしてALEXNETをPytorchHubから取得
ALEXNETが学習したILSVRCのラベル名を追加(下記のimagenet_class_index.jsonを使用)
Pytorchで前処理を追加(transforms)
認識モデル(predict関数)を作成(※gradioではgr.Image()で入力した画像はNumpy形式になるため一度PILに変換)
gradioで入力値:画像、出力値:ラベルになるようにWebアプリ作成
コードと結果は下記の通りです。トラネコ(tabby)をちゃんと認識してくれました。
[IN]
import gradio as gr
import torch
import torchvision
import torchvision.transforms as T
import json
from PIL import Image
#Idとラベルの対応付け
with open("imagenet_class_index.json", "r") as f:
id2label = json.load(f)
model = torch.hub.load('pytorch/vision:v0.10.0', 'alexnet', pretrained=True)
model.eval()
transforms = T.Compose([
T.Resize((256, 256)), # 画像サイズを256x256に変換
T.ToTensor(), # Tensorに変換
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 平均と標準偏差で正規化
])
def predict(img):
img = Image.fromarray(img.astype('uint8'), 'RGB') # NumpyからPIL形式に変換
img = transforms(img).unsqueeze(0) # バッチサイズを1に変換
y_pred = model(img)
_, y_pred = torch.max(y_pred, 1)
label = id2label[str(y_pred.item())][1]
return (label, y_pred.item())
demo = gr.Interface(fn=predict,
inputs=gr.Image(),
outputs=[gr.Textbox(label="label"), gr.Textbox(label="id")])
demo.launch()
[OUT]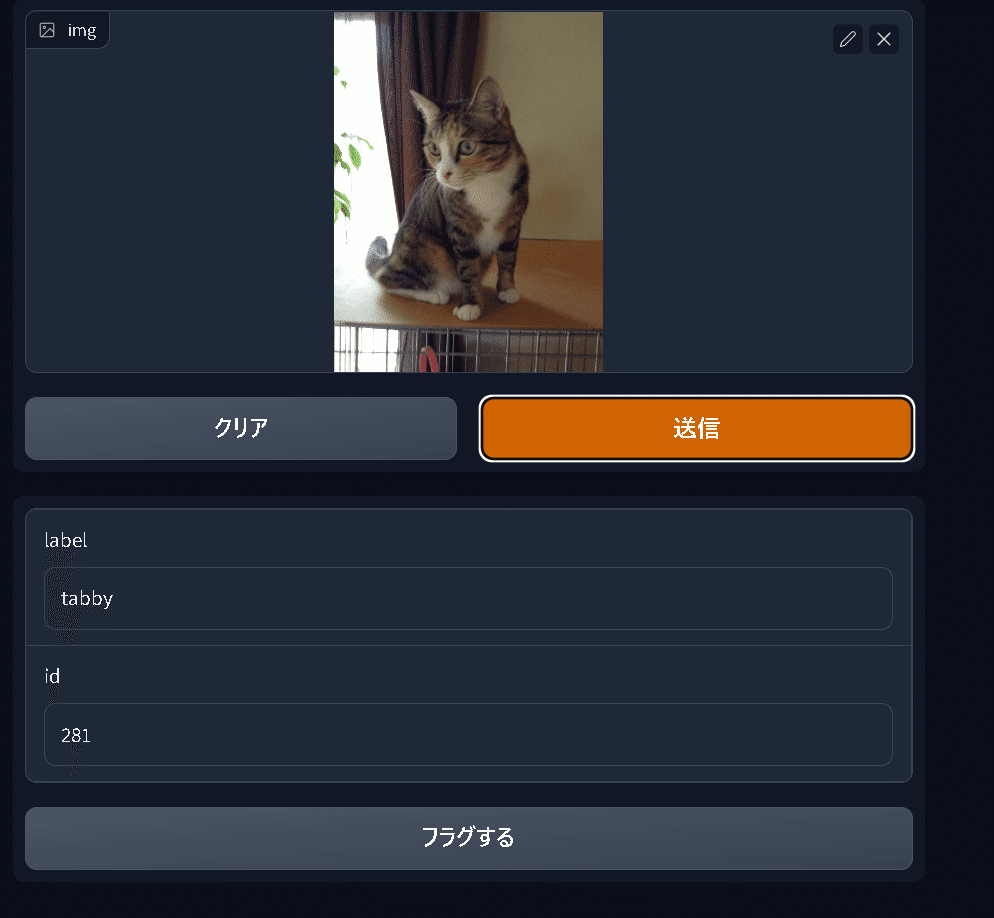
参考資料
あとがき
かなり便利だと思う。公式Docsはかなり充実はしているけど、少し体系度が低いので理解しにくいな・・・・