
Python基礎5:関数・組み込み関数

概要
Pythonの基礎として関数および組み込み関数を簡単に説明します。
1.関数
関数とは入力値に何かしらの処理をして値を返すことができるものです。
まとまった処理を関数化することで同じ処理を実行する時に繰り返しコードを記載する必要がなくなります。
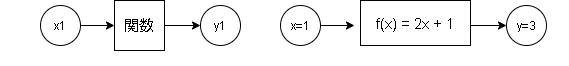
1-1.関数(def)の記載方法
Pythonのコード記載方法は下記のようにdef 関数名(引数)で作成します。
[In]
def f(x):
return 2*x+1
f(1)
[Out]
3コードを見ると1行で書く人も見ます。
[In]
def f(x): return 2*x+1
f(1)
[Out]
3関数の引数をdef()の時点で渡しておけば初期値として使用され、引数に値を入れなくても使用できます。
[In]
def Fizzbuzz(nums=100):
output = []
for i in range(1, nums+1):
if i%15==0:
output.append('FizzBuzz')
elif i%5==0:
output.append('Buzz')
elif i%3==0:
output.append('Fizz')
else:
output.append(i)
return output
print(Fizzbuzz()) #入力値は初期値を設定しているため100
[Out]
[1, 2, 'Fizz', 4, 'Buzz', 'Fizz', 7, 8, 'Fizz', 'Buzz', 11, 'Fizz', 13, 14, 'FizzBuzz', 16, 17, 'Fizz', 19, 'Buzz', 'Fizz', 22, 23, 'Fizz', 'Buzz', 26, 'Fizz', 28, 29, 'FizzBuzz', 31, 32, 'Fizz', 34, 'Buzz', 'Fizz', 37, 38, 'Fizz', 'Buzz', 41, 'Fizz', 43, 44, 'FizzBuzz', 46, 47, 'Fizz', 49, 'Buzz', 'Fizz', 52, 53, 'Fizz', 'Buzz', 56, 'Fizz', 58, 59, 'FizzBuzz', 61, 62, 'Fizz', 64, 'Buzz', 'Fizz', 67, 68, 'Fizz', 'Buzz', 71, 'Fizz', 73, 74, 'FizzBuzz', 76, 77, 'Fizz', 79, 'Buzz', 'Fizz', 82, 83, 'Fizz', 'Buzz', 86, 'Fizz', 88, 89, 'FizzBuzz', 91, 92, 'Fizz', 94, 'Buzz', 'Fizz', 97, 98, 'Fizz', 'Buzz']1-2.ジェネレーター:yield
関数ではreturnが実行されると処理が終了します。下記では戻り値は6個ではなく1個しか取得できません。
[In]
def doubleroop():
for i in range(1,3):
for j in range(10,13):
return (i,j)
print(doubleroop())
[Out]
(1, 10)for文のような反復処理で組み合わせる場合はyeildを使用します。yeildを使用すると戻り値が取得でき、かつ関数の処理を一時停止させて別の処理に移ることができます。結果はジェネレータで取得できるのでfor文などを使用すれば下記の通りとなります。
[In]
def doubleroop_y():
for i in range(1,3):
for j in range(10,13):
yield (i,j)
print(doubleroop_y())
for i in doubleroop_y():
print(i)[Out]
<generator object doubleroop_y at 0x000001EB0F18C820>
(1, 10)
(1, 11)
(1, 12)
(2, 10)
(2, 11)
(2, 12) ジェネレーターの特徴はメモリ使用量を少なくできます。リストやタプルは全要素をメモリに保持しますが、ジェネレーターは次の要素が求められるたびに新しい要素を生成して返すためメモリ使用量を小さく保てます。
例として4桁数値のパスワードを出力する関数で試しました。ジェネレーターを使用することでメモリの増加量を削減できました。
[IN1:returnを使用(出力はリストで保持)]
from itertools import product
import string
def passatack_nam(digits:list, repeat:int):
output = []
for i in product(digits, repeat=repeat):
output.append(''.join(i))
return output
digits = string.digits #出力:'0123456789'
for i in passatack_nam(digits, repeat=6):
print(i)
[IN2:ジェネレーター使用]
from itertools import product
import string
def passatack_nam(digits, repeat:int):
output = []
for i in product(digits, repeat=repeat):
yield ''.join(i)
digits = string.digits #出力:'0123456789'
for i in passatack_nam(digits, repeat=6):
print(i)
[OUT]
000000
000001
000002
~以下省略~
...
