
業務改善への一歩!社内で始めた機械学習勉強会の実践

GMOアドマーケティングではメンバーのスキル向上のためにさまざまな取り組みをおこなっています。
今回はその中から、エンジニアが主体でおこなっている機械学習に関する勉強会をご紹介します!

岸田 優輝(きしだ ゆうき)(写真左)
GMOアドマーケティング株式会社 開発本部
2021年、GMOアドマーケティングに新卒入社。
レコメンド記事配信ロジックや記事カテゴリ類推を担当
春田 雅也(はるた まさや)(写真右)
GMOアドマーケティング株式会社 開発本部
2020年、GMOアドマーケティングに新卒入社。
広告掲載順位の最適化や、文章/画像生成AIを活用した業務効率化を担当
幅広いAI活用の土台づくり

最近、生成型AIのブームが到来し、企業ではAIを業務や事業に活用する動きが高まっています。しかし、AIの万能さから何でもAIで解決しようとする風潮がある中、AIには向き不向きのタスクも存在します。たとえば、ChatGPTのような生成型AIは複雑なデータ分析には適していません。そして、生成型AI以外の分析型・予測型AIを活用する際には、それなりの知識が必要です。
そこで、社内で機械学習の勉強会を企画・実施することにしました。目的は、AIができることとできないことを理解し、AIの仕組みに関する知識を深め、生成型AIに限らない幅広い技術を活用できる土台を作ることです。最終的には、データの整形、モデル作成、予測、精度確認のサイクルを理解し、自身で回せるようになることを目指しました。
初心者にも参加しやすい研修内容
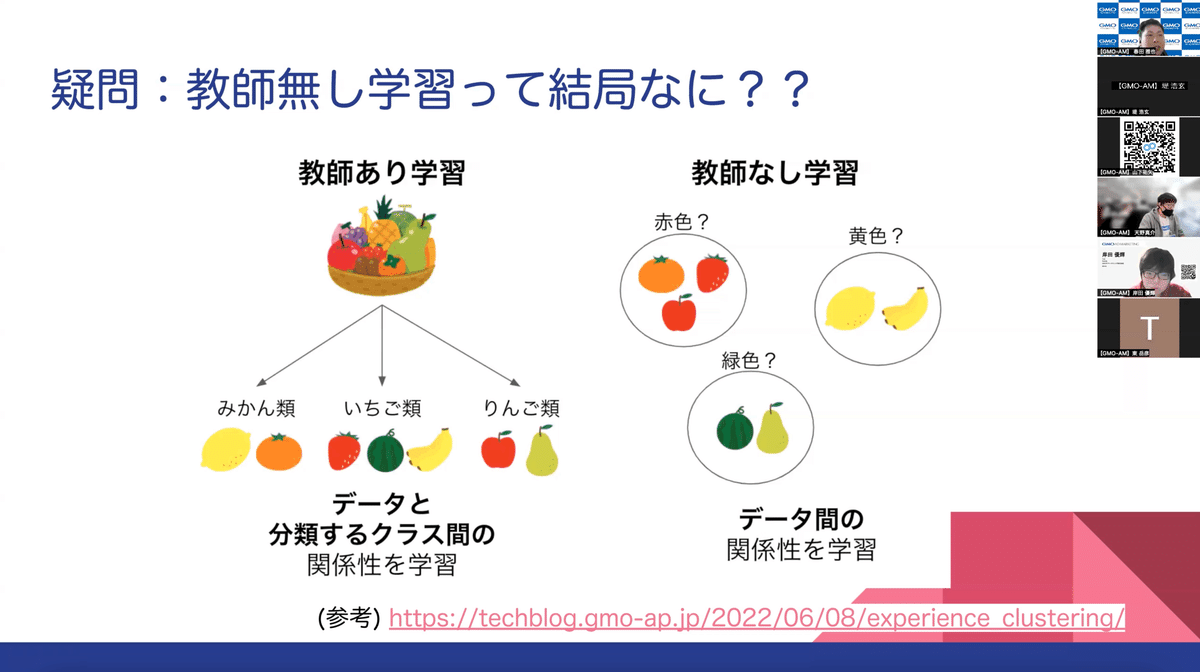
まず、実施内容を決めるうえで重要視した点は、「研修内容のレベルをどう設定するか?」でした。今回の研修は、職種関係なくGMOアドマーケティング全パートナー(社員)が参加します。エンジニア非エンジニアもいるので、機械学習の知識やコーディングスキルには個人差があります。そこで、全員が参加できるよう、週に1回・30分の勉強会を設けました。
内容は、機械学習を基礎的なトピックスに分けて、「座学回」と「ハンズオン回」に分ける形を採用しました。「座学回」では、AIと機械学習の基本知識を学び、「ハンズオン回」ではGoogle Colaboratoryを使用して実際に手を動かしてもらいました。
ハンズオンの内容については、使用するデータセットと事前に学んだ機械学習モデルを利用するためのコードは運営サイドで用意し、説明した後に参加者が実際に問題を解く形をとりました。
全ての人が同じ環境で学べるようにすることで、初心者でも参加しやすいよう工夫しました。
そして、参加者の理解度を深め、手応えを感じてもらうことを目指し、全体の知識を確認するための最終課題として、参加者が独自にデータを分析・学習するタスクも設けました。
また、参加者には勉強会の参加を業務目標に設定してもらい、部署や役職に関わらず業務の一部として取り組んでもらえる仕組みにしました。これにより、参加者の意欲向上を図りました。
勉強会の課題と成果、そして新たな挑戦へ

実施にあたって、座学回での知識の選定やハンズオンのコーディングなど、いくつかの問題に直面しました。
座学では、AIと機械学習の基礎知識が膨大なため、30分に収めるための必要な知識の選定が課題でした。一方、ハンズオンでは、エンジニアと非エンジニアの間でコーディングスキルのギャップがあり、初めてコードを書く人には難しいという問題が出てきました。また、データの選定も難しく、業務に関連するデータを使うことは理解しやすいと思った一方で、初学者が使うにはノイズが多すぎて不適切な場合がありました。
さらに、一般に公開されているデータセットなどをそのまま使用すると、前処理に手間がかかりすぎて初学者向けとは言えなくなるため、最終課題のためのデータ選定も難しかったです。そして何よりも、運営メンバーも通常の業務と並行して勉強会をおこなっていたため、資料の準備や課題の採点の時間を確保することが困難でした。

これらの難しさを乗り越え、勉強会を実施した結果、多くの良い点が見られました。まず、社内の多様なバックグラウンドをもつメンバーに向けて、限られた時間内で機械学習の基礎的な部分を、コーディング含め説明することができたことです。普段のエンジニア業務だけでは得られない経験でした。また、「機械学習」を業務に活用していきたいという意欲を持つメンバーも増え、その後の実業務への活用を後押しをすることができたのは大きな成果さらに、非エンジニアの方が自主的にデータ分析を試みるようになったことも大きな収穫でした。
一方で、反省すべき点もあります。工夫を重ねましたが、それでもついていけず、フェードアウトしてしまったメンバーが一部いました。他の業務も並行しておこなっているためなかなか難しかったものの、離脱したメンバーの多くは非エンジニアメンバーだったため、もっと緻密なフォローが必要だったと感じています。
今回の勉強会では、[データの整形→モデル作成→予測→精度確認]の流れを体験してもらうことができました。次回は、実業務に関連するデータを整形・分析して、AI活用するデモンストレーションをおこないたいと思います。それにより、社内データのAI活用をさらに推進することが可能になると考えています。
Text & Directed by. Masaya Haruta & Yuki Kishida
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?