
ワクワクから始めるAI・データ解析(7.AI予測編)

この記事は初心者向けのノーコードAI構築ツール「Humanome CatData」(以下「CatData」)を使い、まずデータをさわってAIづくりをはじめよう、という連載の最終回となります。これまでの記事は以下のリンクからお読みいただけます。
前回から2回にわたって、AI構築とその評価方法の基本的な流れについてお話しました。
導入・目標設定編でも触れた通り、AI構築のゴールは、未知のデータを構築したAIに適用し、予測された結果を次の行動につなげることです。最終回となる今回はこの「予測する」行程となります。

スポーツクラブの会員退会予測AIの作成例に当てはめると、以下のように置き換えることができます。
・前回まで:過去の会員データからAIモデルを作成した
・今回:現会員から退会の可能性がある会員を予測する
・目標:予測した会員に声掛けし、継続率の向上を図る
(1) 今回のお題

今回も引き続き「ペンギンの種名をくちばしの大きさなどから予測するAI」構築の流れに沿って説明します。前提は以下のとおりです。
お題と資料
あなたは、目の前にいる2009年生まれのペンギン達の種名調査を依頼されました。参考資料として2007・2008年のペンギンデータを受け取りました。
解決方法を検討します
2009年生まれのペンギンの各パーツや体重を計測して、2007・2008年のデータと照合して種名を予測しようと考えました。が、残念ながら2009年の個体データと、2007〜2008年の個体データが完全一致する可能性はかなり低そうです。
お題の解決方法
2007〜2008年のペンギンデータで、種名を予測するAIモデルを作ることにしました。2009年のペンギンを順番に計測し、その結果をAIモデルに入力することで、種名を自動で決めていきます。
(2) 予測に入る前の準備
本編に入る前に、以下の前処理済みデータをダウンロードしてください。これらを利用して説明を進めます。この記事からのスタートも可能です。
・2007〜2008年のペンギンデータ(penguins-2007-2008.xlsx)
・2009年のペンギンデータ(penguins-2009.xlsx)
無料プランの場合
本編に入る前に、現在のテーブルを全て削除してください。テーブルの削除方法は以下のリンクをご覧ください。
Proプランの場合
今までに作成したテーブルを残したままで先に進めます。無料プランと同じ作業を実施してください。
(3) ペンギンの種名を予測するAIモデルの作成
それでは本編に入ります。前回までの流れを復習しながら進めます。
まず、先程ダウンロードした"penguins-2007-2008.xlsx"を利用し、各パーツの長さなどから種目を予想するAIモデルを作成します。前処理済みのデータなので、欠損値のチェックは不要です。詳細な手順や操作の意味などについては以下のリンクをご覧ください。
AIモデル作成の簡易的な手順

アップロード〜テーブルの利用目的の選択
①「テーブル一覧」でテーブルを新規作成
② ポップアップ画面から penguins-2007-2008.xlsx をアップロード
③ アップロードしたファイル内容を念の為確認
④ テーブル用途を決めるポップアップで「学習」を選択
⑤ 保存

データの学習
①「テーブル一覧」で「penguins-2007-2008」を選択
② 「アクションセットの編集」を選択し、編集画面へ移動
③ 前処理済みなので、何もせず「確認」を選択
④ 念の為データを確認して「学習」を選択
⑤ アラートがでるので「はい」を選択

モデルの構築
①「モデルの新規作成」をクリック
② 予想対象の列を「種名」に変更
③ 「予想対象の列以外、全てを学習に使用」をオフ
④ 説明変数として「くちばしの長さ」「くちばしの高さ」「水かきの長さ」「体重」の4つを選択
⑤ モデルやパラメータは変更せずそのまま
⑥ 学習開始
⑦ 画面左上「CatData」のロゴをクリック→テーブル一覧に戻る
(4) ペンギンの種名を予測する
ペンギンの種名を予測するモデルができました。このモデルを2009年のペンギンデータに適用し、種名を予測していきます。先ほどダウンロードした、2009年生まれのペンギンのみを取り出したデータ penguins-2009.xlsx を使います。

テーブルの利用目的を選ぶまでの行程は、前項「アップロード〜テーブルの利用目的の選択」と同様です。「テーブルの利用目的の選択画面」で「予測」を選択ししてください。

では、予測を開始します。テーブル一覧から、先程アップロードしたテーブル「penguins-2009」を選択します。いつもどおり、ファイル内容を確かめるステップとなりますので、問題なければ「予測」に進みます。