999996
999997
999998
999999
2.型ヒント
Pythonは動的型付け言語のため、変数の型(小数、整数、文字列など)を自動で設定してくれます。しかし、後々コードを見返すと関数やクラスにどのような型の入力値を入れたらいいか、どのような型の出力値が出るかがわからなくなります。
可読性を上げるためにPython3.5以降(PEP 484: Type Hints)で型ヒントが記載できるようになりました。特徴は下記の通りです。
ヒントのみであり実行時には何も影響を与えない(異なる型の値を入力してもエラーは発生しない)
mypyなどを使用することでコードの型チェックが確認可能
IDEにより(出力でエラーが出ないが)エラーチェック機能でお知らせしてくれる(下図参照)

参考例は下記のとおりです。
[In]
from typing import List
def Fizzbuzz(nums: int=100) -> List:
output = []
for i in range(1, nums+1):
if i%15==0:
output.append('FizzBuzz')
elif i%5==0:
output.append('Buzz')
elif i%3==0:
output.append('Fizz')
else:
output.append(i)
return output
nums: int = 100 #ループ回数
Fizzbuzz(nums)
[Out]
[1, 2, 'Fizz', 4, 'Buzz', 'Fizz', 7, 8, 'Fizz', 'Buzz', 11, 'Fizz', 13, 14, 'FizzBuzz', 16, 17, 'Fizz', 19, 'Buzz', 'Fizz', 22, 23, 'Fizz', 'Buzz', 26, 'Fizz', 28, 29, 'FizzBuzz', 31, 32, 'Fizz', 34, 'Buzz', 'Fizz', 37, 38, 'Fizz', 'Buzz', 41, 'Fizz', 43, 44, 'FizzBuzz', 46, 47, 'Fizz', 49, 'Buzz', 'Fizz', 52, 53, 'Fizz', 'Buzz', 56, 'Fizz', 58, 59, 'FizzBuzz', 61, 62, 'Fizz', 64, 'Buzz', 'Fizz', 67, 68, 'Fizz', 'Buzz', 71, 'Fizz', 73, 74, 'FizzBuzz', 76, 77, 'Fizz', 79, 'Buzz', 'Fizz', 82, 83, 'Fizz', 'Buzz', 86, 'Fizz', 88, 89, 'FizzBuzz', 91, 92, 'Fizz', 94, 'Buzz', 'Fizz', 97, 98, 'Fizz', 'Buzz']【参考:型ヒントが必要なライブラリ紹介】
FastAPIやSQLModel(型ヒントが必須のライブラリ)ではPydanticを使用して型ヒントを確認可能であり、SQLModelは型ヒントの追加が必須です。
これらにはtypingライブラリを使用して型ヒントをつけました。
2-1.型ヒント:変数
型ヒントの定義方法は変数作成時に":<型ヒント>"を追加します。
[型ヒントの定義方法]
<変数>:<型ヒント> = <値>サンプルは下記の通りです(参考としてpythonのVersionも出力)。
[IN]
import sys
print(f'python version: {sys.version}')
a: int = 10
b: str = 'hello'
c: float = 3.14
d: bool = True
e: list = [1, 2, 3]
f: tuple = (1, 2, 3)
g: dict = {'a': 1, 'b': 2, 'c': 3}
h: set = {1, 2, 3}
i: frozenset = frozenset({1, 2, 3})
j: complex = 1 + 2j
print(a, b, c, d, e, f, g, h, i, j)
[OUT]
python version: 3.8.12 (default, Oct 12 2021, 03:01:40) [MSC v.1916 64 bit (AMD64)]
10 hello 3.14 True [1, 2, 3] (1, 2, 3) {'a': 1, 'b': 2, 'c': 3} {1, 2, 3} frozenset({1, 2, 3}) (1+2j)2-2.型ヒント:関数・戻り値
関数に型ヒントをつける時は下記の通りです。
関数の引数:引数の後ろに(変数と同様に)":<型ヒント>"を記載
関数の戻り値:(引数)と":"の間に"-> <型ヒント>"を記載
参考例は下記の通りです。なお最終行のコードは型ヒントと入力値が異なるためIDEで警告は出ますが、実行してもエラーは出ません。
[IN]
def addnum(a: int, b: int) -> int:
return a + b
print(addnum(1, 2))
print(addnum(10.0, 20.0)) #型は異なるがエラーは出ない
[OUT]
3
30.0
2-3.型ヒント:コンテナ(ListやDict)
Pythonには複数の値を格納できるデータ構造としてコンテナがあり、「リスト (list)、タプル (tuple)、辞書 (dict)、集合 (set)」などがあります。
コンテナの記法はPythonのVersionで異なりますが基本的には同じです。
2-3-1.Python3.5~3.8:List[<型>]
Python3.9より前のVersionではPythonにコンテナの型ヒントが組み込みされていないため"typing"を使用して頭文字を大文字で記載します。
[IN]
from typing import List
names: List[str] = ['Taro', 'Jiro', 'Saburo'] #リストの型を指定
print(names)
[OUT]
['Taro', 'Jiro', 'Saburo'][IN]
from typing import List, Tuple, Dict, Set
names: List[str] = ['Taro', 'Jiro', 'Saburo'] #リストの型を指定
ages: Tuple[int] = (10, 20, 30) #タプルの型を指定
name2age: Dict[str, int] = {'Taro': 10, 'Jiro': 20, 'Saburo': 30} #辞書の型を指定
locate: Set[str] = {'Tokyo', 'Osaka', 'Fukuoka'} #セットの型を指定
print(names, ages, name2age, locate)
[OUT]
['Taro', 'Jiro', 'Saburo']
(10, 20, 30)
{'Taro': 10, 'Jiro': 20, 'Saburo': 30}
{'Fukuoka', 'Tokyo', 'Osaka'}2-3-2.Python3.9以降:list[<型>]
Python 3.9でPEP 585(標準コレクション型の型ヒントにおける総称型)が導入されており、"typing"を使用せずに頭文字を小文字で記載することでコンテナの型ヒントが設定できます。
[IN]
names: list[str] = ['Taro', 'Jiro', 'Saburo'] #リストの型を指定
[OUT]
3.9以降ならエラーなくできるはず
2-4.型ヒント:複数の型(Union)
型ヒントを複数設置する場合はUnionを使用します。下記例ではintとfloatの両方を設置することで前回まで出ていたエラーチェックが消えていることが確認できました。
[IN]
from typing import Union, Optional
def addnum(a: Union[int, float], b: Union[int, float]) -> Union[int, float]:
return a + b
print(addnum(1, 2))
print(addnum(10.0, 20.0))
[OUT]
3
30.0
2-5.型ヒント:全ての型(Optional)
全ての型を受け付ける場合はOptionalを使用します。例としてデータベースでNoneが入る可能性がある場合などに使用できます。また入力値がよくわからなくてもOptionalをつけておくことで明確化することが可能です。
[IN]
from typing import Union, Optional
def justprint(a: Optional[str]) -> None:
print(a)
justprint('hello')
justprint(None)
[OUT]
hello
None3.lambda関数(無名関数)
lambda()はdef()とは別の形式で簡単に関数を作成できます。defの用に関数名がなくても使えるためちょっとした関数を使いたいときに使用します。
3-1.関数名あり:def()と同じ
無名関数ですが通常の関数と同じく名前を付けて関数を使用できます。
[In]
f_lambda = lambda x:2*x + 1
print(f_lambda(1))
[Out]
33-2.関数名なし:関数を直接使用
通常の使用方法として関数名を付けずに直接使用します。
[In]
def f(x): return 2*x+1 #関数記載パターン
for i in map(f, range(5)):
print(i, end=',')
for i in map(lambda x:2*x+1, range(5)): #lambda関数パターン (上と同じ)
print(i, end=',')
[Out]
1,3,5,7,9,
1,3,5,7,9,4.組み込み関数
組み込み関数とはPythonをインストールして最初から使える関数です。「組み込み関数 — Python 3.10.0b2 ドキュメント」より下記があります。

組み込み関数の一部を紹介します(print()やrange()など簡単なものは説明を省略しております)。
4-1.dir(), help():情報確認
dir()に使いたいライブラリやクラスを引数に入れると使用できるメソッド(関数)や属性が確認できます。
[In]
import pandas as pd
dir(pd) #pandasで使えるメソッドや属性を確認
[Out]
['BooleanDtype', 'Categorical', 'CategoricalDtype', 'CategoricalIndex', 'DataFrame', 'DateOffset', 'DatetimeIndex', 'DatetimeTZDtype', 'ExcelFile', 'ExcelWriter', 'Flags', 'Float32Dtype', 'Float64Dtype', 'Float64Index', 'Grouper', 'HDFStore', 'Index', 'IndexSlice', 'Int16Dtype', 'Int32Dtype', 'Int64Dtype', 'Int64Index', 'Int8Dtype', 'Interval', 'IntervalDtype', 'IntervalIndex', 'MultiIndex', 'NA', 'NaT', 'NamedAgg', 'Period', 'PeriodDtype', 'PeriodIndex', 'RangeIndex', 'Series', 'SparseDtype', 'StringDtype', 'Timedelta', 'TimedeltaIndex', 'Timestamp', 'UInt16Dtype', 'UInt32Dtype', 'UInt64Dtype', 'UInt64Index', 'UInt8Dtype', '__builtins__', '__cached__', '__doc__', '__docformat__', '__file__', '__getattr__', '__git_version__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_config', '_hashtable', '_is_numpy_dev', '_lib', '_libs', '_np_version_under1p17', '_np_version_under1p18', '_testing', '_tslib', '_typing', '_version', 