予測の画面は大きく2つに分かれます。上半分が予測に利用するモデルを選ぶ画面、下半分が予測結果を示す画面です。
ほとんどの場合は予測を開始する時点で、適用する学習済みモデルは決まっています。しかし、各モデルの特性を比較検討する場合などは、1つのテーブルに複数のAIモデルを適用することもあります。
CatDataはどちらの利用方法にも対応しています。
では、2009年データに(3)の過程で作成したAIモデルを適用し、予測してみましょう。
予測画面の中ほどに、作成済みのAIモデルが一覧表示されています。「penguins-2007-2008」を選ぶと、作成日時やテストデータのスコア(精度)など、モデルの詳細情報が表示されます。右側に「予測の開始」ボタンがありますので選択し、予測をはじめます。
予測を開始すると、画面の下の方に予測結果を示すエリアが現れます。予測が終あるると「状態」欄が「終了」と表示されます。「予測結果」ボタンが動くようになっているので、早速押してみましょう。
(5) 予測結果を確認する

「予測結果」ボタンを押すと、今回の予測結果の詳細について確認することができます。予測結果は一番左側、緑背景の「Prediction」列に表示されます。CatDataは、予測結果を元のテーブルに加える形で表示されます。どのサンプルが何と予測されたのかがひと目で確認可能です。
本来は「種名」を予測するデータに「種名」データが存在するわけがないのですが、今回は予測結果画面で「予測された種名」と「本当の種名」を一度に比較できるように、種名情報を残したデータを使って予測しました。なお、今回使ったAIモデルは、「各パーツの長さ」と「体重」を利用して予測するため、2009年データに含まれる「種名」情報は予測精度に一切関連しません。
「Prediction」列と「種名」列を比較すると、AIの予測が必ずしも完璧ではない事がわかります。今回の例では、ジェンツーペンギンをヒゲペンギンと間違えてしまっています。

最後に、実際の種名と予測された種名の回答内容を混同行列で比較し、どれくらいの予測精度となっていたのか確認してみましょう。「混同行列」による評価方法については以下のリンクで詳しくご説明しています。
予測結果のテーブルの「可視化」を押すと、精度確認用の混同行列が表示されます。「Prediction」と「種名」を選択すると、正解の種名に対し、AIがどのように回答したかの結果がひとめでわかります。この例では、AIが間違った予測は合計3件で、大部分の予測は正解だったようです。2009年のデータに対しても予測精度が高いことが分かります。
(6)可視化と予測結果
可視化編・その2で既に触れていますが、 2007〜2008年のペンギンのサイズと種名の分布は、2009年の分布とほぼ一致しています。
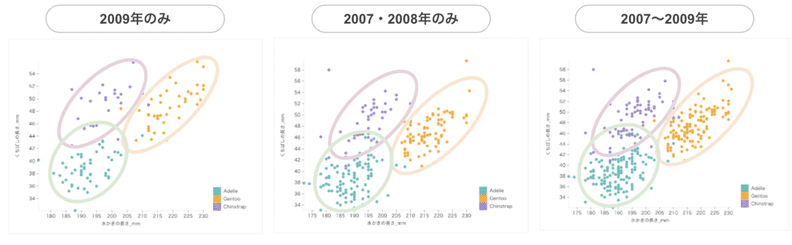
今回、2007〜2008年のペンギンで作成したAIモデルを、2009年のデータに当てはめても、それなりに高精度になるだろうということは、この可視化の時点で推定していました。今回の予測は、この推測を確認する形となっています。
言い換えると、2009年のペンギンのサイズが、2007〜2008年とは大きく異なる場合、2007〜2008年のデータで作成したモデルを適用しても、予測精度は正直期待できません。ペンギンの種名の予測には、大きさのデータを使ったAI予測ではなく、別の手段を考える必要がありました。
ノーコードツールの出現により、AIモデルそのものや、AIモデルの構築・評価プロセスそのものは、計算機にある程度お任せできるようになりました。
しかし、データ解析を進める上では、データ解析者であるみなさんが、手元のデータはどのような特徴を持っていて、どの様な予測であれば利用できそうなのかイメージすることが、とても大切なプロセスの一つなのです。
(7) あとがき
ここまで、全7回にわたって、ペンギンデータを使ったAI解析の代表的な流れについてご説明しました。CatDataを使うことで、プログラミングをせずとも、AI活用までできることを確認いただけたかと思います。
一方で、この連載では解析の流れにフォーカスしたため、細かい手法に関しての説明は省いています。機械学習独特の単語や、他のデータを使った使用事例など、近いうちにご紹介できたらと思います。
ここまでお読み頂き、ありがとうございました!
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!
この記事が気に入ったらサポートをしてみませんか?