'api', 'array', 'arrays', 'bdate_range', 'compat', 'concat', 'core', 'crosstab', 'cut', 'date_range', 'describe_option', 'errors', 'eval', 'factorize', 'get_dummies', 'get_option', 'infer_freq', 'interval_range', 'io', 'isna', 'isnull', 'json_normalize', 'lreshape', 'melt', 'merge', 'merge_asof', 'merge_ordered', 'notna', 'notnull', 'offsets', 'option_context', 'options', 'pandas', 'period_range', 'pivot', 'pivot_table', 'plotting', 'qcut', 'read_clipboard', 'read_csv', 'read_excel', 'read_feather', 'read_fwf', 'read_gbq', 'read_hdf', 'read_html', 'read_json', 'read_orc', 'read_parquet', 'read_pickle', 'read_sas', 'read_spss', 'read_sql', 'read_sql_query', 'read_sql_table', 'read_stata', 'read_table', 'reset_option', 'set_eng_float_format', 'set_option', 'show_versions', 'test', 'testing', 'timedelta_range', 'to_datetime', 'to_numeric', 'to_pickle', 'to_timedelta', 'tseries', 'unique', 'util', 'value_counts', 'wide_to_long'],同様にhelp()に入れるとpackage情報が確認できます。
[In]
help(pd)
[Out]
Help on package pandas:
NAME
pandas
DESCRIPTION
pandas - a powerful data analysis and manipulation library for Python
=====================================================================
**pandas** is a Python package providing fast, flexible, and expressive data
以下略4-2.For文で使用できる関数
それぞれfor文などで使用すると便利な処理ができます。
4-2-1. enumerate:index追加
for文で回す時にindex番号(0開始)を取得できます。
[In]
import string
words = string.ascii_lowercase #output->'abcdefghijklmnopqrstuvwxyz'
for idx, word in enumerate(words):
print((idx, word), end=', ')
[Out]
(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd'), (4, 'e'), (5, 'f'), (6, 'g'), (7, 'h'), (8, 'i'), (9, 'j'), (10, 'k'), (11, 'l'), (12, 'm'), (13, 'n'), (14, 'o'), (15, 'p'), (16, 'q'), (17, 'r'), (18, 's'), (19, 't'), (20, 'u'), (21, 'v'), (22, 'w'), (23, 'x'), (24, 'y'), (25, 'z'),4-2-2. map:関数処理
map(関数, リスト)で値に処理をさせたい関数を渡すことができます。関数はlambda関数も渡すことができます。
[In]
import string
words = string.ascii_lowercase #output->'abcdefghijklmnopqrstuvwxyz'
for word in map(lambda x:x.upper(), words): #小文字を大文字に変換
print(word, end=' ')
[Out]
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z[In]
def f(x): return 2*x+1
for i in map(f, range(5)):
print(i, end=',')
[Out]
1,3,5,7,9,4-2-3. zip:複数処理
リストなどを2個以上まとめて処理したいときにzip()を使用する。
[In]
nums1 = [i for i in range(10)] #output->[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
nums2 = [i*10 for i in range(10)] #output->[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
for num1, num2 in zip(nums1, nums2):
print(num1+num2, end=', ') #print()文の改行をなくすためにend引数を設定
[Out]
0, 11, 22, 33, 44, 55, 66, 77, 88, 99,zipに渡すリストの数が異なる場合、最も少ないリストが基準となる。
[In]
nums1 = [i for i in range(10)] #output->[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
nums2 = [i*10 for i in range(10)] #output->[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
nums3 = [i*100 for i in range(5)] #output->[0, 100, 200, 300, 400]
print('データ数:', len(nums1), len(nums2), len(nums3)) #組み込み関数len()でリストやタプルのデータ数を確認
for num1, num2, num3 in zip(nums1, nums2, nums3):
print(num1+num2+num3, end=', ') #print()文の改行をなくすためにend引数を設定
[Out]
len()でリスト内のデータ数を確認: 10 10 5
0, 111, 222, 333, 444,4-3.type(), id():データ情報の確認
type()は変数のデータ型を確認します。初心者のころは計算時にエラーが多発して原因がデータ型がおかしいことが多かったため、よくtype()でチェックしました。
[In]
import numpy as np
a='1'
b=1
c= np.array([1])
print(type(a),type(b),type(c))
[Out]
<class 'str'> <class 'int'> <class 'numpy.ndarray'>id()は変数を識別してくれる値を返してくれるため、同じidであれば同じ変数と判断できます。詳細は下記の「参照渡しと値渡し」をご参照ください。
4-4.sorted():データのソート
sorted()でリスト内のデータをソートできます。私も初心者のころデータ型と文字列型の違いで混乱したため参考までに2種サンプル作成しました。
文字列を数値と同じするなら数値変換->ソート->文字列変換で可能です。
[In]
import random
random.seed(0) #ランダム値を固定
randomints = [random.randint(1, 300) for _ in range(10)]
randomints_int = [i for i in map(lambda x:str(x), randomints)] #上記で作成したデータ値をstring型に変換
#数値型
print(randomints)
print(sorted(randomints))
#文字列型
print(randomints_int)
print(sorted(randomints_int))
[Out]
[198, 216, 21, 133, 262, 249, 208, 156, 245, 184]
[21, 133, 156, 184, 198, 208, 216, 245, 249, 262]
['198', '216', '21', '133', '262', '249', '208', '156', '245', '184']
['133', '156', '184', '198', '208', '21', '216', '245', '249', '262']4-5.set():リスト内の重複削除
set()でリスト内データの重複を消せます。なお返り値のデータ型は<class 'set'>になります。
[In]
a = [i for i in range(5)]
b = [i for i in range(2,7)]
c = [i for i in range(6,10)]
sampledatas = a+b+c
print(sampledatas) #original data
print(set(sampledatas)) #重複削除
[Out]
[0, 1, 2, 3, 4, 2, 3, 4, 5, 6, 6, 7, 8, 9]
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}4-6.open():ファイルの読み書き
open(file, mode='r')でファイルの読み書きができます。open()を使用するとファイルを開くけど閉じる作業まではしません。開く・閉じるをまとめてするにはwith open()で記載します。
[In]
with open("The Zen of Python.txt", 'r') as f:
text = f.read()
text
[Out]
"The Zen of Python, by Tim Peters\n\nBeautiful is better than ugly.\nExplicit is better than implicit.\nSimple is better than complex.\nComplex is better than complicated.\nFlat is better than nested.\nSparse is better than dense.\nReadability counts.\nSpecial cases aren't special enough to break the rules.\nAlthough practicality beats purity.\nErrors should never pass silently.\nUnless explicitly silenced.\nIn the face of ambiguity, refuse the temptation to guess.\nThere should be one-- and preferably only one --obvious way to do it.\nAlthough that way may not be obvious at first unless you're Dutch.\nNow is better than never.\nAlthough never is often better than *right* now.\nIf the implementation is hard to explain, it's a bad idea.\nIf the implementation is easy to explain, it may be a good idea.\nNamespaces are one honking great idea -- let's do more of those!"
4-7.isinstance():データ型確認
"isinstance(<変数>, <データ型>)"とすることで変数のデータ型を判定できBool型で結果を返します。データ型は複数渡すことができ、その場合はor判定となります。
[IN]
text = 'python'
result1 = isinstance(text, str) #True
result2 = isinstance(text, int) #False
result3 = isinstance(text, (str, int)) #True
print(result1, result2, result3)
[OUT]
True False Trueこれを応用すると入れ子構造のリストを1次元配列に変換可能です。Numpyのravel()で1次元配列できない構造に対して、下記設計をすることで1次元配列化が可能です。
処理したいイテラブルデータをfor文でまわす
"isinstance(<データ>, Iterable)"でイテラブルかどうか判定する。またデータが文字列の場合、そのままだと文字列もイテラブルでありそのまま処理されるため"and not isinstance(<データ>, str)"で文字列は処理しないようにする
再帰的な処理を入れ、もしfor文で取り出したデータがイテラブルなら再度自身の関数を処理するようにする。
[IN]
import numpy as np
from collections.abc import Iterable
nested_list = [[1, 2], 10, [3, 4, [5, 6]]]
print('numpy.ravel():', np.ravel(np.array(nested_list))) #numpy .ravel()で多次元配列を1次元配列に変換
def flatten(lis):
for item in lis:
if isinstance(item, Iterable) and not isinstance(item, str):
for x in flatten(item):
yield x
else:
yield item
print('flatten():', list(flatten(nested_list))) #flatten ()関数で多次元配列を1次元配列に変換
[OUT]
numpy.ravel(): [list([1, 2]) 10 list([3, 4, [5, 6]])]
flatten(): [1, 2, 10, 3, 4, 5, 6]5.可変長引数:関数の定義
数を指定せずに関数に渡せる引数(argument)を可変長引数と言います。可変長引数は"*args"と"**kwargs"がありそれぞれTuple, Dict型で出力します。
【可変長引数】
●*args:関数に渡した引数がまとめてTupleとして取得される
●**kwargs:関数に渡したキーワード引数が辞書として出力される
※可変長引数を記載する時は"*"や"**"を記載すれば変数は何でも問題ないですが形式的に"*args"、"**kwargs"を使用します。
5-1.可変長の位置引数:*args ->Tuple
出力をTupleで受ける場合は"*args"を指定します。"*args"を引数に渡すことで数を指定せずに引数を渡すことができます。
【*argsの特徴まとめ】
●引数の数を任意で関数に渡すことができる。まとめて渡した引数は関数内でTupleとして扱われる。
●キーワード引数と併用可能である。ルールとして*argsはキーワード引数の後ろに記載する(前に記載するとエラー)。
[IN]
import numpy as np
def testf(*args):
print(args)
print('データ型:', type(args))
testf(1)
testf(1,2,np.array(3),[4])
[OUT]
(1,)
データ型: <class 'tuple'>
(1, 2, array(3), [4])
データ型: <class 'tuple'>もし特定値は引数で指定して残りは可変長引数にしたい場合は"*args"の前に引数を記載します。
[IN1]
def testf2(x, y, *args):
print(f'x:{x}, y:{y}, args:{args}')
print(type(x), type(y), type(args))
testf2(1,2,3,4)
[OUT1]
x:1, y:2, args:(3, 4)
<class 'int'> <class 'int'> <class 'tuple'>先に"*args"を指定するとpythonは可変長引数がどこまで範囲指定しているのか判断できないためエラーが出ます。このような場合はキーワード引数(変数実行時に変数を記載する)を指定します。
[IN2]
def testf2(*args, x, y):
print(f'x:{x}, y:{y}, args:{args}')
print(type(x), type(y), type(args))
testf2(1,2,3,4)
[OUT2]
TypeError: testf2() missing 2 required keyword-only arguments: 'x' and 'y'
[IN3]
def testf2(*args, x, y):
print(f'x:{x}, y:{y}, args:{args}')
print(type(x), type(y), type(args))
testf2(1,2,x=3,y=4) #キーワード引数を指定
[OUT3]
x:3, y:4, args:(1, 2)
<class 'int'> <class 'int'> <class 'tuple'>5-2.可変長のキーワード引数:**kwargs ->Dict
キーワード引数をDictで受ける場合は"**kwargs"を使用します。これで数を気にせずにキーワード引数を渡すことができます。
【*kwargsの特徴まとめ】
●キーワード引数を任意の数で渡すことができる。渡したキーワード引数は関数内で辞書型{'変数名':'値'}として扱われる。
●特定のキーワード引数+任意のキーワード引数にしたい場合は、**kwargsはキーワード引数の後ろに記載する(前だとエラー)。
[IN]
def testkf(**kwargs):
print(kwargs)
print(type(kwargs))
testkf(x=1,y=2, z=3)
[OUT]
{'x': 1, 'y': 2, 'z': 3}
<class 'dict'>
[IN2]
testkf(1,2) #キーワード引数ではなく通常の引数を指定
[OUT2]
TypeError: testkf() takes 0 positional arguments but 2 were given特定値は引数で指定して残りはキーワード引数にする場合は"*kwargs"の前に引数を記載します。なお逆の記法(def f(**kwargs, x, y))はエラーになります。
[IN]
def testkf2(a, b, **kwargs):
print(a, b)
print(kwargs)
print(type(a), type(b), type(kwargs))
testkf2(1, 2, x=1, y=2) #キーワード引数は関数で使用していない変数名にすること
[OUT]
1 2
{'x': 1, 'y': 2}
<class 'int'> <class 'int'> <class 'dict'>5-3.def(*args, **kwargs)
引数とキーワード引数をそれぞれ任意の数で渡す場合は"*args"と
"**kwargs"の両方を指定します。関数に渡す時引数->キーワード引数の順に記載します(逆だとエラー)。
[IN]
def testf(*args, **kwargs):
print('args:', args)
print('kwargs', kwargs)
print(type(args), type(kwargs))
testf(1,2,3) #引数のみ testf(x=1,y=2,z=3) #キーワード引数のみ
testf(1,2,3,x=1,y=2,z=3) #引数とキーワード引数を両方指定
[OUT]
args: (1, 2, 3)
kwargs {}
<class 'tuple'> <class 'dict'>
args: ()
kwargs {'x': 1, 'y': 2, 'z': 3}
<class 'tuple'> <class 'dict'>
args: (1, 2, 3)
kwargs {'x': 1, 'y': 2, 'z': 3}
<class 'tuple'> <class 'dict'>[IN]
testf(x=1,y=2,z=3, 1) #キーワード引数と引数を逆に記載
[OUT]
SyntaxError: positional argument follows keyword argument6.可変長引数:関数の使用時
先ほどは関数を定義する時の可変長引数を使用しました。本章では関数側で可変長引数を定義していませんが、関数使用時に引数の渡し方を変えて可変長引数のような処理ができることを確認します。
説明用として事前に①1つの引数xだけ受け取る、②3つの引数x1,x2,x3を受け取る関数 を作成しました。
[IN]
import numpy as np
def func_with_1arg(x):
print(x)
print(type(x))
def func_with_kwargs(x1, x2, x3):
print(x1, x2, x3)
print(type(x1), type(x2), type(x3))6-1.イテラブルな変数xを*xで渡す
イテラブル(リストなど)な変数xがあり、変数の頭に"*"をつけて関数に渡すと各要素に分解した引数を渡します(要素を1個ずつ渡す)。
要素数3のイテラブル変数x1でテストすると下記が確認できます。
引数が1個の関数に"*x1"で渡すと「引数1個の関数に3つ渡しているためエラー」と表示されます。
引数が3個の関数に"*x1"で渡すと(変数は1個しか渡していないが)エラーなく実行できた。
[IN]
x1 = [1,2,3]
func_with_1arg(x1)
[OUT]
[1, 2, 3]
<class 'list'>[IN]
func_with_1arg(*x1)
[OUT]
TypeError: func_with_1arg() takes 1 positional argument but 3 were given[IN]
func_with_kwargs(*x1)
[OUT]
1 2 3
<class 'int'> <class 'int'> <class 'int'>上記よりイテラブル変数の頭に"*"をつけて関数に渡すと要素を分解してそれを1個ずつ関数に渡していくことが分かります。よって変数は文字列でも実行可能です。
[IN]
x2 = 'abc'
func_with_kwargs(*x2)
[OUT]
a b c
<class 'str'> <class 'str'> <class 'str'>6-2.辞書型変数xを**xで渡す
先ほどの"*"だと引数の順序はイテラブル変数の要素順になるため、要素順が整っていないとキーワード引数に対してずれる可能性があります。
明確に特定のキーワード引数に対して値を渡したい場合は"**Dict"の形にすると実行可能となります。
[IN]
params = {'x1':1,
'x2':'A',
'x3':[1,2,3]}
func_with_kwargs(**params)
[OUT]
1 A [1, 2, 3]
<class 'int'> <class 'str'> <class 'list'>参考として辞書を前節の"*"で渡すとKEYが渡されます。またキーワード引数を含まないDictを渡すと「キーワード引数がない」というエラーになります。
[IN]
func_with_kwargs(*params)
[OUT]
x1 x2 x3
<class 'str'> <class 'str'> <class 'str'>[IN]
func_with_1arg(**params)
[OUT]
TypeError: func_with_1arg() got an unexpected keyword argument 'x1'7.デコレータ
追って
8.再帰
再帰(処理)とは関数内に自身の関数を呼び出してループさせる処理となります。ある種while文に近いため処理を完了(returnなど)させる処理がないと無限ループとなります。
正直動作が十分に理解できていないためサンプルコードを紹介します。
8-1.シンプルコード
シンプルな再帰関数として入力値を+1ずつ増やしていき10以上となったら値を出力(関数が終了)します。
[IN]
def testfunc(num: int):
if num>=10:
return num #10以上ならreturn
print(num)
num += 1
testfunc(num) #再帰的に呼び出す
count = 8
print(testfunc(count))
[OUT]
8
9
None上記では再帰処理はできましたが戻り値はNoneになりました。Pythonでは再帰処理をすると自動的にNoneが戻り値として渡されるためです。動作を確認するためにprint文を付けて再実行しました。
[IN]
def testfunc(num: int):
if num>=10:
return num #10以上ならreturn
print('num:', num)
num += 1
output = testfunc(num) #再帰的に呼び出す
print(f'***********num:{num-1}, (num + 1):{num}, output:{output}***********')
count = 8
print(testfunc(count))
[OUT]
num: 8
num: 9
***********num:9, (num + 1):10, output:10***********
***********num:8, (num + 1):9, output:None***********
Nonetestfunc()は下記フローで実施されるためreturnが10になりません。
【testfunc()のフロー手順】
1.入力値num=8をif文で判定(False)後にnumに1を足す(num=9)
2.再帰関数testfunc(9)を実行:if文判定してnumに1を足す(num=10)
3.再帰関数testfunc(10)を実行:if文判定してreturn->testfunc(10)は終了
4.testfunc(9)で実行した「output = testfunc(10)」がreturn 10として処理され、再帰関数下のコード(print文)が実行される
5.testfunc(8)で実行した「output = testfunc(9)」は戻り値がないためreturn Noneとして処理され、再帰関数下のコード(print文)が実行される

これを防止するためには再帰処理の部分にも"return"を記載します。
[IN]
def testfunc(num: int):
if num>=10:
return num #10以上ならreturn
print('num:', num)
num += 1
output = testfunc(num) #再帰的に呼び出す
print(f'***********num:{num-1}, (num + 1):{num}, output:{output}***********')
return output
count = 8
print(testfunc(count))
[OUT]
num: 8
num: 9
***********num:9, (num + 1):10, output:10***********
***********num:8, (num + 1):9, output:10***********
10
8-2.2重ループの再帰
次に2重ループで再帰処理を実施してみました。
[IN]
def testfunc(num):
if num>=10: return num #10以上ならそのまま返す
print('***************num:', num, '***************')
num += 1
for idx in range(3):
print('num:', num, 'idx:', idx)
testfunc(num)
count = 8
print(testfunc(count))
[OUT]
***************num: 8 ***************
num: 9 idx: 0
***************num: 9 ***************
num: 10 idx: 0
num: 10 idx: 1
num: 10 idx: 2
num: 9 idx: 1
***************num: 9 ***************
num: 10 idx: 0
num: 10 idx: 1
num: 10 idx: 2
num: 9 idx: 2
***************num: 9 ***************
num: 10 idx: 0
num: 10 idx: 1
num: 10 idx: 2
None出力から判断すると下記のフローで実行されていることが確認できます。
【2重ループの再帰】
●再帰関数までは通常通りの処理
●再帰関数の場合はfor文より先に再帰関数が実行される。
●再帰関数の処理が完了(return)された場合はfor文が続いて処理される。
●再帰関数内のreturnがすべて処理されたら再帰処理を抜ける。途中の再帰関数ではreturnを付けていないため戻り値はNone

2重ループの再帰関数側にreturnを付けた場合、各returnで再帰処理が完了されております。
[IN]
def testfunc(num):
if num>=10: return num #10以上ならそのまま返す
print('***************num:', num, '***************')
num += 1
for idx in range(3):
print('num:', num, 'idx:', idx)
return testfunc(num)
count = 8
print(testfunc(count))
[OUT]
***************num: 8 ***************
num: 9 idx: 0
***************num: 9 ***************
num: 10 idx: 0
10あとがき
使う技術によって使う関数が異なるため全部は紹介しておりません(ブロックチェーン技術だと他の関数も使っていたと思います)。使うタイミングで公式やブログなどを調べるとよいと思います。
この記事が気に入ったらサポートをしてみませんか?